Apache Flume - 快速指南
Apache Flume - 简介
什么是 Flume?
Apache Flume 是一种工具/服务/数据摄取机制,用于收集聚合并将大量流数据(例如日志文件、事件等)从各种来源传输到集中式数据存储。
Flume 是一个高度可靠、分布式、可配置的工具。它的主要设计目的是将流数据(日志数据)从各种Web服务器复制到HDFS。

Flume的应用
假设电子商务 Web 应用程序想要分析特定区域的客户Behave。为此,他们需要将可用日志数据移至 Hadoop 进行分析。在这里,Apache Flume 来拯救我们。
Flume用于将应用服务器产生的日志数据以更高的速度移动到HDFS中。
Flume的优点
以下是使用 Flume 的优点 -
使用 Apache Flume,我们可以将数据存储到任何集中式存储(HBase、HDFS)中。
当传入数据的速率超过数据写入目的地的速率时,Flume 充当数据生产者和集中式存储之间的中介,并在它们之间提供稳定的数据流。
Flume提供了上下文路由的功能。
Flume 中的事务是基于通道的,其中为每条消息维护两个事务(一个发送者和一个接收者)。它保证可靠的消息传递。
Flume 具有可靠、容错、可扩展、可管理和可定制的特点。
Flume的特点
Flume 的一些显着特征如下:
Flume 将日志数据从多个 Web 服务器有效地提取到集中存储(HDFS、HBase)中。
使用 Flume,我们可以将多个服务器的数据立即获取到 Hadoop。
除了日志文件之外,Flume 还用于导入 Facebook 和 Twitter 等社交网站以及 Amazon 和 Flipkart 等电子商务网站生成的大量事件数据。
Flume 支持大量源和目标类型。
Flume 支持多跳流、扇入扇出流、上下文路由等。
Flume 可以水平缩放。
Apache Flume - Hadoop 中的数据传输
众所周知,大数据是无法使用传统计算技术处理的大型数据集的集合。大数据经过分析后会产生有价值的结果。Hadoop是一个开源框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。
流式传输/日志数据
一般来说,大多数要分析的数据将由各种数据源产生,例如应用程序服务器、社交网站、云服务器和企业服务器。该数据将采用日志文件和事件的形式。
日志文件- 一般来说,日志文件是列出操作系统中发生的事件/操作的文件。例如,Web 服务器会在日志文件中列出向服务器发出的每个请求。
在收集此类日志数据时,我们可以获得以下信息 -
- 应用程序性能并定位各种软硬件故障。
- 用户Behave并获得更好的业务洞察。
将数据传输到HDFS系统的传统方法是使用put命令。让我们看看如何使用put命令。
HDFS put命令
处理日志数据的主要挑战是将多个服务器生成的这些日志移动到 Hadoop 环境。
Hadoop文件系统 Shell提供将数据插入 Hadoop 并从中读取数据的命令。您可以使用put命令将数据插入 Hadoop,如下所示。
$ Hadoop fs –put /path of the required file /path in HDFS where to save the file
put 命令出现问题
我们可以使用Hadoop的put命令将数据从这些来源传输到HDFS。但是,它有以下缺点 -
使用put命令,我们一次只能传输一个文件,而数据生成器以更高的速率生成数据。由于对旧数据的分析不太准确,我们需要一个实时传输数据的解决方案。
如果我们使用put命令,则需要将数据打包并准备好上传。由于网络服务器不断生成数据,因此这是一项非常困难的任务。
这里我们需要的是一种解决方案,能够克服put命令的缺点,以更少的延迟将“流数据”从数据生成器传输到集中式存储(尤其是 HDFS)。
HDFS 的问题
在HDFS中,文件作为目录项存在,文件的长度在关闭之前将被视为零。例如,如果一个源正在将数据写入HDFS,并且在操作过程中网络中断(没有关闭文件),则写入文件的数据将会丢失。
因此我们需要一个可靠、可配置、可维护的系统来将日志数据传输到HDFS中。
注意- 在 POSIX 文件系统中,每当我们访问文件(例如执行写操作)时,其他程序仍然可以读取该文件(至少是文件的已保存部分)。这是因为该文件在关闭之前就已存在于光盘上。
可用的解决方案
要将流数据(日志文件、事件等)从各种来源发送到 HDFS,我们可以使用以下工具:
Facebook 的抄写员
Scribe 是一种非常流行的工具,用于聚合和流式传输日志数据。它旨在扩展到大量节点,并且对网络和节点故障具有鲁棒性。
阿帕奇·卡夫卡
Kafka 由 Apache 软件基金会开发。它是一个开源消息代理。使用 Kafka,我们可以处理高吞吐量和低延迟的 feed。
阿帕奇水槽
Apache Flume 是一种工具/服务/数据摄取机制,用于收集聚合并将大量流数据(例如日志数据、事件等)从各种网络服务器传输到集中式数据存储。
它是一种高度可靠、分布式、可配置的工具,主要设计用于将流数据从各种来源传输到 HDFS。
在本教程中,我们将通过一些示例详细讨论如何使用 Flume。
Apache Flume - 架构
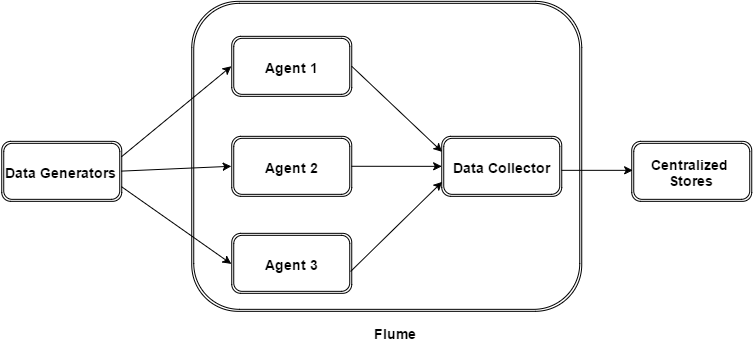
下图描述了 Flume 的基本架构。如图所示,数据生成器(例如 Facebook、Twitter)生成数据,这些数据由运行在其上的各个 Flume代理收集。此后,数据收集器(也是代理)从代理收集数据,并将其聚合并推送到集中式存储(例如 HDFS 或 HBase)中。
水槽事件
事件是Flume内部传输数据的基本单位。它包含字节数组的有效负载,该负载将伴随可选标头从源传输到目的地。典型的 Flume 事件将具有以下结构 -

