H2O - 运行示例应用程序
单击示例列表中的“航空公司延误流程”链接,如下面的屏幕截图所示 -

确认后,将加载新笔记本。
清除所有输出
在解释笔记本中的代码语句之前,让我们清除所有输出,然后逐步运行笔记本。要清除所有输出,请选择以下菜单选项 -
Flow / Clear All Cell Contents
这如下面的屏幕截图所示 -
清除所有输出后,我们将单独运行笔记本中的每个单元并检查其输出。
运行第一个单元格
单击第一个单元格。左侧出现红色标志,表示该单元格已被选中。如下面的屏幕截图所示 -

该单元格的内容只是用MarkDown(MD)语言编写的程序注释。内容描述了加载的应用程序的功能。要运行单元格,请单击“运行”图标,如下面的屏幕截图所示 -

您将不会在单元格下方看到任何输出,因为当前单元格中没有可执行代码。光标现在自动移动到下一个单元格,准备执行。
导入数据
下一个单元格包含以下 Python 语句 -
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
该语句将 allyears2k.csv 文件从 Amazon AWS 导入到系统中。当您运行该单元时,它会导入该文件并提供以下输出。

设置数据解析器
现在,我们需要解析数据并使其适合我们的 ML 算法。这是使用以下命令完成的 -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]
执行上述语句后,将出现一个设置配置对话框。该对话框允许您进行多种解析文件的设置。如下面的屏幕截图所示 -

在此对话框中,您可以从给定的下拉列表中选择所需的解析器并设置其他参数,例如字段分隔符等。
解析数据
下一条语句实际上使用上述配置解析数据文件,该语句很长,如下所示 -
parseFiles paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"] destination_frame: "allyears2k.hex" parse_type: "CSV" separator: 44 number_columns: 31 single_quotes: false column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime", "ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum", "ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay", "Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode", "Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay", "LateAircraftDelay","IsArrDelayed","IsDepDelayed"] column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric" ,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric", "Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum", "Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"] delete_on_done: true check_header: 1 chunk_size: 4194304
请注意,您在配置框中设置的参数已在上面的代码中列出。现在,运行这个单元格。一段时间后,解析完成,您将看到以下输出 -

检查数据框
处理后,它会生成一个数据帧,可以使用以下语句进行检查 -
getFrameSummary "allyears2k.hex"
执行上述语句后,您将看到以下输出 -

现在,您的数据已准备好输入机器学习算法。
下一条语句是程序注释,表示我们将使用回归模型并指定预设的正则化和 lambda 值。
建立模型
接下来是最重要的声明,那就是构建模型本身。这是在以下声明中指定的 -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}
我们使用 glm,它是一个广义线性模型套件,族类型设置为二项式。您可以在上面的声明中看到这些突出显示的内容。在我们的例子中,预期输出是二进制的,这就是我们使用二项式类型的原因。其他参数可自行查看;例如,看看我们之前指定的 alpha 和 lambda。有关所有参数的说明,请参阅 GLM 模型文档。
现在,运行这个语句。执行后,将生成以下输出 -

当然,在您的机器上执行时间会有所不同。现在,该示例代码中最有趣的部分来了。
检查输出
我们只需使用以下语句输出我们构建的模型 -
getModel "glm_model"
请注意,glm_model 是我们在上一条语句中构建模型时指定为 model_id 参数的模型 ID。这给了我们一个巨大的输出,详细说明了几个不同参数的结果。报告的部分输出如下面的屏幕截图所示 -

正如您在输出中看到的,它表示这是在数据集上运行广义线性建模算法的结果。
在“评分历史记录”的正上方,您会看到“模型参数”标签,将其展开,您将看到构建模型时使用的所有参数的列表。这如下面的屏幕截图所示。

同样,每个标签都提供特定类型的详细输出。自己扩展各种标签来研究不同类型的输出。
建立另一个模型
接下来,我们将在数据帧上构建深度学习模型。示例代码中的下一条语句只是程序注释。下面的语句实际上是一个模型构建命令。如下所示 -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}
正如您在上面的代码中看到的,我们指定深度学习来构建模型,并将多个参数设置为深度学习模型文档中指定的适当值。当您运行此语句时,它将比 GLM 模型构建花费更长的时间。模型构建完成后,您将看到以下输出,尽管时间不同。
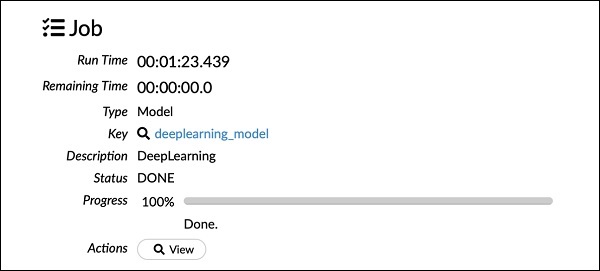
检查深度学习模型输出
这会生成某种输出,可以像前面的情况一样使用以下语句进行检查。
getModel "deeplearning_model"
我们将考虑如下所示的 ROC 曲线输出以供快速参考。

与前面的情况一样,展开各个选项卡并研究不同的输出。
保存模型
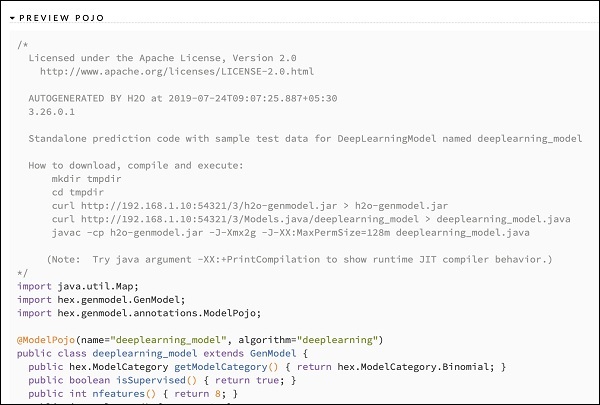
在研究了不同模型的输出后,您决定在生产环境中使用其中一种模型。H20 允许您将此模型保存为 POJO(普通旧 Java 对象)。
展开输出中的最后一个标签 PREVIEW POJO,您将看到微调模型的 Java 代码。在您的生产环境中使用它。
接下来,我们将了解 H2O 的一个非常令人兴奋的功能。我们将学习如何使用 AutoML 来测试各种算法并根据其性能对其进行排名。