- KNIME Tutorial
- KNIME - Home
- KNIME - Introduction
- KNIME - Installation
- KNIME - First Run
- KNIME - Workbench
- KNIME - Running Your First Workflow
- KNIME - Exploring Workflow
- KNIME - Building Your Own Model
- KNIME - Testing the Model
- KNIME - Summary and Future Work
- KNIME Useful Resources
- KNIME - Quick Guide
- KNIME - Useful Resources
- KNIME - Discussion
KNIME - 快速指南
KNIME - 简介
由于其神秘的性质,开发机器学习模型始终被认为非常具有挑战性。一般来说,要开发机器学习应用程序,您必须是一名优秀的开发人员,具有命令驱动开发的专业知识。KNIME 的引入使机器学习模型的开发进入了普通人的视野。
KNIME为整个开发提供了图形界面(用户友好的GUI)。在 KNIME 中,您只需定义其存储库中提供的各种预定义节点之间的工作流程。KNIME 提供了几个称为节点的预定义组件,用于执行各种任务,例如读取数据、应用各种 ML 算法以及以各种格式可视化数据。因此,使用 KNIME 不需要任何编程知识。这不是很令人兴奋吗?
本教程接下来的章节将教您如何使用几种经过充分测试的机器学习算法来掌握数据分析。
KNIME - 安装
KNIME 分析平台适用于 Windows、Linux 和 MacOS。在本章中,我们将了解在 Mac 上安装平台的步骤。如果您使用 Windows 或 Linux,只需按照 KNIME 下载页面上给出的安装说明进行操作即可。所有三个平台的二进制安装都可以在KNIME 页面上找到。
Mac安装
从 KNIME 官方网站下载二进制安装。双击下载的dmg文件开始安装。安装完成后,只需将 KNIME 图标拖到“应用程序”文件夹中,如下所示 -


KNIME - 第一次运行
双击 KNIME 图标启动 KNIME 分析平台。最初,系统会要求您设置一个工作区文件夹来保存您的工作。您的屏幕将如下所示 -
您可以将所选文件夹设置为默认文件夹,下次启动 KNIME 时,它不会

再次显示此对话框。
稍后,KNIME 平台将在您的桌面上启动。这是您进行分析工作的工作台。现在让我们看看工作台的各个部分。
KNIME - 工作台
当 KNIME 启动时,您将看到以下屏幕 -

正如屏幕截图中所标记的,工作台由多个视图组成。对我们立即有用的视图已在屏幕截图中标记并列出如下 -
工作空间
大纲
节点存储库
KNIME 探索者
安慰
描述
当我们继续本章的内容时,让我们详细了解这些观点。
工作区视图
对我们来说最重要的视图是工作区视图。您可以在此处创建机器学习模型。工作区视图在下面的屏幕截图中突出显示 -

屏幕截图显示了打开的工作区。您很快就会了解如何打开现有工作区。
每个工作区包含一个或多个节点。您将在本教程后面了解这些节点的重要性。节点使用箭头连接。通常,程序流程是从左到右定义的,但这不是必需的。您可以在工作区中的任何位置自由移动每个节点。两者之间的连接线会适当移动,以维持节点之间的连接。您可以随时添加/删除节点之间的连接。对于每个节点,可以选择添加一个小的描述。
轮廓视图
工作区视图可能无法一次向您显示整个工作流程。这就是提供轮廓视图的原因。

轮廓视图显示整个工作区的微型视图。该视图内有一个缩放窗口,您可以滑动该窗口以在工作区视图中查看工作流程的不同部分。
节点存储库
这是工作台中的下一个重要视图。节点存储库列出了可用于分析的各种节点。整个存储库根据节点功能进行了很好的分类。您会发现以下类别 -
IO
意见
分析

在每个类别下,您都会找到几个选项。只需展开每个类别视图即可查看其中的内容。在IO类别下,您将找到用于读取各种文件格式数据的节点,例如 ARFF、CSV、PMML、XLS 等。

根据您的输入源数据格式,您将选择适当的节点来读取数据集。
此时,您可能已经了解节点的用途了。节点定义了某种功能,您可以直观地将其包含在工作流程中。
Analytics 节点定义了各种机器学习算法,例如贝叶斯、聚类、决策树、集成学习等。

这些节点中提供了这些各种 ML 算法的实现。要在分析中应用任何算法,只需从存储库中选择所需的节点并将其添加到您的工作区即可。将数据读取器节点的输出连接到该 ML 节点的输入,然后创建您的工作流程。
我们建议您探索存储库中可用的各种节点。
KNIME 探索者
工作台中的下一个重要视图是资源管理器视图,如下面的屏幕截图所示 -