水槽剂
Agent是Flume中的一个独立的守护进程(JVM)。它从客户端或其他代理接收数据(事件)并将其转发到下一个目的地(接收器或代理)。Flume 可能有多个代理。下图表示Flume Agent
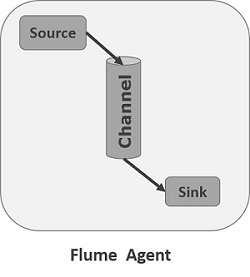
如图所示,Flume Agent 包含三个主要组件,即源、通道和接收器。
来源
源是 Agent 的组件,它从数据生成器接收数据并以 Flume 事件的形式将其传输到一个或多个通道。
Apache Flume 支持多种类型的源,每个源从指定的数据生成器接收事件。
示例- Avro 源、Thrift 源、twitter 1% 源等。
渠道
通道是一个临时存储,它从源接收事件并缓冲它们,直到它们被接收器消耗。它充当源和汇之间的桥梁。
这些通道是完全事务性的,并且可以与任意数量的源和接收器配合使用。
示例- JDBC 通道、文件系统通道、内存通道等。
下沉
接收器将数据存储到 HBase 和 HDFS 等集中存储中。它消耗来自通道的数据(事件)并将其传递到目的地。接收器的目的地可能是另一个代理或中央商店。
示例- HDFS 接收器
注意- 一个 Flume Agent 可以有多个源、汇和通道。我们在本教程的 Flume 配置章节中列出了所有支持的源、接收器、通道。
Flume Agent 的附加成分
我们上面讨论的是代理的原始组件。除此之外,我们还有一些组件在将事件从数据生成器传输到集中存储方面发挥着至关重要的作用。
拦截器
拦截器用于更改/检查在源和通道之间传输的水槽事件。
通道选择器
这些用于确定在多个通道的情况下选择哪个通道来传输数据。有两种类型的通道选择器 -
默认通道选择器- 这些也称为复制通道选择器,它们复制每个通道中的所有事件。
多路复用通道选择器- 这些选择器根据事件标头中的地址决定发送事件的通道。
接收器处理器
它们用于调用所选接收器组中的特定接收器。它们用于为您的接收器创建故障转移路径或跨通道的多个接收器负载平衡事件。
Apache Flume - 数据流
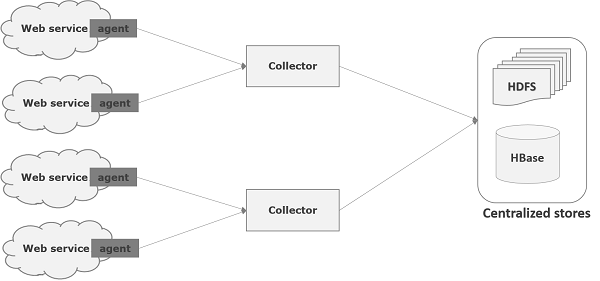
Flume 是一个用于将日志数据移动到 HDFS 的框架。一般来说,事件和日志数据是由日志服务器生成的,这些服务器上运行着 Flume 代理。这些代理从数据生成器接收数据。
这些代理中的数据将由称为Collector 的中间节点收集。就像代理一样,Flume 中可以有多个收集器。
最后,来自所有这些收集器的数据将被聚合并推送到集中存储,例如 HBase 或 HDFS。下图解释了 Flume 中的数据流。
多跳流
在 Flume 中,可以有多个代理,并且在到达最终目的地之前,一个事件可能会经过多个代理。这称为多跳流。
扇出流
从一个源到多个通道的数据流称为扇出流。它有两种类型 -
复制- 数据将在所有配置的通道中复制的数据流。
多路复用- 数据将被发送到事件标题中提到的选定通道的数据流。
扇入流
数据从多个源传输到一个通道的数据流称为扇入流。
故障处理
在 Flume 中,对于每个事件,都会发生两笔交易:一笔在发送方,一笔在接收方。发送者将事件发送到接收者。接收到数据后不久,接收方就会提交自己的事务并向发送方发送“已收到”信号。收到信号后,发送方提交其交易。(发送方在收到来自接收方的信号之前不会提交其事务。)
Apache Flume - 环境
我们在前面的章节中已经讨论了 Flume 的架构。在本章中,让我们看看如何下载和设置 Apache Flume。
在继续之前,您的系统中需要有一个 Java 环境。因此,首先,请确保您的系统中安装了 Java。对于本教程中的一些示例,我们使用了 Hadoop HDFS(作为接收器)。因此,我们建议您安装 Hadoop 和 Java。要收集更多信息,请点击链接 - https://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
安装 Flume
首先,从网站https://flume.apache.org/下载最新版本的 Apache Flume 软件。
步骤1
打开网站。单击主页左侧的下载链接。它将带您进入 Apache Flume 的下载页面。

