- Apache Tajo 教程
- Apache Tajo - 主页
- Apache Tajo - 简介
- Apache Tajo - 架构
- Apache Tajo - 安装
- Apache Tajo - 配置设置
- Apache Tajo - Shell 命令
- Apache Tajo - 数据类型
- Apache Tajo - 操作员
- Apache Tajo - SQL 函数
- Apache Tajo - 数学函数
- Apache Tajo - 字符串函数
- Apache Tajo - 日期时间函数
- Apache Tajo - JSON 函数
- Apache Tajo - 数据库创建
- Apache Tajo - 表管理
- Apache Tajo - SQL 语句
- 聚合和窗口函数
- Apache Tajo - SQL 查询
- Apache Tajo - 存储插件
- 与 HBase 集成
- Apache Tajo - 与 Hive 集成
- OpenStack Swift 集成
- Apache Tajo - JDBC 接口
- Apache Tajo - 自定义函数
- Apache Tajo 有用资源
- Apache Tajo - 快速指南
- Apache Tajo - 有用的资源
- Apache Tajo - 讨论
Apache Tajo - 快速指南
Apache Tajo - 简介
分布式数据仓库系统
数据仓库是一种关系数据库,旨在查询和分析而不是事务处理。它是一个面向主题的、集成的、时变的、非易失性的数据集合。这些数据可以帮助分析师在组织中做出明智的决策,但关系数据量正在日益增加。
为了克服这些挑战,分布式数据仓库系统在多个数据存储库之间共享数据,以实现在线分析处理(OLAP)。每个数据仓库可能属于一个或多个组织。它执行负载平衡和可扩展性。元数据被复制并集中分布。
Apache Tajo 是一个分布式数据仓库系统,它使用 Hadoop 分布式文件系统(HDFS)作为存储层,并拥有自己的查询执行引擎而不是 MapReduce 框架。
Hadoop 上的 SQL 概述
Hadoop 是一个开源框架,允许在分布式环境中存储和处理大数据。它速度极快且功能强大。然而,Hadoop 的查询能力有限,因此借助 SQL on Hadoop 可以进一步提高其性能。这允许用户通过简单的 SQL 命令与 Hadoop 交互。
Hadoop 应用程序上的 SQL 的一些示例包括 Hive、Impala、Drill、Presto、Spark、HAWQ 和 Apache Tajo。
什么是阿帕奇 Tajo
Apache Tajo 是一个关系型分布式数据处理框架。它专为低延迟和可扩展的即席查询分析而设计。
Tajo 支持标准 SQL 和各种数据格式。大多数 Tajo 查询无需任何修改即可执行。
Tajo通过失败任务的重启机制和可扩展的查询重写引擎实现容错。
Tajo 执行必要的ETL(提取转换和加载过程)操作来汇总存储在 HDFS 上的大型数据集。它是 Hive/Pig 的替代选择。
最新版本的 Tajo 与 Java 程序和第三方数据库(例如 Oracle 和 PostGreSQL)具有更好的连接性。
Apache Tajo 的特点
Apache Tajo 具有以下功能 -
- 卓越的可扩展性和优化的性能
- 低延迟
- 用户定义函数
- 行/列存储处理框架。
- 与 HiveQL 和 Hive MetaStore 的兼容性
- 数据流程简单,维护方便。
Apache Tajo 的优点
Apache Tajo 具有以下优点 -
- 便于使用
- 简化的架构
- 基于成本的查询优化
- 向量化查询执行计划
- 交货快
- 简单的I/O机制,支持多种类型的存储。
- 容错能力
Apache Tajo 的用例
以下是 Apache Tajo 的一些用例 -
数据仓储和分析
韩国 SK Telecom 公司对 1.7 TB 的数据运行 Tajo,发现它可以比 Hive 或 Impala 更快地完成查询。
数据发现
韩国音乐流媒体服务 Melon 使用 Tajo 进行分析处理。Tajo 执行 ETL(提取-转换-加载过程)作业的速度比 Hive 快 1.5 到 10 倍。
日志分析
Bluehole Studio 是一家韩国公司,开发了《TERA》——一款奇幻多人在线游戏。该公司使用 Tajo 进行游戏日志分析并查找服务质量中断的主要原因。
存储和数据格式
Apache Tajo 支持以下数据格式 -
- JSON
- 文本文件(CSV)
- 实木复合地板
- 序列文件
- AVRO
- 协议缓冲区
- 阿帕奇兽人
Tajo 支持以下存储格式 -
- 分布式文件系统
- 数据库连接
- 亚马逊S3
- 阿帕奇HBase
- 弹性搜索
Apache Tajo - 架构
下图描述了 Apache Tajo 的架构。

下表详细描述了每个组件。
| 编号 | 组件及描述 |
|---|---|
| 1 | 客户 Client将SQL语句提交给Tajo Master以获取结果。 |
| 2 | 掌握 Master 是主要守护进程。它负责查询规划,并且是工作人员的协调员。 |
| 3 | 目录服务器 维护表和索引的描述。它嵌入在主守护进程中。目录服务器使用 Apache Derby 作为存储层并通过 JDBC 客户端进行连接。 |
| 4 | 工人 主节点将任务分配给工作节点。TajoWorker 处理数据。随着TajoWorkers数量的增加,处理能力也线性增加。 |
