敏捷数据科学 - 快速指南
敏捷数据科学 - 简介
敏捷数据科学是一种使用数据科学和敏捷方法进行 Web 应用程序开发的方法。它侧重于适合影响组织变革的数据科学过程的输出。数据科学包括构建通过分析、交互式可视化以及现在应用的机器学习来描述研究过程的应用程序。
敏捷数据科学的主要目标是 -
记录并指导解释性数据分析,以发现并遵循打造引人注目的产品的关键路径。
敏捷数据科学是按照以下原则组织的 -
持续迭代
此过程涉及创建表格、图表、报告和预测的连续迭代。构建预测模型将需要对特征工程进行多次迭代,以提取和产生洞察力。
中间输出
这是生成的输出的轨道列表。甚至有人说,失败的实验也有产出。跟踪每次迭代的输出将有助于在下一次迭代中创建更好的输出。
原型实验
原型实验涉及分配任务并根据实验生成输出。在给定的任务中,我们必须迭代以获得洞察力,这些迭代可以最好地解释为实验。
数据整合
软件开发生命周期包括不同的阶段,其中数据至关重要 -
顾客
开发商,以及
这生意
数据的整合为更好的前景和产出铺平了道路。
Pyramid数据值

上述Pyramid值描述了“敏捷数据科学”发展所需的层次。它首先根据要求收集记录并检查各个记录。图表是在数据清理和聚合后创建的。聚合的数据可用于数据可视化。生成的报告具有正确的结构、元数据和数据标签。Pyramid从顶部算起的第二层包括预测分析。预测层是创造更多价值的地方,但有助于创建专注于特征工程的良好预测。
最顶层涉及有效驱动数据价值的行动。这种实现的最好例证是“人工智能”。
敏捷数据科学 - 方法论概念
在本章中,我们将重点讨论称为“敏捷”的软件开发生命周期的概念。敏捷软件开发方法有助于通过 1 到 4 周的短迭代内的增量会话来构建软件,从而使开发与不断变化的业务需求保持一致。
有 12 条原则详细描述了敏捷方法 -
客户满意度
通过早期和持续交付有价值的软件,我们会优先考虑关注需求的客户。
迎接新变化
软件开发期间的更改是可以接受的。敏捷流程旨在匹配客户的竞争优势。
送货
工作软件会在一到四个星期内交付给客户。
合作
业务分析师、质量分析师和开发人员必须在项目的整个生命周期中共同努力。
动机
项目应该由一群积极进取的个人来设计。它提供了一个支持各个团队成员的环境。
个人谈话
面对面的对话是向开发团队以及在开发团队内部发送信息的最高效、最有效的方法。
衡量进展
衡量进度是帮助定义项目和软件开发进度的关键。
保持恒定的步伐
敏捷过程注重可持续发展。企业、开发人员和用户应该能够与项目保持一致的节奏。
监控
必须定期关注卓越技术和良好设计,以增强敏捷功能。
简单
敏捷流程使一切变得简单,并使用简单的术语来衡量未完成的工作。
自组织术语
敏捷团队应该是自组织的,应该是独立的,有最好的架构;需求和设计来自自组织团队。
回顾工作
定期审查工作非常重要,以便团队能够反思工作的进展情况。及时审查模块将提高性能。
每日站立会
每日站会是指团队成员之间的日常状况会议。它提供与软件开发相关的更新。它还指解决项目开发的障碍。
无论敏捷团队如何建立,无论其办公地点在哪里,每日站会都是强制性的做法。
每日站立会议的特点列表如下:
每日站立会议的持续时间应约为 15 分钟。它不应延长较长的持续时间。
站立会议应包括有关状态更新的讨论。
这次会议的参与者通常站着,打算尽快结束会议。
用户故事
故事通常是一个需求,用简单的语言用几句话来表述,并且应该在一个迭代内完成。用户故事应包括以下特征 -
所有相关代码都应该有相关的签入。
指定迭代的单元测试用例。
应定义所有验收测试用例。
定义故事时得到产品负责人的接受。
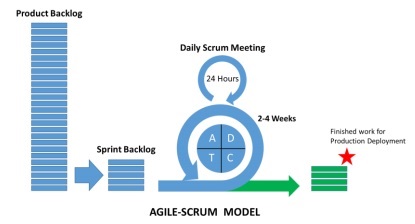
什么是 Scrum?