第2步
在下载页面中,您可以看到 Apache Flume 的二进制文件和源文件的链接。单击链接apache-flume-1.6.0-bin.tar.gz
您将被重定向到镜像列表,您可以通过单击其中任意镜像来开始下载。同样,您可以通过点击apache-flume-1.6.0-src.tar.gz下载 Apache Flume 的源代码。
步骤3
在安装Hadoop、HBase和其他软件(如果已经安装)的安装目录同一目录中创建一个名为 Flume 的目录,如下所示。
$ mkdir Flume
步骤4
解压缩下载的 tar 文件,如下所示。
$ cd Downloads/ $ tar zxvf apache-flume-1.6.0-bin.tar.gz $ tar zxvf apache-flume-1.6.0-src.tar.gz
步骤5
将 apache- flume-1.6.0-bin.tar文件的内容移至之前创建的Flume目录,如下所示。(假设我们已经在名为Hadoop的本地用户中创建了Flume目录。)
$ mv apache-flume-1.6.0-bin.tar/* /home/Hadoop/Flume/
配置 Flume
要配置 Flume,我们必须修改三个文件,即Flume-env.sh、flumeconf.properties和bash.rc。
设置路径/类路径
在.bashrc文件中,设置 Flume 的主文件夹、路径和类路径,如下所示。
conf文件夹
如果打开Apache Flume 的conf文件夹,您将有以下四个文件 -
- Flume-conf.properties.template,
- Flume-env.sh.模板,
- Flume-env.ps1.template,和
- log4j.properties。
现在重命名
Flume-conf.properties.template文件作为Flume-conf.properties和
Flume-env.sh.template为Flume-env.sh
Flume-env.sh
打开flume-env.sh文件并将JAVA_Home设置为系统中安装Java 的文件夹。