| 5 | 查询大师 Tajo master 将查询分配给 Query Master。查询主机负责控制分布式执行计划。它启动 TaskRunner 并将任务安排到 TaskRunner。Query Master的主要作用是监控正在运行的任务并将其报告给Master节点。 |
| 6 | 节点管理器 管理worker节点的资源。它决定将请求分配给节点。 |
| 7 | 任务运行器 充当本地查询执行引擎。它用于运行和监视查询过程。TaskRunner 一次处理一个任务。 它具有以下三个主要属性 -
|
| 8 | 查询执行器 它用于执行查询。 |
| 9 | 仓储服务 将底层数据存储连接到 Tajo。 |
工作流程
Tajo 使用 Hadoop 分布式文件系统(HDFS)作为存储层,并拥有自己的查询执行引擎而不是 MapReduce 框架。一个 Tajo 集群由一个主节点和跨集群节点的多个工作节点组成。
master主要负责查询规划,worker的协调者。master将查询分成小任务并分配给worker。每个工作线程都有一个本地查询引擎,用于执行物理运算符的有向无环图。
此外,Tajo可以比MapReduce更灵活地控制分布式数据流,并支持索引技术。
Tajo 基于网络的界面具有以下功能 -
- 用于查找如何计划提交的查询的选项
- 用于查找查询如何跨节点分布的选项
- 检查集群和节点状态的选项
Apache Tajo - 安装
要安装 Apache Tajo,您的系统上必须有以下软件 -
- Hadoop 版本 2.3 或更高版本
- Java 版本 1.7 或更高版本
- Linux 或 Mac 操作系统
现在让我们继续执行以下步骤来安装 Tajo。
验证 Java 安装
希望您已经在计算机上安装了 Java 版本 8。现在,您只需继续验证即可。
要验证,请使用以下命令 -
$ java -version
如果 Java 已成功安装在您的计算机上,您可以看到已安装 Java 的当前版本。如果未安装 Java,请按照以下步骤在您的计算机上安装 Java 8。
下载JDK
通过访问以下链接下载最新版本的 JDK,然后下载最新版本。
最新版本是JDK 8u 92,文件是“jdk-8u92-linux-x64.tar.gz”。请将文件下载到您的机器上。接下来,提取文件并将它们移动到特定目录。现在,设置 Java 替代项。最后,Java 安装在您的计算机上。
验证 Hadoop 安装
您已经在系统上安装了Hadoop 。现在,使用以下命令验证它 -
$ hadoop version
如果您的设置一切正常,那么您可以看到 Hadoop 的版本。如果未安装 Hadoop,请访问以下链接下载并安装 Hadoop - https://www.apache.org
Apache Tajo 安装
Apache Tajo 提供两种执行模式——本地模式和完全分布式模式。验证 Java 和 Hadoop 安装后,请继续执行以下步骤在您的计算机上安装 Tajo 集群。本地模式 Tajo 实例需要非常简单的配置。
通过访问以下链接下载最新版本的 Tajo - https://www.apache.org/dyn/closer.cgi/tajo
现在您可以从您的计算机下载文件“tajo-0.11.3.tar.gz”。
提取 Tar 文件
使用以下命令提取 tar 文件 -
$ cd opt/ $ tar tajo-0.11.3.tar.gz $ cd tajo-0.11.3
设置环境变量
将以下更改添加到“conf/tajo-env.sh”文件中
$ cd tajo-0.11.3 $ vi conf/tajo-env.sh # Hadoop home. Required export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2 # The java implementation to use. Required. export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/
在这里,您必须指定“tajo-env.sh”文件的 Hadoop 和 Java 路径。进行更改后,保存文件并退出终端。
启动 Tajo 服务器
要启动 Tajo 服务器,请执行以下命令 -
$ bin/start-tajo.sh
您将收到类似于以下内容的回复 -
Starting single TajoMaster starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../ localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/ Tajo master web UI: http://local:26080 Tajo Client Service: local:26002
现在,输入命令“jps”来查看正在运行的守护进程。
$ jps 1010 TajoWorker 1140 Jps 933 TajoMaster
启动 Tajo Shell (Tsql)
要启动 Tajo shell 客户端,请使用以下命令 -
$ bin/tsql
您将收到以下输出 -
welcome to _____ ___ _____ ___ /_ _/ _ |/_ _/ / / // /_| |_/ // / / /_//_/ /_/___/ \__/ 0.11.3 Try \? for help.
