- Python XlsxWriter 教程
- Python XlsxWriter - 主页
- Python XlsxWriter - 概述
- Python XlsxWriter - 环境设置
- Python XlsxWriter - 你好世界
- Python XlsxWriter - 重要类
- Python XlsxWriter - 单元格符号和范围
- Python XlsxWriter - 定义的名称
- Python XlsxWriter - 公式和函数
- Python XlsxWriter - 日期和时间
- Python XlsxWriter - 表格
- Python XlsxWriter - 应用过滤器
- Python XlsxWriter - 字体和颜色
- Python XlsxWriter - 数字格式
- Python XlsxWriter - 边框
- Python XlsxWriter - 超链接
- Python XlsxWriter - 条件格式
- Python XlsxWriter - 添加图表
- Python XlsxWriter - 图表格式
- Python XlsxWriter - 图表图例
- Python XlsxWriter - 条形图
- Python XlsxWriter - 折线图
- Python XlsxWriter - 饼图
- Python XlsxWriter - 迷你图
- Python XlsxWriter - 数据验证
- Python XlsxWriter - 大纲和分组
- Python XlsxWriter - 冻结和拆分窗格
- Python XlsxWriter - 隐藏/保护工作表
- Python XlsxWriter - 文本框
- Python XlsxWriter - 插入图像
- Python XlsxWriter - 页面设置
- Python XlsxWriter - 页眉和页脚
- Python XlsxWriter - 单元格注释
- Python XlsxWriter - 使用 Pandas
- Python XlsxWriter - VBA 宏
- Python XlsxWriter 有用资源
- Python XlsxWriter - 快速指南
- Python XlsxWriter - 有用的资源
- Python XlsxWriter - 讨论
Python XlsxWriter - 快速指南
Python XlsxWriter - 概述
XlsxWriter是一个 Python 模块,用于创建使用开放 XML 标准的 Excel 2007 (XLSX) 格式的电子表格文件。XlsxWriter 模块由 John McNamara 开发。其最早版本(0.0.1)于2013年发布。最新版本3.0.2于2021年11月发布。最新版本需要Python 3.4或以上版本。
XlsxWriter 功能
XlsxWriter 的一些重要功能包括 -
XlsxWriter 创建的文件与 Excel XLSX 文件 100% 兼容。
XlsxWriter 提供完整的格式化功能,例如合并单元格、定义名称、条件格式化等。
XlsxWriter 允许以编程方式在 XLSX 文件中插入图表。
可以使用 XlsxWriter 设置自动过滤器。
XlsxWriter 支持数据验证和下拉列表。
使用 XlsxWriter,可以插入 PNG/JPEG/GIF/BMP/WMF/EMF 图像。
通过 XlsxWriter,Excel 电子表格可以与 Pandas 库集成。
XlsxWriter 还提供对添加宏的支持。
XlsxWriter 具有用于写入大文件的内存优化模式。
Python XlsxWriter - 环境设置
使用 PIP 安装 XlsxWriter
安装 XlsxWriter 最简单且推荐的方法是使用PIP安装程序。使用以下命令安装XlsxWriter(最好在虚拟环境中)。
pip3 install xlsxwriter
从 Tarball 安装
另一种选择是从其源代码安装 XlsxWriter,托管在https://github.com/jmcnamara/XlsxWriter/。下载最新的源 tarball 并使用以下命令安装库 -
$ curl -O -L http://github.com/jmcnamara/XlsxWriter/archive/main.tar.gz $ tar zxvf main.tar.gz $ cd XlsxWriter-main/ $ python setup.py install
从 GitHub 克隆
您还可以克隆 GitHub 存储库并从中安装。
$ git clone https://github.com/jmcnamara/XlsxWriter.git $ cd XlsxWriter $ python setup.py install
要确认 XlsxWriter 是否已正确安装,请从 Python 提示符中检查其版本 -
>>> import xlsxwriter >>> xlsxwriter.__version__ '3.0.2'
Python XlsxWriter - 你好世界
入门
测试模块/库是否正常工作的第一个程序通常是编写 Hello world 消息。以下程序创建一个扩展名为 .XLSX 的文件。xlsxwriter模块中Workbook类的一个对象对应当前工作目录下的电子表格文件。
wb = xlsxwriter.Workbook('hello.xlsx')
接下来,调用Workbook 对象的add_worksheet()方法在其中插入新工作表。
ws = wb.add_worksheet()
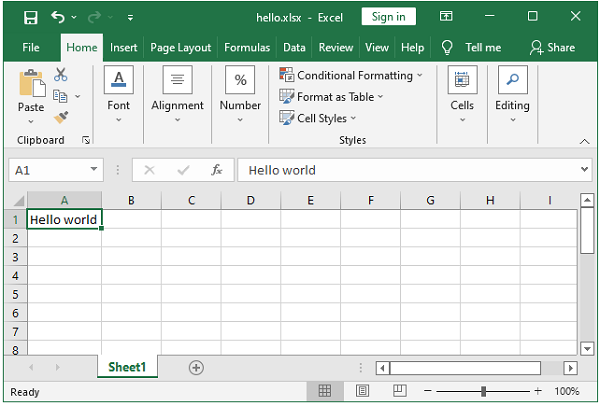
现在,我们可以通过调用工作表对象的write()方法在 A1 单元格中添加 Hello World 字符串。它需要两个参数:单元格地址和字符串。
ws.write('A1', 'Hello world')
例子
hello.py的完整代码如下:
