TIKA - 概述
什么是阿帕奇蒂卡?
Apache Tika 是一个用于文档类型检测和从各种文件格式中提取内容的库。
在内部,Tika 使用现有的各种文档解析器和文档类型检测技术来检测和提取数据。
使用 Tika,人们可以开发一种通用类型检测器和内容提取器,以从不同类型的文档(例如电子表格、文本文档、图像、PDF,甚至在一定程度上的多媒体输入格式)中提取结构化文本和元数据。
Tika 提供了一个通用 API 来解析不同的文件格式。它对每种文档类型使用现有的专用解析器库。
所有这些解析器库都封装在一个称为Parser 接口的接口下。

为什么是蒂卡?
根据 filext.com 的数据,大约有 15k 到 51k 种内容类型,并且这个数字每天都在增长。数据以各种格式存储,例如文本文档、Excel 电子表格、PDF、图像和多媒体文件等。因此,搜索引擎和内容管理系统等应用程序需要额外的支持,以便轻松地从这些文档类型中提取数据。Apache Tika 通过提供通用 API 来从多种文件格式中查找和提取数据来实现此目的。
阿帕奇蒂卡应用程序
有多种应用程序使用 Apache Tika。在这里,我们将讨论一些严重依赖 Apache Tika 的著名应用程序。
搜索引擎
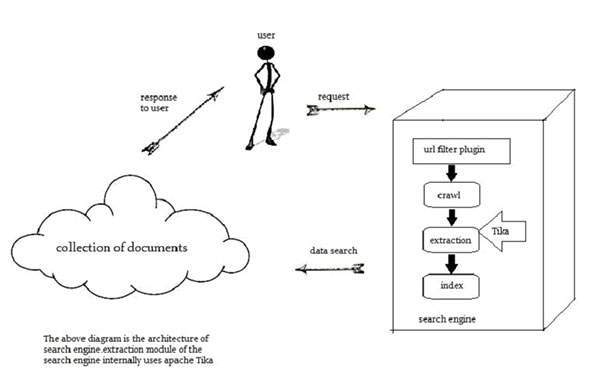
Tika 在开发搜索引擎以索引数字文档的文本内容时被广泛使用。
搜索引擎是一种信息处理系统,旨在从网络上搜索信息和索引文档。
爬虫是搜索引擎的重要组成部分,它通过网络爬行以获取要使用某种索引技术建立索引的文档。此后,爬虫将这些索引文档传输到提取组件。
提取组件的职责是从文档中提取文本和元数据。这样提取的内容和元数据对于搜索引擎非常有用。该提取成分含有蒂卡。
然后,提取的内容被传递到搜索引擎的索引器,搜索引擎使用它来构建搜索索引。除此之外,搜索引擎还以许多其他方式使用提取的内容。
文件分析
在人工智能领域,有一些工具可以在语义层面自动分析文档并从中提取各种数据。
在此类应用中,根据提取的文档内容中的突出术语对文档进行分类。
这些工具利用 Tika 进行内容提取来分析从纯文本到数字文档的各种文档。
数字资产管理
一些组织使用称为数字资产管理 (DAM) 的特殊应用程序来管理其数字资产,例如照片、电子书、绘图、音乐和视频。
此类应用程序借助文档类型检测器和元数据提取器对各种文档进行分类。
内容分析
亚马逊等网站会根据个人用户的兴趣向其推荐其网站新发布的内容。为此,这些网站遵循机器学习技术,或借助 Facebook 等社交媒体网站来提取所需信息,例如用户的喜好和兴趣。收集到的信息将采用 html 标签或其他需要进一步内容类型检测和提取的格式的形式。
对于文档的内容分析,我们拥有实现机器学习技术的技术,例如UIMA和Mahout。这些技术对于聚类和分析文档中的数据很有用。
Apache Mahout是一个在 Apache Hadoop(云计算平台)上提供机器学习算法的框架。Mahout 通过遵循某些集群和过滤技术来提供架构。通过遵循这种架构,程序员可以编写自己的机器学习算法,通过采用各种文本和元数据组合来生成推荐。为了向这些算法提供输入,最新版本的 Mahout 使用 Tika 从二进制内容中提取文本和元数据。
Apache UIMA分析和处理各种编程语言并生成 UIMA 注释。在内部,它使用 Tika Annotator 来提取文档文本和元数据。
历史
| 年 | 发展 |
|---|---|
| 2006年 | Tika 的想法已提交给 Lucene 项目管理委员会。 |
| 2006年 | 讨论了 Tika 的概念及其在 Jackrabbit 项目中的用途。 |
| 2007年 | Tika 进入 Apache 孵化器。 |
| 2008年 | 0.1和0.2版本发布,Tika从孵化器毕业到Lucene子项目。 |
| 2009年 | 发布了 0.3、0.4 和 0.5 版本。 |
| 2010年 | 0.6 和 0.7 版本发布,Tika 跻身 Apache 顶级项目。 |
| 2011年 | Tika 1.0 发布,同年还发布了关于 Tika 的书《Tika in Action》。 |