退出 Tajo 壳牌
执行以下命令退出 Tsql -
default> \q bye!
这里默认是指Tajo中的目录。
网页用户界面
输入以下 URL 以启动 Tajo Web UI - http://localhost:26080/
您现在将看到以下屏幕,该屏幕与 ExecuteQuery 选项类似。
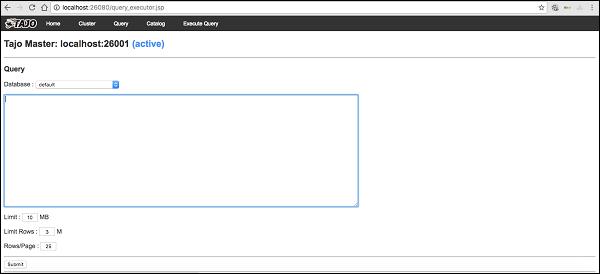
停止塔霍
要停止 Tajo 服务器,请使用以下命令 -
$ bin/stop-tajo.sh
您将得到以下响应 -
localhost: stopping worker stopping master
Apache Tajo - 配置设置
Tajo的配置是基于Hadoop的配置系统。本章详细介绍 Tajo 配置设置。
基本设置
Tajo 使用以下两个配置文件 -
- Catalog-site.xml - 目录服务器的配置。
- tajo-site.xml - 其他 Tajo 模块的配置。
分布式模式配置
分布式模式设置在 Hadoop 分布式文件系统 (HDFS) 上运行。让我们按照以下步骤配置 Tajo 分布式模式设置。
tajo-site.xml
该文件位于/path/to/tajo/conf目录中,并充当其他 Tajo 模块的配置。要以分布式模式访问 Tajo,请将以下更改应用于“tajo-site.xml”。
<property> <name>tajo.rootdir</name> <value>hdfs://hostname:port/tajo</value> </property> <property> <name>tajo.master.umbilical-rpc.address</name> <value>hostname:26001</value> </property> <property> <name>tajo.master.client-rpc.address</name> <value>hostname:26002</value> </property> <property> <name>tajo.catalog.client-rpc.address</name> <value>hostname:26005</value> </property>
主节点配置
Tajo 使用 HDFS 作为主要存储类型。配置如下,应添加到“tajo-site.xml”中。
<property> <name>tajo.rootdir</name> <value>hdfs://namenode_hostname:port/path</value> </property>
目录配置
如果要自定义目录服务,请将$path/to/Tajo/conf/catalogsite.xml.template复制到$path/to/Tajo/conf/catalog-site.xml并根据需要添加以下任意配置。
例如,如果您使用“Hive Catalog Store”访问 Tajo,则配置应如下所示 -
<property> <name>tajo.catalog.store.class</name> <value>org.apache.tajo.catalog.store.HCatalogStore</value> </property>
如果您需要存储MySQL目录,请应用以下更改 -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>
同样,您可以在配置文件中注册其他 Tajo 支持的目录。
工作人员配置
默认情况下,TajoWorker 将临时数据存储在本地文件系统上。它在“tajo-site.xml”文件中定义如下 -
<property> <name>tajo.worker.tmpdir.locations</name> <value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value> </property>
要增加每个工作资源运行任务的能力,请选择以下配置 -
<property> <name>tajo.worker.resource.cpu-cores</name> <value>12</value> </property> <property> <name>tajo.task.resource.min.memory-mb</name> <value>2000</value> </property> <property> <name>tajo.worker.resource.disks</name> <value>4</value> </property>
要使 Tajo Worker 在专用模式下运行,请选择以下配置 -
<property> <name>tajo.worker.resource.dedicated</name> <value>true</value> </property>
Apache Tajo - Shell 命令
在本章中,我们将详细了解 Tajo Shell 命令。
要执行 Tajo shell 命令,您需要使用以下命令启动 Tajo 服务器和 Tajo shell -
启动服务器
$ bin/start-tajo.sh
启动外壳
$ bin/tsql
上面的命令现在可以执行了。
元命令
现在让我们讨论元命令。Tsql 元命令以反斜杠('\')开头。
帮助命令
“\?” 命令用于显示帮助选项。
询问
默认> \?