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
ws.write('A1', 'Hello world')
wb.close()
输出
执行上述代码后,会在当前工作目录下创建hello.xlsx文件。您现在可以使用 Excel 软件打开它。
Python XlsxWriter - 重要类
XlsxWriter 库由以下类组成。这些类中定义的所有方法都允许以编程方式对 XLSX 文件执行不同的操作。课程是 -
- 作业本类
- 工作表类
- 格式类
- 图表类
- 图表类
- 异常类
练习册班
这是 XlsxWriter 模块公开的主类,也是您需要直接实例化的唯一类。它代表写入磁盘上的 Excel 文件。
wb=xlsxwriter.Workbook('filename.xlsx')
Workbook 类定义了以下方法 -
| 先生编号 | 工作簿类别和说明 |
|---|---|
| 1 | 添加工作表() 将新工作表添加到工作簿。 |
| 2 | 添加格式() 用于创建新的 Format 对象,该对象用于将格式应用于单元格。 |
| 3 | 添加图表() 创建一个新的图表对象,可以通过 insert_chart() Worksheet 方法插入到工作表中 |
| 4 | add_chartsheet() 将新图表表添加到工作簿。 |
| 5 | 关闭() 关闭 Workbook 对象并写入 XLSX 文件。 |
| 6 | 定义名称() 在工作簿中创建定义的名称以用作变量。 |
| 7 | 添加_vba_项目() 用于使用二进制 VBA 项目文件将宏或函数添加到工作簿。 |
| 8 | 工作表() 返回工作簿中的工作表列表。 |
工作表类
工作表类代表 Excel 工作表。此类的对象处理诸如将数据写入单元格或格式化工作表布局等操作。它是通过从Workbook()对象调用add_worksheet()方法创建的。
Worksheet 对象可以访问以下方法 -
写() |
将通用数据写入工作表单元格。 参数-
返回-
|
write_string() |
将字符串写入由行和列指定的单元格。 参数-
返回-
|
写数字() |
将数字类型写入由行和列指定的单元格。 参数-
返回-
|
写公式() |
将公式或函数写入由行和列指定的单元格。 参数-
返回-
|
插入图像() |
用于将图像插入到工作表中。图像可以是 PNG、JPEG、GIF、BMP、WMF 或 EMF 格式。 参数-
返回-
|
插入图表() |
用于将图表插入工作表中。图表对象是通过 Workbook add_chart() 方法创建的。 参数-
|
条件格式() |
用于根据用户定义的条件向单元格或单元格区域添加格式设置。 参数-
返回-
|
添加表() |
用于将一系列单元格分组到 Excel 表格中。 参数-
|
自动过滤器() |
在工作表中设置自动筛选区域。它将下拉列表添加到二维工作表数据范围的标题中。用户可以根据简单的标准过滤数据。 参数-
|
格式类
格式对象是通过调用工作簿add_format()方法创建的。该对象可用的方法和属性与字体、颜色、图案、边框、对齐方式和数字格式有关。
字体格式化方法和属性 -
| 方法名称 | 描述 | 财产 |
|---|---|---|
| 设置字体名称() | 字体类型 | '字体名称' |
| 设置字体大小() | 字体大小 | '字体大小' |
| 设置字体颜色() | 字体颜色 | '字体颜色' |
| 设置粗体() | 大胆的 | '大胆的' |
| 设置斜体() | 斜体 | ‘斜体’ |
| 设置下划线() | 强调 | '强调' |
| 设置字体删除线() | 三振 | '字体删除线' |
| 设置字体脚本() | 上标/下标 | '字体脚本' |
对齐格式设置方法和属性
| 方法名称 | 描述 | 财产 |
|---|---|---|
| 设置对齐() | 水平对齐 | '对齐' |
| 设置对齐() | 垂直对齐 | 'valign' |
| 设置旋转() | 回转 | '回转' |
| set_text_wrap() | 文本换行 | '文本换行' |
| 设置阅读顺序() | 阅读顺序 | '阅读顺序' |
| set_text_justlast() | 最后证明合理 | 'text_justlast' |
| set_center_across() | 中心横跨 | '中心_交叉' |
| 设置缩进() | 缩进 | ‘缩进’ |
| set_shrink() | 缩小以适合 | '收缩' |
图表类
图表对象是通过指定图表类型的 Workbook 对象的add_chart()方法创建的。
chart = workbook.add_chart({'type': 'column'})
通过调用insert_chart()方法将图表对象插入到工作表中。
worksheet.insert_chart('A7', chart)
XlxsWriter 支持以下图表类型 -
区域- 创建区域(实心线)样式图表。
bar - 创建条形样式(转置直方图)图表。
柱- 创建柱形(直方图)图表。
line - 创建线条样式图表。
pie - 创建饼图样式图表。
甜甜圈- 创建甜甜圈样式图表。
scatter - 创建散点样式图表。
stock - 创建股票样式图表。
雷达- 创建雷达样式图表。
Chart 类定义了以下方法 -
添加系列(选项) |
将数据系列添加到图表中。可以给出以下属性 -
|
设置x轴(选项) |
设置图表 X 轴选项,包括
|
设置 y 轴(选项) |
设置图表 Y 轴选项,包括 -
|
设置大小() |
该方法用于设置图表的尺寸。可以通过设置宽度和高度或设置x_scale和y_scale来修改图表的大小。 |
设置标题(选项) |
设置图表标题选项。 参数-
|
设置图例() |
此方法使用以下属性格式化图表图例 -
|
图表类
XLSX 文件中的图表表是仅包含图表而不包含其他数据的工作表。通过从 Workbook 对象调用add_chartsheet()方法来创建新的图表对象 -
