遗传算法 - 快速指南
遗传算法 - 简介
遗传算法(GA)是一种基于遗传学和自然选择原理的基于搜索的优化技术。它经常被用来寻找解决难题的最佳或接近最佳的解决方案,否则这些问题将需要一生的时间才能解决。它经常用于解决研究和机器学习中的优化问题。
优化简介
优化是使事物变得更好的过程。在任何流程中,我们都有一组输入和一组输出,如下图所示。
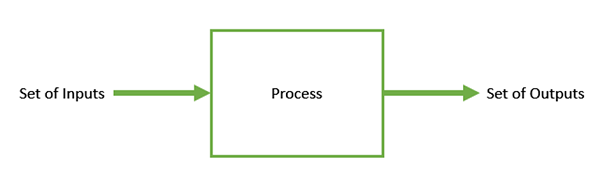
优化是指以某种方式找到输入值,从而获得“最佳”输出值。“最佳”的定义因问题而异,但用数学术语来说,它是指通过改变输入参数来最大化或最小化一个或多个目标函数。
输入可以采用的所有可能的解决方案或值的集合构成了搜索空间。在这个搜索空间中,有一个点或一组点可以给出最优解。优化的目的是在搜索空间中找到该点或点集。
什么是遗传算法?
大自然一直是全人类灵感的重要源泉。遗传算法 (GA) 是基于自然选择和遗传学概念的基于搜索的算法。遗传算法是一个更大的计算分支(称为进化计算)的子集。
遗传算法由密歇根大学的约翰·霍兰德 (John Holland) 及其学生和同事(其中最著名的是大卫·E·戈德堡 (David E. Goldberg))开发,此后在各种优化问题上进行了尝试,并取得了高度成功。
在 GA 中,我们有一个针对给定问题的可能解决方案池或群体。然后这些解决方案经历重组和突变(就像自然遗传学一样),产生新的孩子,并且这个过程在不同的世代中重复。每个个体(或候选解决方案)都被分配一个适合度值(基于其目标函数值),并且更适合的个体有更高的机会交配并产生更多“更适合”的个体。这符合达尔文“适者生存”的理论。
通过这种方式,我们一代又一代地不断“进化”出更好的个体或解决方案,直到达到停止标准。
遗传算法本质上是足够随机的,但它们的性能比随机局部搜索(我们只是尝试各种随机解决方案,跟踪迄今为止最好的解决方案)要好得多,因为它们也利用了历史信息。
GA 的优点
GA 具有多种优点,使其非常受欢迎。这些包括 -
不需要任何衍生信息(这可能不适用于许多现实世界的问题)。
与传统方法相比,速度更快、效率更高。
具有非常好的并行能力。
优化连续和离散函数以及多目标问题。
提供一系列“好的”解决方案,而不仅仅是一个解决方案。
问题总能得到答案,并且随着时间的推移会变得更好。
当搜索空间非常大并且涉及大量参数时很有用。
GA 的局限性
与任何技术一样,遗传算法也有一些限制。这些包括 -
遗传算法并不适合所有问题,尤其是简单且可以获得衍生信息的问题。
适应度值是重复计算的,这对于某些问题来说可能是计算昂贵的。
由于是随机的,无法保证解决方案的最优性或质量。
如果实施不当,遗传算法可能无法收敛到最优解。
GA——动机
遗传算法有能力“足够快”地提供“足够好”的解决方案。这使得遗传算法在解决优化问题中具有吸引力。需要 GA 的原因如下:
解决难题
在计算机科学中,存在大量的问题,这些问题都是NP-Hard的。这本质上意味着,即使是最强大的计算系统也需要很长时间(甚至几年!)来解决这个问题。在这种情况下,遗传算法被证明是一种有效的工具,可以在短时间内提供可用的近乎最优的解决方案。
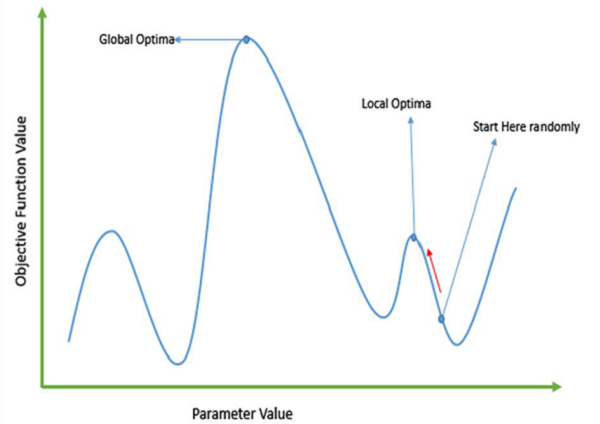
基于梯度的方法的失败
传统的基于微积分的方法的工作原理是从随机点开始,沿着梯度方向移动,直到到达山顶。该技术非常高效,并且对于单峰目标函数(例如线性回归中的成本函数)非常有效。但是,在大多数现实世界的情况下,我们有一个非常复杂的问题,称为景观,它由许多山峰和许多山谷组成,这导致这些方法失败,因为它们具有陷入局部最优的固有倾向。如下图所示。
快速获得良好的解决方案
一些难题,如旅行推销员问题 (TSP),在现实世界中有应用,如路径查找和 VLSI 设计。现在想象一下,您正在使用 GPS 导航系统,需要几分钟(甚至几个小时)来计算从源点到目的地的“最佳”路径。这种现实世界应用程序中的延迟是不可接受的,因此需要“快速”交付的“足够好”的解决方案。
遗传算法 - 基础知识
本节介绍理解 GA 所需的基本术语。此外,GA 的通用结构以伪代码和图形形式呈现。建议读者正确理解本节中介绍的所有概念,并在阅读本教程的其他部分时牢记它们。
基本术语
在开始讨论遗传算法之前,有必要熟悉本教程中将使用的一些基本术语。
人口- 它是给定问题的所有可能(编码)解决方案的子集。遗传算法的种群类似于人类的种群,只不过我们有代表人类的候选解,而不是人类。
染色体- 染色体就是给定问题的解决方案之一。
基因- 基因是染色体的一个元素位置。
等位基因- 它是基因对特定染色体的值。