结果
上面的\? 命令列出了 Tajo 中的所有基本使用选项。您将收到以下输出 -

列出数据库
要列出 Tajo 中的所有数据库,请使用以下命令 -
询问
default> \l
结果
您将收到以下输出 -
information_schema default
目前,我们还没有创建任何数据库,因此它显示了两个内置的 Tajo 数据库。
当前数据库
\c选项用于显示当前数据库名称。
询问
default> \c
结果
您现在已作为用户“username”连接到数据库“default”。
列出内置函数
要列出所有内置函数,请键入查询,如下所示 -
询问
default> \df
结果
您将收到以下输出 -

描述功能
\df 函数名称- 此查询返回给定函数的完整描述。
询问
default> \df sqrt
结果
您将收到以下输出 -

退出终端
要退出终端,请输入以下查询 -
询问
default> \q
结果
您将收到以下输出 -
bye!
管理命令
Tajo shell 提供\admin选项来列出所有管理功能。
询问
default> \admin
结果
您将收到以下输出 -

集群信息
要显示 Tajo 中的集群信息,请使用以下查询
询问
default> \admin -cluster
结果
您将收到以下输出 -

秀大师
以下查询显示当前的主信息。
询问
default> \admin -showmasters
结果
localhost
同样,您可以尝试其他管理命令。
会话变量
Tajo 客户端通过唯一的会话 ID 连接到 Master。会话一直有效,直到客户端断开连接或过期。
以下命令用于列出所有会话变量。
询问
default> \set
结果
'SESSION_LAST_ACCESS_TIME' = '1470206387146' 'CURRENT_DATABASE' = 'default' ‘USERNAME’ = 'user' 'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c' 'TIMEZONE' = 'Asia/Kolkata' 'FETCH_ROWNUM' = '200' ‘COMPRESSED_RESULT_TRANSFER' = 'false'
\ set key val将使用值val设置名为key的会话变量。例如,
询问
default> \set ‘current_database’='default'
结果
usage: \set [[NAME] VALUE]
在这里,您可以在\set命令中分配键和值。如果需要恢复更改,请使用\unset命令。
Apache Tajo - 数据类型
要在 Tajo shell 中执行查询,请打开终端并移至 Tajo 安装目录,然后键入以下命令 -
$ bin/tsql
您现在将看到如下程序所示的响应 -
default>
您现在可以执行查询。否则,您可以通过 Web 控制台应用程序运行查询到以下 URL - http://localhost:26080/
原始数据类型
Apache Tajo 支持以下原始数据类型列表 -
| 编号 | 数据类型和描述 |
|---|---|
| 1 | 整数 用于存储整数值,存储空间为 4 字节。 |
| 2 | 小整数 小整数值是 1 个字节 |
| 3 | 小整数 用于存储小尺寸整数 2 字节值。 |
| 4 | 大整数 大范围整数值有 8 个字节存储。 |
| 5 | 布尔值 返回真/假。 |
| 6 | 真实的 用于存储实际值。大小为 4 字节。 |
| 7 | 漂浮 浮点精度值,有4或8字节存储空间。 |
| 8 | 双倍的 双点精度值存储在 8 个字节中。 |
| 9 | 字符[(n)] 人物价值。 |
| 10 | varchar[(n)] 可变长度非 Unicode 数据。 |
| 11 | 数字 小数值。 |
| 12 | 二进制 二进制值。 |
| 13 | 日期 日历日期(年、月、日)。 示例- 日期“2016-08-22” |
| 14 | 时间 没有时区的一天中的时间(小时、分钟、秒、毫秒)。这种类型的值在会话时区中进行解析和呈现。 |
| 15 | 时区 带有时区的一天中的时间(小时、分钟、秒、毫秒)。这种类型的值是使用值中的时区来呈现的。 示例- TIME '01:02:03.456 亚洲/加尔各答' |
| 16 | 时间戳 即时时间,包括没有时区的日期和时间。 示例- TIMESTAMP '2016-08-22 03:04:05.321' |
| 17 号 | 文本 可变长度 Unicode 文本。 |
Apache Tajo - 操作员
Tajo 中使用以下运算符来执行所需的操作。
| 编号 | 运算符及描述 |
|---|---|
| 1 | 算术运算符
Presto 支持 +、−、*、/、% 等算术运算符。 |
| 2 | 关系运算符
<、>、<=、>=、=、<> |
| 3 | 逻辑运算符
与、或、非 |
| 4 | 字符串运算符
'||' 运算符执行字符串连接。 |
| 5 | 范围运算符
范围运算符用于测试特定范围内的值。Tajo 支持 BETWEEN、IS NULL、IS NOT NULL 运算符。 |
Apache Tajo - SQL 函数
到目前为止,您已经知道在 Tajo 上运行简单的基本查询。在接下来的几章中,我们将讨论以下 SQL 函数 -
Apache Tajo - 数学函数
数学函数根据数学公式进行运算。下表详细描述了函数列表。
| 编号 | 功能说明 |
|---|---|
| 1 | 绝对值(x)
返回 x 的绝对值。 |
| 2 | CBRT(x)
返回 x 的立方根。 |
| 3 | 上限(x)
返回向上舍入到最接近的整数的 x 值。 |