chartsheet = workbook.add_chartsheet()
Chartsheet类的一些功能与数据工作表的功能类似,例如选项卡选择、页眉、页脚、边距和打印属性。但是,其主要目的是显示单个图表,而普通数据工作表可以包含一个或多个嵌入图表。
图表数据必须出现在单独的工作表中。因此,它总是使用set_chart()方法与至少一个数据工作表一起创建。
chartsheet = workbook.add_chartsheet()
chart = workbook.add_chart({'type': 'column'})
chartsheet.set_chart(chart)
请记住,图表表只能包含一个图表。
例子
以下代码将数据系列写入名为sheet1的工作表中,但打开一个新的图表工作表以根据sheet1中的数据添加柱形图。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
worksheet = wb.add_worksheet()
cs = wb.add_chartsheet()
chart = wb.add_chart({'type': 'column'})
data = [
[10, 20, 30, 40, 50],
[20, 40, 60, 80, 100],
[30, 60, 90, 120, 150],
]
worksheet.write_column('A1', data[0])
worksheet.write_column('B1', data[1])
worksheet.write_column('C1', data[2])
chart.add_series({'values': '=Sheet1!$A$1:$A$5'})
chart.add_series({'values': '=Sheet1!$B$1:$B$5'})
chart.add_series({'values': '=Sheet1!$C$1:$C$5'})
cs.set_chart(chart)
cs.activate()
wb.close()
输出

异常类
XlsxWriter 识别各种运行时错误或异常,可以使用 Python 的错误处理技术捕获这些错误或异常,从而避免 Excel 文件损坏。XlsxWriter 中的 Exception 类如下 -
| 先生编号 | 异常类和描述 |
|---|---|
| 1 |
XlsxWriter异常 XlsxWriter 的基本异常。 |
| 2 | Xlsx文件错误 所有文件相关错误的基本异常。 |
| 3 | Xlsx输入错误 所有输入数据相关错误的基本异常。 |
| 4 | 文件创建错误 如果将 xlsx 文件写入磁盘或文件已在 Excel 中打开时出现文件权限错误或 IO 错误,则会发生此情况。 |
| 5 | 未定义图像大小 如果图像不包含高度或宽度信息,则使用insert_image()方法引发。在 Workbook close()期间引发异常。 |
| 6 | 不支持的图像格式 如果图像不是受支持的文件格式之一,则引发该错误:PNG、JPEG、GIF、BMP、WMF 或 EMF。 |
| 7 | 空图表系列 当将图表添加到没有数据系列的工作表时,会出现此异常。 |
| 8 | 无效的工作表名称 如果工作表名称太长或包含无效字符。 |
| 9 | 重复工作表名称 当工作表名称已存在时,会引发此异常。 |
文件创建错误异常
假设已使用 Excel 应用程序打开名为hello.xlsx的工作簿,则以下代码将引发FileCreateError -
import xlsxwriter
workbook = xlsxwriter.Workbook('hello.xlsx')
worksheet = workbook.add_worksheet()
workbook.close()
当该程序运行时,错误消息显示如下 -
PermissionError: [Errno 13] Permission denied: 'hello.xlsx' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "hello.py", line 4, in <module> workbook.close() File "e:\xlsxenv\lib\site-packages\xlsxwriter\workbook.py", line 326, in close raise FileCreateError(e) xlsxwriter.exceptions.FileCreateError: [Errno 13] Permission denied: 'hello.xlsx'
处理异常
我们可以使用Python的异常处理机制来达到这个目的。
import xlsxwriter
try:
workbook = xlsxwriter.Workbook('hello.xlsx')
worksheet = workbook.add_worksheet()
workbook.close()
except:
print ("The file is already open")
现在将显示自定义错误消息。
(xlsxenv) E:\xlsxenv>python ex34.py The file is already open
异常空图表系列
另一种情况是在图表中添加数据系列时引发异常。
import xlsxwriter
workbook = xlsxwriter.Workbook('hello.xlsx')
worksheet = workbook.add_worksheet()
chart = workbook.add_chart({'type': 'column'})
worksheet.insert_chart('A7', chart)
workbook.close()
这会导致 EmptyChartSeries 异常 -
xlsxwriter.exceptions.EmptyChartSeries: Chart1 must contain at least one data series.
