- Teradata 教程
- Teradata - 主页
- Teradata 基础知识
- Teradata - 简介
- Teradata - 安装
- Teradata - 架构
- Teradata - 关系概念
- Teradata - 数据类型
- Teradata - 表
- Teradata - 数据操作
- Teradata - SELECT 语句
- 逻辑和条件运算符
- Teradata - SET 运算符
- Teradata - 字符串操作
- Teradata - 日期/时间函数
- Teradata - 内置函数
- Teradata - 聚合函数
- Teradata - 案例与合并
- Teradata - 主索引
- Teradata - 加入
- Teradata - 子查询
- Teradata 高级版
- Teradata - 表类型
- Teradata - 空间概念
- Teradata - 二级索引
- Teradata - 统计
- Teradata - 压缩
- Teradata - 解释
- Teradata - 哈希算法
- Teradata - 连接索引
- Teradata - 视图
- Teradata - 宏
- Teradata - 存储过程
- Teradata - 加入策略
- Teradata - 分区主索引
- Teradata - OLAP 函数
- Teradata - 数据保护
- Teradata - 用户管理
- Teradata - 性能调优
- Teradata - 快速加载
- Teradata - 多负载
- Teradata - 快速导出
- Teradata-BTEQ
- Teradata 有用资源
- Teradata - 问题与解答
- Teradata - 快速指南
- Teradata - 有用的资源
- Teradata - 讨论
Teradata - 快速指南
Teradata - 简介
什么是 Teradata?
Teradata 是流行的关系数据库管理系统之一。它主要适合构建大规模数据仓库应用程序。Teradata 通过并行性概念实现了这一点。它是由 Teradata 公司开发的。
Teradata 的历史
以下是 Teradata 历史的快速摘要,列出了主要里程碑。
1979 年- Teradata 成立。
1984 – 发布第一台数据库计算机 DBC/1012。
1986 年- 《财富》杂志将 Teradata 评为“年度产品”。
1999 - 使用 Teradata 的世界上最大的数据库,容量为 130 TB。
2002 - Teradata V2R5 发布,带有分区主索引和压缩。
2006 年- 推出 Teradata 主数据管理解决方案。
2008 年- Teradata 13.0 与 Active Data Warehousing 一起发布。
2011 - 收购 Teradata Aster 并进入高级分析领域。
2012 年- 推出 Teradata 14.0。
2014 年- 推出 Teradata 15.0。
Teradata 的特点
以下是 Teradata 的一些功能 -
无限并行性- Teradata 数据库系统基于大规模并行处理 (MPP) 架构。MPP 架构将工作负载平均分配到整个系统。Teradata系统将任务拆分到多个进程中并并行运行,以确保任务快速完成。
Shared Nothing 架构- Teradata 的架构称为 Shared Nothing 架构。Teradata 节点、其访问模块处理器 (AMP) 以及与 AMP 关联的磁盘独立工作。它们不与他人共享。
线性可扩展性- Teradata 系统具有高度可扩展性。它们最多可以扩展到 2048 个节点。例如,您可以通过将 AMP 数量加倍来使系统容量加倍。
连接性- Teradata 可以连接到通道附加系统,例如大型机或网络附加系统。
成熟的优化器- Teradata 优化器是市场上成熟的优化器之一。它从一开始就被设计为并行的。它针对每个版本都进行了改进。
SQL - Teradata 支持行业标准 SQL 与表中存储的数据进行交互。除此之外,它还提供了自己的扩展。
强大的实用程序- Teradata 提供强大的实用程序,用于从 Teradata 系统导入/导出数据,例如 FastLoad、MultiLoad、FastExport 和 TPT。
自动分配- Teradata 自动将数据均匀分配到磁盘,无需任何手动干预。
Teradata - 安装
Teradata 为 VMWARE 提供 Teradata Express,这是一个完全可操作的 Teradata 虚拟机。它提供高达 1 TB 的存储空间。Teradata 提供 40GB 和 1TB 版本的 VMware。
先决条件
由于VM是64位的,因此您的CPU必须支持64位。
Windows 的安装步骤
步骤 1 - 从链接下载所需的 VM 版本:https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
步骤 2 - 提取文件并指定目标文件夹。
步骤 3 - 从链接下载 VMWare Workstation 播放器:https://my.vmware.com/web/vmware/downloads。它适用于 Windows 和 Linux。下载适用于 Windows 的 VMWARE 工作站播放器。

步骤 4 - 下载完成后,安装软件。
步骤 5 - 安装完成后,运行 VMWARE 客户端。
步骤 6 - 选择“打开虚拟机”。浏览提取的 Teradata VMWare 文件夹并选择扩展名为 .vmdk 的文件。

步骤 7 - Teradata VMWare 已添加到 VMWare 客户端。选择添加的 Teradata VMware,然后单击“播放虚拟机”。

步骤 8 - 如果您收到有关软件更新的弹出窗口,您可以选择“稍后提醒我”。