| 4 | 楼层(x)
返回 x 向下舍入到最接近的整数。 |
| 5 | 圆周率()
返回 pi 值。结果将以双精度值形式返回。 |
| 6 | 弧度(x)
将角度 x 转换为度弧度。 |
| 7 | 度(x)
返回 x 的度值。 |
| 8 | 战俘(x,p)
返回值 'p' 的 x 值幂。 |
| 9 | div(x,y)
返回给定两个 x,y 整数值的除法结果。 |
| 10 | 指数 (x)
返回欧拉数e的某个数次方。 |
| 11 | 开方(x)
返回 x 的平方根。 |
| 12 | 符号(x)
返回 x 的正负号函数,即 -
|
| 13 | 模(n,m)
返回 n 除以 m 的模(余数)。 |
| 14 | 轮(x)
返回 x 的舍入值。 |
| 15 | 余弦(x)
返回余弦值(x)。 |
| 16 | 阿信(x)
返回反正弦值 (x)。 |
| 17 号 | acos(x)
返回反余弦值(x)。 |
| 18 | 阿坦(x)
返回反正切值 (x)。 |
| 19 | atan2(y,x)
返回反正切值 (y/x)。 |
数据类型函数
下表列出了 Apache Tajo 中可用的数据类型函数。
| 编号 | 功能说明 |
|---|---|
| 1 | 到_bin(x)
返回整数的二进制表示形式。 |
| 2 | to_char(int,文本)
将整数转换为字符串。 |
| 3 | to_hex(x)
将 x 值转换为十六进制。 |
Apache Tajo - 字符串函数
下表列出了 Tajo 中的字符串函数。
| 编号 | 功能说明 |
|---|---|
| 1 | 连接(字符串1,...,字符串N)
连接给定的字符串。 |
| 2 | 长度(字符串)
返回给定字符串的长度。 |
| 3 | 较低(字符串)
返回字符串的小写格式。 |
| 4 | 上部(字符串)
返回给定字符串的大写格式。 |
| 5 | ascii(字符串文本)
返回文本第一个字符的 ASCII 代码。 |
| 6 | 位长度(字符串文本)
返回字符串中的位数。 |
| 7 | char_length(字符串文本)
返回字符串中的字符数。 |
| 8 | 八位字节长度(字符串文本)
返回字符串中的字节数。 |
| 9 | 摘要(输入文本,方法文本)
计算字符串的摘要哈希。这里,第二个arg方法指的是hash方法。 |
| 10 | initcap(字符串文本)
将每个单词的第一个字母转换为大写。 |
| 11 | md5(字符串文本)
计算字符串的MD5哈希值。 |
| 12 | 左(字符串文本,整数大小)
返回字符串中的前 n 个字符。 |
| 13 | 右(字符串文本,整数大小)
返回字符串中的最后 n 个字符。 |
| 14 | 定位(源文本,目标文本,起始索引)
返回指定子字符串的位置。 |
| 15 | strposb(源文本,目标文本)
返回指定子字符串的二进制位置。 |
| 16 | substr(源文本、起始索引、长度)
返回指定长度的子字符串。 |
| 17 号 | 修剪(字符串文本[,字符文本])
删除字符串开头/结尾/两端的字符(默认为空格)。 |
| 18 | split_part(字符串文本、分隔符文本、字段 int)
按分隔符拆分字符串并返回给定字段(从 1 开始计数)。 |
| 19 | regexp_replace(字符串文本、模式文本、替换文本)
替换与给定正则表达式模式匹配的子字符串。 |
| 20 | 反转(字符串)
对字符串执行反向操作。 |
Apache Tajo - 日期时间函数
Apache Tajo 支持以下日期时间函数。
| 编号 | 功能说明 |
|---|---|
| 1 | add_days(date 日期或时间戳, int 天
返回添加给定日期值的日期。 |
| 2 | add_months(日期日期或时间戳,int月份)
返回添加给定月份值的日期。 |
| 3 | 当前日期()
返回今天的日期。 |
| 4 | 当前时间()
返回今天的时间。 |
| 5 | 提取(日期/时间戳的世纪)
从给定参数中提取世纪。 |
| 6 | 提取(日期/时间戳中的日期)
从给定参数中提取日期。 |
| 7 | 提取(从日期/时间戳算起的十年)
从给定参数中提取十年。 |
| 8 | 摘录(道琼斯指数日期/时间戳)
从给定参数中提取星期几。 |
| 9 | 提取(从日期/时间戳中提取)
从给定参数中提取一年中的某一天。 |
| 10 | 选择提取(时间戳中的小时)
从给定参数中提取小时。 |
| 11 | 选择提取(来自时间戳的 isodow)
从给定参数中提取星期几。除周日外,这与道琼斯指数相同。这与 ISO 8601 星期编号相匹配。 |
| 12 | 选择摘录(从日期开始的等年)
从指定日期提取 ISO 年份。ISO 年份可能与公历年份不同。 |
| 13 | 提取(时间微秒)
从给定参数中提取微秒。秒字段,包括小数部分,乘以 1 000 000; |
| 14 | 提取(时间戳的千年)
从给定参数中提取千年。一千年对应于 1000 年。因此,第三个千年从 2001 年 1 月 1 日开始。 |
| 15 | 提取(从时间开始的毫秒数)
从给定参数中提取毫秒。 |
| 16 | 提取(时间戳中的分钟)
从给定参数中提取分钟。 |
| 17 号 | 提取(时间戳的四分之一)
从给定参数中提取一年中的季度 (1 - 4)。 |
| 18 | date_part(字段文本、源日期或时间戳或时间)
从文本中提取日期字段。 |
| 19 | 现在()
返回当前时间戳。 |
| 20 | to_char(时间戳,格式文本)
将时间戳转换为文本。 |
| 21 | to_date(源文本,格式文本)
将文本转换为日期。 |