前两个类别列出了 KNIME 服务器上定义的工作区。第三个选项 LOCAL 用于存储您在本地计算机上创建的所有工作区。尝试展开这些选项卡以查看各种预定义的工作区。特别是,展开示例选项卡。

KNIME 提供了几个示例来帮助您开始使用该平台。在下一章中,您将使用其中一个示例来熟悉该平台。
控制台视图
顾名思义,控制台视图提供执行工作流时各种控制台消息的视图。

控制台视图对于诊断工作流程和检查分析结果非常有用。
描述视图
与我们直接相关的最后一个重要视图是“描述”视图。此视图提供工作区中所选项目的描述。典型的视图如下面的屏幕截图所示 -

上图显示了文件读取器节点的描述。当您在工作区中选择“文件读取器”节点时,您将在此视图中看到其描述。单击任何其他节点将显示所选节点的描述。因此,当您不准确了解工作区和/或节点存储库中各个节点的用途时,此视图在学习的初始阶段变得非常有用。
工具栏
除了上述视图外,工作台还有其他视图,例如工具栏。工具栏包含有助于快速操作的各种图标。根据上下文启用/禁用图标。您可以通过将鼠标悬停在每个图标上来查看每个图标执行的操作。以下屏幕显示“配置”图标所采取的操作。

启用/禁用视图
到目前为止您所看到的各种视图都可以轻松打开/关闭。单击视图中的关闭图标将关闭视图。要恢复视图,请转至“视图”菜单选项并选择所需的视图。选定的视图将添加到工作台中。

现在,您已经熟悉了工作台,我将向您展示如何运行工作流程并研究其执行的分析。
KNIME - 运行您的第一个工作流程
KNIME 提供了几个很好的工作流程以方便学习。在本章中,我们将选择安装中提供的工作流程之一来解释分析平台的各种功能和强大功能。我们将使用基于决策树的简单分类器进行研究。
加载决策树分类器
在 KNIME Explorer 中找到以下工作流程 -
本地 / 示例工作流程 / 基本示例 / 构建简单的分类器
下面的屏幕截图也显示了这一点,供您快速参考 -
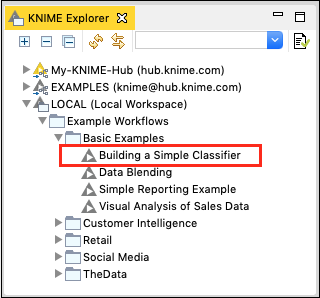
双击所选项目以打开工作流程。观察工作区视图。您将看到包含多个节点的工作流程。此工作流程的目的是根据 UCI 机器学习存储库中的成人数据集的民主属性来预测收入群体。该 ML 模型的任务是将特定地区的人分类为收入大于或小于 50K 的人。
工作区视图及其轮廓如下面的屏幕截图所示 -
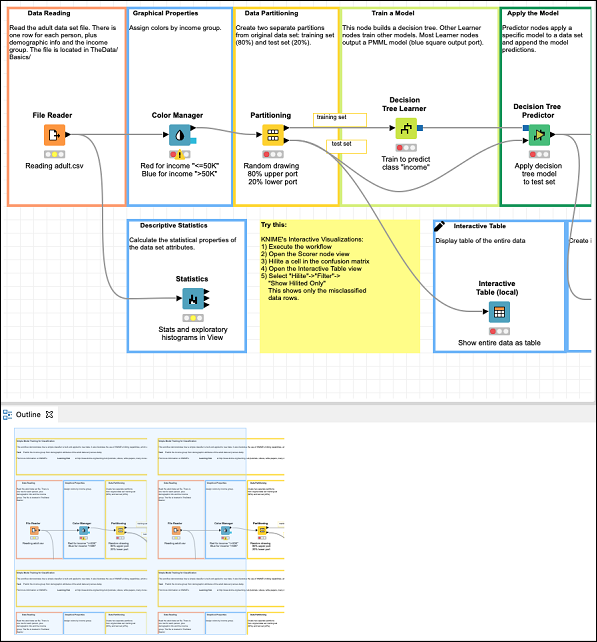
请注意,存在从节点存储库中选取的多个节点,并通过箭头在工作流中连接。连接表示一个节点的输出被馈送到下一个节点的输入。在了解工作流中每个节点的功能之前,让我们首先执行整个工作流。
执行工作流程
在我们研究工作流的执行之前,了解每个节点的状态报告非常重要。检查工作流中的任何节点。在每个节点的底部,您会发现一个包含三个圆圈的状态指示器。决策树学习器节点如下面的屏幕截图所示 -
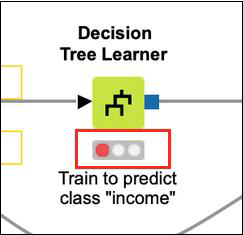
状态指示灯为红色,表示该节点到目前为止尚未执行。执行过程中,中心黄色圆圈会亮起。成功执行后,最后一个圆圈会变成绿色。有更多指示器可以在出现错误时为您提供状态信息。当处理过程中发生错误时您将了解到它们。
需要注意的是,目前所有节点上的指示灯都是红色的,表示目前还没有节点被执行。要运行所有节点,请单击以下菜单项 -
节点→执行全部
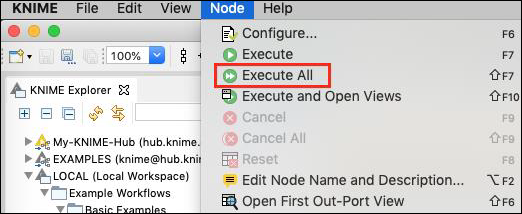
过了一会儿,你会发现各个节点的状态指示灯现在都变成了绿色,表示没有错误。
在下一章中,我们将探讨工作流中各个节点的功能。
KNIME - 探索工作流程
如果您检查工作流程中的节点,您可以看到它包含以下内容 -
文件阅读器,
色彩管理器
分区
决策树学习器
决策树预测器
分数
互动桌
散点图
统计数据
这些可以在大纲视图中轻松看到,如下所示 -

