- 使用 Python 进行机器学习
- 家
- 基本
- Python生态系统
- 机器学习方法
- ML 项目的数据加载
- 通过统计了解数据
- 通过可视化了解数据
- 准备数据
- 数据特征选择
- 机器学习算法 - 分类
- 介绍
- 逻辑回归
- 支持向量机(SVM)
- 决策树
- 朴素贝叶斯
- 随机森林
- 机器学习算法 - 回归
- 随机森林
- 线性回归
- 机器学习算法 - 聚类
- 概述
- K均值算法
- 均值平移算法
- 层次聚类
- ML 算法 - KNN 算法
- 寻找最近的邻居
- 性能指标
- 自动工作流程
- 提高机器学习模型的性能
- 提高 ML 模型的性能(续……)
- 使用 Python 进行机器学习 - 资源
- 使用 Python 进行机器学习 - 快速指南
- 使用 Python 进行机器学习 - 资源
- 使用 Python 进行机器学习 - 讨论
使用 Python 进行机器学习 - 基础知识
我们生活在“数据时代”,拥有更好的计算能力和更多的存储资源。这些数据或信息日益增加,但真正的挑战是理解所有数据。企业和组织正在尝试通过使用数据科学、数据挖掘和机器学习的概念和方法构建智能系统来应对这一问题。其中,机器学习是计算机科学中最令人兴奋的领域。如果我们将机器学习称为为数据提供意义的算法的应用和科学,这并没有错。
什么是机器学习?
机器学习 (ML) 是计算机科学的一个领域,借助该领域,计算机系统可以像人类一样为数据提供意义。
简而言之,机器学习是一种人工智能,它通过使用算法或方法从原始数据中提取模式。机器学习的主要重点是允许计算机系统从经验中学习,而无需明确编程或人工干预。
机器学习的需求
此时此刻,人类是地球上最聪明、最先进的物种,因为他们能够思考、评估和解决复杂的问题。另一方面,人工智能还处于初级阶段,在很多方面还没有超越人类智能。那么问题来了,机器学习需要什么?最合适的理由是“基于数据、高效、规模化决策”。
最近,组织正在大力投资人工智能、机器学习和深度学习等新技术,以从数据中获取关键信息,以执行多项现实任务并解决问题。我们可以将其称为机器做出的数据驱动决策,特别是自动化流程。在解决本质上无法编程的问题时,可以使用这些数据驱动的决策,而不是使用编程逻辑。事实是,我们离不开人类智能,但另一方面,我们都需要大规模、高效地解决现实世界的问题。这就是为什么需要机器学习。
为什么以及何时让机器学习?
我们已经讨论了机器学习的必要性,但是另一个问题出现了,在什么场景下我们必须让机器学习?在某些情况下,我们需要机器高效、大规模地做出数据驱动的决策。以下是一些让机器学习会更有效的情况 -
缺乏人类专业知识
我们希望机器学习并做出数据驱动决策的第一个场景可能是缺乏人类专业知识的领域。这些例子可以是在未知领域或太空行星中的导航。
动态场景
有些场景本质上是动态的,即它们随着时间的推移而不断变化。对于这些场景和Behave,我们希望机器能够学习并做出数据驱动的决策。其中一些示例可以是组织中的网络连接和基础设施的可用性。
难以将专业知识转化为计算任务
人类可以在多个领域拥有自己的专业知识;然而,他们无法将这种专业知识转化为计算任务。在这种情况下,我们需要机器学习。这些例子可以是语音识别、认知任务等领域。
机器学习模型