| 22 | to_timestamp(源文本,格式文本)
将文本转换为时间戳。 |
Apache Tajo - JSON 函数
下表列出了 JSON 函数 -
| 编号 | 功能说明 |
|---|---|
| 1 | json_extract_path_text(文本上的js,json_path文本)
根据指定的 json 路径从 JSON 字符串中提取 JSON 字符串。 |
| 2 | json_array_get(json_array 文本,索引 int4)
将指定索引处的元素返回到 JSON 数组中。 |
| 3 | json_array_contains(json_数组文本,任意值)
确定给定值是否存在于 JSON 数组中。 |
| 4 | json_array_length(json_array 文本)
返回 json 数组的长度。 |
Apache Tajo - 数据库创建
本节介绍 Tajo DDL 命令。Tajo 有一个名为default的内置数据库。
创建数据库语句
Create Database是Tajo 中用于创建数据库的语句。该语句的语法如下 -
CREATE DATABASE [IF NOT EXISTS] <database_name>
询问
default> default> create database if not exists test;
结果
上述查询将生成以下结果。
OK
数据库是 Tajo 中的命名空间。一个数据库可以包含多个具有唯一名称的表。
显示当前数据库
要检查当前数据库名称,请发出以下命令 -
询问
default> \c
结果
上述查询将生成以下结果。
You are now connected to database "default" as user “user1". default>
连接到数据库
到目前为止,您已经创建了一个名为“test”的数据库。以下语法用于连接“test”数据库。
\c <database name>
询问
default> \c test
结果
上述查询将生成以下结果。
You are now connected to database "test" as user “user1”. test>
现在您可以看到从默认数据库到测试数据库的提示更改。
删除数据库
要删除数据库,请使用以下语法 -
DROP DATABASE <database-name>
询问
test> \c default You are now connected to database "default" as user “user1". default> drop database test;
结果
上述查询将生成以下结果。
OK
Apache Tajo - 表管理
表是一个数据源的逻辑视图。它由逻辑架构、分区、URL 和各种属性组成。Tajo 表可以是 HDFS 中的一个目录、单个文件、一个 HBase 表或一个 RDBMS 表。
Tajo 支持以下两种类型的表 -
- 外部表
- 内表
外部表
外部表在创建时需要位置属性。例如,如果您的数据已作为文本/JSON 文件或 HBase 表存在,则可以将其注册为 Tajo 外部表。
以下查询是外部表创建的示例。
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';
这里,
外部关键字- 用于创建外部表。这有助于在指定位置创建表。
Sample指的是表名。
位置- 它是 HDFS、Amazon S3、HBase 或本地文件系统的目录。要为目录分配位置属性,请使用以下 URI 示例 -
HDFS - hdfs://localhost:端口/路径/到/表
Amazon S3 - s3://bucket-name/table
本地文件系统- file:///path/to/table
Openstack Swift - swift://bucket-name/table
表属性
外部表具有以下属性 -
TimeZone - 用户可以指定读取或写入表的时区。
压缩格式- 用于使数据大小紧凑。例如,text/json 文件使用compression.codec属性。
内表
内部表也称为托管表。它是在称为表空间的预定义物理位置中创建的。
句法
create table table1(col1 int,col2 text);
默认情况下,Tajo 使用位于“conf/tajo-site.xml”中的“tajo.warehouse.directory”。要为表分配新位置,您可以使用表空间配置。
表空间
表空间用于定义存储系统中的位置。仅内部表支持它。您可以通过表空间的名称来访问它们。每个表空间可以使用不同的存储类型。如果您不指定表空间,Tajo 将使用根目录中的默认表空间。
表空间配置
您在 Tajo 中有“conf/tajo-site.xml.template”。复制文件并将其重命名为“storagesite.json”。该文件将充当表空间的配置。Tajo 数据格式使用以下配置 -
HDFS配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}
HBase配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}
文本文件配置
$ vi conf/storage-site.json {
"spaces": {
"${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}
表空间创建
Tajo 的内表记录只能从另一个表访问。您可以使用表空间对其进行配置。
句法