每个节点都提供工作流中的特定功能。我们现在将研究如何配置这些节点以满足所需的功能。请注意,我们将仅讨论在当前探索工作流程的上下文中与我们相关的节点。
文件阅读器
文件读取器节点如下面的屏幕截图所示 -

窗口顶部有一些由工作流创建者提供的描述。它告诉这个节点读取成人数据集。从节点符号下方的描述可以看出,该文件的名称为Adult.csv 。文件读取器有两个输出 - 一个输出到颜色管理器节点,另一个输出到统计节点。
如果右键单击文件管理器,将显示一个弹出菜单,如下所示 -

配置菜单选项允许进行节点配置。执行菜单运行节点。请注意,如果节点已经运行并且处于绿色状态,则此菜单将被禁用。另请注意“编辑注释描述”菜单选项的存在。这允许您编写节点的描述。
现在,选择“配置”菜单选项,它显示包含成人.csv 文件中的数据的屏幕,如屏幕截图所示 -

当执行该节点时,数据将被加载到内存中。整个数据加载程序代码对用户是隐藏的。您现在可以体会到此类节点的有用性 - 无需编码。
我们的下一个节点是颜色管理器。
色彩管理器
选择颜色管理器节点并右键单击它进入其配置。将出现一个颜色设置对话框。从下拉列表中选择收入列。
您的屏幕将如下所示 -

请注意两个约束的存在。如果收入小于 50K,则数据点将变为绿色,如果大于,则变为红色。当我们在本章后面查看散点图时,您将看到数据点映射。
分区
在机器学习中,我们通常将整个可用数据分为两部分。较大的部分用于训练模型,而较小的部分用于测试。有不同的策略用于对数据进行分区。
要定义所需的分区,请右键单击“分区”节点并选择“配置”选项。您将看到以下屏幕 -

在本例中,系统建模者使用了相对(%) 模式,并且数据按 80:20 的比例进行分割。在进行分割时,数据点是随机选取的。这可以确保您的测试数据不会有偏差。在线性采样的情况下,用于测试的剩余 20% 数据可能无法正确代表训练数据,因为它在收集过程中可能完全有偏差。
如果确定数据采集时能够保证随机性,那么可以选择线性抽样。一旦您的数据准备好用于训练模型,请将其提供给下一个节点,即决策树学习器。
决策树学习器
顾名思义,决策树学习器节点使用训练数据并构建模型。查看该节点的配置设置,如下面的屏幕截图所示 -

如您所见,班级是收入。因此,树将根据收入列构建,这就是我们在该模型中试图实现的目标。我们希望将收入高于或低于 5 万的人分开。
该节点成功运行后,您的模型就可以进行测试了。
决策树预测器
决策树预测器节点将开发的模型应用于测试数据集并附加模型预测。

