H2O - 快速指南
H2O - 简介
您是否曾被要求在巨大的数据库上开发机器学习模型?通常,客户会向您提供数据库并要求您做出某些预测,例如谁将是潜在买家;是否可以及早发现欺诈案件等。要回答这些问题,您的任务是开发一种机器学习算法,为客户的查询提供答案。从头开始开发机器学习算法并不是一件容易的事,当市场上有几个现成的机器学习库可用时,为什么要这样做呢?
如今,您更愿意使用这些库,应用这些库中经过充分测试的算法并查看其性能。如果性能不在可接受的范围内,您将尝试微调当前算法或尝试完全不同的算法。
同样,您可以在同一数据集上尝试多种算法,然后选择最能满足客户要求的算法。这就是 H2O 来拯救你的地方。它是一个开源机器学习框架,对多种广泛接受的机器学习算法进行了全面测试的实现。您只需从其庞大的存储库中获取算法并将其应用到您的数据集即可。它包含最广泛使用的统计和机器学习算法。
这里仅举几例,其中包括梯度增强机 (GBM)、广义线性模型 (GLM)、深度学习等等。不仅如此,它还支持 AutoML 功能,可以对数据集上不同算法的性能进行排名,从而减少寻找最佳性能模型的工作量。H2O 在全球范围内被超过 18000 个组织使用,并且与 R 和 Python 很好地接口,以便于您的开发。它是一个提供卓越性能的内存平台。
在本教程中,您将首先学习使用 Python 和 R 选项在计算机上安装 H2O。我们将了解如何在命令行中使用它,以便您了解其按行工作。如果您是 Python 爱好者,您可以使用 Jupyter 或您选择的任何其他 IDE 来开发 H2O 应用程序。如果您更喜欢 R,您可以使用 RStudio 进行开发。
在本教程中,我们将通过一个示例来了解如何使用 H2O。我们还将学习如何更改程序代码中的算法,并将其性能与之前的算法进行比较。H2O 还提供了一个基于网络的工具来测试数据集上的不同算法。这就是所谓的“流”。
本教程将向您介绍 Flow 的使用。此外,我们还将讨论 AutoML 的使用,它可以识别数据集上性能最佳的算法。您对学习 H2O 不感兴趣吗?继续阅读!
H2O - 安装
H2O 可以配置和使用以下五种不同的选项 -
在Python中安装
在 R 中安装
基于 Web 的流程 GUI
Hadoop
蟒蛇云
在我们的后续部分中,您将看到根据可用选项安装 H2O 的说明。您可能会使用其中一种选项。
在Python中安装
要使用 Python 运行 H2O,安装需要多个依赖项。那么让我们开始安装运行 H2O 的最小依赖集。
安装依赖项
要安装依赖项,请执行以下 pip 命令 -
$ pip install requests
打开控制台窗口并键入上述命令来安装 requests 包。以下屏幕截图显示了上述命令在我们的 Mac 机器上的执行情况 -

安装 requests 后,您还需要安装三个软件包,如下所示 -
$ pip install tabulate $ pip install "colorama >= 0.3.8" $ pip install future
最新的依赖项列表可在 H2O GitHub 页面上找到。在撰写本文时,页面上列出了以下依赖项。
python 2. H2O — Installation pip >= 9.0.1 setuptools colorama >= 0.3.7 future >= 0.15.2
删除旧版本
安装上述依赖项后,您需要删除任何现有的 H2O 安装。为此,请运行以下命令 -
$ pip uninstall h2o
安装最新版本
现在,让我们使用以下命令安装最新版本的 H2O -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
成功安装后,您应该在屏幕上看到以下消息 -
Installing collected packages: h2o Successfully installed h2o-3.26.0.1
测试安装
为了测试安装,我们将运行 H2O 安装中提供的示例应用程序之一。首先输入以下命令启动 Python 提示符 -
$ Python3
Python 解释器启动后,在 Python 命令提示符下键入以下 Python 语句 -
>>>import h2o
上面的命令将 H2O 包导入到您的程序中。接下来,使用以下命令初始化 H2O 系统 -
>>>h2o.init()
您的屏幕将显示集群信息,并且在此阶段应显示以下内容 -

现在,您已准备好运行示例代码。在 Python 提示符下键入以下命令并执行。
>>>h2o.demo("glm")
该演示由一个带有一系列命令的 Python 笔记本组成。执行每个命令后,其输出立即显示在屏幕上,系统会要求您按该键继续下一步。执行笔记本中最后一条语句的部分屏幕截图如下所示 -