步骤 9 - 输入 root 用户名,按 Tab 键并输入 root 密码,然后再次按 Enter 键。

步骤 10 - 桌面上出现以下屏幕后,双击“root's home”。然后双击“基因组终端”。这将打开外壳。

步骤 11 - 从以下 shell 中输入命令 /etc/init.d/tpa start。这将启动 Teradata 服务器。

启动 BTEQ
BTEQ 实用程序用于交互式提交 SQL 查询。以下是启动 BTEQ 实用程序的步骤。
步骤 1 - 输入命令 /sbin/ifconfig 并记下 VMWare 的 IP 地址。
步骤 2 - 运行命令 bteq。在登录提示符处输入命令。
登录<ip地址>/dbc,dbc; 并输入 在密码提示符下,输入密码为 dbc;
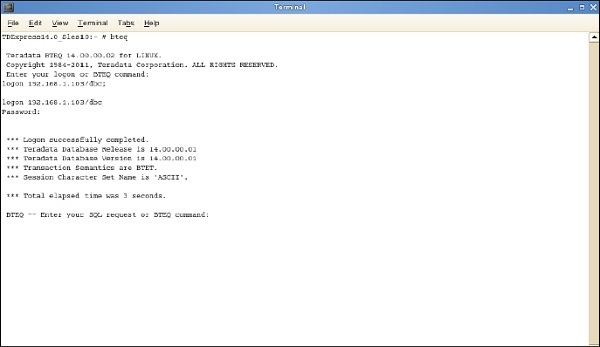
您可以使用 BTEQ 登录 Teradata 系统并运行任何 SQL 查询。
Teradata - 架构
Teradata 架构基于大规模并行处理 (MPP) 架构。Teradata 的主要组件是解析引擎、BYNET 和访问模块处理器 (AMP)。下图显示了 Teradata 节点的高级架构。

Teradata 的组件
Teradata 的关键组件如下 -
节点- 它是 Teradata 系统中的基本单元。Teradata 系统中的每个单独的服务器称为一个节点。节点由自己的操作系统、CPU、内存、自己的 Teradata RDBMS 软件副本和磁盘空间组成。一个机柜由一个或多个节点组成。
解析引擎- 解析引擎负责接收来自客户端的查询并准备有效的执行计划。解析引擎的职责是 -
接收客户端的SQL查询
解析 SQL 查询检查语法错误
检查用户是否对 SQL 查询中使用的对象具有所需的权限
检查SQL中使用的对象是否确实存在
准备执行计划来执行SQL查询并将其传递给BYNET
接收来自 AMP 的结果并发送给客户端
消息传递层- 消息传递层称为 BYNET,是 Teradata 系统中的网络层。它允许 PE 和 AMP 之间以及节点之间的通信。它从解析引擎接收执行计划并发送给AMP。同样,它从 AMP 接收结果并将其发送到解析引擎。
访问模块处理器 (AMP) - AMP,称为虚拟处理器 (vproc),是实际存储和检索数据的处理器。AMP 从解析引擎接收数据和执行计划,执行任何数据类型转换、聚合、过滤、排序并将数据存储在与其关联的磁盘中。表中的记录均匀分布在系统中的 AMP 之间。每个 AMP 都与一组存储数据的磁盘相关联。只有 AMP 可以从磁盘读取/写入数据。
存储架构
当客户端运行查询插入记录时,解析引擎将记录发送到 BYNET。BYNET 检索记录并将行发送到目标 AMP。AMP 将这些记录存储在其磁盘上。下图展示了 Teradata 的存储架构。

检索架构
当客户端运行查询来检索记录时,解析引擎会向 BYNET 发送请求。BYNET 将检索请求发送到适当的 AMP。然后 AMP 并行搜索其磁盘并识别所需的记录并将其发送到 BYNET。然后,BYNET 将记录发送到解析引擎,解析引擎又将发送到客户端。以下是 Teradata 的检索架构。

Teradata - 关系概念
关系数据库管理系统(RDBMS)是一种有助于与数据库交互的 DBMS 软件。他们使用结构化查询语言(SQL)与表中存储的数据进行交互。
数据库
数据库是逻辑上相关的数据的集合。许多用户出于不同目的访问它们。例如,销售数据库包含存储在许多表中的有关销售的完整信息。
表格
表是 RDBMS 中存储数据的基本单位。表是行和列的集合。以下是员工表的示例。
| 员工号 | 名 | 姓 | 出生日期 |
|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 1980年1月5日 |
| 104 | 亚历克斯 | 斯图尔特 | 1984年11月6日 |
| 102 | 罗伯特 | 威廉斯 | 1983年3月5日 |
| 105 | 罗伯特 | 詹姆士 | 1984年12月1日 |
| 103 | 彼得 | 保罗 | 1983年4月1日 |
列
一列包含相似的数据。例如,Employee表中的BirthDate列包含所有员工的birth_date信息。
| 出生日期 |
|---|
| 1980年1月5日 |
| 1984年11月6日 |
| 1983年3月5日 |
| 1984年12月1日 |
| 1983年4月1日 |
排
行是所有列的一个实例。例如,在员工表中,一行包含单个员工的信息。
| 员工号 | 名 | 姓 | 出生日期 |
|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 1980年1月5日 |
首要的关键
主键用于唯一标识表中的行。主键列中不允许有重复值,并且不能接受 NULL 值。它是表中的必填字段。
外键
外键用于建立表之间的关系。子表中的外键被定义为父表中的主键。一张表可以有多个外键。它可以接受重复值,也可以接受空值。外键在表中是可选的。
Teradata - 数据类型
表中的每一列都与一种数据类型相关联。数据类型指定列中将存储哪种类型的值。Teradata 支持多种数据类型。以下是一些常用的数据类型。
| 数据类型 | 长度(字节) | 数值范围 |
|---|---|---|
| 字节整数 | 1 | -128 至 +127 |
| 小智 | 2 | -32768 至 +32767 |
| 整数 | 4 | -2,147,483,648 至 +2147,483,647 |
| BIGINT | 8 | -9,233,372,036,854,775,80 8 至 +9,233,372,036,854,775,8 07 |
| 十进制 | 1-16 | |
| 数字 | 1-16 | |
| 漂浮 | 8 | IEEE 格式 |
| 字符 | 固定格式 | 1-64,000 |