Python XlsxWriter - 单元格符号和范围
工作簿中的每个工作表都是由大量单元格组成的网格,每个单元格可以存储一项数据 - 值或公式。网格中的每个单元格由其行号和列号标识。
在 Excel 的标准单元格寻址中,列由字母 A、B、C、…、Z、AA、AB 等标识,行从 1 开始编号。
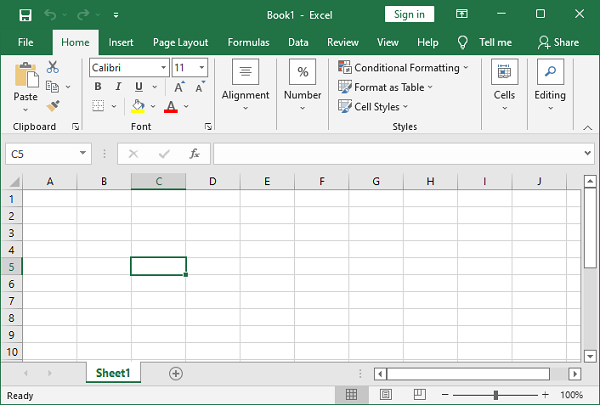
每个单元格的地址都是字母数字的,其中字母部分对应于列,数字对应于行。例如,地址“C5”指向列“C”和行号“5”中的单元格。
单元格符号
标准 Excel 使用列字母和从 1 开始的行的字母数字序列。XlsxWriter 支持标准 Excel 表示法(A1表示法)以及行列表示法,行和列均使用基于零的索引。
例子
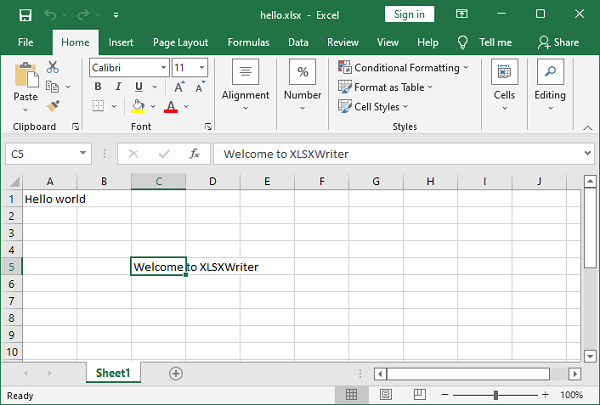
在以下示例中,使用 Excel 的标准单元格地址将字符串“Hello world”写入 A1 单元格,而使用行列表示法将“Welcome to XLSXWriter”写入单元格 C5。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
ws.write('A1', 'Hello world') # A1 notation
ws.write(4,2,"Welcome to XLSXWriter") # Row-column notation
wb.close()
输出
使用 Excel 软件打开hello.xlsx文件。
当以编程方式引用单元格时,编号的行列表示法特别有用。在以下代码中,列表列表中的数据必须写入工作表中的一系列单元格。这是通过两个嵌套循环实现的,外部循环代表行号,内部循环代表列号。
data = [
['Name', 'Physics', 'Chemistry', 'Maths', 'Total'],
['Ravi', 60, 70, 80],
['Kiran', 65, 75, 85],
['Karishma', 55, 65, 75],
]
for row in range(len(data)):
for col in range(len(data[row])):
ws.write(row, col, data[row][col])
使用下面代码中使用的工作表对象的write_row()方法可以实现相同的结果 -
for row in range(len(data)): ws.write_row(6+row,0, data[row])
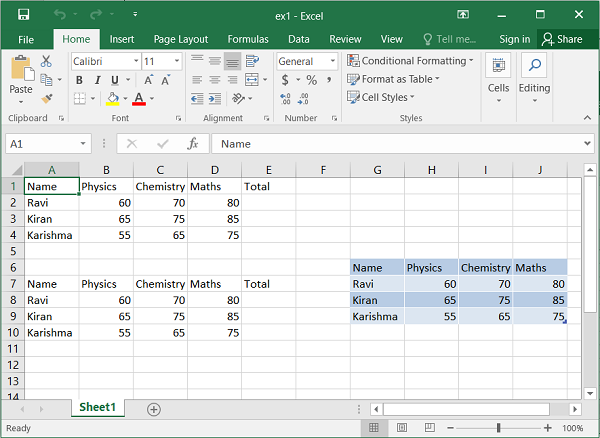
工作表对象具有add_table()方法,该方法将数据写入范围并转换为 Excel 范围,在顶行显示自动筛选下拉箭头。
ws.add_table('G6:J9', {'data': data, 'header_row':True})
例子
上述所有三个代码的输出可以通过以下代码验证并显示在下图中 -
import xlsxwriter
wb = xlsxwriter.Workbook('ex1.xlsx')
ws = wb.add_worksheet()
data = [
['Name', 'Physics', 'Chemistry', 'Maths', 'Total'],
['Ravi', 60, 70, 80],
['Kiran', 65, 75, 85],
['Karishma', 55, 65, 75],
]
for row in range(len(data)):
for col in range(len(data[row])):
ws.write(row, col, data[row][col])
for row in range(len(data)):
ws.write_row(6+row,0, data[row])
ws.add_table('G6:J9', {'data': data, 'header_row':False})
wb.close()
输出
执行上述程序并使用Excel软件打开ex1.xlsx。
Python XlsxWriter - 定义的名称
在Excel中,可以通过用户定义的名称来标识单元格、公式或单元格区域,这些名称可以用作变量,使公式的定义易于理解。这可以使用Workbook 类的Define_name()方法来实现。
在下面的代码片段中,我们有一系列由数字组成的单元格。该范围已被命名为标记。
data=['marks',50,60,70, 'Total']
ws.write_row('A1', data)
wb.define_name('marks', '=Sheet1!$A$1:$E$1')
如果名称分配给单元格范围,则Define_name()方法的第二个参数是一个字符串,其中包含工作表名称,后跟“ ! ”符号,然后是使用绝对寻址方案的单元格范围。在本例中,sheet1 中的范围A1:E1被命名为标记。
该名称可以在任何公式中使用。例如,我们计算由名称marks标识的范围内的数字总和。
ws.write('F1', '=sum(marks)')
我们还可以在write_formula()方法中使用命名单元格。在以下代码中,此方法用于计算利率为Defined_name 的金额的利息。
ws.write('B5', 10)
wb.define_name('rate', '=sheet1!$B$5')
ws.write_row('A5', ['Rate', 10])
data=['Amount',1000, 2000, 3000]
ws.write_column('A6', data)
ws.write('B6', 'Interest')
for row in range(6,9):
ws.write_formula(row, 1, '= rate*$A{}/100'.format(row+1))
我们还可以使用write_array_formula()方法代替上面代码中的循环 -
ws.write_array_formula('D7:D9' , '{=rate/100*(A7:A9)}')
例子
使用define_name()方法的完整代码如下:
import xlsxwriter
wb = xlsxwriter.Workbook('ex2.xlsx')
ws = wb.add_worksheet()
data = ['marks',50,60,70, 'Total']
ws.write_row('A1', data)
wb.define_name('marks', '=Sheet1!$A$1:$E$1')
ws.write('F1', '=sum(marks)')
ws.write('B5', 10)
wb.define_name('rate', '=sheet1!$B$5')
ws.write_row('A5', ['Rate', 10])
data=['Amount',1000, 2000, 3000]
ws.write_column('A6', data)
ws.write('B6', 'Interest')
for row in range(6,9):
