- Scikit 学习教程
- Scikit Learn - 主页
- Scikit Learn - 简介
- Scikit Learn - 建模过程
- Scikit Learn - 数据表示
- Scikit Learn - 估计器 API
- Scikit Learn - 约定
- Scikit Learn - 线性建模
- Scikit Learn - 扩展线性建模
- 随机梯度下降
- Scikit Learn - 支持向量机
- Scikit Learn - 异常检测
- Scikit Learn - K 最近邻
- Scikit Learn - KNN 学习
- 使用朴素贝叶斯分类
- Scikit Learn - 决策树
- 随机决策树
- Scikit Learn - Boosting 方法
- Scikit Learn - 聚类方法
- 集群性能评估
- 使用 PCA 降维
- Scikit Learn 有用资源
- Scikit Learn - 快速指南
- Scikit Learn - 有用的资源
- Scikit Learn - 讨论
Scikit Learn - 快速指南
Scikit Learn - 简介
在本章中,我们将了解什么是 Scikit-Learn 或 Sklearn、Scikit-Learn 的起源以及其他一些相关主题,例如负责开发和维护 Scikit-Learn 的社区和贡献者、其先决条件、安装及其功能。
什么是 Scikit-Learn (Sklearn)
Scikit-learn (Sklearn) 是 Python 中最有用、最强大的机器学习库。它为机器学习和统计建模提供了一系列有效的工具,包括通过 Python 中的一致性接口进行分类、回归、聚类和降维。该库主要用 Python 编写,基于NumPy、SciPy和Matplotlib构建。
Scikit-Learn 的起源
它最初称为scikits.learn,最初由 David Cournapeau 在 2007 年作为 Google 夏季代码项目开发。后来,在 2010 年,来自 FIRCA(法国研究院)的 Fabian Pedregosa、Gael Varoquaux、Alexandre Gramfort 和 Vincent Michel计算机科学与自动化),将该项目提升到另一个层次,并于 2010 年 2 月 1 日首次公开发布(v0.1 beta)。
让我们看一下它的版本历史 -
2019 年 5 月:scikit-learn 0.21.0
2019 年 3 月:scikit-learn 0.20.3
2018 年 12 月:scikit-learn 0.20.2
2018 年 11 月:scikit-learn 0.20.1
2018 年 9 月:scikit-learn 0.20.0
2018 年 7 月:scikit-learn 0.19.2
2017 年 7 月:scikit-learn 0.19.0
2016 年 9 月。scikit-learn 0.18.0
2015 年 11 月。scikit-learn 0.17.0
2015 年 3 月。scikit-learn 0.16.0
2014 年 7 月。scikit-learn 0.15.0
2013 年 8 月。scikit-learn 0.14
社区和贡献者
Scikit-learn 是一项社区成果,任何人都可以为其做出贡献。该项目托管在https://github.com/scikit-learn/scikit-learn 上。以下人员目前是 Sklearn 开发和维护的核心贡献者 -
Joris Van den Bossche(数据科学家)
托马斯·J·范(软件开发人员)
Alexandre Gramfort(机器学习研究员)
Olivier Grisel(机器学习专家)
尼古拉斯·哈格(副研究科学家)
安德烈亚斯·穆勒(机器学习科学家)
秦汉民(软件工程师)
Adrin Jalali(开源开发人员)
Nelle Varoquaux(数据科学研究人员)
Roman Yurchak(数据科学家)
Booking.com、JP Morgan、Evernote、Inria、AWeber、Spotify 等各种组织都在使用 Sklearn。
先决条件
在开始使用 scikit-learn 最新版本之前,我们需要以下内容 -
Python (>=3.5)
NumPy (>= 1.11.0)
Scipy (>= 0.17.0)li
作业库 (>= 0.11)
Sklearn 绘图功能需要 Matplotlib (>= 1.5.1)。
一些使用数据结构和分析的 scikit-learn 示例需要 Pandas (>= 0.18.0)。
安装
如果您已经安装了 NumPy 和 Scipy,以下是安装 scikit-learn 的两种最简单方法 -
使用点
以下命令可用于通过 pip 安装 scikit-learn -
pip install -U scikit-learn
使用康达
以下命令可用于通过 conda 安装 scikit-learn -
conda install scikit-learn
另一方面,如果您的 Python 工作站上尚未安装 NumPy 和 Scipy,则可以使用pip或conda安装它们。
使用 scikit-learn 的另一个选择是使用Canopy和Anaconda等 Python 发行版,因为它们都提供了最新版本的 scikit-learn。
特征
Scikit-learn 库不是专注于加载、操作和汇总数据,而是专注于数据建模。Sklearn 提供的一些最受欢迎的模型组如下 -
监督学习算法- 几乎所有流行的监督学习算法,如线性回归、支持向量机(SVM)、决策树等,都是 scikit-learn 的一部分。
无监督学习算法- 另一方面,它还拥有所有流行的无监督学习算法,从聚类、因子分析、PCA(主成分分析)到无监督神经网络。
聚类- 该模型用于对未标记的数据进行分组。