| VARCHAR | 多变的 | 1-64,000 |
| 日期 | 4 | 年年年月日 |
| 时间 | 6 或 8 | HHMMSS.nnnnnn或HHMMSS.nnnnnn+HHMM |
| 时间戳 | 10 或 12 | YYMMDDHHMMSS.nnnnnn或YYMMDDHHMMSS.nnnnnn +HHMM |
Teradata - 表
关系模型中的表被定义为数据的集合。它们表示为行和列。
表格类型
类型 Teradata 支持不同类型的表。
永久表- 这是默认表,它包含用户插入的数据并永久存储数据。
易失性表- 插入易失性表的数据仅在用户会话期间保留。表和数据在会话结束时被删除。这些表主要用于保存数据转换过程中的中间数据。
全局临时表- 全局临时表的定义是持久的,但表中的数据在用户会话结束时被删除。
派生表- 派生表保存查询中的中间结果。它们的生命周期是在创建、使用和删除它们的查询内。
集合与多重集
Teradata 根据重复记录的处理方式将表分类为 SET 或 MULTISET 表。定义为 SET 表的表不存储重复记录,而 MULTISET 表可以存储重复记录。
| 先生编号 | 表命令和说明 |
|---|---|
| 1 | 创建表
CREATE TABLE 命令用于在 Teradata 中创建表。 |
| 2 | 修改表
ALTER TABLE 命令用于在现有表中添加或删除列。 |
| 3 | 掉落表
DROP TABLE 命令用于删除表。 |
Teradata - 数据操作
本章介绍用于操作 Teradata 表中存储的数据的 SQL 命令。
插入记录
INSERT INTO 语句用于向表中插入记录。
句法
以下是 INSERT INTO 的通用语法。
INSERT INTO <tablename> (column1, column2, column3,…) VALUES (value1, value2, value3 …);
例子
以下示例将记录插入到员工表中。
INSERT INTO Employee ( EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo ) VALUES ( 101, 'Mike', 'James', '1980-01-05', '2005-03-27', 01 );
插入上述查询后,您可以使用 SELECT 语句查看表中的记录。
| 员工号 | 名 | 姓 | 加入日期 | 部门编号 | 出生日期 |
|---|---|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 2005年3月27日 | 1 | 1980年1月5日 |
从另一个表插入
INSERT SELECT 语句用于从另一个表插入记录。
句法
以下是 INSERT INTO 的通用语法。
INSERT INTO <tablename> (column1, column2, column3,…) SELECT column1, column2, column3… FROM <source table>;
例子
以下示例将记录插入到员工表中。在运行以下插入查询之前,创建一个名为 Employee_Bkup 的表,其列定义与员工表相同。
INSERT INTO Employee_Bkup ( EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo ) SELECT EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo FROM Employee;
当执行上述查询时,它将把employee表中的所有记录插入到employee_bkup表中。
规则
VALUES 列表中指定的列数应与 INSERT INTO 子句中指定的列数匹配。
NOT NULL 列的值是必需的。
如果未指定值,则将为可为空的字段插入 NULL。
VALUES 子句中指定的列的数据类型应与 INSERT 子句中的列的数据类型兼容。
更新记录
UPDATE 语句用于更新表中的记录。
句法
以下是 UPDATE 的通用语法。
UPDATE <tablename> SET <columnnamme> = <new value> [WHERE condition];
例子
以下示例将员工 101 的员工部门更新为 03。
UPDATE Employee SET DepartmentNo = 03 WHERE EmployeeNo = 101;
在以下输出中,您可以看到 EmployeeNo 101 的 DepartmentNo 从 1 更新为 3。
SELECT Employeeno, DepartmentNo FROM Employee; *** Query completed. One row found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo DepartmentNo ----------- ------------- 101 3
规则
您可以更新表中的一个或多个值。
如果未指定 WHERE 条件,则表的所有行都会受到影响。
您可以使用另一个表中的值更新一个表。
删除记录
DELETE FROM 语句用于更新表中的记录。
句法
以下是 DELETE FROM 的通用语法。
DELETE FROM <tablename> [WHERE condition];
例子
以下示例从表employee 中删除雇员101。
DELETE FROM Employee WHERE EmployeeNo = 101;
在以下输出中,您可以看到员工 101 已从表中删除。
SELECT EmployeeNo FROM Employee; *** Query completed. No rows found. *** Total elapsed time was 1 second.