验证安装
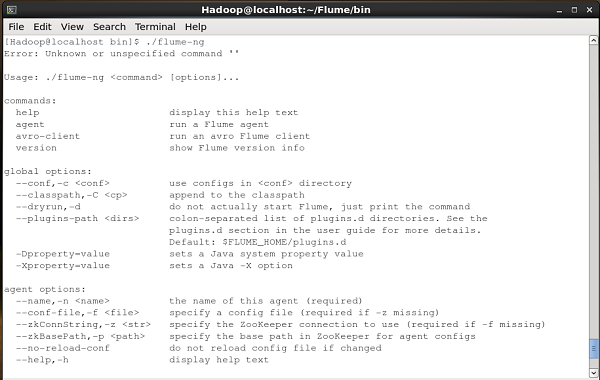
通过浏览bin文件夹并键入以下命令来验证 Apache Flume 的安装。
$ ./flume-ng
如果您已经成功安装Flume,您将得到如下所示的Flume帮助提示。
Apache Flume - 配置
安装完 Flume 后,我们需要使用配置文件来配置它,该配置文件是一个具有键值对的 Java 属性文件。我们需要将值传递给文件中的键。
在 Flume 配置文件中,我们需要 -
- 命名当前代理的组件。
- 描述/配置源。
- 描述/配置接收器。
- 描述/配置通道。
- 将源和接收器绑定到通道。
通常我们在 Flume 中可以有多个代理。我们可以通过使用唯一的名称来区分每个代理。使用这个名称,我们必须配置每个代理。
命名组件
首先,您需要命名/列出代理的源、接收器和通道等组件,如下所示。
agent_name.sources = source_name agent_name.sinks = sink_name agent_name.channels = channel_name
Flume 支持各种源、接收器和通道。它们列于下表中。
| 来源 | 渠道 | 水槽 |
|---|---|---|
|
|
|
您可以使用其中任何一个。例如,如果您使用 Twitter 源通过内存通道将 Twitter 数据传输到 HDFS 接收器,并且代理名称 id TwitterAgent,则
TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS
列出代理的组件后,您必须通过为其属性提供值来描述源、接收器和通道。
描述来源
每个源都有一个单独的属性列表。名为“type”的属性对于每个源都是通用的,它用于指定我们正在使用的源的类型。
除了属性“type”之外,还需要提供特定源的所有必需属性的值来配置它,如下所示。
agent_name.sources. source_name.type = value agent_name.sources. source_name.property2 = value agent_name.sources. source_name.property3 = value
例如,如果我们考虑twitter 源,则以下是我们必须为其提供值以对其进行配置的属性。
TwitterAgent.sources.Twitter.type = Twitter (type name) TwitterAgent.sources.Twitter.consumerKey = TwitterAgent.sources.Twitter.consumerSecret = TwitterAgent.sources.Twitter.accessToken = TwitterAgent.sources.Twitter.accessTokenSecret =
描述水槽
就像源一样,每个接收器都将有一个单独的属性列表。名为“type”的属性对于每个接收器都是通用的,它用于指定我们正在使用的接收器的类型。除了属性“type”之外,还需要为特定接收器的所有必需属性提供值以对其进行配置,如下所示。
agent_name.sinks. sink_name.type = value agent_name.sinks. sink_name.property2 = value agent_name.sinks. sink_name.property3 = value
例如,如果我们考虑HDFS sink ,则以下是我们必须提供值来配置它的属性。
TwitterAgent.sinks.HDFS.type = hdfs (type name) TwitterAgent.sinks.HDFS.hdfs.path = HDFS directory’s Path to store the data
描述频道
Flume 提供了各种通道在源和接收器之间传输数据。因此,除了来源和渠道之外,还需要描述代理中使用的渠道。
为了描述每个通道,您需要设置所需的属性,如下所示。
agent_name.channels.channel_name.type = value agent_name.channels.channel_name. property2 = value agent_name.channels.channel_name. property3 = value
例如,如果我们考虑内存通道,则以下是我们必须为其提供值以对其进行配置的属性。
TwitterAgent.channels.MemChannel.type = memory (type name)
将 Source 和 Sink 绑定到 Channel
由于通道连接源和接收器,因此需要将它们都绑定到通道,如下所示。
agent_name.sources.source_name.channels = channel_name agent_name.sinks.sink_name.channels = channel_name
以下示例显示如何将源和接收器绑定到通道。在这里,我们考虑twitter 源、内存通道和HDFS 接收器。
TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sinks.HDFS.channels = MemChannel
启动 Flume 代理
配置完成后,我们必须启动Flume代理。其操作如下 -
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf Dflume.root.logger=DEBUG,console -n TwitterAgent
其中 -
agent - 启动 Flume 代理的命令
--conf ,-c<conf> - 使用conf目录中的配置文件
-f<file> - 指定配置文件路径(如果缺少)
--name, -n <name> - twitter 代理的名称
-D property =value - 设置 Java 系统属性值。
Apache Flume - 获取 Twitter 数据
使用 Flume,我们可以从各种服务获取数据并将其传输到集中存储(HDFS 和 HBase)。本章介绍如何使用 Apache Flume 从 Twitter 服务获取数据并将其存储在 HDFS 中。
正如 Flume 架构中所讨论的,网络服务器生成日志数据,并且该数据由 Flume 中的代理收集。通道将这些数据缓冲到接收器,接收器最终将其推送到集中存储。
在本章提供的示例中,我们将创建一个应用程序并使用 Apache Flume 提供的实验性 Twitter 源从中获取推文。我们将使用内存通道来缓冲这些推文,并使用 HDFS 接收器将这些推文推送到 HDFS。