基因型- 基因型是计算空间中的群体。在计算空间中,解决方案以易于使用计算系统理解和操作的方式表示。
表型- 表型是实际现实世界解决方案空间中的群体,其中解决方案以现实世界情况中表示的方式表示。
解码和编码- 对于简单的问题,表型和基因型空间是相同的。然而,在大多数情况下,表型和基因型空间是不同的。解码是将解从基因型空间转换到表型空间的过程,而编码是从表型空间转换到基因型空间的过程。解码应该很快,因为在适应度值计算过程中,它在 GA 中重复执行。
例如,考虑 0/1 背包问题。表型空间由仅包含要挑选的项目的项目编号的解决方案组成。
然而,在基因型空间中,它可以表示为长度为 n 的二进制字符串(其中 n 是项目数)。位置 x 处的 0表示第x个项目被选取,而 1 则表示相反的情况。这是基因型和表型空间不同的情况。

适应度函数- 简单定义的适应度函数是将解作为输入并产生解的适用性作为输出的函数。在某些情况下,适应度函数和目标函数可能相同,而在其他情况下,根据问题的不同,适应度函数和目标函数可能会有所不同。
遗传运算符- 这些改变后代的遗传组成。其中包括交叉、变异、选择等。
基本结构
GA 的基本结构如下 -
我们从初始群体(可能是随机生成的或通过其他启发式播种)开始,从该群体中选择父母进行交配。对父母应用交叉和变异算子以生成新的后代。最后,这些后代取代了种群中现有的个体,这个过程不断重复。通过这种方式,遗传算法实际上试图在某种程度上模仿人类的进化。
本教程后面的每个步骤将作为单独的章节进行介绍。