规则
您可以更新表的一条或多条记录。
如果未指定 WHERE 条件,则删除表中的所有行。
您可以使用另一个表中的值更新一个表。
Teradata - SELECT 语句
SELECT 语句用于从表中检索记录。
句法
以下是 SELECT 语句的基本语法。
SELECT column 1, column 2, ..... FROM tablename;
例子
考虑以下员工表。
| 员工号 | 名 | 姓 | 加入日期 | 部门编号 | 出生日期 |
|---|---|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | 罗伯特 | 威廉斯 | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | 彼得 | 保罗 | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | 亚历克斯 | 斯图尔特 | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | 罗伯特 | 詹姆士 | 2008年1月4日 | 3 | 1984年12月1日 |
以下是 SELECT 语句的示例。
SELECT EmployeeNo,FirstName,LastName FROM Employee;
执行此查询时,它会从员工表中获取 EmployeeNo、FirstName 和 LastName 列。
EmployeeNo FirstName LastName ----------- ------------------------------ --------------------------- 101 Mike James 104 Alex Stuart 102 Robert Williams 105 Robert James 103 Peter Paul
如果要从表中获取所有列,可以使用以下命令而不是列出所有列。
SELECT * FROM Employee;
上面的查询将从员工表中获取所有记录。
WHERE 子句
WHERE 子句用于过滤 SELECT 语句返回的记录。条件与 WHERE 子句相关联。仅返回满足 WHERE 子句中的条件的记录。
句法
以下是带有 WHERE 子句的 SELECT 语句的语法。
SELECT * FROM tablename WHERE[condition];
例子
以下查询获取 EmployeeNo 为 101 的记录。
SELECT * FROM Employee WHERE EmployeeNo = 101;
执行此查询时,它返回以下记录。
EmployeeNo FirstName LastName ----------- ------------------------------ ----------------------------- 101 Mike James
订购依据
执行 SELECT 语句时,返回的行没有任何特定的顺序。ORDER BY 子句用于在任何列上按升序/降序排列记录。
句法
以下是带有 ORDER BY 子句的 SELECT 语句的语法。
SELECT * FROM tablename ORDER BY column 1, column 2..;
例子
以下查询从员工表中获取记录并按名字对结果进行排序。
SELECT * FROM Employee ORDER BY FirstName;
执行上述查询时,会产生以下输出。
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert James
通过...分组
GROUP BY 子句与 SELECT 语句一起使用,将相似的记录分组。
句法
以下是带有 GROUP BY 子句的 SELECT 语句的语法。
SELECT column 1, column2 …. FROM tablename GROUP BY column 1, column 2..;
例子
以下示例按 DepartmentNo 列对记录进行分组,并标识每个部门的总计数。
SELECT DepartmentNo,Count(*) FROM Employee GROUP BY DepartmentNo;
执行上述查询时,会产生以下输出。
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3
Teradata - 逻辑和条件运算符
Teradata 支持以下逻辑和条件运算符。这些运算符用于执行比较和组合多个条件。
| 句法 | 意义 |
|---|---|
| > | 比...更棒 |
| < | 少于 |
| >= | 大于或等于 |
| <= | 小于或等于 |
| = | 等于 |
| 之间 | 如果值在范围内 |
| 在 | 如果 <表达式> 中的值 |
| 不在 | 如果值不在 <表达式> 中 |
| 一片空白 | 如果值为 NULL |
| 不为空 | 如果值不为空 |
| 和 | 结合多个条件。仅当满足所有条件时才计算为 true |
| 或者 | 结合多个条件。仅当满足任一条件时才计算为 true。 |
| 不是 | 反转条件的含义 |
之间
BETWEEN 命令用于检查某个值是否在某个值范围内。
例子
考虑以下员工表。
| 员工号 | 名 | 姓 | 加入日期 | 部门编号 | 出生日期 |
|---|---|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | 罗伯特 | 威廉斯 | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | 彼得 | 保罗 | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | 亚历克斯 | 斯图尔特 | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | 罗伯特 | 詹姆士 | 2008年1月4日 | 3 | 1984年12月1日 |
以下示例获取员工编号在 101,102 到 103 之间的记录。
SELECT EmployeeNo, FirstName FROM Employee WHERE EmployeeNo BETWEEN 101 AND 103;
执行上述查询时,将返回员工编号在 101 到 103 之间的员工记录。
*** Query completed. 3 rows found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo FirstName ----------- ------------------------------ 101 Mike 102 Robert 103 Peter
在
IN 命令用于根据给定的值列表检查该值。
例子
以下示例获取员工编号为 101、102 和 103 的记录。
SELECT EmployeeNo, FirstName FROM Employee WHERE EmployeeNo in (101,102,103);
上述查询返回以下记录。