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name] [using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]
这里,
IF NOT EXISTS - 如果尚未创建相同的表,这可以避免错误。
TABLESPACE - 此子句用于分配表空间名称。
存储类型- Tajo 数据支持文本、JSON、HBase、Parquet、Sequencefile 和 ORC 等格式。
AS select 语句- 从另一个表中选择记录。
配置表空间
启动 Hadoop 服务并打开文件“conf/storage-site.json”,然后添加以下更改 -
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}
在这里,Tajo 将引用 HDFS 位置的数据,space1是表空间名称。如果不启动Hadoop服务,则无法注册表空间。
询问
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;
上面的查询创建了一个名为“table1”的表,“space1”指的是表空间名称。
数据格式
Tajo 支持数据格式。让我们一一详细了解每种格式。
文本
字符分隔值的纯文本文件表示由行和列组成的表格数据集。每行都是纯文本行。
创建表
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;
这里,“customers.csv”文件是指位于 Tajo 安装目录中的逗号分隔值文件。
要使用文本格式创建内部表,请使用以下查询 -
default> create table customer(id int,name text,address text,age int) using text;
在上面的查询中,您没有分配任何表空间,因此它将采用 Tajo 的默认表空间。
特性
文本文件格式具有以下属性 -
text.delimiter - 这是一个分隔符。默认为“|”。
Compression.codec - 这是一种压缩格式。默认情况下,它是禁用的。您可以使用指定的算法更改设置。
timezone - 用于读取或写入的表。
text.error-tolerance.max-num - 容差级别的最大数量。
text.skip.headerlines - 每次跳过的标题行数。
text.serde - 这是序列化属性。
JSON
Apache Tajo 支持 JSON 格式来查询数据。Tajo 将 JSON 对象视为 SQL 记录。一个对象等于 Tajo 表中的一行。让我们考虑“array.json”,如下所示 -
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}
创建此文件后,切换到 Tajo shell 并键入以下查询以使用 JSON 格式创建表。
询问
default> create external table sample (num1 int,num2 text,num3 float) using json location ‘json/array.json’;
始终记住文件数据必须与表架构匹配。否则,您可以省略列名称并使用 *,这不需要列列表。
要创建内部表,请使用以下查询 -
default> create table sample (num1 int,num2 text,num3 float) using json;
实木复合地板
Parquet 是一种列式存储格式。Tajo 使用 Parquet 格式实现轻松、快速、高效的访问。
表创建
以下查询是创建表的示例 -
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;
Parquet 文件格式具有以下属性 -
parquet.block.size - 内存中缓冲的行组的大小。
parquet.page.size - 页面大小用于压缩。
parquet.compression - 用于压缩页面的压缩算法。
parquet.enable.dictionary - 布尔值用于启用/禁用字典编码。
RC文件
RCFile 是记录列式文件。它由二进制键/值对组成。
表创建
以下查询是创建表的示例 -
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;
RCFile 具有以下属性 -
rcfile.serde - 自定义反序列化器类。
Compression.codec - 压缩算法。
rcfile.null - NULL 字符。
序列文件
SequenceFile 是 Hadoop 中的基本文件格式,由键/值对组成。
表创建
以下查询是创建表的示例 -
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;
该序列文件具有 Hive 兼容性。这可以在 Hive 中写成:
CREATE TABLE table1 (id int, name string, score float, type string) STORED AS sequencefile;
兽人
ORC(优化行列式)是 Hive 的列式存储格式。
表创建
以下查询是创建表的示例 -
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;
ORC 格式具有以下属性 -
orc.max.merge.distance - 读取 ORC 文件,当距离较小时进行合并。
orc.stripe.size - 这是每个条带的大小。
orc.buffer.size - 默认为 256KB。