要获取 Twitter 数据,我们必须遵循以下步骤 -
- 创建一个 Twitter 应用程序
- 安装/启动HDFS
- 配置 Flume
创建 Twitter 应用程序
为了从 Twitter 获取推文,需要创建一个 Twitter 应用程序。按照下面给出的步骤创建 Twitter 应用程序。
步骤1
要创建 Twitter 应用程序,请单击以下链接https://apps.twitter.com/。登录您的 Twitter 帐户。您将有一个 Twitter 应用程序管理窗口,您可以在其中创建、删除和管理 Twitter 应用程序。

第2步
单击创建新应用程序按钮。您将被重定向到一个窗口,您将在其中获得一份申请表,您必须在其中填写详细信息才能创建应用程序。填写网站地址时,请给出完整的 URL 模式,例如http://example.com。

步骤3
填写详细信息,完成后接受开发者协议,单击页面底部的“创建 Twitter 应用程序”按钮。如果一切顺利,将使用给定的详细信息创建一个应用程序,如下所示。

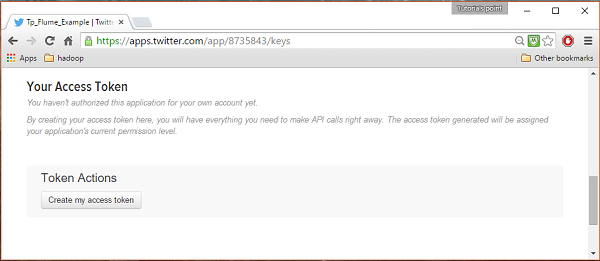
步骤4
在页面底部的“密钥和访问令牌”选项卡下,您可以看到一个名为“创建我的访问令牌”的按钮。单击它以生成访问令牌。
步骤5
最后,单击页面右上角的“测试 OAuth”按钮。这将导致一个页面显示您的Consumer key、Consumer Secret、Access token和Access token Secret。复制这些详细信息。这些对于在 Flume 中配置代理很有用。