在此阶段,您的 Python 安装已完成,您可以开始自己的实验了。
在 R 中安装
为 R 开发安装 H2O 与为 Python 安装 H2O 非常相似,只不过您将使用 R 提示符进行安装。
启动 R 控制台
单击计算机上的 R 应用程序图标启动 R 控制台。控制台屏幕将如下图所示 -

您的 H2O 安装将在上述 R 提示符下完成。如果您更喜欢使用 RStudio,请在 R 控制台子窗口中键入命令。
删除旧版本
首先,在 R 提示符下使用以下命令删除旧版本 -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
下载依赖项
使用以下代码下载 H2O 的依赖项 -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}
安装水
通过在 R 提示符下键入以下命令来安装 H2O -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))
以下屏幕截图显示了预期的输出 -

在 R 中还有另一种安装 H2O 的方法。
从 CRAN 安装在 R 中
要从 CRAN 安装 R,请在 R 提示符下使用以下命令 -
> install.packages("h2o")
您将被要求选择镜像 -
--- Please select a CRAN mirror for use in this session ---

屏幕上将显示一个显示镜像站点列表的对话框。选择最近的位置或您选择的镜子。
测试安装
在 R 提示符下,键入并运行以下代码 -
> library(h2o) > localH2O = h2o.init() > demo(h2o.kmeans)
生成的输出将如以下屏幕截图所示 -

您在 R 中的 H2O 安装现已完成。
安装 Web GUI 流程
要安装 GUI Flow,请从 H20 站点下载安装文件。将下载的文件解压缩到您的首选文件夹中。请注意安装中是否存在 h2o.jar 文件。使用以下命令在命令窗口中运行此文件 -
$ java -jar h2o.jar
一段时间后,控制台窗口中将出现以下内容。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms 07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:
要启动流程,请在浏览器中打开给定的 URL http://localhost:54321 。将出现以下屏幕 -

在此阶段,您的 Flow 安装已完成。
在 Hadoop/Anaconda 云上安装
除非您是经验丰富的开发人员,否则您不会想到在大数据上使用 H2O。在此可以说,H2O 模型可以在数 TB 的大型数据库上高效运行。如果您的数据位于 Hadoop 安装或云中,请按照 H2O 站点上给出的步骤为您各自的数据库安装它。
现在您已在计算机上成功安装并测试了 H2O,您已准备好进行真正的开发。首先,我们将从命令提示符中看到进展。在后续课程中,我们将学习如何在 H2O Flow 中进行模型测试。
在命令提示符下开发
现在让我们考虑使用 H2O 对著名的鸢尾花数据集的植物进行分类,该数据集可免费用于开发机器学习应用程序。
通过在 shell 窗口中键入以下命令来启动 Python 解释器 -
$ Python3
这将启动 Python 解释器。使用以下命令导入 h2o 平台 -
>>> import h2o
我们将使用随机森林算法进行分类。这是在 H2ORandomForestEstimator 包中提供的。我们使用 import 语句导入这个包,如下所示 -
>>> from h2o.estimators import H2ORandomForestEstimator
我们通过调用 H2o 的 init 方法来初始化 H2o 环境。
>>> h2o.init()
成功初始化后,您应该在控制台上看到以下消息以及集群信息。
Checking whether there is an H2O instance running at http://localhost:54321 . connected.
现在,我们将使用 H2O 中的 import_file 方法导入虹膜数据。
>>> data = h2o.import_file('iris.csv')
进度将显示如下屏幕截图所示 -

文件加载到内存后,您可以通过显示加载表的前 10 行来验证这一点。您可以使用head方法来执行此操作 -
>>> data.head()
您将看到以下表格格式的输出。