Scrum 可以被视为敏捷方法论的一个子集。这是一个轻量级的过程,包括以下功能 -
它是一个流程框架,其中包括一组需要按一致顺序遵循的实践。Scrum 的最佳例证是迭代或冲刺。
这是一个“轻量级”流程,意味着流程尽可能小,以在指定的给定时间内最大化生产产出。
与传统敏捷方法的其他方法相比,Scrum 过程以其独特的过程而闻名。它分为以下三类 -
角色
文物
时间盒
角色定义了团队成员及其在整个流程中的角色。Scrum 团队由以下三个角色组成 -
敏捷大师
产品拥有者
团队
Scrum 工件提供了每个成员都应该了解的关键信息。这些信息包括产品、计划的活动和已完成的活动的详细信息。Scrum 框架中定义的工件如下 -
产品积压
冲刺待办事项
燃尽图
增量
时间框是为每次迭代计划的用户故事。这些用户故事有助于描述构成 Scrum 工件一部分的产品功能。产品待办事项列表是用户故事的列表。这些用户故事会按优先级排列并转发给用户会议,以决定应该讨论哪一个。
为什么是 Scrum Master?
Scrum Master 与团队的每个成员互动。现在让我们看看 Scrum Master 与其他团队和资源的交互。
产品拥有者
Scrum Master 通过以下方式与产品负责人互动 -
寻找技术来实现有效的用户故事产品积压并对其进行管理。
帮助团队了解清晰简洁的产品待办事项列表的需求。
特定环境下的产品规划。
确保产品负责人知道如何增加产品的价值。
根据需要促进 Scrum 活动。
Scrum 团队
Scrum Master 通过多种方式与团队互动 -
指导组织采用 Scrum。
规划特定组织的 Scrum 实施。
帮助员工和利益相关者了解产品开发的要求和阶段。
与其他团队的 Scrum Master 合作,提高指定团队 Scrum 应用的有效性。
组织
Scrum Master 通过多种方式与组织进行交互。下面提到了一些 -
教练和 scrum 团队与自组织交互,并包含跨功能的特征。
在 Scrum 尚未完全采用或不被接受的领域对组织和团队进行指导。
Scrum 的好处
Scrum 帮助客户、团队成员和利益相关者进行协作。它包括限时方法和产品负责人的持续反馈,确保产品处于工作状态。Scrum 为项目的不同角色提供了好处。
顾客
冲刺或迭代的持续时间较短,用户故事是根据优先级设计的,并在冲刺计划中进行。它确保每次冲刺交付、客户要求都得到满足。如果没有,则会记录需求并计划并进行冲刺。
组织
在 Scrum 和 Scrum master 的帮助下,组织可以专注于开发用户故事所需的工作,从而减少工作负担并避免返工(如果有)。这也有助于提高开发团队的效率和客户满意度。这种方法还有助于增加市场潜力。
产品经理
产品经理的主要职责是确保维持产品质量。在 Scrum Master 的帮助下,可以轻松促进工作、收集快速响应并吸收变化(如果有)。产品经理还会在每个冲刺中验证设计的产品是否符合客户要求。
开发团队
由于时间限制和冲刺时间较短,开发团队会热衷于看到工作得到正确反映和交付。工作产品在每次迭代后都会递增每个级别,或者更确切地说,我们可以将它们称为“冲刺”。为每个冲刺设计的用户故事成为客户优先考虑的事项,为迭代增加更多价值。
结论
Scrum 是一个高效的框架,您可以在其中团队合作开发软件。它完全按照敏捷原则设计。ScrumMaster 以各种可能的方式帮助和配合 Scrum 团队。他就像一位私人教练,帮助您坚持设计的计划并按照计划执行所有活动。ScrumMaster 的权威永远不应该超出流程。他/她应该有能力应对各种情况。
敏捷数据科学 - 数据科学流程
在本章中,我们将了解数据科学过程以及理解该过程所需的术语。
“数据科学是数据接口、算法开发和技术的融合,旨在解决分析复杂问题”。