预测器的输出被馈送到两个不同的节点 - Scorer和Scatter Plot。接下来,我们将检查预测的输出。
得分手
该节点生成混淆矩阵。要查看它,请右键单击该节点。您将看到以下弹出菜单 -

单击“视图:混淆矩阵”菜单选项,矩阵将在单独的窗口中弹出,如屏幕截图所示 -

这表明我们开发的模型的准确率为 83.71%。如果您对此不满意,您可以在模型构建中尝试其他参数,特别是您可能想重新访问和清理您的数据。
散点图
要查看数据分布的散点图,请右键单击“散点图”节点,然后选择菜单选项“交互式视图:散点图”。您将看到以下Plotly -

该图以两个不同颜色的点(红色和蓝色)给出了基于 50K 阈值的不同收入群体的分布。这些是我们的颜色管理器节点中设置的颜色。该分布与 x 轴上绘制的年龄相关。您可以通过更改节点的配置来为 x 轴选择不同的功能。
此处显示配置对话框,其中我们选择婚姻状况作为 x 轴的特征。

我们对 KNIME 提供的预定义模型的讨论到此结束。我们建议您自学模型中的另外两个节点(统计和交互表)。
现在让我们继续本教程最重要的部分 - 创建您自己的模型。
KNIME - 构建您自己的模型
在本章中,您将构建自己的机器学习模型,以根据一些观察到的特征对植物进行分类。为此,我们将使用UCI 机器学习存储库中著名的iris数据集。该数据集包含三种不同类别的植物。我们将训练我们的模型将未知植物分类为这三个类别之一。
我们将首先在 KNIME 中创建一个新的工作流程来创建我们的机器学习模型。
创建工作流程
要创建新工作流程,请在 KNIME 工作台中选择以下菜单选项。
文件 → 新建
您将看到以下屏幕 -

选择“新建 KNIME 工作流程”选项,然后单击“下一步”按钮。在下一个屏幕上,系统将要求您输入所需的工作流程名称以及保存它的目标文件夹。根据需要输入此信息,然后单击“完成”以创建新工作区。
具有给定名称的新工作区将添加到工作区视图中,如下所示 -

现在,您将在此工作区中添加各种节点来创建模型。在添加节点之前,您必须下载并准备iris数据集供我们使用。
准备数据集
从 UCI 机器学习存储库网站 下载 iris 数据集下载 iris 数据集。下载的 iris.data 文件为 CSV 格式。我们将对其进行一些更改以添加列名称。
在您喜欢的文本编辑器中打开下载的文件,并在开头添加以下行。
萼片长度、花瓣长度、萼片宽度、花瓣宽度、类别
当我们的文件读取器节点读取该文件时,它会自动将上述字段作为列名。
现在,您将开始添加各种节点。
添加文件阅读器
转到节点存储库视图,在搜索框中键入“file”以找到文件读取器节点。这可以在下面的屏幕截图中看到 -

选择并双击文件读取器以将节点添加到工作区中。或者,您可以使用拖放功能将节点添加到工作区中。添加节点后,您必须对其进行配置。右键单击该节点并选择“配置”菜单选项。您在前面的课程中已经完成了此操作。
加载数据文件后,设置屏幕如下所示。

要加载数据集,请单击“浏览”按钮并选择 iris.data 文件的位置。该节点将加载显示在配置框下部的文件内容。一旦您对数据文件的正确定位和加载感到满意,请单击“确定”按钮关闭配置对话框。
您现在将向该节点添加一些注释。右键单击该节点并选择“新建工作流注释”菜单选项。屏幕上会出现一个注释框,如屏幕截图所示:

单击框内并添加以下注释 -
读取 iris.data
单击框外的任意位置可退出编辑模式。根据需要调整框的大小并将其放置在节点周围。最后,双击节点下方的节点 1文本,将此字符串更改为以下内容 -
加载数据
此时,您的屏幕将如下所示 -

我们现在将添加一个新节点,用于将加载的数据集划分为训练和测试。
添加分区节点
在节点存储库搜索窗口中,键入几个字符来找到分区节点,如下面的屏幕截图所示 -

将节点添加到我们的工作区。设置其配置如下 -
相对(%):95 随机抽取
以下屏幕截图显示了配置参数。

接下来,在两个节点之间建立连接。为此,单击“文件读取器”节点的输出,按住鼠标按钮,会出现一条橡皮筋线,将其拖动到“分区”节点的输入,释放鼠标按钮。现在两个节点之间已建立连接。
添加注释、更改描述、根据需要定位节点和注释视图。在此阶段,您的屏幕应如下所示 -