ws.write_formula(row, 1, '= rate*$A{}/100'.format(row+1))
wb.close()
输出
运行上述程序并使用 Excel打开ex2.xlsx 。

Python XlsxWriter - 公式和函数
Worksheet 类提供了三种使用公式的方法。
- 写公式()
- write_array_formula()
- write_dynamic_array_formula()
所有这些方法都用于将公式和函数分配给单元格。
write_formula() 方法
write_formula ()方法需要单元格的地址以及包含有效 Excel 公式的字符串。在公式字符串内,仅接受 A1 样式地址表示法。但是,单元格地址参数可以是标准 Excel 类型,也可以是从零开始的行数和列数表示法。
例子
在下面的示例中,各种语句使用write_formula()方法。第一个使用标准 Excel 符号来指定公式。第二条语句使用行号和列号来指定设置公式的目标单元格的地址。在第三个示例中,IF()函数被分配给 G2 单元。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data=[
['Name', 'Phy', 'Che', 'Maths', 'Total', 'percent', 'Result' ],
['Arvind', 50,60,70]
]
ws.write_row('A1', data[0])
ws.write_row('A2', data[1])
ws.write_formula('E2', '=B2+C2+D2')
ws.write_formula(1,5, '=E2*100/300')
ws.write_formula('G2', '=IF(F2>=50, "PASS","FAIL")')
wb.close()
输出
Excel 文件显示以下结果 -

write_array_formula() 方法
write_array_formula ()方法用于在一定范围内扩展公式。在 Excel 中,数组公式对一组值执行计算。它可能返回单个值或一系列值。
数组公式由公式周围的一对大括号表示 - {=SUM(A1:B1*A2:B2)}。该范围可以由范围中第一个和最后一个单元格的行号和列号(例如 0,0, 2,2)指定,也可以由字符串表示形式“A1:C2”指定。
例子
在以下示例中,E、F 和 G 列使用数组公式来计算 B2:D4 范围内标记的总计、百分比和结果。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data=[
['Name', 'Phy', 'Che', 'Maths', 'Total', 'percent', 'Result'],
['Arvind', 50,60,70],
['Amar', 55,65,75],
['Asha', 75,85,80]
]
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.write_array_formula('E2:E4', '{=B2:B4+C2:C4+D2:D4}')
ws.write_array_formula(1,5,3,5, '{=(E2:E4)*100/300}')
ws.write_array_formula('G2:G4', '{=IF((F2:F4)>=50, "PASS","FAIL")}')
wb.close()
输出
以下是使用 MS Excel 打开工作表时的显示方式 -

write_dynamic_array_data() 方法
write_dynamic_array_data ()方法将动态数组公式写入单元格区域。EXCEL 365版本中引入了动态数组的概念,并且引入了一些利用动态数组优势的新函数。这些功能是 -
| 先生编号 | 功能及说明 |
|---|---|
| 1 | 筛选 过滤数据并返回匹配记录 |
| 2 | 随机数组 生成随机数数组 |
| 3 | 顺序 生成连续数字的数组 |
| 4 | 种类 按列对范围进行排序 |
| 5 | 排序方式 按另一个范围或数组对范围进行排序 |
| 6 | 独特的 从列表或范围中提取唯一值 |
| 7 | X查找 替代 VLOOKUP |
| 8 | X比赛 替换 MATCH 函数 |
动态数组是返回值的范围,其大小可以根据结果而改变。例如,FILTER()等函数返回一个值数组,该数组的大小可能会根据过滤结果而变化。
例子
在下面的示例中,数据范围为 A1:D17。过滤功能使用该范围,标准范围是C1:C17,其中给出了产品名称。FILTER ()函数会生成动态数组,因为满足条件的行数可能会发生变化。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814])
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.write_dynamic_array_formula('F1', '=FILTER(A1:D17,C1:C17="Apple")')
wb.close()
输出
请注意,write_dynamic_array_formula() 的公式字符串不需要包含大括号。生成的 hello.xlsx 必须使用 Excel 365 应用程序打开。

Python XlsxWriter - 日期和时间
在 Excel 中,日期存储为实数,以便可以在计算中使用。默认情况下,1900 年 1 月 1 日(称为纪元)被视为 1,因此 2022 年 1 月 28 日对应于 44589。同样,时间表示为数字的小数部分,即天的百分比。因此,2022 年 1 月 28 日 11 点对应于 44589.45833。
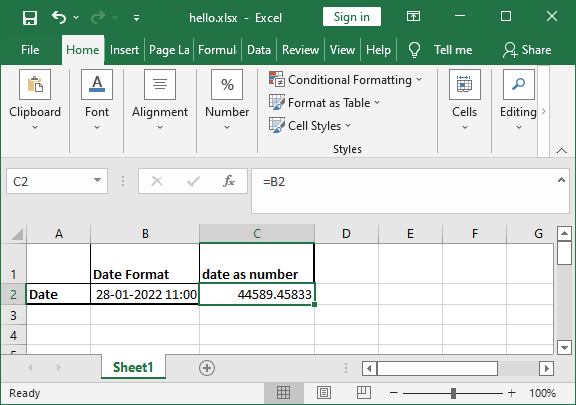
set_num_format() 方法
由于 Excel 中的日期或时间与任何其他数字一样,因此要将数字显示为日期,您必须对其应用 Excel 数字格式。使用Format 对象的set_num_format()方法并使用适当的格式。
以下代码片段显示“dd/mm/yy”格式的数字。
num = 44589
format1 = wb.add_format()
format1.set_num_format('dd/mm/yy')
ws.write('B2', num, format1)
num_format 参数
或者,可以将add_format()方法的num_format参数设置为所需的格式。
format1 = wb.add_format({'num_format':'dd/mm/yy'})
ws.write('B2', num, format1)
例子
以下代码显示了各种日期格式的数字。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
num=44589
ws.write('A1', num)