数据科学是一个跨学科领域,涵盖科学方法、过程和系统,其中包括机器学习、数学和统计知识与传统研究等类别。它还包括黑客技能与实质性专业知识的结合。数据科学从数学、统计学、信息科学、计算机科学、数据挖掘和预测分析中汲取原理。
下面提到了构成数据科学团队的不同角色 -
顾客
客户是使用该产品的人。他们的兴趣决定了项目的成功,他们的反馈在数据科学中非常有价值。
业务发展
这个数据科学团队通过直接或通过创建登陆页面和促销活动来吸引早期客户。业务开发团队交付产品的价值。
产品经理
产品经理认识到创造具有市场价值的最佳产品的重要性。
交互设计师
他们专注于围绕数据模型设计交互,以便用户找到适当的价值。
数据科学家
数据科学家以新的方式探索和转换数据,以创建和发布新功能。这些科学家还结合不同来源的数据来创造新的价值。他们在与研究人员、工程师和网络开发人员一起创建可视化方面发挥着重要作用。
研究人员
顾名思义,研究人员参与研究活动。他们解决数据科学家无法解决的复杂问题。这些问题涉及机器学习和统计模块的高度关注和时间。
适应变化
数据科学的所有团队成员都需要适应新的变化,根据需求开展工作。采用数据科学的敏捷方法应该做出一些改变,如下:
选择通才而不是专家。
小团队优于大团队。
使用高级工具和平台。
中间工作的持续迭代共享。
笔记
在敏捷数据科学团队中,一个由通才组成的小团队使用可扩展的高级工具,并通过迭代将数据细化为越来越高的价值状态。
考虑以下与数据科学团队成员的工作相关的示例 -
设计师交付 CSS。
Web 开发人员构建整个应用程序,了解用户体验和界面设计。
数据科学家应该致力于研究和构建网络服务,包括网络应用程序。
研究人员在代码库中工作,代码库显示解释中间结果的结果。
产品经理尝试识别和理解所有相关领域的缺陷。
敏捷工具和安装
在本章中,我们将了解不同的敏捷工具及其安装。敏捷方法的开发堆栈包括以下组件集 -
活动
事件是指发生或记录的事件及其特征和时间戳。
事件可以有多种形式,例如服务器、传感器、金融交易或用户在我们的应用程序中采取的操作。在这个完整的教程中,我们将使用 JSON 文件来促进不同工具和语言之间的数据交换。
收藏家
收藏家是事件聚合者。它们以系统的方式收集事件,以存储和聚合大量数据,使实时工作人员可以采取行动。
分发文档
这些文档包括以特定格式存储文档的多节点(多个节点)。在本教程中我们将重点关注 MongoDB。
网络应用服务器
Web 应用程序服务器通过可视化方式通过客户端将数据支持为 JSON,并且开销最小。这意味着 Web 应用程序服务器有助于测试和部署使用敏捷方法创建的项目。
现代浏览器
它使现代浏览器或应用程序能够将数据作为用户的交互工具呈现。
本地环境设置
对于管理数据集,我们将重点关注 python 的 Anaconda 框架,其中包括用于管理 excel、csv 和更多文件的工具。Anaconda框架安装完成后的仪表板如下图所示。它也被称为“Anaconda Navigator” -

导航器包括“Jupyter 框架”,这是一个有助于管理数据集的笔记本系统。一旦启动框架,它将托管在浏览器中,如下所述 -

敏捷数据科学 - 敏捷数据处理
在本章中,我们将重点讨论结构化、半结构化和非结构化数据之间的区别。
结构化数据
结构化数据涉及以 SQL 格式存储在包含行和列的表中的数据。它包括一个关系键,映射到预先设计的字段中。结构化数据的使用规模更大。
结构化数据仅占所有信息学数据的 5% 到 10%。
半结构化数据
Sem 结构数据包括不驻留在关系数据库中的数据。它们包括一些更容易分析的组织属性。它包括将它们存储在关系数据库中的相同过程。半结构化数据库的示例有 CSV 文件、XML 和 JSON 文档。NoSQL 数据库被认为是半结构化的。
非结构化数据
非结构化数据占数据的 80%。它通常包括文本和多媒体内容。非结构化数据的最佳示例包括音频文件、演示文稿和网页。机器生成的非结构化数据的例子有卫星图像、科学数据、照片和视频、雷达和声纳数据。

上述Pyramid结构特别关注数据量及其分散的比例。
准结构化数据是介于非结构化数据和半结构化数据之间的类型。在本教程中,我们将重点关注半结构化数据,这有利于敏捷方法论和数据科学研究。
半结构化数据没有正式的数据模型,但具有通过分析开发的明显的、自描述的模式和结构。
敏捷数据科学 - SQL 与 NoSQL
本教程的全部重点是遵循敏捷方法,减少步骤并实现更有用的工具。要理解这一点,了解 SQL 和 NoSQL 数据库之间的区别非常重要。
大多数用户都了解SQL数据库,并且对MySQL、Oracle或其他SQL数据库有很好的了解。在过去的几年里,NoSQL 数据库被广泛采用来解决各种业务问题和项目需求。