下面的程序解释了 GA 的通用伪代码 -
GA()
initialize population
find fitness of population
while (termination criteria is reached) do
parent selection
crossover with probability pc
mutation with probability pm
decode and fitness calculation
survivor selection
find best
return best
基因型表征
实现遗传算法时要做的最重要的决定之一是决定我们将用来表示解决方案的表示形式。据观察,不正确的表示会导致遗传算法的性能不佳。
因此,选择正确的表示形式,对表型和基因型空间之间的映射进行正确的定义对于遗传算法的成功至关重要。
在本节中,我们将介绍一些最常用的遗传算法表示形式。然而,表示是高度特定于问题的,读者可能会发现另一种表示或此处提到的表示的混合可能更适合他/她的问题。
二进制表示
这是遗传算法中最简单且使用最广泛的表示形式之一。在这种类型的表示中,基因型由位串组成。
对于某些问题,当解空间由布尔决策变量(是或否)组成时,二进制表示是自然的。以 0/1 背包问题为例。如果有 n 个项目,我们可以用 n 个元素的二进制字符串表示解决方案,其中第 x个元素表示项目 x 是否被选中 (1) 或未被选中 (0)。

对于其他问题,特别是那些处理数字的问题,我们可以用二进制表示形式来表示数字。这种编码的问题在于不同的位具有不同的意义,因此变异和交叉运算符可能会产生不良后果。使用格雷编码可以在一定程度上解决这个问题,因为一位的变化不会对解决方案产生巨大影响。
真实价值代表
对于我们想要使用连续变量而不是离散变量定义基因的问题,实值表示是最自然的。然而,这些实数值或浮点数的精度仅限于计算机。

整数表示
对于离散值基因,我们不能总是将解空间限制为二元“是”或“否”。例如,如果我们想对四个距离——北、南、东、西进行编码,我们可以将它们编码为{0,1,2,3}。在这种情况下,需要整数表示。

排列表示
在许多问题中,解决方案由元素的顺序表示。在这种情况下,排列表示是最合适的。
这种表示的一个典型例子是旅行商问题(TSP)。在这种情况下,推销员必须游览所有城市,每个城市恰好访问一次,然后返回起始城市。旅行的总距离必须最小化。这个 TSP 的解决方案自然是对所有城市进行排序或排列,因此使用排列表示对于这个问题是有意义的。

遗传算法 - 人口
人口是当前一代解决方案的子集。它也可以被定义为一组染色体。处理 GA 群体时需要牢记以下几点 -
应保持种群的多样性,否则可能导致过早收敛。
种群规模不应保持太大,因为这会导致 GA 速度减慢,而较小的种群可能不足以形成良好的交配池。因此,最佳种群规模需要通过反复试验来确定。
种群通常被定义为二维数组——种群大小、x 大小、染色体大小。
群体初始化
在 GA 中初始化种群有两种主要方法。他们是 -
随机初始化- 用完全随机的解决方案填充初始群体。
启发式初始化- 使用问题的已知启发式填充初始群体。
据观察,整个群体不应该使用启发式进行初始化,因为它可能导致群体具有相似的解决方案和很少的多样性。实验观察到,随机解决方案是推动群体达到最优的解决方案。因此,通过启发式初始化,我们只需用几个好的解决方案为群体播种,用随机解决方案填充其余部分,而不是用基于启发式的解决方案填充整个群体。
还观察到,在某些情况下,启发式初始化仅影响总体的初始适应度,但最终,解决方案的多样性导致了最优性。
人口模型
有两种广泛使用的人口模型 -
稳定状态
在稳态遗传算法中,我们在每次迭代中生成一两个后代,它们替换种群中的一两个个体。稳态 GA 也称为增量 GA。
世代相传
在世代模型中,我们生成“n”个后代,其中 n 是种群大小,并且在迭代结束时整个种群被新种群替换。
遗传算法 - 适应度函数
简单定义的适应度函数是一个函数,它将问题的候选解决方案作为输入,并产生输出作为输出,该解决方案对于所考虑的问题有多“适合”我们的“好”程度。
适应度值的计算在遗传算法中重复进行,因此它应该足够快。适应度值计算缓慢会对 GA 产生不利影响,并使其异常缓慢。
在大多数情况下,适应度函数和目标函数相同,因为目标是最大化或最小化给定的目标函数。然而,对于具有多个目标和约束的更复杂的问题,算法设计者可能会选择不同的适应度函数。
适应度函数应具有以下特征 -
适应度函数的计算速度应该足够快。
它必须定量地衡量给定解决方案的适合程度或从给定解决方案中产生个体的适合程度。
在某些情况下,由于当前问题的固有复杂性,直接计算适应度函数可能是不可能的。在这种情况下,我们会进行适应度近似来满足我们的需求。
下图显示了 0/1 背包解的适应度计算。这是一个简单的适应度函数,它只是对正在挑选的物品(其中有 1)的利润值进行求和,从左到右扫描元素直到背包满。