该表还显示列名称。我们将使用前四列作为 ML 算法的特征,最后一列类作为预测输出。我们在调用 ML 算法时通过首先创建以下两个变量来指定这一点。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] >>> output = 'class'
接下来,我们通过调用 split_frame 方法将数据拆分为训练和测试。
>>> train, test = data.split_frame(ratios = [0.8])
数据按 80:20 的比例分割。我们使用 80% 的数据进行训练,20% 的数据用于测试。
现在,我们将内置的随机森林模型加载到系统中。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
在上面的调用中,我们将树的数量设置为 50,树的最大深度设置为 20,交叉验证的折叠数设置为 10。现在我们需要训练模型。我们通过调用 train 方法来做到这一点,如下所示 -
>>> model.train(x = features, y = output, training_frame = train)
train 方法接收我们之前创建的特征和输出作为前两个参数。训练数据集被设置为训练,这是我们完整数据集的 80%。在训练期间,您将看到如下所示的进度 -
现在,随着模型构建过程的结束,是时候测试模型了。我们通过在训练后的模型对象上调用 model_performance 方法来做到这一点。
>>> performance = model.model_performance(test_data=test)
在上面的方法调用中,我们发送测试数据作为参数。
现在是时候查看输出了,这是我们模型的性能。您只需打印性能即可完成此操作。
>>> print (performance)
这将为您提供以下输出 -

输出显示均方误差 (MSE)、均方根误差 (RMSE)、LogLoss 甚至混淆矩阵。
在 Jupyter 中运行
我们已经看到了命令的执行过程,也了解了每行代码的用途。您可以在 Jupyter 环境中运行整个代码,可以逐行运行,也可以一次运行整个程序。完整的列表在这里给出 -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)
运行代码并观察输出。现在,您可以体会到在数据集上应用和测试随机森林算法是多么容易。H20的威力远远超出了这个能力。如果您想在同一数据集上尝试另一个模型,看看是否可以获得更好的性能,该怎么办?这将在我们的后续部分中进行解释。
应用不同的算法
现在,我们将学习如何将梯度提升算法应用于我们之前的数据集,看看它的表现如何。在上面的完整列表中,您只需要进行两个小的更改,如下面的代码中突出显示的那样 -
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)
运行代码,您将得到以下输出 -

只需将 MSE、RMSE、混淆矩阵等结果与之前的输出进行比较,然后决定使用哪一个进行生产部署。事实上,您可以应用多种不同的算法来决定最适合您的目的的算法。
H2O - 流量
在上一课中,您学习了使用命令行界面创建基于 H2O 的 ML 模型。H2O Flow 可以实现相同的目的,但具有基于 Web 的界面。
在接下来的课程中,我将向您展示如何启动 H2O Flow 并运行示例应用程序。
启动水流
您之前下载的 H2O 安装包含 h2o.jar 文件。要启动 H2O Flow,首先从命令提示符运行此 jar -
$ java -jar h2o.jar
当 jar 成功运行时,您将在控制台上收到以下消息 -
Open H2O Flow in your web browser: http://192.168.1.10:54321
现在,打开您选择的浏览器并输入上述 URL。您将看到 H2O 基于网络的桌面,如下所示 -
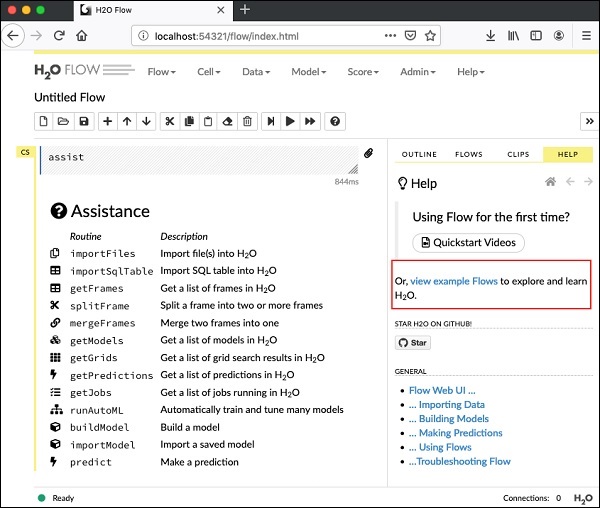
这基本上是一个类似于 Colab 或 Jupyter 的笔记本。我将向您展示如何在此笔记本中加载和运行示例应用程序,同时解释 Flow 中的各种功能。单击上面屏幕上的查看示例流程链接可查看提供的示例列表。
我将描述示例中的航空公司延误流程示例。
H2O - 运行示例应用程序
单击示例列表中的“航空公司延误流程”链接,如下面的屏幕截图所示 -

确认后,将加载新笔记本。
清除所有输出
在解释笔记本中的代码语句之前,让我们清除所有输出,然后逐步运行笔记本。要清除所有输出,请选择以下菜单选项 -
Flow / Clear All Cell Contents
这如下面的屏幕截图所示 -
清除所有输出后,我们将单独运行笔记本中的每个单元并检查其输出。
运行第一个单元格
单击第一个单元格。左侧出现红色标志,表示该单元格已被选中。如下面的屏幕截图所示 -

