其他分类方法
这里我们将讨论其他分类方法,例如遗传算法、粗糙集方法和模糊集方法。
遗传算法
遗传算法的思想来源于自然进化。在遗传算法中,首先创建初始种群。该初始群体由随机生成的规则组成。我们可以用一串位来表示每个规则。
例如,在给定的训练集中,样本由两个布尔属性(例如A1和A2)来描述。这个给定的训练集包含两个类,例如 C1 和 C2。
我们可以将规则IF A1 AND NOT A2 THEN C2 编码为位串100。在该位表示中,最左边的两个位分别表示属性A1和A2。
同样,规则IF NOT A1 AND NOT A2 THEN C1可以被编码为001。
注意- 如果属性有 K 个值,其中 K>2,那么我们可以使用 K 位来对属性值进行编码。类也以相同的方式编码。
要记住的要点 -
基于适者生存的概念,形成一个新的种群,该种群由当前种群中的适者规则和这些规则的后代值组成。
规则的适用性通过其在一组训练样本上的分类准确性来评估。
应用交叉和变异等遗传算子来创造后代。
在交叉中,规则对中的子串被交换以形成一对新的规则。
在变异中,规则字符串中随机选择的位被反转。
粗糙集方法
我们可以使用粗糙集方法来发现不精确和噪声数据中的结构关系。
注意- 此方法只能应用于离散值属性。因此,连续值属性在使用前必须进行离散化。
粗糙集理论基于给定训练数据内等价类的建立。形成等价类的元组是难以辨别的。这意味着样本在描述数据的属性方面是相同的。
给定的现实世界数据中存在一些类,无法根据可用属性来区分。我们可以使用粗糙集来粗略地定义此类。
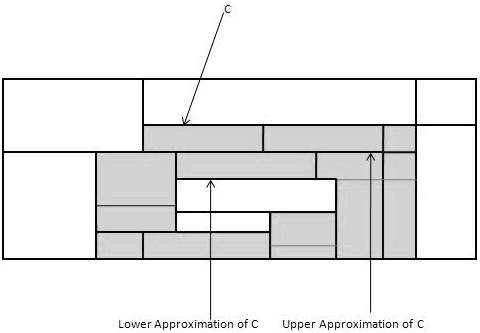
对于给定的 C 类,粗糙集定义由两个集合近似,如下所示 -
C 的下近似值- C 的下近似值由所有数据元组组成,基于属性的知识,这些数据元组肯定属于 C 类。
C 的上近似- C 的上近似由所有元组组成,基于属性的知识,不能被描述为不属于 C。
下图显示了 C 类的上近似和下近似 -
模糊集方法
模糊集合论也称为可能性论。该理论由 Lotfi Zadeh 于 1965 年提出,作为二值逻辑和概率论的替代。这个理论使我们能够在高抽象层次上工作。它还为我们提供了处理数据测量不精确的方法。
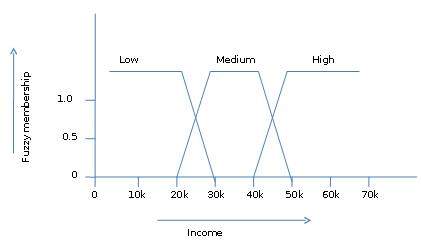
模糊集合论还允许我们处理模糊或不精确的事实。例如,成为一组高收入的成员是准确的(例如,如果 50,000 美元很高,那么 49,000 美元和 48,000 美元又如何)。与传统的 CRISP 集合不同,传统的 CRISP 集合中的元素要么属于 S 要么属于它的补集,但在模糊集合理论中,元素可以属于多个模糊集合。
例如,收入值$49,000既属于中模糊集又属于高模糊集,但程度不同。该收入值的模糊集符号如下 -
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96
其中“m”是分别对medium_venue 和high_venue 的模糊集进行操作的隶属函数。该符号可以用图解表示如下 -