遗传算法 - 父代选择
亲代选择是选择交配和重组为下一代创造后代的亲代的过程。父母的选择对于遗传算法的收敛速度非常重要,因为好的父母会促使个体找到更好、更合适的解决方案。
然而,应注意防止一种极其适合的解决方案在几代之内接管整个种群,因为这会导致解决方案在解决方案空间中彼此接近,从而导致多样性的丧失。保持种群的良好多样性对于遗传算法的成功至关重要。这种由一个极其适合的解决方案占据整个种群的情况被称为过早收敛,并且是 GA 中的一种不良情况。
健身比例选择
健身比例选择是最流行的家长选择方式之一。在这种情况下,每个人都可以成为父母,其概率与其适应度成正比。因此,身体健康的个体有更高的机会交配并将其特征传播给下一代。因此,这种选择策略对种群中更适合的个体施加选择压力,随着时间的推移进化出更好的个体。
考虑一个圆形轮子。轮子分为n 个饼,其中 n 是种群中的个体数量。每个个体得到的圆的一部分与其适应度值成正比。
适应度比例选择的两种实现是可能的 -
轮盘赌选择
在轮盘选择中,圆形轮如前所述被划分。如图所示,在轮子圆周上选择一个固定点,然后旋转轮子。选择位于固定点前面的轮子区域作为父区域。对于第二个父母,重复相同的过程。

显然,安装工在车轮上占有更大的份额,因此当车轮旋转时,落在固定点前面的机会更大。因此,选择个体的概率直接取决于其适应度。
在实施方面,我们使用以下步骤 -
计算 S = a 技巧之和。
生成 0 到 S 之间的随机数。
从总体顶部开始,不断将精细度添加到部分和 P 上,直到 P<S。
P 超过 S 的个体是被选择的个体。
随机通用抽样 (SUS)
随机通用采样与轮盘赌选择非常相似,但是我们不是只有一个固定点,而是有多个固定点,如下图所示。因此,所有的父母都在轮子的一转中被选择。此外,这样的设置鼓励高度适合的个人至少被选择一次。

值得注意的是,适应度比例选择方法不适用于适应度可以取负值的情况。
赛事选择
在 K-Way 锦标赛选择中,我们从人群中随机选择 K 个个体,并从其中选择最好的个体作为父母。重复相同的过程来选择下一个父代。锦标赛选择在文学中也非常流行,因为它甚至可以与负健身值一起使用。