在讨论机器学习模型之前,我们必须了解 Mitchell 教授给出的 ML 的以下正式定义 -
“如果计算机程序在 T 中的任务中的性能(按 P 测量)随着经验 E 的提高而提高,则可以说,计算机程序可以从关于某类任务 T 和性能测量 P 的经验 E 中学习。”
上述定义基本上关注三个参数,也是任何学习算法的主要组成部分,即任务(T)、性能(P)和经验(E)。在这种情况下,我们可以将此定义简化为 -
机器学习是人工智能的一个领域,由学习算法组成:
提高他们的表现(P)
执行某些任务时 (T)
随着时间的推移和经验的积累 (E)
基于上述,下图代表了一个机器学习模型 -
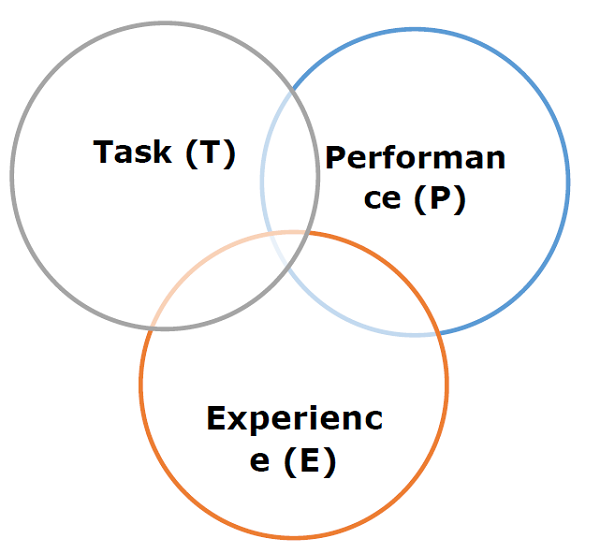
现在让我们更详细地讨论它们 -
任务(T)
从问题的角度来看,我们可以将任务T定义为要解决的现实世界问题。这个问题可以是任何东西,比如寻找特定地点的最佳房价或找到最佳的营销策略等。另一方面,如果我们谈论机器学习,任务的定义是不同的,因为很难通过以下方式解决基于机器学习的任务:传统的编程方法。
当任务 T 基于流程且系统必须遵循对数据点进行操作时,则称其为基于 ML 的任务。基于机器学习的任务的例子有分类、回归、结构化注释、聚类、转录等。
经验(E)
顾名思义,它是从提供给算法或模型的数据点中获得的知识。一旦提供了数据集,模型将迭代运行并学习一些固有的模式。由此获得的学习称为经验(E)。与人类学习进行类比,我们可以将这种情况视为人类正在从情境、关系等各种属性中学习或获得一些经验。监督学习、无监督学习和强化学习是学习或获得经验的一些方式。我们的 ML 模型或算法获得的经验将用于解决任务 T。
性能(P)
机器学习算法应该执行任务并随着时间的推移获得经验。衡量 ML 算法是否按预期执行的指标是其性能 (P)。P 基本上是一个定量指标,它告诉模型如何使用其经验 E 来执行任务 T。有许多指标有助于理解 ML 性能,例如准确度得分、F1 得分、混淆矩阵、精度、召回率、灵敏度等
机器学习的挑战
尽管机器学习正在迅速发展,在网络安全和自动驾驶汽车方面取得了重大进展,但整个人工智能领域仍有很长的路要走。背后的原因是机器学习未能克服许多挑战。机器学习目前面临的挑战是 -
数据质量- 为机器学习算法提供高质量的数据是最大的挑战之一。使用低质量数据会导致与数据预处理和特征提取相关的问题。
耗时的任务- 机器学习模型面临的另一个挑战是时间消耗,尤其是数据采集、特征提取和检索。
缺乏专家- 由于机器学习技术仍处于起步阶段,获得专家资源是一项艰巨的任务。
制定业务问题没有明确的目标- 对于业务问题没有明确的目标和明确的目标是机器学习的另一个关键挑战,因为这项技术还不够成熟。
过度拟合和欠拟合问题- 如果模型过度拟合或欠拟合,则无法很好地表示问题。
维数诅咒- 机器学习模型面临的另一个挑战是数据点的特征太多。这可能是一个真正的障碍。
部署困难- ML 模型的复杂性使得在现实生活中部署非常困难。
机器学习的应用
机器学习是发展最快的技术,研究人员表示,我们正处于人工智能和机器学习的黄金年。它用于解决许多传统方法无法解决的现实世界复杂问题。以下是机器学习的一些实际应用 -
情绪分析
情感分析
错误检测和预防
天气预报和预测
股市分析与预测
语音合成
语音识别
客户细分
物体识别
欺诈识别
预防诈骗
在线购物时向顾客推荐产品。