*** Query completed. 3 rows found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo FirstName ----------- ------------------------------ 101 Mike 102 Robert 103 Peter
不在
NOT IN 命令反转 IN 命令的结果。它获取值与给定列表不匹配的记录。
例子
以下示例获取员工编号不在 101、102 和 103 中的记录。
SELECT * FROM Employee WHERE EmployeeNo not in (101,102,103);
上述查询返回以下记录。
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert James
Teradata - SET 运算符
SET 运算符组合多个 SELECT 语句的结果。这可能看起来类似于联接,但联接组合了多个表中的列,而 SET 运算符组合了多行中的行。
规则
每个 SELECT 语句的列数应该相同。
每个 SELECT 的数据类型必须兼容。
ORDER BY 只能包含在最终的 SELECT 语句中。
联盟
UNION 语句用于组合多个 SELECT 语句的结果。它忽略重复项。
句法
以下是 UNION 语句的基本语法。
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] UNION SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
例子
考虑以下员工表和工资表。
| 员工号 | 名 | 姓 | 加入日期 | 部门编号 | 出生日期 |
|---|---|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | 罗伯特 | 威廉斯 | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | 彼得 | 保罗 | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | 亚历克斯 | 斯图尔特 | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | 罗伯特 | 詹姆士 | 2008年1月4日 | 3 | 1984年12月1日 |
| 员工号 | 总的 | 扣除 | 网络支付 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
以下 UNION 查询组合了 Employee 和 Salary 表中的 EmployeeNo 值。
SELECT EmployeeNo FROM Employee UNION SELECT EmployeeNo FROM Salary;
执行查询时,它会产生以下输出。
EmployeeNo ----------- 101 102 103 104 105
联合所有
UNION ALL 语句与 UNION 类似,它组合了多个表(包括重复行)的结果。
句法
以下是 UNION ALL 语句的基本语法。
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] UNION ALL SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
例子
以下是 UNION ALL 语句的示例。
SELECT EmployeeNo FROM Employee UNION ALL SELECT EmployeeNo FROM Salary;
执行上述查询时,会产生以下输出。您可以看到它也返回重复项。
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103
相交
INTERSECT 命令还用于组合多个 SELECT 语句的结果。它返回第一个 SELECT 语句中与第二个 SELECT 语句中具有相应匹配项的行。换句话说,它返回两个 SELECT 语句中都存在的行。
句法
以下是 INTERSECT 语句的基本语法。
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] INTERSECT SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
例子
以下是 INTERSECT 语句的示例。它返回两个表中都存在的 EmployeeNo 值。
SELECT EmployeeNo FROM Employee INTERSECT SELECT EmployeeNo FROM Salary;
当执行上述查询时,它返回以下记录。EmployeeNo 105 被排除,因为它不存在于 SALARY 表中。
EmployeeNo ----------- 101 104 102 103
减/除
MINUS/EXCEPT 命令组合多个表中的行并返回第一个 SELECT 中但不在第二个 SELECT 中的行。它们都返回相同的结果。
句法
以下是 MINUS 语句的基本语法。
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] MINUS SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
例子
以下是 MINUS 语句的示例。
SELECT EmployeeNo FROM Employee MINUS SELECT EmployeeNo FROM Salary;
执行此查询时,它返回以下记录。
EmployeeNo ----------- 105
Teradata - 字符串操作
Teradata 提供了多个函数来操作字符串。这些功能与 ANSI 标准兼容。
| 先生编号 | 字符串函数及说明 |
|---|---|
| 1 | ||
将字符串连接在一起 |
| 2 | 子字符串
提取字符串的一部分(Teradata 扩展) |
| 3 | 子串
提取字符串的一部分(ANSI 标准) |
| 4 | 指数
定位字符串中字符的位置(Teradata 扩展) |
| 5 | 位置
定位字符串中字符的位置(ANSI 标准) |
| 6 | 修剪
修剪字符串中的空格 |
| 7 | 上
将字符串转换为大写 |
| 8 | 降低
将字符串转换为小写 |
例子
下表列出了一些字符串函数及其结果。
| 字符串函数 | 结果 |
|---|---|
| SELECT SUBSTRING('仓库' FROM 1 FOR 4) | 洁具 |
| SELECT SUBSTR('仓库',1,4) | 洁具 |
| 选择“数据”|| ' ' || '仓库' | 数据仓库 |
| 选择上部('数据') | 数据 |
| 选择较低('数据') | 数据 |
Teradata - 日期/时间函数
本章讨论 Teradata 中可用的日期/时间函数。
数据存储
使用以下公式在内部将日期存储为整数。
((YEAR - 1900) * 10000) + (MONTH * 100) + DAY
您可以使用以下查询来检查日期的存储方式。
SELECT CAST(CURRENT_DATE AS INTEGER);