交叉验证- 用于检查监督模型对未见数据的准确性。
降维- 用于减少数据中属性的数量,可进一步用于汇总、可视化和特征选择。
集成方法- 顾名思义,它用于组合多个监督模型的预测。
特征提取- 用于从数据中提取特征以定义图像和文本数据中的属性。
特征选择- 用于识别有用的属性以创建监督模型。
开源- 它是开源库,也可在 BSD 许可下商业使用。
Scikit Learn - 建模过程
本章介绍 Sklearn 中涉及的建模过程。让我们详细了解这一点并从数据集加载开始。
数据集加载
数据的集合称为数据集。它具有以下两个组成部分 -
特征- 数据的变量称为其特征。它们也称为预测变量、输入或属性。
特征矩阵- 它是特征的集合,以防有多个特征。
功能名称- 这是所有功能名称的列表。
响应- 它是基本上取决于特征变量的输出变量。它们也称为目标、标签或输出。
响应向量- 用于表示响应列。一般来说,我们只有一个回复栏。
目标名称- 它表示响应向量可能采用的值。
Scikit-learn 几乎没有示例数据集,例如用于分类的虹膜和数字以及用于回归的波士顿房价。
例子
以下是加载虹膜数据集的示例-
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nFirst 10 rows of X:\n", X[:10])
输出
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] Target names: ['setosa' 'versicolor' 'virginica'] First 10 rows of X: [ [5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1] ]
分割数据集
为了检查模型的准确性,我们可以将数据集分成两部分——训练集和测试集。使用训练集训练模型,使用测试集测试模型。之后,我们可以评估我们的模型的表现。
例子
下面的示例将数据按照70:30的比例进行分割,即70%的数据将用作训练数据,30%的数据将用作测试数据。数据集是 iris 数据集,如上例所示。
from sklearn.datasets import load_iris iris = load_iris() X = iris.data y = iris.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.3, random_state = 1 ) print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape)
输出
(105, 4) (45, 4) (105,) (45,)
如上例所示,它使用scikit-learn 的train_test_split()函数来分割数据集。该函数有以下参数 -
X, y - 这里,X是特征矩阵,y是响应向量,需要进行分割。
test_size - 这表示测试数据与总给定数据的比率。如上例所示,我们为 X 的 150 行设置test_data = 0.3。它将产生 150*0.3 = 45 行的测试数据。
random_size - 用于保证分割始终相同。这在您想要可重现结果的情况下非常有用。
训练模型
接下来,我们可以使用我们的数据集来训练一些预测模型。正如所讨论的,scikit-learn 拥有广泛的机器学习 (ML) 算法,这些算法具有一致的接口用于拟合、预测准确性、召回率等。
例子
在下面的示例中,我们将使用 KNN(K 最近邻)分类器。不要深入讨论 KNN 算法的细节,因为会有单独的章节来介绍。本示例仅用于让您了解实现部分。
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.4, random_state=1
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors = 3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Finding accuracy by comparing actual response values(y_test)with predicted response value(y_pred)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)
输出
Accuracy: 0.9833333333333333 Predictions: ['versicolor', 'virginica']
模型持久化
训练模型后,最好保留该模型以供将来使用,这样我们就不需要一次又一次地重新训练它。这可以借助joblib包的转储和加载功能来完成。
考虑下面的示例,我们将保存上述训练模型(classifier_knn)以供将来使用 -
from sklearn.externals import joblib joblib.dump(classifier_knn, 'iris_classifier_knn.joblib')
上面的代码将模型保存到名为 iris_classifier_knn.joblib 的文件中。现在,可以借助以下代码从文件重新加载对象 -
joblib.load('iris_classifier_knn.joblib')
预处理数据
由于我们正在处理大量数据并且这些数据处于原始形式,因此在将数据输入机器学习算法之前,我们需要将其转换为有意义的数据。这个过程称为数据预处理。Scikit-learn为此提供了名为preprocessing 的包。预处理包具有以下技术 -
二值化
当我们需要将数值转换为布尔值时,会使用这种预处理技术。
例子
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