启动HDFS
由于我们将数据存储在 HDFS 中,因此我们需要安装/验证 Hadoop。启动Hadoop并在其中创建一个文件夹来存储Flume数据。在配置 Flume 之前,请按照以下步骤操作。
第 1 步:安装/验证 Hadoop
安装Hadoop。如果您的系统中已安装 Hadoop,请使用 Hadoop version 命令验证安装,如下所示。
$ hadoop version
如果您的系统包含 Hadoop,并且设置了路径变量,那么您将得到以下输出 -
Hadoop 2.6.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
第2步:启动Hadoop
浏览Hadoop的sbin目录,启动yarn和Hadoop dfs(分布式文件系统),如下图。
cd /$Hadoop_Home/sbin/ $ start-dfs.sh localhost: starting namenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out localhost: starting datanode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out Starting secondary namenodes [0.0.0.0] starting secondarynamenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out $ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out localhost: starting nodemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.out
步骤3:在HDFS中创建目录
在 Hadoop DFS 中,您可以使用命令mkdir创建目录。浏览它并在所需路径中创建一个名为twitter_data 的目录,如下所示。
$cd /$Hadoop_Home/bin/ $ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_data
配置 Flume
我们必须使用conf文件夹中的配置文件来配置源、通道和接收器。本章给出的示例使用 Apache Flume 提供的实验源,名为Twitter 1% Firehose Memory 通道和 HDFS 接收器。
Twitter 1% Firehose 来源
这个来源是高度实验性的。它使用流 API 连接到 1% 示例 Twitter Firehose,持续下载推文,将其转换为 Avro 格式,并将 Avro 事件发送到下游 Flume 接收器。
我们将在安装 Flume 时默认获取此源。与该源对应的 jar文件可以位于lib文件夹中,如下所示。

设置类路径
在Flume-env.sh文件中将类路径变量设置为Flume 的lib文件夹,如下所示。
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*
该源需要Twitter 应用程序的消费者密钥、消费者秘密、访问令牌和访问令牌秘密等详细信息。配置此源时,您必须为以下属性提供值 -
渠道
源类型:org.apache.flume.source.twitter.TwitterSource
ConsumerKey - OAuth 消费者密钥
ConsumerSecret - OAuth 消费者秘密
accessToken - OAuth 访问令牌
accessTokenSecret - OAuth 令牌秘密
maxBatchSize - Twitter 批次中应包含的 Twitter 消息的最大数量。默认值为 1000(可选)。
maxBatchDurationMillis - 关闭批次之前等待的最大毫秒数。默认值为 1000(可选)。
渠道
我们正在使用内存通道。要配置内存通道,您必须为通道类型提供值。
type - 它保存通道的类型。在我们的示例中,类型是MemChannel。
容量- 通道中存储的最大事件数。其默认值为 100(可选)。
TransactionCapacity - 这是通道接受或发送的最大事件数。其默认值为 100(可选)。
HDFS 接收器
该接收器将数据写入 HDFS。要配置此接收器,您必须提供以下详细信息。
渠道
类型- hdfs
hdfs.path - HDFS 中存储数据的目录路径。
我们可以根据场景提供一些可选值。下面给出的是我们在应用程序中配置的 HDFS 接收器的可选属性。
fileType - 这是我们的 HDFS 文件所需的文件格式。SequenceFile、DataStream和CompressedStream是此流可用的三种类型。在我们的示例中,我们使用DataStream。
writeFormat - 可以是文本或可写。
batchSize - 它是在将文件刷新到 HDFS 之前写入文件的事件数。其默认值为 100。
rollsize - 触发滚动的文件大小。它的默认值为 100。
rollCount - 它是在滚动之前写入文件的事件数。它的默认值为 10。
示例 – 配置文件
下面给出的是配置文件的示例。复制此内容并在 Flume 的conf文件夹中另存为twitter.conf 。
# Naming the components on the current agent. TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS # Describing/Configuring the source TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql # Describing/Configuring the sink TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/ TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000 TwitterAgent.sinks.HDFS.hdfs.rollSize = 0 TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000 # Describing/Configuring the channel TwitterAgent.channels.MemChannel.type = memory TwitterAgent.channels.MemChannel.capacity = 10000 TwitterAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sinks.HDFS.channel = MemChannel
执行
浏览 Flume 主目录并执行应用程序,如下所示。
$ cd $FLUME_HOME $ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf Dflume.root.logger=DEBUG,console -n TwitterAgent
如果一切顺利,推文将开始流式传输到 HDFS。下面给出的是获取推文时命令提示符窗口的快照。

验证HDFS
您可以使用下面给出的 URL 访问 Hadoop 管理 Web UI。
http://localhost:50070/
单击页面右侧名为“实用程序”的下拉列表。您可以看到两个选项,如下面的快照所示。