由于日期存储为整数,因此您可以对它们执行一些算术运算。Teradata 提供了执行这些操作的函数。
提炼
EXTRACT 函数从 DATE 值中提取日、月和年的部分内容。此函数还用于从 TIME/TIMESTAMP 值中提取小时、分钟和秒。
例子
以下示例显示如何从日期和时间戳值中提取年、月、日期、小时、分钟和秒值。
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000
间隔
Teradata 提供 INTERVAL 函数来对 DATE 和 TIME 值执行算术运算。INTERVAL 函数有两种类型。
年月间隔
- 年
- 逐月
- 月
日间间隔
- 天
- 日复一日
- 日复一日
- 日复一日
- 小时
- 小时到分钟
- 小时到秒
- 分钟
- 分钟到秒
- 第二
例子
以下示例将当前日期添加 3 年。
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR; Date (Date+ 3) -------- --------- 16/01/01 19/01/01
以下示例将 3 年零 1 个月添加到当前日期。
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH; Date (Date+ 3-01) -------- ------------ 16/01/01 19/02/01
以下示例将 01 天 05 小时 10 分钟添加到当前时间戳。
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00
Teradata - 内置函数
Teradata 提供内置函数,这些函数是 SQL 的扩展。以下是常见的内置函数。
| 功能 | 结果 |
|---|---|
| 选择日期; | 日期 -------- 16/01/01 |
| 选择当前日期; | 日期 -------- 16/01/01 |
| 选择时间; | 时间 -------- 04:50:29 |
| 选择当前时间; | 时间 -------- 04:50:29 |
| 选择当前时间戳; | 当前时间戳(6) -------------------------------- 2016-01-01 04:51:06.990000+00: 00 |
| 选择数据库; | 数据库 ------------------------------------------ TDUSER |
Teradata - 聚合函数
Teradata 支持常见的聚合函数。它们可以与 SELECT 语句一起使用。
COUNT - 计算行数
SUM - 对指定列的值求和
MAX - 返回指定列的大值
MIN - 返回指定列的最小值
AVG - 返回指定列的平均值
例子
考虑下面的薪资表。
| 员工号 | 总的 | 扣除 | 网络支付 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 104 | 75,000 | 5,000 | 70,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 105 | 70,000 | 4,000 | 66,000 |
| 103 | 90,000 | 7,000 | 83,000 |
数数
以下示例计算 Salary 表中的记录数。
SELECT count(*) from Salary;
Count(*)
-----------
5
最大限度
以下示例返回最大员工净工资值。
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000
最小
以下示例从 Salary 表中返回最低员工净工资值。
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000
平均电压
以下示例返回表中员工净工资值的平均值。
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800
和
以下示例计算 Salary 表的所有记录中员工净工资的总和。
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000
Teradata - CASE 和 COALESCE
本章介绍 Teradata 的 CASE 和 COALESCE 函数。
CASE表达式
CASE 表达式根据条件或 WHEN 子句计算每一行,并返回第一个匹配的结果。如果没有匹配项,则返回 ELSE 部分的结果。
句法
以下是 CASE 表达式的语法。
CASE <expression> WHEN <expression> THEN result-1 WHEN <expression> THEN result-2 ELSE Result-n END
例子
考虑以下 Employee 表。
| 员工号 | 名 | 姓 | 加入日期 | 部门编号 | 出生日期 |
|---|---|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | 罗伯特 | 威廉斯 | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | 彼得 | 保罗 | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | 亚历克斯 | 斯图尔特 | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | 罗伯特 | 詹姆士 | 2008年1月4日 | 3 | 1984年12月1日 |
以下示例评估 DepartmentNo 列,如果部门编号为 1,则返回值 1;如果部门编号为 3,则返回 2;否则它返回值作为无效部门。
SELECT EmployeeNo, CASE DepartmentNo WHEN 1 THEN 'Admin' WHEN 2 THEN 'IT' ELSE 'Invalid Dept' END AS Department FROM Employee;
执行上述查询时,会产生以下输出。
*** Query completed. 5 rows found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo Department ----------- ------------ 101 Admin 104 IT 102 IT 105 Invalid Dept 103 IT
上面的 CASE 表达式也可以写成下面的形式,将产生与上面相同的结果。
SELECT EmployeeNo, CASE WHEN DepartmentNo = 1 THEN 'Admin' WHEN DepartmentNo = 2 THEN 'IT' ELSE 'Invalid Dept' END AS Department FROM Employee;
合并
COALESCE 是返回表达式的第一个非空值的语句。如果表达式的所有参数的计算结果均为 NULL,则返回 NULL。以下是语法。
句法
COALESCE(expression 1, expression 2, ....)