data_binarized = preprocessing.Binarizer(threshold=0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)
在上面的例子中,我们使用阈值= 0.5,这就是为什么所有高于 0.5 的值都会转换为 1,所有低于 0.5 的值都会转换为 0。
输出
Binarized data: [ [ 1. 0. 1.] [ 0. 1. 1.] [ 0. 0. 1.] [ 1. 1. 0.] ]
均值去除
该技术用于消除特征向量的均值,使每个特征都以零为中心。
例子
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
#displaying the mean and the standard deviation of the input data
print("Mean =", input_data.mean(axis=0))
print("Stddeviation = ", input_data.std(axis=0))
#Removing the mean and the standard deviation of the input data
data_scaled = preprocessing.scale(input_data)
print("Mean_removed =", data_scaled.mean(axis=0))
print("Stddeviation_removed =", data_scaled.std(axis=0))
输出
Mean = [ 1.75 -1.275 2.2 ] Stddeviation = [ 2.71431391 4.20022321 4.69414529] Mean_removed = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00] Stddeviation_removed = [ 1. 1. 1.]
缩放
我们使用这种预处理技术来缩放特征向量。特征向量的缩放很重要,因为特征不应该综合地变大或变小。
例子
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)
输出
Min max scaled data: [ [ 0.48648649 0.58252427 0.99122807] [ 0. 1. 0.81578947] [ 0.27027027 0. 1. ] [ 1. 0.99029126 0. ] ]
正常化
我们使用这种预处理技术来修改特征向量。特征向量的归一化是必要的,以便可以在公共尺度上测量特征向量。有两种类型的标准化,如下 -
L1 归一化
它也称为最小绝对偏差。它以这样的方式修改值,使得每行中的绝对值之和始终保持为 1。以下示例显示了对输入数据进行 L1 标准化的实现。
例子
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
print("\nL1 normalized data:\n", data_normalized_l1)
输出
L1 normalized data: [ [ 0.22105263 -0.2 0.57894737] [-0.2027027 0.32432432 0.47297297] [ 0.03571429 -0.56428571 0.4 ] [ 0.42142857 0.16428571 -0.41428571] ]
L2 归一化
也称为最小二乘法。它以每行的平方和始终保持为 1 的方式修改该值。以下示例显示了对输入数据进行 L2 标准化的实现。
例子
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l2)
输出
L2 normalized data: [ [ 0.33946114 -0.30713151 0.88906489] [-0.33325106 0.53320169 0.7775858 ] [ 0.05156558 -0.81473612 0.57753446] [ 0.68706914 0.26784051 -0.6754239 ] ]
Scikit Learn - 数据表示
众所周知,机器学习是根据数据创建模型。为此,计算机必须首先理解数据。接下来,我们将讨论表示数据的各种方法,以便计算机能够理解 -
数据为表格
在 Scikit-learn 中表示数据的最佳方式是采用表格的形式。表表示二维数据网格,其中行表示数据集的各个元素,列表示与这些各个元素相关的数量。
例子
通过下面给出的示例,我们可以借助 python seaborn库以 Pandas DataFrame 的形式下载iris 数据集。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
输出
sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa
从上面的输出中,我们可以看到数据的每一行代表一朵观察到的花朵,行数代表数据集中花朵的总数。通常,我们将矩阵的行称为样本。
另一方面,每一列数据代表描述每个样本的定量信息。通常,我们将矩阵的列称为特征。
数据作为特征矩阵
特征矩阵可以定义为表格布局,其中信息可以被视为二维矩阵。它存储在名为X的变量中,并假定为形状为 [n_samples, n_features] 的二维变量。大多数情况下,它包含在 NumPy 数组或 Pandas DataFrame 中。如前所述,样本始终代表数据集描述的各个对象,而特征代表以定量方式描述每个样本的不同观察结果。
数据作为目标数组
除了特征矩阵(用 X 表示)之外,我们还有目标数组。它也被称为标签。它用y表示。标签或目标数组通常是长度为 n_samples 的一维数组。它通常包含在 NumPy数组或 Pandas Series中。目标数组可以同时具有值、连续数值和离散值。
目标数组与特征列有何不同?