该单元格的内容只是用MarkDown(MD)语言编写的程序注释。内容描述了加载的应用程序的功能。要运行单元格,请单击“运行”图标,如下面的屏幕截图所示 -

您将不会在单元格下方看到任何输出,因为当前单元格中没有可执行代码。光标现在自动移动到下一个单元格,准备执行。
导入数据
下一个单元格包含以下 Python 语句 -
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
该语句将 allyears2k.csv 文件从 Amazon AWS 导入到系统中。当您运行该单元时,它会导入该文件并提供以下输出。

设置数据解析器
现在,我们需要解析数据并使其适合我们的 ML 算法。这是使用以下命令完成的 -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]
执行上述语句后,将出现一个设置配置对话框。该对话框允许您进行多种解析文件的设置。如下面的屏幕截图所示 -

在此对话框中,您可以从给定的下拉列表中选择所需的解析器并设置其他参数,例如字段分隔符等。
解析数据
下一条语句实际上使用上述配置解析数据文件,该语句很长,如下所示 -
parseFiles paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"] destination_frame: "allyears2k.hex" parse_type: "CSV" separator: 44 number_columns: 31 single_quotes: false column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime", "ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum", "ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay", "Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode", "Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay", "LateAircraftDelay","IsArrDelayed","IsDepDelayed"] column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric" ,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric", "Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum", "Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"] delete_on_done: true check_header: 1 chunk_size: 4194304
请注意,您在配置框中设置的参数已在上面的代码中列出。现在,运行这个单元格。一段时间后,解析完成,您将看到以下输出 -

检查数据框
处理后,它会生成一个数据帧,可以使用以下语句进行检查 -
getFrameSummary "allyears2k.hex"
执行上述语句后,您将看到以下输出 -

现在,您的数据已准备好输入机器学习算法。
下一条语句是程序注释,表示我们将使用回归模型并指定预设的正则化和 lambda 值。
建立模型
接下来是最重要的声明,那就是构建模型本身。这是在以下声明中指定的 -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}
我们使用 glm,它是一个广义线性模型套件,族类型设置为二项式。您可以在上面的声明中看到这些突出显示的内容。在我们的例子中,预期输出是二进制的,这就是我们使用二项式类型的原因。其他参数可自行查看;例如,看看我们之前指定的 alpha 和 lambda。有关所有参数的说明,请参阅 GLM 模型文档。
现在,运行这个语句。执行后,将生成以下输出 -

当然,在您的机器上执行时间会有所不同。现在,该示例代码中最有趣的部分来了。
检查输出
我们只需使用以下语句输出我们构建的模型 -
getModel "glm_model"
请注意,glm_model 是我们在上一条语句中构建模型时指定为 model_id 参数的模型 ID。这给了我们一个巨大的输出,详细说明了几个不同参数的结果。报告的部分输出如下面的屏幕截图所示 -

正如您在输出中看到的,它表示这是在数据集上运行广义线性建模算法的结果。
在“评分历史记录”的正上方,您会看到“模型参数”标签,将其展开,您将看到构建模型时使用的所有参数的列表。这如下面的屏幕截图所示。

同样,每个标签都提供特定类型的详细输出。自己扩展各种标签来研究不同类型的输出。
建立另一个模型
接下来,我们将在数据帧上构建深度学习模型。示例代码中的下一条语句只是程序注释。下面的语句实际上是一个模型构建命令。如下所示 -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}
正如您在上面的代码中看到的,我们指定深度学习来构建模型,并将多个参数设置为深度学习模型文档中指定的适当值。当您运行此语句时,它将比 GLM 模型构建花费更长的时间。模型构建完成后,您将看到以下输出,尽管时间不同。
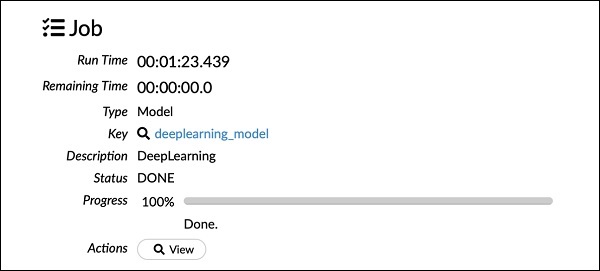
检查深度学习模型输出
这会生成某种输出,可以像前面的情况一样使用以下语句进行检查。
getModel "deeplearning_model"
我们将考虑如下所示的 ROC 曲线输出以供快速参考。