下表显示了 SQL 和 NoSQL 数据库之间的区别 -
| SQL | NoSQL |
|---|---|
| SQL数据库主要称为关系数据库管理系统(RDBMS)。 | NoSQL数据库也称为面向文档的数据库。它是非关系型的、分布式的。 |
| 基于 SQL 的数据库包括具有行和列的表结构。表和其他模式结构的集合称为数据库。 | NoSQL数据库以文档为主要结构,文档的包含称为集合。 |
| SQL 数据库包括预定义的架构。 | NoSQL 数据库拥有动态数据并包含非结构化数据。 |
| SQL 数据库是垂直可扩展的。 | NoSQL 数据库是水平可扩展的。 |
| SQL数据库非常适合复杂的查询环境。 | NoSQL 没有用于复杂查询开发的标准接口。 |
| SQL 数据库不适用于分层数据存储。 | NoSQL 数据库更适合分层数据存储。 |
| SQL 数据库最适合指定应用程序中的繁重事务。 | NoSQL 数据库在复杂事务应用程序的高负载方面仍然不被认为具有可比性。 |
| SQL 数据库为其供应商提供了出色的支持。 | NoSQL 数据库仍然依赖社区支持。只有少数专家可以进行大规模 NoSQL 部署的设置和部署。 |
| SQL 数据库关注 ACID 属性——Atomics性、一致性、隔离性和持久性。 | NoSQL 数据库关注 CAP 属性——一致性、可用性和分区容错性。 |
| 根据选择 SQL 数据库的供应商,SQL 数据库可以分为开源数据库和闭源数据库。 | NoSQL 数据库根据存储类型进行分类。NoSQL 数据库默认是开源的。 |
为什么要使用 NoSQL 来实现敏捷?
通过上述对比可以看出,NoSQL文档数据库完全支持敏捷开发。它是无模式的,并且不完全专注于数据建模。相反,NoSQL 推迟了应用程序和服务,因此开发人员可以更好地了解如何对数据进行建模。NoSQL 将数据模型定义为应用程序模型。

MongoDB安装
在本教程中,我们将更多地关注 MongoDB 的示例,因为它被认为是最好的“NoSQL 模式”。





NoSQL 和数据流编程
有时,数据无法以关系格式提供,我们需要借助 NoSQL 数据库来保持数据的事务性。
在本章中,我们将重点讨论NoSQL的数据流。我们还将了解它如何结合敏捷和数据科学进行操作。
敏捷使用 NoSQL 的主要原因之一是为了提高市场竞争的速度。以下原因表明 NoSQL 如何最适合敏捷软件方法 -
更少的障碍
即使在敏捷开发的情况下,目前正在中途改变模型也会产生一些实际成本。使用 NoSQL,用户可以使用聚合数据,而不是浪费时间来标准化数据。要点是完成某件事并以使模型数据完美为目标。
提高可扩展性
每当组织创建产品时,它都会更加关注其可扩展性。NoSQL 一直以其可扩展性而闻名,但当它设计为具有水平可扩展性时,效果会更好。
利用数据的能力
NoSQL 是一种无模式数据模型,允许用户轻松使用大量数据,其中包括多个可变性和速度参数。在考虑选择技术时,您应该始终考虑能够更大规模地利用数据的技术。
NoSQL的数据流
让我们考虑以下示例,其中我们展示了数据模型如何专注于创建 RDBMS 模式。
以下是模式的不同要求 -
应列出用户标识。
每个用户都应该至少拥有一项强制性技能。
每个用户体验的细节都应该得到妥善维护。
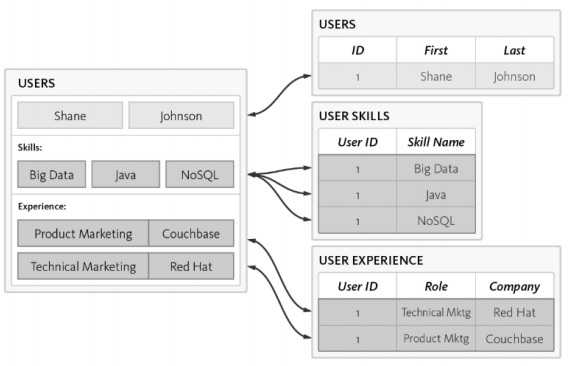
用户表使用 3 个独立的表进行规范化 -
用户
用户技能
用户体验
查询数据库时复杂性会增加,并且随着规范化的增加,时间消耗也会增加,这不利于敏捷方法。可以使用 NoSQL 数据库设计相同的模式,如下所述 -
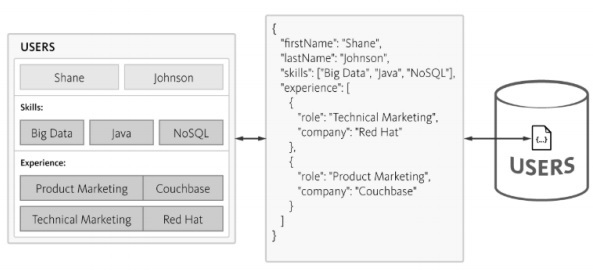
NoSQL 以 JSON 格式维护结构,结构轻量。使用 JSON,应用程序可以将具有嵌套数据的对象存储为单个文档。
收集和显示记录
在本章中,我们将重点关注 JSON 结构,它构成了“敏捷方法论”的一部分。MongoDB 是一种广泛使用的 NoSQL 数据结构,操作简单,可以收集和显示记录。
步骤1
此步骤涉及与 MongoDB 建立连接以创建集合和指定的数据模型。您需要执行的只是用于启动连接的“mongod”命令和用于连接到指定终端的 mongo 命令。
第2步
创建一个新数据库,用于创建 JSON 格式的记录。现在,我们正在创建一个名为“mydb”的虚拟数据库。
>use mydb
switched to db mydb
>db
mydb
>show dbs
local 0.78125GB
test 0.23012GB
>db.user.insert({"name":"Agile Data Science"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
步骤3
要获取记录列表,必须创建集合。此功能有利于数据科学研究和输出。
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>show collections
mycollection
system.indexes
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>db.agiledatascience.insert({"name" : "demoname"})
>show collections
mycol
mycollection
system.indexes
demoname
敏捷数据科学 - 数据可视化
数据可视化在数据科学中发挥着非常重要的作用。我们可以将数据可视化视为数据科学的一个模块。数据科学不仅仅包括构建预测模型。它包括模型的解释以及使用它们来理解数据和做出决策。数据可视化是以最令人信服的方式呈现数据的一个组成部分。
从数据科学的角度来看,数据可视化是展示变化和趋势的一大亮点。
考虑以下有效数据可视化指南 -
沿通用比例定位数据。
与圆形和方形相比,使用条形更有效。
散点图应使用适当的颜色。
使用饼图来显示比例。
旭日可视化对于分层图更有效。
敏捷需要一种简单的脚本语言来进行数据可视化,并且与数据科学合作“Python”是数据可视化的建议语言。
实施例1
以下示例演示了特定年份计算的 GDP 的数据可视化。“Matplotlib”是 Python 中最好的数据可视化库。该库的安装如下所示 -