我们可以通过一点来区分两者,即目标数组通常是我们想要从数据中预测的数量,即在统计术语中它是因变量。
例子
在下面的示例中,我们从鸢尾花数据集中根据其他测量值预测花的种类。在这种情况下,物种列将被视为特征。
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);
输出
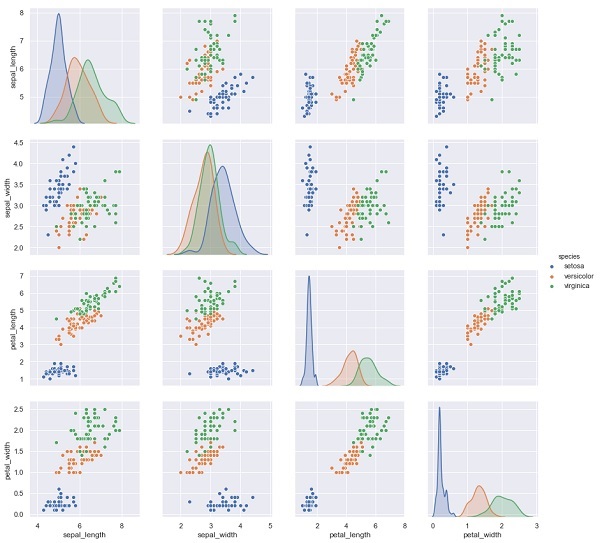
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
输出
(150,4) (150,)
Scikit Learn - 估计器 API
在本章中,我们将学习Estimator API(应用程序编程接口)。让我们首先了解什么是 Estimator API。
什么是估算器 API
它是 Scikit-learn 实现的主要 API 之一。它为各种 ML 应用程序提供了一致的接口,这就是 Scikit-Learn 中的所有机器学习算法都是通过 Estimator API 实现的原因。从数据中学习(拟合数据)的对象是估计器。它可以与任何算法一起使用,例如分类、回归、聚类,甚至可以与变压器一起使用,从原始数据中提取有用的特征。
为了拟合数据,所有估计器对象都公开一个拟合方法,该方法采用如下所示的数据集 -
estimator.fit(data)
接下来,当通过相应的属性实例化估计器时,可以设置估计器的所有参数,如下所示。
estimator = Estimator (param1=1, param2=2) estimator.param1
上面的输出将为 1。
一旦数据与估计器相匹配,就可以根据手头的数据估计参数。现在,所有估计参数都将是以下划线结尾的估计器对象的属性,如下所示 -
estimator.estimated_param_
估算器 API 的使用
估计器的主要用途如下 -
模型的估计和解码
估计器对象用于模型的估计和解码。此外,该模型被估计为以下确定性函数 -
对象构造中提供的参数。
如果估计器的 random_state 参数设置为 none,则全局随机状态 (numpy.random)。
传递到最近一次调用fit、fit_transform 或 fit_predict 的任何数据。
在对partial_fit的一系列调用中传递的任何数据。
将非矩形数据表示映射到矩形数据
它将非矩形数据表示映射为矩形数据。简而言之,它接受输入,其中每个样本不表示为固定长度的类似数组的对象,并为每个样本生成类似数组的特征对象。
核心样本和外围样本之间的区别
它使用以下方法对核心样本和外围样本之间的区别进行建模 -
合身
fit_predict 如果是传导性的
预测是否有感性
指导原则
在设计 Scikit-Learn API 时,请牢记以下指导原则 -
一致性
该原则规定所有对象应该共享一个从有限的方法集得出的公共接口。文档也应该一致。
有限的对象层次结构
该指导原则说:
算法应该用Python类来表示
数据集应以标准格式表示,例如 NumPy 数组、Pandas DataFrames、SciPy 稀疏矩阵。
参数名称应使用标准 Python 字符串。
作品
众所周知,机器学习算法可以表示为许多基本算法的序列。Scikit-learn 在需要时会利用这些基本算法。
合理的默认值
根据这一原则,只要 ML 模型需要用户指定的参数,Scikit-learn 库就会定义适当的默认值。
检查
根据此指导原则,每个指定的参数值都作为公共属性公开。
使用 Estimator API 的步骤
以下是使用 Scikit-Learn 估计器 API 的步骤 -
第 1 步:选择模型类别
在第一步中,我们需要选择一类模型。这可以通过从 Scikit-learn 导入适当的 Estimator 类来完成。
步骤2:选择模型超参数
在这一步中,我们需要选择类模型超参数。这可以通过使用所需值实例化类来完成。
第三步:整理数据
接下来,我们需要将数据排列成特征矩阵(X)和目标向量(y)。
第四步:模型拟合
现在,我们需要使模型适合您的数据。可以通过调用模型实例的 fit() 方法来完成。
第 5 步:应用模型
拟合模型后,我们可以将其应用于新数据。对于监督学习,使用predict()方法来预测未知数据的标签。而对于无监督学习,使用predict()或transform()来推断数据的属性。
监督学习示例
在这里,作为此过程的示例,我们采用将直线拟合到 (x,y) 数据的常见情况,即简单线性回归。
首先,我们需要加载数据集,我们使用的是 iris 数据集 -
例子
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
输出
(150, 4)
例子
y_iris = iris['species'] y_iris.shape
输出
(150,)
例子
现在,对于这个回归示例,我们将使用以下示例数据 -
%matplotlib inline import matplotlib.pyplot as plt import numpy as np rng = np.random.RandomState(35) x = 10*rng.rand(40) y = 2*x-1+rng.randn(40) plt.scatter(x,y);
输出
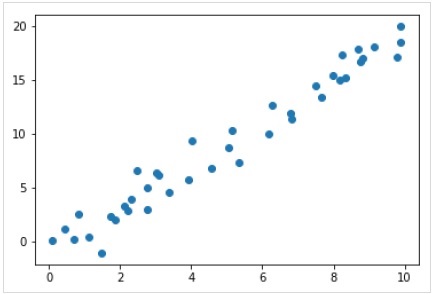