例子
SELECT EmployeeNo, COALESCE(dept_no, 'Department not found') FROM employee;
NULLIF
如果参数相等,NULLIF 语句将返回 NULL。
句法
以下是 NULLIF 语句的语法。
NULLIF(expression 1, expression 2)
例子
如果 DepartmentNo 等于 3,以下示例将返回 NULL。否则,返回 DepartmentNo 值。
SELECT EmployeeNo, NULLIF(DepartmentNo,3) AS department FROM Employee;
上述查询返回以下记录。您可以看到员工 105 的部门号为 105。作为 NULL。
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2
Teradata - 主索引
主索引用于指定数据在 Teradata 中的位置。用于指定哪个AMP获取数据行。Teradata 中的每个表都需要定义一个主索引。如果未定义主索引,Teradata 会自动分配主索引。主索引提供了访问数据的最快方式。主数据库最多可以有 64 列。
主索引是在创建表时定义的。主索引有两种类型。
- 唯一主索引(UPI)
- 非唯一主索引(NUPI)
唯一主索引 (UPI)
如果表被定义为具有 UPI,则被视为 UPI 的列不应具有任何重复值。如果插入任何重复值,它们将被拒绝。
创建唯一主索引
以下示例创建 Salary 表,其中 EmployeeNo 列作为唯一主索引。
CREATE SET TABLE Salary ( EmployeeNo INTEGER, Gross INTEGER, Deduction INTEGER, NetPay INTEGER ) UNIQUE PRIMARY INDEX(EmployeeNo);
非唯一主索引 (NUPI)
如果表被定义为具有 NUPI,则被视为 UPI 的列可以接受重复值。
创建非唯一主索引
以下示例创建员工帐户表,其中 EmployeeNo 列作为非唯一主索引。EmployeeNo 定义为非唯一主索引,因为一个员工可以在表中拥有多个帐户;一份用于工资账户,另一份用于报销账户。
CREATE SET TABLE Employee _Accounts ( EmployeeNo INTEGER, employee_bank_account_type BYTEINT. employee_bank_account_number INTEGER, employee_bank_name VARCHAR(30), employee_bank_city VARCHAR(30) ) PRIMARY INDEX(EmployeeNo);
Teradata - 加入
连接用于组合多个表中的记录。表根据这些表中的公共列/值进行连接。
有不同类型的联接可用。
- 内部联接
- 左外连接
- 右外连接
- 全外连接
- 自加入
- 交叉连接
- 笛卡尔生产连接
内部联接
内连接合并多个表中的记录并返回两个表中都存在的值。
句法
以下是 INNER JOIN 语句的语法。
SELECT col1, col2, col3…. FROM Table-1 INNER JOIN Table-2 ON (col1 = col2) <WHERE condition>;
例子
考虑以下员工表和工资表。
| 员工号 | 名 | 姓 | 加入日期 | 部门编号 | 出生日期 |
|---|---|---|---|---|---|
| 101 | 麦克风 | 詹姆士 | 2005年3月27日 | 1 | 1980年1月5日 |
| 102 | 罗伯特 | 威廉斯 | 2007年4月25日 | 2 | 1983年3月5日 |
| 103 | 彼得 | 保罗 | 2007年3月21日 | 2 | 1983年4月1日 |
| 104 | 亚历克斯 | 斯图尔特 | 2008年2月1日 | 2 | 1984年11月6日 |
| 105 | 罗伯特 | 詹姆士 | 2008年1月4日 | 3 | 1984年12月1日 |
| 员工号 | 总的 | 扣除 | 网络支付 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
以下查询在公共列 EmployeeNo 上连接 Employee 表和 Salary 表。每个表都分配有一个别名 A 和 B,并且使用正确的别名引用列。
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay FROM Employee A INNER JOIN Salary B ON (A.EmployeeNo = B. EmployeeNo);
当执行上述查询时,它返回以下记录。员工 105 未包含在结果中,因为它在 Salary 表中没有匹配的记录。
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
外连接
LEFT OUTER JOIN 和 RIGHT OUTER JOIN 还组合多个表的结果。
LEFT OUTER JOIN返回左表中的所有记录,仅返回右表中匹配的记录。
RIGHT OUTER JOIN返回右表中的所有记录,并仅返回左表中的匹配行。
FULL OUTER JOIN组合了 LEFT OUTER JOINS 和 RIGHT OUTER JOINS 的结果。它返回连接表中的匹配行和不匹配行。
句法
以下是 OUTER JOIN 语句的语法。您需要使用 LEFT OUTER JOIN、RIGHT OUTER JOIN 或 FULL OUTER JOIN 中的选项之一。
SELECT col1, col2, col3…. FROM Table-1 LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN Table-2 ON (col1 = col2) <WHERE condition>;
例子
请考虑以下 LEFT OUTER JOIN 查询示例。它返回 Employee 表中的所有记录以及 Salary 表中的匹配记录。
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay FROM Employee A LEFT OUTER JOIN Salary B ON (A.EmployeeNo = B. EmployeeNo) ORDER BY A.EmployeeNo;
执行上述查询时,会产生以下输出。对于员工 105,NetPay 值为 NULL,因为它在 Salary 表中没有匹配的记录。
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?