请考虑以下代码来理解这一点 -
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()
输出
上面的代码生成以下输出 -

有多种方法可以使用轴标签、线条样式和点标记来自定义图表。让我们重点关注下一个示例,该示例演示了更好的数据可视化。这些结果可用于更好的输出。
实施例2
import datetime import random import matplotlib.pyplot as plt # make up some data x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)] y = [i+random.gauss(0,1) for i,_ in enumerate(x)] # plot plt.plot(x,y) # beautify the x-labels plt.gcf().autofmt_xdate() plt.show()
输出
上面的代码生成以下输出 -

敏捷数据科学 - 数据丰富
数据丰富是指用于增强、细化和改进原始数据的一系列过程。它指的是有用的数据转换(原始数据到有用信息)。数据丰富的过程侧重于使数据成为现代商业或企业的宝贵数据资产。
最常见的数据丰富过程包括通过使用特定的决策算法来纠正数据库中的拼写错误或印刷错误。数据丰富工具向简单的数据表添加有用的信息。
考虑以下单词拼写纠正代码 -
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
print(correction('speling'))
print(correction('korrectud'))
在此程序中,我们将与包含更正单词的“big.txt”进行匹配。单词与文本文件中包含的单词匹配,并相应地打印适当的结果。
输出
上面的代码将生成以下输出 -

敏捷数据科学 - 使用报告
在本章中,我们将学习报告创建,这是敏捷方法论的一个重要模块。敏捷冲刺将通过可视化创建的图表页面转化为成熟的报告。通过报告,图表变得交互式,静态页面变得动态且与网络相关的数据。数据价值Pyramid报告阶段的特征如下所示 -

我们将更加注重创建csv文件,它可以用作数据科学分析的报告,并得出结论。尽管敏捷侧重于减少文档,但始终会考虑生成报告以提及产品开发的进度。
import csv
#----------------------------------------------------------------------
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "wb") as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
path = "output.csv"
csv_writer(data, path)
上面的代码将帮助您生成“csv 文件”,如下所示 -

让我们考虑一下 csv(逗号分隔值)报告的以下好处 -
- 它对人友好且易于手动编辑。
- 实现和解析都很简单。
- CSV 可以在所有应用程序中处理。
- 它更小,处理速度更快。
- CSV 遵循标准格式。
- 它为数据科学家提供了简单的模式。
敏捷数据科学 - 预测的作用
在本章中,我们将了解预测在敏捷数据科学中的作用。交互式报告揭示了数据的不同方面。预测构成了敏捷冲刺的第四层。