因此,我们的线性回归示例就有了上述数据。
现在,有了这些数据,我们就可以应用上述步骤了。
选择型号类别
在这里,为了计算一个简单的线性回归模型,我们需要导入线性回归类,如下所示 -
from sklearn.linear_model import LinearRegression
选择模型超参数
一旦我们选择了一类模型,我们就需要做出一些重要的选择,这些选择通常表示为超参数,或者在模型适合数据之前必须设置的参数。在这里,对于这个线性回归的示例,我们希望使用fit_intercept超参数来拟合截距,如下所示 -
例子
model = LinearRegression(fit_intercept = True) model
输出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)
整理数据
现在,我们知道目标变量y的形式正确,即长度为n_samples的一维数组。但是,我们需要重塑特征矩阵X,使其成为大小为[n_samples, n_features]的矩阵。可以按如下方式完成 -
例子
X = x[:, np.newaxis] X.shape
输出
(40, 1)
模型拟合
一旦我们安排了数据,就该拟合模型了,即将我们的模型应用到数据上。这可以借助fit()方法来完成,如下所示 -
例子
model.fit(X, y)
输出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)
在 Scikit-learn 中,fit()过程有一些尾随下划线。
对于此示例,以下参数显示了数据的简单线性拟合的斜率 -
例子
model.coef_
输出
array([1.99839352])
以下参数表示数据的简单线性拟合的截距 -
例子
model.intercept_
输出
-0.9895459457775022
将模型应用于新数据
训练模型后,我们可以将其应用到新数据中。由于监督机器学习的主要任务是基于不属于训练集的新数据来评估模型。可以借助Predict()方法来完成,如下所示 -
例子
xfit = np.linspace(-1, 11) Xfit = xfit[:, np.newaxis] yfit = model.predict(Xfit) plt.scatter(x, y) plt.plot(xfit, yfit);
输出
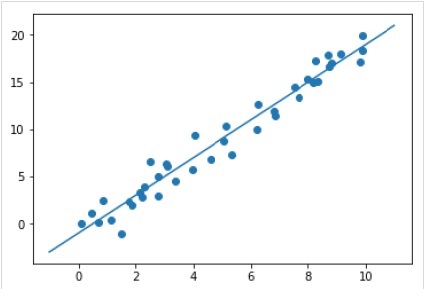
完整的工作/可执行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);
无监督学习示例
在这里,作为此过程的一个示例,我们采用降低 Iris 数据集维度的常见情况,以便我们可以更轻松地对其进行可视化。对于此示例,我们将使用主成分分析 (PCA),这是一种快速线性降维技术。
就像上面给出的示例一样,我们可以加载并绘制 iris 数据集中的随机数据。之后我们可以按照以下步骤操作 -
选择型号类别
from sklearn.decomposition import PCA
选择模型超参数
例子
model = PCA(n_components=2) model
输出
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None, svd_solver = 'auto', tol = 0.0, whiten = False)
模型拟合
例子
model.fit(X_iris)
输出
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None, svd_solver = 'auto', tol = 0.0, whiten = False)
将数据转换为二维
例子
X_2D = model.transform(X_iris)
现在,我们可以绘制结果如下 -
输出
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);
输出
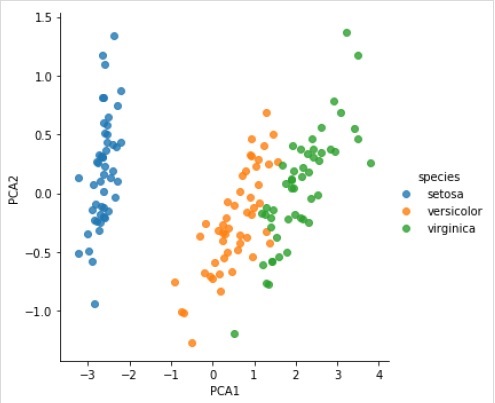
完整的工作/可执行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);
Scikit Learn - 约定
Scikit-learn 的对象共享一个统一的基本 API,由以下三个互补接口组成 -
估计器接口- 用于构建和拟合模型。
预测器接口- 用于进行预测。
转换器接口- 用于转换数据。
API 采用简单的约定,并以避免框架代码激增的方式指导设计选择。
公约的目的
约定的目的是确保 API 遵循以下广泛原则 -
一致性- 所有对象,无论是基本对象还是复合对象,都必须共享一个一致的接口,该接口进一步由一组有限的方法组成。
检查- 由学习算法确定的构造函数参数和参数值应存储并公开为公共属性。
类的不扩散- 数据集应表示为 NumPy 数组或 Scipy 稀疏矩阵,而超参数名称和值应表示为标准 Python 字符串,以避免框架代码的扩散。
组合- 算法无论是可表示为数据转换的序列或组合,还是自然地被视为在其他算法上参数化的元算法,都应该由现有的构建块来实现和组合。