单击“浏览文件系统”并输入存储推文的 HDFS 目录的路径。在我们的示例中,路径为/user/Hadoop/twitter_data/。然后,您可以看到存储在 HDFS 中的 twitter 日志文件列表,如下所示。

Apache Flume - 序列生成器源
在上一章中,我们了解了如何从 twitter 源获取数据到 HDFS。本章介绍如何从序列生成器获取数据。
先决条件
要运行本章提供的示例,您需要安装HDFS和Flume。因此,在继续操作之前,请验证 Hadoop 安装并启动 HDFS。(参考上一章了解如何启动HDFS)。
配置 Flume
我们必须使用conf文件夹中的配置文件来配置源、通道和接收器。本章给出的示例使用序列生成器源、内存通道和HDFS 接收器。
序列发生器源
它是不断产生事件的源头。它维护一个从0开始并以1递增的计数器。它用于测试目的。配置此源时,您必须为以下属性提供值 -
渠道
源类型- seq
渠道
我们正在使用内存通道。要配置内存通道,您必须为通道类型提供一个值。下面给出了配置内存通道时需要提供的属性列表 -
type - 它保存通道的类型。在我们的示例中,类型是 MemChannel。
容量- 通道中存储的最大事件数。其默认值为 100。(可选)
TransactionCapacity - 这是通道接受或发送的最大事件数。其默认值为 100。(可选)。
HDFS 接收器
该接收器将数据写入 HDFS。要配置此接收器,您必须提供以下详细信息。
渠道
类型- hdfs
hdfs.path - HDFS 中存储数据的目录路径。
我们可以根据场景提供一些可选值。下面给出的是我们在应用程序中配置的 HDFS 接收器的可选属性。
fileType - 这是我们的 HDFS 文件所需的文件格式。SequenceFile、DataStream和CompressedStream是此流可用的三种类型。在我们的示例中,我们使用DataStream。
writeFormat - 可以是文本或可写。
batchSize - 它是在将文件刷新到 HDFS 之前写入文件的事件数。其默认值为 100。
rollsize - 触发滚动的文件大小。它的默认值为 100。
rollCount - 它是在滚动之前写入文件的事件数。它的默认值为 10。
示例 – 配置文件
下面给出的是配置文件的示例。复制此内容并在 Flume 的conf文件夹中另存为seq_gen.conf 。
# Naming the components on the current agent SeqGenAgent.sources = SeqSource SeqGenAgent.channels = MemChannel SeqGenAgent.sinks = HDFS # Describing/Configuring the source SeqGenAgent.sources.SeqSource.type = seq # Describing/Configuring the sink SeqGenAgent.sinks.HDFS.type = hdfs SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/ SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0 SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000 SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream # Describing/Configuring the channel SeqGenAgent.channels.MemChannel.type = memory SeqGenAgent.channels.MemChannel.capacity = 1000 SeqGenAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel SeqGenAgent.sources.SeqSource.channels = MemChannel SeqGenAgent.sinks.HDFS.channel = MemChannel
执行
浏览 Flume 主目录并执行应用程序,如下所示。
$ cd $FLUME_HOME $./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf --name SeqGenAgent
如果一切顺利,源开始生成序列号,这些序列号将以日志文件的形式推送到 HDFS 中。
下面给出的是命令提示符窗口的快照,该窗口将序列生成器生成的数据提取到 HDFS 中。

验证 HDFS
您可以使用以下 URL 访问 Hadoop 管理 Web UI -
http://localhost:50070/
单击页面右侧名为“实用程序”的下拉列表。您可以看到两个选项,如下图所示。
单击“浏览文件系统”并输入存储序列生成器生成的数据的 HDFS 目录的路径。
在我们的示例中,路径为/user/Hadoop/ seqgen_data /。然后,您可以看到序列生成器生成的日志文件列表,存储在 HDFS 中,如下所示。
验证文件的内容
所有这些日志文件都包含顺序格式的数字。您可以使用cat命令验证文件系统中这些文件的内容,如下所示。