排名选择
排名选择也适用于负适应度值,并且主要在群体中的个体具有非常接近的适应度值时使用(这通常发生在运行结束时)。这导致每个人都拥有几乎相等的份额(就像适应度比例选择的情况一样),如下图所示,因此每个人无论彼此之间的适应程度如何,都有大致相同的概率被选为父母。这反过来又导致对更适应个体的选择压力的损失,使得遗传算法在这种情况下做出糟糕的父母选择。
在此,我们在选择父代时删除了适应度值的概念。然而,群体中的每个人都是根据他们的健康状况进行排名的。父母的选择取决于每个人的等级而不是健康状况。排名较高的个人比排名较低的个人更受青睐。
| 染色体 | 健身值 | 秩 |
|---|---|---|
| A | 8.1 | 1 |
| 乙 | 8.0 | 4 |
| C | 8.05 | 2 |
| D | 7.95 | 6 |
| 乙 | 8.02 | 3 |
| F | 7.99 | 5 |
随机选择
在这个策略中,我们从现有群体中随机选择父母。对于更适合的个体不存在选择压力,因此通常会避免这种策略。
遗传算法 - 交叉
在本章中,我们将讨论什么是交叉运算符及其其他模块、它们的用途和优点。
交叉简介
交叉算子类似于繁殖和生物交叉。在这种情况下,选择不止一个亲本,并使用亲本的遗传物质产生一个或多个后代。交叉通常应用于遗传算法中,概率较高 - p c。
交叉算子
在本节中,我们将讨论一些最常用的交叉运算符。值得注意的是,这些交叉算子非常通用,GA 设计者也可能选择实现特定于问题的交叉算子。
一点交叉
在这种单点交叉中,选择一个随机交叉点,并交换其两个父母的尾巴以获得新的后代。

多点交叉
多点交叉是单点交叉的推广,其中交替的片段被交换以获得新的后代。

统一交叉
在统一交叉中,我们不会将染色体分成片段,而是单独处理每个基因。在这种情况下,我们本质上是为每条染色体掷一枚硬币来决定它是否会包含在后代中。我们还可以将硬币偏向父母之一,以便孩子拥有更多来自该父母的遗传物质。
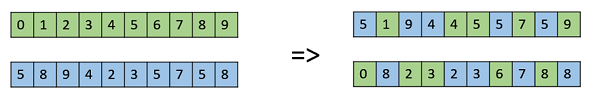
整体算术重组
这通常用于整数表示,并通过使用以下公式取两个父项的加权平均值来工作 -
- Child1 = α.x + (1-α).y
- Child2 = α.x + (1-α).y
显然,如果 α = 0.5,那么两个子级将是相同的,如下图所示。

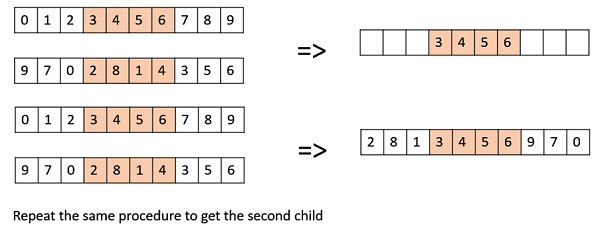
戴维斯阶交叉 (OX1)
OX1 用于基于排列的交叉,旨在将有关相对排序的信息传递给后代。它的工作原理如下 -
在父代中创建两个随机交叉点,并将它们之间的线段从第一个父代复制到第一个子代。
现在,从第二个父级中的第二个交叉点开始,将剩余未使用的数字从第二个父级复制到第一个子级,环绕列表。
对第二个孩子重复上述步骤,将父母的角色颠倒过来。
还存在许多其他交叉,例如部分映射交叉(PMX)、基于顺序的交叉(OX2)、随机交叉、环交叉等。
遗传算法 - 变异
突变简介
简单来说,突变可以定义为对染色体进行小的随机调整,以获得新的解决方案。它用于维持和引入遗传群体的多样性,通常以较低的概率应用 – p m。如果概率非常高,遗传算法就会简化为随机搜索。
变异是遗传算法中与搜索空间“探索”相关的部分。据观察,突变对于 GA 的收敛至关重要,而交叉则不然。
变异算子
在本节中,我们将描述一些最常用的变异运算符。与交叉算子一样,这并不是一个详尽的列表,遗传算法设计者可能会发现这些方法的组合或针对特定问题的变异算子更有用。
位翻转突变
在这个位翻转突变中,我们选择一个或多个随机位并翻转它们。这用于二进制编码的 GA。