合理的默认值- 在 scikit-learn 中,只要操作需要用户定义的参数,就会定义适当的默认值。此默认值应使操作以合理的方式执行,例如,为手头的任务提供基线解决方案。
各种约定
Sklearn 中可用的约定解释如下 -
类型铸造
它指出输入应转换为float64。在下面的示例中,其中sklearn.random_projection模块用于降低数据的维度,将对其进行解释 -
例子
import numpy as np from sklearn import random_projection rannge = np.random.RandomState(0) X = range.rand(10,2000) X = np.array(X, dtype = 'float32') X.dtype Transformer_data = random_projection.GaussianRandomProjection() X_new = transformer.fit_transform(X) X_new.dtype
输出
dtype('float32')
dtype('float64')
在上面的例子中,我们可以看到 X 是float32 ,它被fit_transform(X)转换为float64。
改装及更新参数
估计器的超参数可以在通过set_params()方法构建后进行更新和重新拟合。让我们看下面的例子来理解它 -
例子
import numpy as np from sklearn.datasets import load_iris from sklearn.svm import SVC X, y = load_iris(return_X_y = True) clf = SVC() clf.set_params(kernel = 'linear').fit(X, y) clf.predict(X[:5])
输出
array([0, 0, 0, 0, 0])
一旦构建了估计器,上面的代码将通过SVC.set_params()将默认内核rbf更改为线性。
现在,以下代码将内核更改回 rbf 以重新拟合估计器并进行第二次预测。
例子
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y) clf.predict(X[:5])
输出
array([0, 0, 0, 0, 0])
完整代码
以下是完整的可执行程序 -
import numpy as np from sklearn.datasets import load_iris from sklearn.svm import SVC X, y = load_iris(return_X_y = True) clf = SVC() clf.set_params(kernel = 'linear').fit(X, y) clf.predict(X[:5]) clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y) clf.predict(X[:5])
多类和多标签拟合
在多类拟合的情况下,学习和预测任务都取决于拟合的目标数据的格式。使用的模块是sklearn.multiclass。检查下面的示例,其中多类分类器适合一维数组。
例子
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.preprocessing import LabelBinarizer X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]] y = [0, 0, 1, 1, 2] classif = OneVsRestClassifier(estimator = SVC(gamma = 'scale',random_state = 0)) classif.fit(X, y).predict(X)
输出
array([0, 0, 1, 1, 2])
在上面的示例中,分类器适合多类标签的一维数组,因此Predict()方法提供相应的多类预测。但另一方面,也可以拟合二进制标签指示符的二维数组,如下所示 -
例子
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.preprocessing import LabelBinarizer X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]] y = LabelBinarizer().fit_transform(y) classif.fit(X, y).predict(X)
输出
array(
[
[0, 0, 0],
[0, 0, 0],
[0, 1, 0],
[0, 1, 0],
[0, 0, 0]
]
)
同样,在多标签拟合的情况下,可以为一个实例分配多个标签,如下所示 -
例子
from sklearn.preprocessing import MultiLabelBinarizer y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]] y = MultiLabelBinarizer().fit_transform(y) classif.fit(X, y).predict(X)
输出
array(
[
[1, 0, 1, 0, 0],