交叉连接
交叉联接将左表中的每一行连接到右表中的每一行。
句法
以下是 CROSS JOIN 语句的语法。
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay FROM Employee A CROSS JOIN Salary B WHERE A.EmployeeNo = 101 ORDER BY B.EmployeeNo;
执行上述查询时,会产生以下输出。Employee 表中的 Employee No 101 与 Salary 表中的每条记录相连接。
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000
Teradata - 子查询
子查询根据另一个表中的值返回一个表中的记录。它是另一个查询中的 SELECT 查询。首先执行称为内部查询的 SELECT 查询,然后将结果供外部查询使用。它的一些显着特征是 -
一个查询可以有多个子查询,并且子查询可以包含另一个子查询。
子查询不返回重复记录。
如果子查询仅返回一个值,则可以使用 = 运算符将其与外部查询一起使用。如果它返回多个值,您可以使用 IN 或 NOT IN。
句法
以下是子查询的通用语法。
SELECT col1, col2, col3,… FROM Outer Table WHERE col1 OPERATOR ( Inner SELECT Query);
例子
考虑下面的薪资表。
| 员工号 | 总的 | 扣除 | 网络支付 |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
以下查询找出工资最高的员工编号。内部 SELECT 执行聚合函数以返回最大 NetPay 值,外部 SELECT 查询使用该值返回具有该值的员工记录。
SELECT EmployeeNo, NetPay FROM Salary WHERE NetPay = (SELECT MAX(NetPay) FROM Salary);
执行此查询时,它会产生以下输出。
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000
Teradata - 表类型
Teradata 支持以下表类型来保存临时数据。
- 派生表
- 易失性表
- 全局临时表
派生表
派生表是在查询中创建、使用和删除的。它们用于存储查询中的中间结果。
例子
以下示例构建一个派生表 EmpSal,其中包含工资大于 75000 的员工的记录。
SELECT Emp.EmployeeNo, Emp.FirstName, Empsal.NetPay FROM Employee Emp, (select EmployeeNo , NetPay from Salary where NetPay >= 75000) Empsal where Emp.EmployeeNo = Empsal.EmployeeNo;
执行上述查询时,将返回工资大于 75000 的员工。
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000
易失性表
易失性表是在用户会话中创建、使用和删除的。它们的定义不存储在数据字典中。它们保存经常使用的查询的中间数据。以下是语法。
句法
CREATE [SET|MULTISET] VOALTILE TABLE tablename <table definitions> <column definitions> <index definitions> ON COMMIT [DELETE|PRESERVE] ROWS
例子
CREATE VOLATILE TABLE dept_stat ( dept_no INTEGER, avg_salary INTEGER, max_salary INTEGER, min_salary INTEGER ) PRIMARY INDEX(dept_no) ON COMMIT PRESERVE ROWS;
执行上述查询时,会产生以下输出。
*** Table has been created. *** Total elapsed time was 1 second.
全局临时表
全局临时表的定义存储在数据字典中,可供多个用户/会话使用。但加载到全局临时表中的数据仅在会话期间保留。每个会话最多可以实现 2000 个全局临时表。以下是语法。
句法
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename <table definitions> <column definitions> <index definitions>
例子
CREATE SET GLOBAL TEMPORARY TABLE dept_stat ( dept_no INTEGER, avg_salary INTEGER, max_salary INTEGER, min_salary INTEGER ) PRIMARY INDEX(dept_no);
执行上述查询时,会产生以下输出。
*** Table has been created. *** Total elapsed time was 1 second.
Teradata - 空间概念
Teradata 中提供三种类型的空间。
永久空间
永久空间是用户/数据库可用于保存数据行的最大空间量。永久表、日志、后备表和二级索引子表使用永久空间。
没有为数据库/用户预先分配永久空间。它们只是定义为数据库/用户可以使用的最大空间量。永久空间量除以 AMP 数量。每当超出每个 AMP 限制时,就会生成一条错误消息。
线轴空间
Spool 空间是未使用的永久空间,系统用来保存 SQL 查询的中间结果。没有假脱机空间的用户无法执行任何查询。
与永久空间类似,假脱机空间定义用户可以使用的最大空间量。假脱机空间除以 AMP 数量。每当超出每个 AMP 限制时,用户都会收到假脱机空间错误。
临时空间
临时空间是全局临时表使用的未使用的永久空间。临时空间也除以 AMP 数量。
Teradata - 二级索引
一张表只能包含一个主索引。更常见的是,您会遇到表包含其他列的情况,使用这些列经常访问数据。Teradata 将为这些查询执行全表扫描。二级索引解决了这个问题。
二级索引是访问数据的替代路径。主索引和辅助索引之间存在一些差异。
二级索引不参与数据分布。
二级索引值存储在子表中。这些表是在所有 AMP 中构建的。
二级索引是可选的。
它们可以在创建表期间或创建表之后创建。
它们占用额外的空间,因为它们构建子表,并且还需要维护,因为需要为每个新行更新子表。
有两种类型的二级索引 -
- 唯一二级索引 (USI)
- 非唯一二级索引 (NUSI)
唯一二级索引 (USI)
唯一二级索引仅允许定义为 USI 的列具有唯一值。通过 USI 访问行是一个两放大器操作。
创建唯一二级索引
以下示例在员工表的 EmployeeNo 列上创建 USI。
CREATE UNIQUE INDEX(EmployeeNo) on employee;
非唯一二级索引 (NUSI)
非唯一的次要