format2 = wb.add_format({'num_format': 'dd/mm/yy'})
ws.write('A2', num, format2)
format3 = wb.add_format({'num_format': 'mm/dd/yy'})
ws.write('A3', num, format3)
format4 = wb.add_format({'num_format': 'd-m-yyyy'})
ws.write('A4', num, format4)
format5 = wb.add_format({'num_format': 'dd/mm/yy hh:mm'})
ws.write('A5', num, format5)
format6 = wb.add_format({'num_format': 'd mmm yyyy'})
ws.write('A6', num, format6)
format7 = wb.add_format({'num_format': 'mmm d yyyy hh:mm AM/PM'})
ws.write('A7', num, format7)
wb.close()
输出
Excel 软件中的工作表如下所示 -

write_datetime() 和 strptime()
XlsxWriter 的 Worksheet 对象还具有write_datetime()方法,该方法在处理使用 Python 标准库的 datetime 模块获取的日期和时间对象时非常有用。
strptime ()方法从根据给定格式解析的字符串中返回日期时间对象。下面给出了一些用于格式化字符串的代码 -
%A |
工作日缩写名称 |
周日、周一 |
%A |
工作日的完整名称 |
星期天星期一 |
%d |
以零填充小数表示的月份中的某一天 |
01, 02 |
%-d |
十进制数形式的月份中的某一天 |
1, 2.. |
%b |
月份名称缩写 |
一月、二月 |
%m |
以零填充的十进制数表示的月份 |
01, 02 |
%-m |
十进制数形式的月份 |
1, 2 |
%B |
完整的月份名称 |
一月二月 |
%y |
不带世纪的年份作为补零十进制数 |
99, 00 |
%-y |
不带世纪的年份为十进制数 |
0, 99 |
%Y |
年份(世纪)为十进制数 |
2022年、1999年 |
%H |
小时(24 小时制),以零填充的十进制数 |
01, 23 |
%-H |
十进制数形式的小时(24 小时制) |
1, 23 |
%我 |
小时(12 小时制),以零填充的十进制数 |
01, 12 |
%-我 |
十进制数形式的小时(12 小时制) |
1, 12 |
%p |
区域设置的 AM 或 PM |
上午下午 |
%M |
以零填充的十进制数形式的分钟 |
01, 59 |
%-M |
以十进制表示的分钟 |
1, 59 |
%S |
第二个以零填充的十进制数 |
01, 59 |
%-S |
第二位十进制数 |
1, 59 |
%C |
区域设置的适当日期和时间表示 |
2022 年 9 月 30 日星期一 07:06:05 |
strptime ()方法的使用如下 -
>>> from datetime import datetime >>> dt="Thu February 3 2022 11:35:5" >>> code="%a %B %d %Y %H:%M:%S" >>> datetime.strptime(dt, code) datetime.datetime(2022, 2, 3, 11, 35, 5)
现在可以使用write_datetime()方法将此日期时间对象写入工作表中。
例子
在以下示例中,日期时间对象以不同的格式编写。
import xlsxwriter
from datetime import datetime
wb = xlsxwriter.Workbook('hello.xlsx')
worksheet = wb.add_worksheet()
dt="Thu February 3 2022 11:35:5"
code="%a %B %d %Y %H:%M:%S"
obj=datetime.strptime(dt, code)
date_formats = (
'dd/mm/yy',
'mm/dd/yy',
'dd m yy',
'd mm yy',
'd mmm yy',
'd mmmm yy',
'd mmmm yyy',
'd mmmm yyyy',
'dd/mm/yy hh:mm',
'dd/mm/yy hh:mm:ss',
'dd/mm/yy hh:mm:ss.000',
'hh:mm',
'hh:mm:ss',
'hh:mm:ss.000',
)
worksheet.write('A1', 'Formatted date')
worksheet.write('B1', 'Format')
row = 1
for fmt in date_formats:
date_format = wb.add_format({'num_format': fmt, 'align': 'left'})
worksheet.write_datetime(row, 0, obj, date_format)
worksheet.write_string(row, 1, fmt)
row += 1
wb.close()
输出
使用 Excel 打开时,工作表如下所示。

Python XlsxWriter - 表格
在 MS Excel 中,表格是已分组为单个实体的一系列单元格。它可以从公式中引用,并具有通用的格式属性。可以在工作表中定义一些功能,例如列标题、自动筛选器、总行数、列公式。
add_table() 方法
工作表方法add_table()用于将单元格区域添加为表格。
worksheet.add_table(first_row, first_col, last_row, last_col, options)
这两种方法、标准“ A1 ”或“行/列”表示法都可以指定范围。add_table ()方法可以采用以下一个或多个可选参数。请注意,除了 range 参数外,其他参数都是可选的。如果未给出,则创建一个空表。
例子
数据
该参数可用于指定表格单元格中的数据。看下面的例子 -
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = [
['Namrata', 75, 65, 80],
['Ravi', 60, 70, 80],
['Kiran', 65, 75, 85],
['Karishma', 55, 65, 75],
]
ws.add_table("A1:D4", {'data':data})
wb.close()
输出
这是结果 -

标题行
该参数可用于打开或关闭表中的标题行。默认情况下它是打开的。标题行将包含默认标题,例如第 1 列、第 2 列等。您可以使用 columns 参数设置所需的标题。
列
例子
该属性用于设置列标题。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = [
['Namrata', 75, 65, 80],
['Ravi', 60, 70, 80],
['Kiran', 65, 75, 85],
['Karishma', 55, 65, 75],
]
ws.add_table("A1:D4",
{'data':data,
'columns': [
{'header': 'Name'},
{'header': 'physics'},
{'header': 'Chemistry'},
{'header': 'Maths'}]
})
wb.close()
输出
标题行现在设置如下所示 -

自动过滤器
默认情况下,此参数为 ON。设置为“关闭”时,标题行不显示用于设置过滤条件的下拉箭头。
姓名
在Excel工作表中,表格被命名为Table1、Table2等。name参数可以根据需要设置表格的名称。
ws.add_table("A1:E4", {'data':data, 'name':'marklist'})
公式
可以通过在列选项中指定公式子属性来创建带有公式的列。
例子
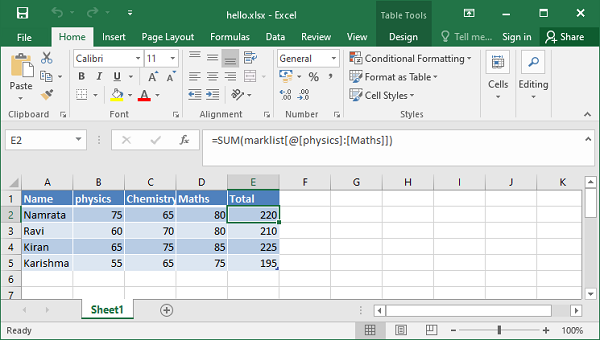
在以下示例中,表的名称属性设置为“marklist”。“总计”列 E 的公式执行分数求和,并分配公式子属性的值。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = [
['Namrata', 75, 65, 80],
['Ravi', 60, 70, 80],
['Kiran', 65, 75, 85],
['Karishma', 55, 65, 75],
]
formula = '=SUM(marklist[@[physics]:[Maths]])'
tbl = ws.add_table("A1:E5",
{'data': data,
'autofilter': False,
'name': 'marklist',
'columns': [
{'header': 'Name'},
{'header': 'physics'},
{'header': 'Chemistry'},
{'header': 'Maths'},
{'header': 'Total', 'formula': formula}
]
})
wb.close()
输出
执行上述代码时,工作表将显示“总计”列以及分数总和。
Python XlsxWriter - 应用过滤器
在 Excel 中,您可以使用逻辑表达式根据条件对表格数据设置过滤器。在 XlsxWriter 的工作表类中,我们有autofilter()方法或目的。此方法的强制参数是单元格范围。这将在标题行中创建下拉选择器。要应用一些标准,我们有两种可用的方法 - filter_column()或filter_column_list()。
对列应用过滤条件
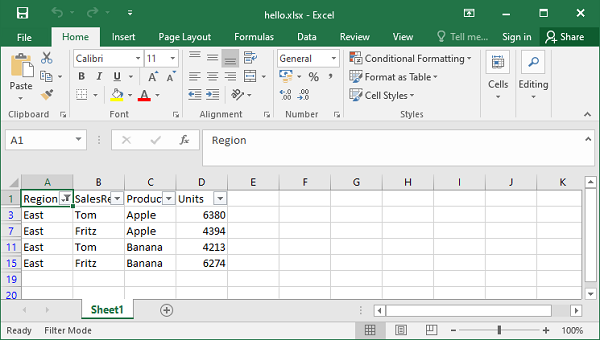
在以下示例中,范围 A1:D51(即单元格 0,0 到 50,3)中的数据用作autofilter()方法的范围参数。使用filter_column()方法在第 0 列(带有区域标题)上设置过滤条件“Region == East”。
例子
通过将工作表对象的set_row()方法的隐藏选项设置为 true,可以隐藏数据范围中不满足过滤条件的所有行。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814]
)
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.autofilter(0, 0, 50, 3)
ws.filter_column(0, 'Region == East')
row = 1
for row_data in (data):
region = row_data[0]
if region != 'East':
ws.set_row(row, options={'hidden': True})
ws.write_row(row, 0, row_data)
row += 1
wb.close()
输出
当我们借助Excel打开工作表时,我们会发现只有Region='East'的行是可见的,其他行是隐藏的(您可以通过清除过滤器来再次显示)。
列参数可以是零索引列号或字符串列名。Python 中允许的所有逻辑运算符都可以在条件中使用(==、!=、<、>、<=、>=)。可以在多个列上定义过滤条件,并且可以通过and或or运算符将它们组合起来。具有逻辑运算符的标准示例如下 -
ws.filter_column('A', 'x > 2000')
ws.filter_column('A', 'x != 2000')
ws.filter_column('A', 'x > 2000 and x<5000')
请注意,标准参数中的“ x ”只是一个正式的占位符,可以是任何合适的字符串,因为无论如何它在内部都会被忽略。
ws.filter_column('A', 'price > 2000')
ws.filter_column('A', 'x != 2000')
ws.filter_column('A', 'marks > 60 and x<75')
XlsxWriter 还允许在包含字符串数据的列的过滤条件中使用通配符“ * ”和“ ? ”。
ws.filter_column('A', name=K*') #starts with K
ws.filter_column('A', name=*K*') #contains K
ws.filter_column('A', name=?K*') # second character as K
ws.filter_column('A', name=*K??') #any two characters after K
例子
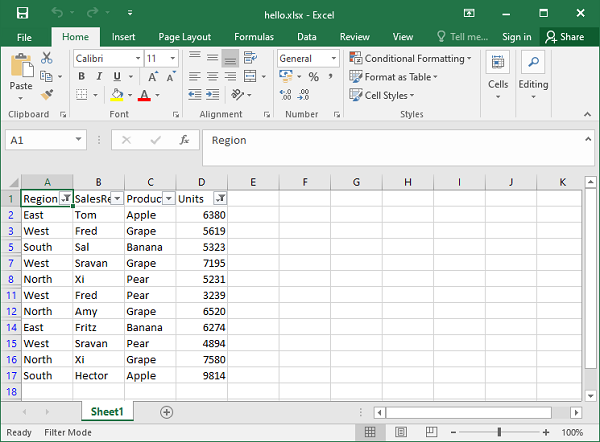
在以下示例中,A 列上的第一个过滤器要求区域为 West,D 列上的第二个过滤器的条件是“ units > 5000 ”。不满足条件“ region = West ”或“ units > 5000 ”的行将被隐藏。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814])
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.autofilter(0, 0, 50, 3)
ws.filter_column('A', 'x == West')
ws.filter_column('D', 'x > 5000')
row = 1
for row_data in (data[1:]):
region = row_data[0]
volume = int(row_data[3])
if region == 'West' or volume > 5000:
pass
else:
ws.set_row(row, options={'hidden': True})