[1, 0, 1, 0, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 0, 0]
]
)
在上面的示例中,sklearn.MultiLabelBinarizer用于对多标签的二维数组进行二值化以适应。这就是为什么 Predict() 函数给出一个二维数组作为输出,每个实例都有多个标签。
Scikit Learn - 线性建模
本章将帮助您学习 Scikit-Learn 中的线性建模。让我们首先了解什么是 Sklearn 中的线性回归。
下表列出了 Scikit-Learn 提供的各种线性模型 -
| 先生编号 | 型号及说明 |
|---|---|
| 1 |
它是研究因变量 (Y) 与给定的一组自变量 (X) 之间关系的最佳统计模型之一。 |
| 2 |
逻辑回归,尽管它的名字如此,它是一种分类算法而不是回归算法。基于给定的一组自变量,它用于估计离散值(0 或 1、是/否、真/假)。 |
| 3 |
岭回归或吉洪诺夫正则化是执行 L2 正则化的正则化技术。它通过添加相当于系数大小平方的惩罚(收缩量)来修改损失函数。 |
| 4 |
贝叶斯回归通过使用概率分布而不是点估计来制定线性回归,允许自然机制应对数据不足或分布不良的数据。 |
| 5 |
LASSO 是执行 L1 正则化的正则化技术。它通过添加相当于系数绝对值总和的惩罚(收缩量)来修改损失函数。 |
| 6 |
它允许联合拟合多个回归问题,强制所选特征对于所有回归问题都相同,也称为任务。Sklearn 提供了一个名为 MultiTaskLasso 的线性模型,使用混合 L1、L2 范数进行正则化训练,联合估计多个回归问题的稀疏系数。 |
| 7 |
Elastic-Net 是一种正则化回归方法,它线性组合了 Lasso 和 Ridge 回归方法的 L1 和 L2 惩罚。当存在多个相关特征时它很有用。 |
| 8 |
它是一个弹性网络模型,允许联合拟合多个回归问题,强制所有回归问题(也称为任务)的所选特征相同 |
Scikit Learn - 扩展线性建模
本章重点介绍 Sklearn 中的多项式特征和流水线工具。
多项式特征简介
在数据的非线性函数上训练的线性模型通常保持线性方法的快速性能。它还允许它们适应更广泛的数据。这就是机器学习中使用基于非线性函数训练的线性模型的原因。
一个这样的例子是,可以通过从系数构造多项式特征来扩展简单的线性回归。
从数学上讲,假设我们有标准线性回归模型,那么对于二维数据,它看起来像这样 -
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}$$现在,我们可以结合二阶多项式中的特征,我们的模型将如下所示 -
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}+W_{3}X_{1}X_{2}+W_{4}X_1^2+W_{ 5}X_2^2$$上面仍然是线性模型。在这里,我们看到所得的多项式回归属于同一类线性模型,并且可以类似地求解。
为此,scikit-learn 提供了一个名为PolynomialFeatures的模块。该模块将输入数据矩阵转换为给定阶数的新数据矩阵。
参数
下表列出了PolynomialFeatures模块使用的参数
| 先生编号 | 参数及说明 |
|---|---|
| 1 |
度- 整数,默认 = 2 它表示多项式特征的次数。 |
| 2 |
Interaction_only - 布尔值,默认 = false 默认情况下,它是 false,但如果设置为 true,则会生成大多数程度不同的输入特征的产物特征。这些特征称为交互特征。 |
| 3 |
include_bias - 布尔值,默认 = true 它包括一个偏置列,即所有多项式幂均为零的特征。 |
| 4 |
order - {'C', 'F'} 中的 str,默认 = 'C' 该参数表示密集情况下输出数组的顺序。“F”阶意味着计算速度更快,但另一方面,它可能会减慢后续估计器的速度。 |
属性
下表包含PolynomialFeatures模块使用的属性
| 先生编号 | 属性和描述 |
|---|---|
| 1 |
powers_ - 数组,形状 (n_output_features, n_input_features) 它表明 powers_ [i,j] 是第 i 个输出中第 j 个输入的指数。 |
| 2 |
n_input_features _ − int 顾名思义,它给出了输入特征的总数。 |
| 3 |
n_output_features _ − int 顾名思义,它给出了多项式输出特征的总数。 |
实施例
以下 Python 脚本使用PolynomialFeatures转换器将 8 数组转换为形状 (4,2) -
from sklearn.preprocessing import PolynomialFeatures import numpy as np Y = np.arange(8).reshape(4, 2) poly = PolynomialFeatures(degree=2) poly.fit_transform(Y)
输出
array(
[
[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.],
[ 1., 6., 7., 36., 42., 49.]