Apache Flume - NetCat 源
本章通过一个示例来解释如何生成事件并将其记录到控制台。为此,我们使用NetCat源和记录器接收器。
先决条件
要运行本章提供的示例,您需要安装Flume。
配置 Flume
我们必须使用conf文件夹中的配置文件来配置源、通道和接收器。本章给出的示例使用NetCat Source、Memory Channel和logger sink。
网猫来源
在配置NetCat源时,我们必须在配置源时指定端口。现在,源(NetCat 源)监听给定的端口,并接收我们在该端口中输入的每一行作为单个事件,并通过指定的通道将其传输到接收器。
配置此源时,您必须为以下属性提供值 -
渠道
源类型- netcat
bind - 要绑定的主机名或 IP 地址。
port - 我们希望源监听的端口号。
渠道
我们正在使用内存通道。要配置内存通道,您必须为通道类型提供一个值。下面给出了配置内存通道时需要提供的属性列表 -
type - 它保存通道的类型。在我们的示例中,类型是MemChannel。
容量- 通道中存储的最大事件数。其默认值为 100。(可选)
TransactionCapacity - 这是通道接受或发送的最大事件数。其默认值为 100。(可选)。
记录器接收器
该接收器记录传递给它的所有事件。通常,它用于测试或调试目的。要配置此接收器,您必须提供以下详细信息。
渠道
类型- 记录器
配置文件示例
下面给出的是配置文件的示例。复制此内容并在 Flume 的conf文件夹中另存为netcat.conf 。
# Naming the components on the current agent NetcatAgent.sources = Netcat NetcatAgent.channels = MemChannel NetcatAgent.sinks = LoggerSink # Describing/Configuring the source NetcatAgent.sources.Netcat.type = netcat NetcatAgent.sources.Netcat.bind = localhost NetcatAgent.sources.Netcat.port = 56565 # Describing/Configuring the sink NetcatAgent.sinks.LoggerSink.type = logger # Describing/Configuring the channel NetcatAgent.channels.MemChannel.type = memory NetcatAgent.channels.MemChannel.capacity = 1000 NetcatAgent.channels.MemChannel.transactionCapacity = 100 # Bind the source and sink to the channel NetcatAgent.sources.Netcat.channels = MemChannel NetcatAgent.sinks. LoggerSink.channel = MemChannel
执行
浏览 Flume 主目录并执行应用程序,如下所示。
$ cd $FLUME_HOME $ ./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/netcat.conf --name NetcatAgent -Dflume.root.logger=INFO,console
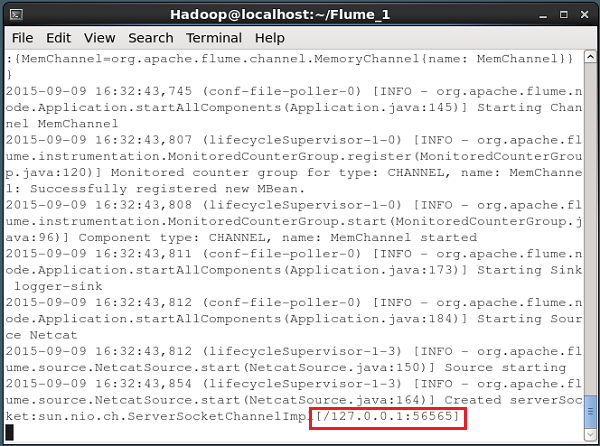
如果一切顺利,源将开始监听给定的端口。在本例中,它是56565。下面给出的是 NetCat 源的命令提示符窗口的快照,该源已启动并侦听端口 56565。
将数据传递到源
要将数据传递到 NetCat 源,您必须打开配置文件中给出的端口。打开一个单独的终端并使用curl命令连接到源(56565)。连接成功后,您将收到一条消息“已连接”,如下所示。
$ curl telnet://localhost:56565 connected
现在您可以逐行输入数据(每行之后,您必须按 Enter 键)。NetCat 源将每一行作为单独的事件接收,您将收到一条收到的消息“ OK ”。
每当您完成传递数据时,您可以按 ( Ctrl+C ) 退出控制台。下面给出的是我们使用curl命令连接到源的控制台的快照。
在上述控制台中输入的每一行都将作为单个事件由源接收。由于我们使用了Logger接收器,因此这些事件将通过指定的通道(本例中为内存通道)记录到控制台(源控制台)。
以下快照显示了记录事件的 NetCat 控制台。