在进行预测时,我们总是参考过去的数据并将其用作未来迭代的推论。在这个完整的过程中,我们将数据从历史数据的批量处理转变为关于未来的实时数据。
预测的作用包括以下内容 -
预测有助于预测。一些预测是基于统计推断。一些预测是基于专家的意见。
统计推断涉及各种预测。
有时预测准确,有时预测不准确。
预测分析
预测分析包括来自预测建模、机器学习和数据挖掘的各种统计技术,这些技术分析当前和历史事实,以对未来和未知事件做出预测。
预测分析需要训练数据。训练数据包括独立特征和相关特征。相关特征是用户尝试预测的值。独立特征是描述我们想要基于依赖特征预测的事物的特征。
对特征的研究称为特征工程;这对于做出预测至关重要。数据可视化和探索性数据分析是特征工程的一部分;这些构成了敏捷数据科学的核心。

做出预测
在敏捷数据科学中进行预测有两种方法 -
回归
分类
构建回归或分类完全取决于业务需求及其分析。连续变量的预测导致回归模型,分类变量的预测导致分类模型。
回归
回归考虑包含特征的示例,从而产生数字输出。
分类
分类获取输入并产生分类。
注意- 定义统计预测的输入并使机器能够学习的示例数据集称为“训练数据”。
使用 PySpark 提取特征
在本章中,我们将了解 PySpark 提取特征在敏捷数据科学中的应用。
Spark概述
Apache Spark 可以定义为一个快速实时处理框架。它进行计算以实时分析数据。Apache Spark 被引入作为实时流处理系统,也可以处理批处理。Apache Spark 支持交互式查询和迭代算法。
Spark 是用“Scala 编程语言”编写的。
PySpark 可以被认为是 Python 与 Spark 的结合。PySpark 提供 PySpark shell,它将 Python API 链接到 Spark 核心并初始化 Spark 上下文。大多数数据科学家使用 PySpark 来跟踪特征,如上一章所述。
在此示例中,我们将重点关注构建名为 counts 的数据集并将其保存到特定文件的转换。
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
使用 PySpark,用户可以使用 Python 编程语言处理 RDD。内置库涵盖了数据驱动文档和组件的基础知识,对此有所帮助。
建立回归模型
逻辑回归是指用于预测类别因变量概率的机器学习算法。在逻辑回归中,因变量是二元变量,由编码为 1(布尔值 true 和 false)的数据组成。
在本章中,我们将重点关注使用连续变量在 Python 中开发回归模型。线性回归模型的示例将重点关注 CSV 文件中的数据探索。
分类目标是预测客户是否会认购(1/0)定期存款。
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))
按照以下步骤使用“Jupyter Notebook”在 Anaconda Navigator 中实现上述代码 -
步骤 1 - 使用 Anaconda Navigator 启动 Jupyter Notebook。
步骤 2 - 上传 csv 文件以系统方式获取回归模型的输出。
步骤 3 - 创建一个新文件并执行上述代码行以获得所需的输出。
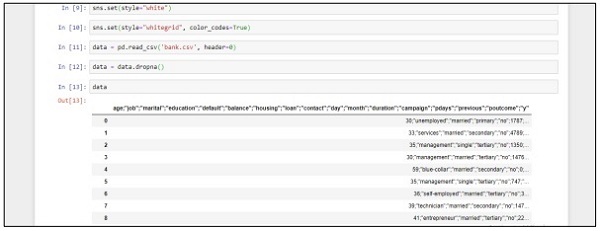
部署预测系统
在此示例中,我们将学习如何创建和部署预测模型,该模型有助于使用 python 脚本预测房价。用于部署预测系统的重要框架包括Anaconda和“Jupyter Notebook”。
请按照以下步骤部署预测系统 -
步骤 1 - 实现以下代码将 csv 文件中的值转换为关联值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
data = pd.read_csv("kc_house_data.csv")
data.head()
上面的代码生成以下输出 -

步骤 2 - 执行描述函数以获取 csv 文件属性中包含的数据类型。
data.describe()

步骤 3 - 我们可以根据我们创建的预测模型的部署删除关联值。
train1 = data.drop(['id', 'price'],axis=1) train1.head()

步骤 4 - 您可以根据记录可视化数据。数据可用于数据科学分析和白皮书输出。
data.floors.value_counts().plot(kind='bar')