接下来,我们将添加k-Means节点。
添加 k-Means 节点
从存储库中选择k-Means节点并将其添加到工作区。如果您想刷新有关 k-Means 算法的知识,只需在工作台的描述视图中查找其描述即可。这如下面的屏幕截图所示 -

顺便说一句,您可以在描述窗口中查找不同算法的描述,然后再决定使用哪种算法。
打开节点的配置对话框。我们将使用所有字段的默认值,如下所示 -

单击“确定”接受默认值并关闭对话框。
将注释和描述设置为以下内容 -
注释:对簇进行分类
描述:执行聚类
将Partitioning节点的顶部输出连接到k-Means节点的输入。重新放置您的项目,您的屏幕应如下所示 -

接下来,我们将添加一个集群分配器节点。
添加集群分配器
集群分配器将新数据分配给现有的一组原型。它需要两个输入 - 原型模型和包含输入数据的数据表。在描述窗口中查找节点的描述,如下面的屏幕截图所示 -

因此,对于这个节点,您必须建立两个连接 -
分区节点的 PMML 集群模型输出→集群分配器的原型输入
Partitioning节点的第二个分区输出→ Cluster分配器的输入数据
这两个连接如下面的屏幕截图所示 -

集群分配器不需要任何特殊配置。只需接受默认值即可。
现在,向该节点添加一些注释和描述。重新排列您的节点。您的屏幕应如下所示 -

至此,我们的聚类就完成了。我们需要以图形方式可视化输出。为此,我们将添加散点图。我们将在散点图中为三个类设置不同的颜色和形状。因此,我们将首先通过颜色管理器节点,然后通过形状管理器节点过滤k-Means节点的输出。
添加色彩管理器
在存储库中找到颜色管理器节点。将其添加到工作区。将配置保留为默认值。请注意,您必须打开配置对话框并单击“确定”以接受默认值。设置节点的描述文本。
将k-Means的输出连接到Color Manager的输入。在此阶段,您的屏幕将如下所示 -

添加形状管理器
在存储库中找到形状管理器并将其添加到工作区。将其配置保留为默认值。与前一个一样,您必须打开配置对话框并单击“确定”以设置默认值。建立从颜色管理器的输出到形状管理器的输入的连接。设置节点的描述。
您的屏幕应如下所示 -

现在,您将在模型中添加最后一个节点,即散点图。
添加散点图
在存储库中找到散点图节点并将其添加到工作区。将Shape Manager的输出连接到Scatter Plot的输入。将配置保留为默认值。设置描述。
最后为最近添加的三个节点添加组注释
注释:可视化
根据需要重新定位节点。在此阶段,您的屏幕应如下所示。

这样就完成了模型构建的任务。
KNIME - 测试模型
要测试模型,请执行以下菜单选项:节点→执行全部
如果一切顺利,每个节点底部的状态信号将变成绿色。如果没有,您将需要在控制台视图中查找错误,修复它们并重新运行工作流程。
现在,您已准备好可视化模型的预测输出。为此,右键单击散点图节点并选择以下菜单选项:交互式视图:散点图
这如下面的屏幕截图所示 -

您将在屏幕上看到散点图,如下所示 -

您可以通过更改 x 轴和 y 轴来运行不同的可视化效果。为此,请单击散点图右上角的设置菜单。将出现一个弹出菜单,如下面的屏幕截图所示 -

您可以在此屏幕上设置绘图的各种参数,以从多个方面可视化数据。
这样就完成了我们的模型构建任务。
KNIME - 总结和未来的工作
KNIME 提供了用于构建机器学习模型的图形工具。在本教程中,您学习了如何在计算机上下载并安装 KNIME。
概括
您了解了 KNIME 工作台中提供的各种视图。KNIME 为您的学习提供了几个预定义的工作流程。我们使用这样的工作流程来了解 KNIME 的功能。KNIME 提供了多个预编程节点,用于读取各种格式的数据、使用多种 ML 算法分析数据,并最终以多种不同的方式可视化数据。在本教程即将结束时,您从头开始创建了自己的模型。我们使用著名的鸢尾花数据集,通过 k-Means 算法对植物进行分类。
您现在已准备好将这些技术用于您自己的分析。
未来的工作
如果您是一名开发人员并且希望在您的编程应用程序中使用 KNIME 组件,您会很高兴知道 KNIME 与多种编程语言(例如 Java、R、Python 等)本机集成。