]
)
使用 Pipeline 工具进行简化
上述预处理即将输入数据矩阵转换为给定程度的新数据矩阵,可以使用管道工具进行简化,管道工具基本上用于将多个估计器链接到一个。
例子
下面的 python 脚本使用 Scikit-learn 的 Pipeline 工具来简化预处理(将适合 3 阶多项式数据)。
#First, import the necessary packages.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
#Next, create an object of Pipeline tool
Stream_model = Pipeline([('poly', PolynomialFeatures(degree=3)), ('linear', LinearRegression(fit_intercept=False))])
#Provide the size of array and order of polynomial data to fit the model.
x = np.arange(5)
y = 3 - 2 * x + x ** 2 - x ** 3
Stream_model = model.fit(x[:, np.newaxis], y)
#Calculate the input polynomial coefficients.
Stream_model.named_steps['linear'].coef_
输出
array([ 3., -2., 1., -1.])
上面的输出表明,在多项式特征上训练的线性模型能够恢复精确的输入多项式系数。
Scikit Learn - 随机梯度下降
在这里,我们将学习 Sklearn 中的一种优化算法,称为随机梯度下降 (SGD)。
随机梯度下降 (SGD) 是一种简单而有效的优化算法,用于查找最小化成本函数的函数参数/系数值。换句话说,它用于SVM和Logistic回归等凸损失函数下线性分类器的判别学习。它已成功应用于大规模数据集,因为系数的更新是针对每个训练实例执行的,而不是在实例结束时执行。
SGD分类器
随机梯度下降 (SGD) 分类器基本上实现了一个简单的 SGD 学习例程,支持各种损失函数和分类惩罚。Scikit-learn 提供SGDClassifier模块来实现 SGD 分类。
参数
下表包含SGDClassifier模块使用的参数-
| 先生编号 | 参数及说明 |
|---|---|
| 1 |
损失- str,默认 = '铰链' 它表示实现时要使用的损失函数。默认值为“hinge”,这将为我们提供线性 SVM。可以使用的其他选项是 -
|
| 2 |
惩罚- str,'none','l2','l1','elasticnet' 它是模型中使用的正则化项。默认为L2。我们可以使用 L1 或 'elasticnet; 同样,但两者都可能会给模型带来稀疏性,因此 L2 无法实现。 |
| 3 |
alpha - 浮点数,默认 = 0.0001 Alpha 是乘以正则化项的常数,是决定我们想要对模型进行惩罚程度的调整参数。默认值为 0.0001。 |
| 4 |
l1_ratio - 浮点数,默认 = 0.15 这称为 ElasticNet 混合参数。它的范围是0 <= l1_ratio <= 1。如果l1_ratio = 1,则惩罚将为L1惩罚。如果 l1_ratio = 0,则惩罚将为 L2 惩罚。 |
| 5 |
fit_intercept - 布尔值,默认=True 该参数指定应将常数(偏差或截距)添加到决策函数中。如果将其设置为 false,则在计算中不会使用截距,并且将假定数据已居中。 |
| 6 |
tol - 浮动或无,可选,默认 = 1.e-3 该参数表示迭代的停止标准。它的默认值为 False,但如果设置为 None,则迭代将在以下情况下停止: |