敏捷数据科学 - SparkML
机器学习库也称为“SparkML”或“MLLib”,由常见的学习算法组成,包括分类、回归、聚类和协同过滤。
为什么要学习 SparkML 来实现敏捷?
Spark 正在成为构建机器学习算法和应用程序的事实上的平台。Spark 开发人员致力于在 Spark 框架中以可扩展且简洁的方式实现机器算法。我们将通过这个框架学习机器学习的概念、实用程序和算法。敏捷总是选择一个框架,它可以提供简短而快速的结果。
机器学习算法
机器学习算法包括分类、回归、聚类和协同过滤等常见学习算法。
特征
它包括特征提取、变换、降维和选择。
管道
Pipelines 提供了用于构建、评估和调整机器学习管道的工具。
流行算法
以下是一些流行的算法 -
基础统计
回归
分类
推荐系统
聚类
降维
特征提取
优化
推荐系统
推荐系统是信息过滤系统的子类,它寻求用户对给定项目建议的“评级”和“偏好”的预测。
推荐系统包括各种过滤系统,其使用如下 -
协同过滤
它包括根据过去的Behave以及其他用户做出的类似决策构建模型。这种特定的过滤模型用于预测用户感兴趣的项目。
基于内容的过滤
它包括过滤项目的离散特征,以便推荐和添加具有相似属性的新项目。
在后续章节中,我们将重点讨论使用推荐系统解决特定问题并从敏捷方法论的角度提高预测性能。
修复预测问题
在本章中,我们将重点在特定场景的帮助下解决预测问题。
假设一家公司希望根据通过在线申请表提供的客户详细信息自动处理贷款资格详细信息。详细信息包括客户姓名、性别、婚姻状况、贷款金额和其他必填信息。
详细信息记录在 CSV 文件中,如下所示 -

执行以下代码来评估预测问题 -
import pandas as pd
from sklearn import ensemble
import numpy as np
from scipy.stats import mode
from sklearn import preprocessing,model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
#loading the dataset
data=pd.read_csv('train.csv',index_col='Loan_ID')
def num_missing(x):
return sum(x.isnull())
#imputing the the missing values from the data
data['Gender'].fillna(mode(list(data['Gender'])).mode[0], inplace=True)
data['Married'].fillna(mode(list(data['Married'])).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(list(data['Self_Employed'])).mode[0], inplace=True)
# print (data.apply(num_missing, axis=0))
# #imputing mean for the missing value
data['LoanAmount'].fillna(data['LoanAmount'].mean(), inplace=True)
mapping={'0':0,'1':1,'2':2,'3+':3}
data = data.replace({'Dependents':mapping})
data['Dependents'].fillna(data['Dependents'].mean(), inplace=True)
data['Loan_Amount_Term'].fillna(method='ffill',inplace=True)
data['Credit_History'].fillna(method='ffill',inplace=True)
print (data.apply(num_missing,axis=0))
#converting the cateogorical data to numbers using the label encoder
var_mod = ['Gender','Married','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
le.fit(list(data[i].values))
data[i] = le.transform(list(data[i]))
#Train test split
x=['Gender','Married','Education','Self_Employed','Property_Area','LoanAmount', 'Loan_Amount_Term','Credit_History','Dependents']
y=['Loan_Status']
print(data[x])
X_train,X_test,y_train,y_test=model_selection.train_test_split(data[x],data[y], test_size=0.2)
#
# #Random forest classifier
# clf=ensemble.RandomForestClassifier(n_estimators=100,
criterion='gini',max_depth=3,max_features='auto',n_jobs=-1)
clf=ensemble.RandomForestClassifier(n_estimators=200,max_features=3,min_samples
_split=5,oob_score=True,n_jobs=-1,criterion='entropy')
clf.fit(X_train,y_train)
accuracy=clf.score(X_test,y_test)
print(accuracy)
输出
上面的代码生成以下输出。