与前面的情况一样,展开各个选项卡并研究不同的输出。
保存模型
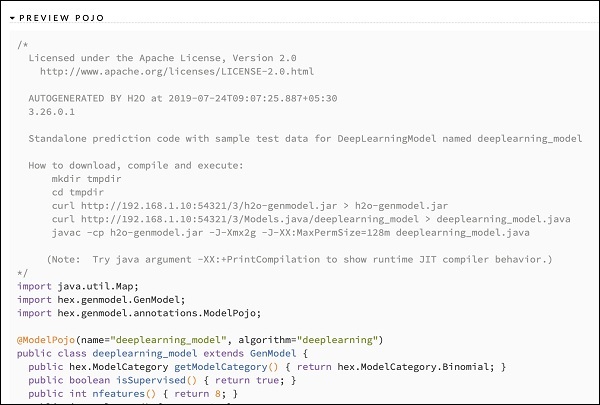
在研究了不同模型的输出后,您决定在生产环境中使用其中一种模型。H20 允许您将此模型保存为 POJO(普通旧 Java 对象)。
展开输出中的最后一个标签 PREVIEW POJO,您将看到微调模型的 Java 代码。在您的生产环境中使用它。
接下来,我们将了解 H2O 的一个非常令人兴奋的功能。我们将学习如何使用 AutoML 来测试各种算法并根据其性能对其进行排名。
H2O-AutoML
要使用 AutoML,请启动新的 Jupyter 笔记本并按照以下步骤操作。
导入 AutoML
首先使用以下两条语句将 H2O 和 AutoML 包导入到项目中 -
import h2o from h2o.automl import H2OAutoML
初始化水
使用以下语句初始化 h2o -
h2o.init()
您应该在屏幕上看到集群信息,如下面的屏幕截图所示 -

加载数据中
我们将使用您在本教程前面使用的相同的 iris.csv 数据集。使用以下语句加载数据 -
data = h2o.import_file('iris.csv')
准备数据集
我们需要决定特征和预测列。我们使用与之前的案例相同的特征和预测列。使用以下两个语句设置功能和输出列 -
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] output = 'class'
以 80:20 的比例分割数据进行训练和测试 -
train, test = data.split_frame(ratios=[0.8])
应用 AutoML
现在,我们已准备好在数据集上应用 AutoML。AutoML 将运行我们设置的固定时间,并为我们提供优化的模型。我们使用以下语句设置 AutoML -
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)
第一个参数指定我们要评估和比较的模型的数量。
第二个参数指定算法运行的时间。
我们现在调用 AutoML 对象上的 train 方法,如下所示 -
aml.train(x = features, y = output, training_frame = train)
我们将 x 指定为之前创建的特征数组,将 y 指定为输出变量以指示预测值,将数据帧指定为训练数据集。
运行代码,您必须等待 5 分钟(我们将 max_runtime_secs 设置为 300),直到获得以下输出 -

打印排行榜
AutoML 处理完成后,它会创建一个排行榜,对它评估过的所有 30 种算法进行排名。要查看排行榜的前 10 条记录,请使用以下代码 -
lb = aml.leaderboard lb.head()
执行后,上述代码将生成以下输出 -

显然,DeepLearning 算法获得了最高分。
根据测试数据进行预测
现在,您已经对模型进行了排名,您可以在测试数据上查看排名最高的模型的性能。为此,请运行以下代码语句 -
preds = aml.predict(test)
处理会持续一段时间,完成后您将看到以下输出。

打印结果
使用以下语句打印预测结果 -
print (preds)
执行上述语句后,您将看到以下结果 -

打印所有人的排名
如果您想查看所有测试算法的排名,请运行以下代码语句 -
lb.head(rows = lb.nrows)
执行上述语句后,将生成以下输出(部分显示) -
结论
H2O 提供了一个易于使用的开源平台,用于在给定数据集上应用不同的 ML 算法。它提供了多种统计和机器学习算法,包括深度学习。在测试过程中,您可以微调这些算法的参数。您可以使用命令行或提供的名为 Flow 的基于 Web 的界面来执行此操作。H2O 还支持 AutoML,它可以根据性能对多种算法进行排名。H2O 在大数据方面也表现出色。对于数据科学家来说,这绝对是一个福音,可以在他们的数据集上应用不同的机器学习模型,并选择最好的模型来满足他们的需求。