随机重置
随机重置是整数表示的位翻转的扩展。在此,将允许值集中的随机值分配给随机选择的基因。
交换突变
在交换突变中,我们随机选择染色体上的两个位置,并交换值。这在基于排列的编码中很常见。

乱序突变
加扰突变在排列表示中也很流行。在这种情况下,从整个染色体中选择一个基因子集,并将它们的值随机打乱或改组。

倒位突变
在反转突变中,我们像打乱突变一样选择基因的子集,但我们不是对子集进行洗牌,而是仅仅反转子集中的整个字符串。

遗传算法 - 幸存者选择
幸存者选择策略决定了哪些个体将被淘汰,哪些个体将被保留在下一代中。这是至关重要的,因为它应该确保更适应的个体不会被踢出种群,同时应该保持种群的多样性。
一些 GA 采用精英主义。简单来说,这意味着当前种群中最适应的成员总是会传播到下一代。因此,在任何情况下都不能更换当前种群中最适者。
最简单的策略是将随机成员踢出群体,但这种方法经常存在收敛问题,因此以下策略被广泛使用。
基于年龄的选择
在基于年龄的选择中,我们没有适合度的概念。它基于这样的前提:每个个体被允许在种群中存在有限的一代,在那里它被允许繁殖,之后,无论它的适应度有多好,它都会被踢出种群。
例如,在以下示例中,年龄是个体在群体中存在的代数。群体中最年长的成员,即P4和P7被踢出群体,其余成员的年龄加一。

基于健身的选择
在这种基于适应度的选择中,孩子们倾向于取代人群中最不适应的个体。可以使用之前描述的任何选择策略的变体来选择最不适合的个体——锦标赛选择、适应度比例选择等。
例如,在下图中,孩子们替换了总体中最不适合的个体 P1 和 P10。值得注意的是,由于 P1 和 P9 具有相同的适应度值,因此从种群中删除哪个个体的决定是任意的。

遗传算法 - 终止条件
遗传算法的终止条件对于确定遗传算法运行何时结束非常重要。据观察,最初,遗传算法进展非常快,每隔几次迭代就会出现更好的解决方案,但在后期阶段,这种情况往往会饱和,改进很小。我们通常需要一个终止条件,以便我们的解决方案在运行结束时接近最优。
通常,我们保留以下终止条件之一 -
- 当 X 次迭代中总体没有改善时。
- 当我们达到绝对代数时。
- 当目标函数值达到某个预先定义的值时。
例如,在遗传算法中,我们保留一个计数器来跟踪人口没有改善的几代人。最初,我们将此计数器设置为零。每当我们没有产生比种群中的个体更好的后代时,我们就会增加计数器。
然而,如果任何后代的适应度更好,那么我们将计数器重置为零。当计数器达到预定值时,算法终止。
与 GA 的其他参数一样,终止条件也是高度特定于问题的,GA 设计者应该尝试各种选项,看看什么最适合他的特定问题。
终生适应模型
到目前为止,在本教程中,我们所讨论的任何内容都对应于达尔文的进化模型——自然选择和通过重组和突变的遗传变异。在自然界中,只有个体基因型所包含的信息才能传递给下一代。这是我们迄今为止在本教程中一直遵循的方法。
然而,其他终生适应模型——拉马克模型和鲍德温模型也确实存在。值得注意的是,无论哪个模型是最好的,都值得争论,研究人员获得的结果表明,终生适应的选择是高度特定于问题的。
通常,我们将遗传算法与本地搜索混合在一起——就像模因算法一样。在这种情况下,人们可能会选择使用拉马克模型或鲍德温模型来决定如何处理本地搜索后生成的个体。
拉马克模型
拉马克模型本质上是说,一个人在一生中获得的特征可以遗传给其后代。它以法国生物学家让-巴蒂斯特·拉马克的名字命名。
尽管如此,自然生物学已经完全无视拉马克主义,因为我们都知道只有基因型中的信息才能传播。然而,从计算的角度来看,已经表明采用拉马克模型可以为某些问题提供良好的结果。
在拉马克模型中,局部搜索算子检查邻域(获得新的性状),如果找到更好的染色体,它就会成为后代。
鲍德温模型
鲍德温模型是一种以詹姆斯·马克·鲍德温(James Mark Baldwin,1896)命名的中间思想。在鲍德温模型中,染色体可以编码学习有益Behave的倾向。这意味着,与拉马克模型不同,我们不会将获得的特征传递给下一代,也不会像达尔文模型那样完全忽略获得的特征。
鲍德温模型处于这两个极端的中间,其中个体获得某些特征的倾向被编码,而不是特征本身。
在这个鲍德温模型中,局部搜索算子检查邻域(获得新的性状),如果找到更好的染色体,它只会将改进的适应度分配给染色体,而不会修改染色体本身。适应度的变化意味着染色体“获得性状”的能力,尽管它不会直接传递给后代。
有效实施
遗传算法本质上是非常通用的,仅仅将它们应用于任何优化问题不会给出好的结果。在本节中,我们将描述一些有助于和协助 GA 设计者或 GA 实施者工作的要点。
介绍特定问题的领域知识
据观察,我们将更多针对特定问题的领域知识纳入 GA 中;我们获得的客观价值就越高。添加问题特定信息可以通过使用特定于问题的交叉或变异运算符、自定义表示等来完成。
下图显示了 Michalewicz (1990) 对 EA 的看法 -