orc.rowindex.stride - 这是 ORC 索引跨度(以行数为单位)。
Apache Tajo - SQL 语句
在上一章中,您已经了解了如何在 Tajo 中创建表。本章介绍 Tajo 中的 SQL 语句。
创建表语句
在创建表之前,请在 Tajo 安装目录路径中创建一个文本文件“students.csv”,如下所示 -
学生.csv
| ID | 姓名 | 地址 | 年龄 | 分数 |
|---|---|---|---|---|
| 1 | 亚当 | 新街23号 | 21 | 90 |
| 2 | 阿米特 | 老街12号 | 13 | 95 |
| 3 | 鲍勃 | 十字街10号 | 12 | 80 |
| 4 | 大卫 | 快捷大道15号 | 12 | 85 |
| 5 | 埃莎 | 花园街20号 | 13 | 50 |
| 6 | 恒河 | 北街25号 | 12 | 55 |
| 7 | 杰克 | 公园街2号 | 12 | 60 |
| 8 | 莉娜 | 南街24号 | 12 | 70 |
| 9 | 玛丽 | 西街5号 | 12 | 75 |
| 10 | 彼得 | 公园大道16号 | 12 | 95 |
创建文件后,移动到终端并一一启动 Tajo 服务器和 shell。
创建数据库
使用以下命令创建一个新数据库 -
询问
default> create database sampledb; OK
连接到现在创建的数据库“sampledb”。
default> \c sampledb You are now connected to database "sampledb" as user “user1”.
然后,在“sampledb”中创建一个表,如下所示 -
询问
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;
结果
上述查询将生成以下结果。
OK
到这里,外部表就创建完成了。现在,您只需输入文件位置即可。如果必须从 hdfs 分配表,请使用 hdfs 而不是文件。
接下来,“students.csv”文件包含逗号分隔值。text.delimiter字段分配有“,”。
您现在已经在“sampledb”中成功创建了“mytable”。
显示表
要显示 Tajo 中的表,请使用以下查询。
询问
sampledb> \d mytable sampledb> \d mytable
结果
上述查询将生成以下结果。
table name: sampledb.mytable table uri: file:/Users/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 261 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4
列表表
要获取表中的所有记录,请输入以下查询 -
询问
sampledb> select * from mytable;
结果
上述查询将生成以下结果。

插入表语句
Tajo 使用以下语法在表中插入记录。
句法
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;
Tajo的insert语句类似于SQL的INSERT INTO SELECT语句。
询问
让我们创建一个表来覆盖现有表的表数据。
sampledb> create table test(sno int,name text,addr text,age int,mark int); OK sampledb> \d
结果
上述查询将生成以下结果。
mytable test
插入记录
要在“test”表中插入记录,请键入以下查询。
询问
sampledb> insert overwrite into test select * from mytable;
结果
上述查询将生成以下结果。
Progress: 100%, response time: 0.518 sec
这里,“mytable”记录覆盖“test”表。如果您不想创建“test”表,则立即分配物理路径位置,如插入查询的替代选项中所述。
获取记录
使用以下查询列出“test”表中的所有记录 -
询问
sampledb> select * from test;
结果
上述查询将生成以下结果。

该语句用于添加、删除或修改现有表的列。
要重命名表,请使用以下语法 -
Alter table table1 RENAME TO table2;
询问
sampledb> alter table test rename to students;
结果
上述查询将生成以下结果。
OK
要检查更改后的表名称,请使用以下查询。
sampledb> \d mytable students
现在表“test”更改为“students”表。
添加列
要在“students”表中插入新列,请输入以下语法 -
Alter table <table_name> ADD COLUMN <column_name> <data_type>
询问
sampledb> alter table students add column grade text;
结果
上述查询将生成以下结果。
OK
设置属性
该属性用于更改表的属性。
询问
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD', 'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ; OK
这里分配压缩类型和编解码器属性。
要更改文本分隔符属性,请使用以下命令 -
询问
ALTER TABLE students SET PROPERTY ‘text.delimiter'=','; OK