提高预测性能
在本章中,我们将重点构建一个模型,该模型有助于预测学生的表现,其中包含许多属性。重点是展示学生考试不及格的结果。
过程
评估目标值为G3。该值可以被分类并进一步分类为失败和成功。如果G3值大于或等于10,则学生通过考试。
例子
考虑以下示例,其中执行代码来预测学生的表现 -
import pandas as pd
""" Read data file as DataFrame """
df = pd.read_csv("student-mat.csv", sep=";")
""" Import ML helpers """
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import LinearSVC # Support Vector Machine Classifier model
""" Split Data into Training and Testing Sets """
def split_data(X, Y):
return train_test_split(X, Y, test_size=0.2, random_state=17)
""" Confusion Matrix """
def confuse(y_true, y_pred):
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
# print("\nConfusion Matrix: \n", cm)
fpr(cm)
ffr(cm)
""" False Pass Rate """
def fpr(confusion_matrix):
fp = confusion_matrix[0][1]
tf = confusion_matrix[0][0]
rate = float(fp) / (fp + tf)
print("False Pass Rate: ", rate)
""" False Fail Rate """
def ffr(confusion_matrix):
ff = confusion_matrix[1][0]
tp = confusion_matrix[1][1]
rate = float(ff) / (ff + tp)
print("False Fail Rate: ", rate)
return rate
""" Train Model and Print Score """
def train_and_score(X, y):
X_train, X_test, y_train, y_test = split_data(X, y)
clf = Pipeline([
('reduce_dim', SelectKBest(chi2, k=2)),
('train', LinearSVC(C=100))
])
scores = cross_val_score(clf, X_train, y_train, cv=5, n_jobs=2)
print("Mean Model Accuracy:", np.array(scores).mean())
clf.fit(X_train, y_train)
confuse(y_test, clf.predict(X_test))
print()
""" Main Program """
def main():
print("\nStudent Performance Prediction")
# For each feature, encode to categorical values
class_le = LabelEncoder()
for column in df[["school", "sex", "address", "famsize", "Pstatus", "Mjob",
"Fjob", "reason", "guardian", "schoolsup", "famsup", "paid", "activities",
"nursery", "higher", "internet", "romantic"]].columns:
df[column] = class_le.fit_transform(df[column].values)
# Encode G1, G2, G3 as pass or fail binary values
for i, row in df.iterrows():
if row["G1"] >= 10:
df["G1"][i] = 1
else:
df["G1"][i] = 0
if row["G2"] >= 10:
df["G2"][i] = 1
else:
df["G2"][i] = 0
if row["G3"] >= 10:
df["G3"][i] = 1
else:
df["G3"][i] = 0
# Target values are G3
y = df.pop("G3")
# Feature set is remaining features
X = df
print("\n\nModel Accuracy Knowing G1 & G2 Scores")
print("=====================================")
train_and_score(X, y)
# Remove grade report 2
X.drop(["G2"], axis = 1, inplace=True)
print("\n\nModel Accuracy Knowing Only G1 Score")
print("=====================================")
train_and_score(X, y)
# Remove grade report 1
X.drop(["G1"], axis=1, inplace=True)
print("\n\nModel Accuracy Without Knowing Scores")
print("=====================================")
train_and_score(X, y)
main()
输出
上面的代码生成的输出如下所示
仅参考一个变量来处理预测。参考一个变量,学生表现预测如下 -

用敏捷和数据科学创造更好的场景
敏捷方法帮助组织适应变化、参与市场竞争并构建高质量的产品。据观察,组织随着敏捷方法的成熟而成熟,客户需求的变化也不断增加。与敏捷的组织团队编译和同步数据对于根据所需的产品组合汇总数据非常重要。
制定更好的计划
标准化的敏捷绩效完全取决于计划。有序的数据模式提高了组织进步的生产力、质量和响应能力。数据一致性水平与历史和实时场景保持一致。
考虑下图来理解数据科学实验周期 -

数据科学涉及需求分析,然后基于需求分析创建算法。一旦算法和环境设置一起设计,用户就可以创建实验并收集数据以进行更好的分析。
这种意识形态计算敏捷的最后冲刺,称为“行动”。

行动涉及最后一个冲刺或敏捷方法级别的所有强制性任务。可以使用故事卡作为行动项目来维护数据科学阶段(相对于生命周期)的跟踪。
预测分析和大数据
规划的未来完全取决于通过分析收集的数据定制数据报告。它还将包括通过大数据分析进行操作。在大数据的帮助下,可以通过对组织的指标进行有效地分析来分析离散的信息。分析始终被认为是更好的解决方案。
敏捷数据科学 - 敏捷的实施
敏捷开发过程中使用了多种方法。这些方法也可用于数据科学研究过程。
下面给出的流程图显示了不同的方法 -

Scrum
在软件开发术语中,Scrum 意味着管理小团队的工作以及管理特定项目以揭示项目的优势和劣势。
水晶方法论
Crystal 方法论包括产品管理和执行的创新技术。通过这种方法,团队可以以不同的方式完成类似的任务。Crystal 系列是最容易应用的方法之一。
动态软件开发方法
该交付框架主要用于实现当前软件方法论的知识体系。
未来驱动发展
此开发生命周期的重点是项目涉及的功能。它最适合领域对象建模、代码和所有权功能开发。
精益软件开发
这种方法旨在以低成本提高软件开发速度,并使团队专注于为客户提供特定价值。极限编程
极限编程是一种独特的软件开发方法,其重点在于提高软件质量。当客户不确定任何项目的功能时,这种方法会很有效。
敏捷方法论正在数据科学领域扎根,被认为是重要的软件方法论。通过敏捷的自组织,跨职能团队可以有效地协同工作。如前所述,敏捷开发有六种主要类别,每一类都可以根据要求与数据科学进行流式传输。数据科学涉及统计见解的迭代过程。敏捷有助于分解数据科学模块,并有助于有效地处理迭代和冲刺。
敏捷数据科学的过程是理解数据科学模块如何以及为何实施的一种奇妙方式。它以创造性的方式解决问题。