减少拥挤
当高度适应的染色体大量繁殖时,就会发生拥挤,并且在几代之后,整个种群都充满了具有相似适应度的相似解决方案。这减少了多样性,而多样性是确保 GA 成功的一个非常关键的因素。有很多方法可以限制拥挤。其中一些是 -
突变引入多样性。
对于具有相似适应度的个体,切换到排名选择和锦标赛选择,这比适应度比例选择具有更大的选择压力。
健身共享- 在这种情况下,如果群体中已经包含相似的个体,则个体的健身度会降低。
随机化有帮助!
实验观察到,最好的解决方案是由随机染色体驱动的,因为它们赋予种群多样性。GA 实施者应小心保持群体的足够随机性和多样性,以获得最佳结果。
将 GA 与本地搜索混合
局部搜索是指检查给定解的邻域内的解,以寻找更好的目标值。
有时将遗传算法与本地搜索混合起来可能很有用。下图显示了 GA 中可以引入本地搜索的各个位置。

参数和技术的变化
在遗传算法中,不存在“一刀切”或适用于所有问题的神奇公式。即使在初始 GA 准备好之后,也需要花费大量的时间和精力来研究种群大小、变异和交叉概率等参数,以找到适合特定问题的参数。
遗传算法 - 高级主题
在本节中,我们将介绍遗传算法中的一些高级主题。只想了解 GA 简介的读者可以选择跳过本节。
约束优化问题
约束优化问题是那些我们必须最大化或最小化受某些约束的给定目标函数值的优化问题。因此,并非解空间中的所有结果都是可行的,并且解空间包含如下图所示的可行区域。

在这种情况下,交叉和变异算子可能会给我们提供不可行的解决方案。因此,在处理约束优化问题时,必须在遗传算法中采用额外的机制。
一些最常见的方法是 -
使用降低不可行解的适合度的罚函数,优选地使得适合度与违反的约束的数量或距可行区域的距离成比例地降低。
使用修复函数,采用不可行的解决方案并对其进行修改,以满足违反的约束。
根本不允许不可行的解决方案进入大众。
使用特殊的表示或解码器函数来确保解决方案的可行性。
基本理论背景
在本节中,我们将讨论模式和 NFL 定理以及构建块假设。
图式定理
研究人员一直在试图找出遗传算法工作背后的数学原理,而霍兰德的图式定理是朝这个方向迈出的一步。一年来,人们对图式定理进行了各种改进和建议,使其更加通用。
在本节中,我们不会深入研究图式定理的数学原理,而是尝试对图式定理是什么有一个基本的了解。要了解的基本术语如下 -
模式是一个“模板”。形式上,它是字母表上的一个字符串 = {0,1,*},
其中 * 不关心并且可以取任何值。
因此,*10*1 可能表示 01001、01011、11001 或 11011
从几何角度来看,模式是解决方案搜索空间中的超平面。
模式的顺序是基因中指定固定位置的数量。

定义长度是基因中两个最远的固定符号之间的距离。

模式定理指出,具有高于平均适应性、短定义长度和较低阶的模式更有可能在交叉和变异中生存。
积木假设
构建块是具有上述给定平均适应度的低阶、低定义长度模式。构建块假说认为,这些构建块是 GA 成功和 GA 适应的基础,因为它通过连续识别和重新组合这些“构建块”而不断进步。
没有免费的午餐 (NFL) 定理
Wolpert 和 Macready 于 1997 年发表了一篇题为“优化没有免费午餐定理”的论文。它本质上表明,如果我们对所有可能问题的空间进行平均,那么所有非重新访问的黑盒算法将表现出相同的性能。
这意味着我们对问题了解得越多,我们的 GA 就会变得更加针对具体问题并提供更好的性能,但它通过在其他问题上表现不佳来弥补这一点。
基于遗传算法的机器学习
遗传算法也在机器学习中得到应用。分类器系统是基于遗传学的机器学习(GBML)系统的一种形式,常用于机器学习领域。GBML 方法是一种小众的机器学习方法。
GBML 系统有两类 -
匹兹堡方法- 在这种方法中,一条染色体编码一个解决方案,因此适应度被分配给解决方案。
密歇根方法- 一个解决方案通常由许多染色体表示,因此适应度被分配给部分解决方案。
应该记住,GBML 系统中也存在交叉、变异、拉马克或达尔文等标准问题。
遗传算法 - 应用领域
遗传算法主要用于各种优化问题,但也经常用于其他应用领域。
在本节中,我们列出了一些经常使用遗传算法的领域。这些是 -
优化- 遗传算法最常用于优化问题,其中我们必须在给定的一组约束下最大化或最小化给定的目标函数值。本教程强调了解决优化问题的方法。
经济学- 遗传算法还用于描述各种经济模型,如蜘蛛网模型、博弈论均衡解决、资产定价等。
神经网络- 遗传算法也用于训练神经网络,特别是循环神经网络。
并行化- 遗传算法还具有非常好的并行能力,并被证明是解决某些问题的非常有效的手段,也提供了一个很好的研究领域。
图像处理- GA 用于各种数字图像处理 (DIP) 任务以及密集像素匹配。
车辆路径问题- 具有多个软时间窗口、多个仓库和异构车队。
调度应用程序- GA 也用于解决各种调度问题,特别是时间表问题。
机器学习- 正如已经讨论过的,基于遗传学的机器学习(GBML)是机器学习的一个利基领域。
机器人轨迹生成- 遗传算法已用于规划机器人手臂从一点移动到另一点所采取的路径。
飞机的参数化设计- 遗传算法已被用于通过改变参数和发展更好的解决方案来设计飞机。
DNA 分析- GA 已用于使用样品的光谱数据确定 DNA 的结构。
多模态优化- GA 显然是非常好的多模态优化方法,我们必须找到多个最佳解决方案。
旅行商问题及其应用- 遗传算法已被用来解决 TSP,这是一个使用新颖的交叉和打包策略的众所周知的组合问题。
遗传算法 - 进一步阅读
可以参考以下书籍来进一步增强读者对遗传算法和进化计算的了解 -
David E. Goldberg的《搜索、优化和机器学习中的遗传算法》。
遗传算法 + 数据结构 = 进化程序,作者:Zbigniew Michalewicz。
《实用遗传算法》作者:Randy L. Haupt和Sue Ellen Haupt。
Kalyanmoy Deb使用进化算法进行多目标优化。