ws.write_row(row, 0, row_data)
row += 1
wb.close()
输出
在 Excel 中,可以在 A 列和 D 列标题上看到筛选器图标。过滤后的数据如下所示 -
应用列列表过滤器
filter_column_list ()方法可用于以 Excel 2007 样式表示具有多个选定条件的筛选器。
ws.filter_column_list(col,list)
第二个参数是与给定列中的数据相匹配的值列表。例如 -
ws.filter_column_list('C', ['March', 'April', 'May'])
它会过滤数据,以便 C 列中的值与列表中的任何项目匹配。
例子
在以下示例中,filter_column_list()方法用于过滤区域等于 East 或 West 的行。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
data = (
['Region', 'SalesRep', 'Product', 'Units'],
['East', 'Tom', 'Apple', 6380],
['West', 'Fred', 'Grape', 5619],
['North', 'Amy', 'Pear', 4565],
['South', 'Sal', 'Banana', 5323],
['East', 'Fritz', 'Apple', 4394],
['West', 'Sravan', 'Grape', 7195],
['North', 'Xi', 'Pear', 5231],
['South', 'Hector', 'Banana', 2427],
['East', 'Tom', 'Banana', 4213],
['West', 'Fred', 'Pear', 3239],
['North', 'Amy', 'Grape', 6520],
['South', 'Sal', 'Apple', 1310],
['East', 'Fritz', 'Banana', 6274],
['West', 'Sravan', 'Pear', 4894],
['North', 'Xi', 'Grape', 7580],
['South', 'Hector', 'Apple', 9814]
)
for row in range(len(data)):
ws.write_row(row,0, data[row])
ws.autofilter(0, 0, 50, 3)
l1= ['East', 'West']
ws.filter_column_list('A', l1)
row = 1
for row_data in (data[1:]):
region = row_data[0]
if region not in l1:
ws.set_row(row, options={'hidden': True})
ws.write_row(row, 0, row_data)
row += 1
wb.close()
输出
A 列显示自动筛选已应用。所有 Region 为 East 或 West 的行都会显示,其余行则隐藏。

在 Excel 软件中,单击“区域”标题中的过滤器选择器箭头,我们应该看到应用了等于“东部”或“西部”的区域过滤器。

Python XlsxWriter - 字体和颜色
使用字体
要执行工作表单元格的格式化,我们需要在add_format()方法的帮助下使用 Format 对象,并使用其属性或格式化方法对其进行配置。
f1 = workbook.add_format()
f1 = set_bold(True)
# or
f2 = wb.add_format({'bold':True})
然后,该格式对象用作工作表的 write() 方法的参数。
ws.write('B1', 'Hello World', f1)
例子
要使单元格中的文本变为粗体、下划线、斜体或删除线,我们可以使用这些属性或相应的方法。在以下示例中,文本 Hello World 是使用 set 方法编写的。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
for row in range(4):
ws.write(row,0, "Hello World")
f1=wb.add_format()
f2=wb.add_format()
f3=wb.add_format()
f4=wb.add_format()
f1.set_bold(True)
ws.write('B1', '=A1', f1)
f2.set_italic(True)
ws.write('B2', '=A2', f2)
f3.set_underline(True)
ws.write('B3', '=A3', f3)
f4.set_font_strikeout(True)
ws.write('B4', '=A4', f4)
wb.close()
输出
这是结果 -

例子
另一方面,我们可以使用font_color、font_name和font_size属性来格式化文本,如下例所示 -
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
for row in range(4):
ws.write(row,0, "Hello World")
f1=wb.add_format({'bold':True, 'font_color':'red'})
f2=wb.add_format({'italic':True,'font_name':'Arial'})
f3=wb.add_format({'font_size':20})
f4=wb.add_format({'font_color':'blue','font_size':14,'font_name':'Times New Roman'})
ws.write('B1', '=A1', f1)
ws.write('B2', '=A2', f2)
ws.write('B3', '=A3', f3)
ws.write('B4', '=A4', f4)
wb.close()
输出
可以通过使用 Excel 打开工作表来验证上述代码的输出 -

文本对齐
XlsxWriter 的 Format 对象也可以使用对齐方法/属性创建。对齐属性可以有左、右、中心和对齐值。
例子
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
for row in range(4):
ws.write(row,0, "Hello World")
ws.set_column('B:B', 30)
f1=wb.add_format({'align':'left'})
f2=wb.add_format({'align':'right'})
f3=wb.add_format({'align':'center'})
f4=wb.add_format({'align':'justify'})
ws.write('B1', '=A1', f1)
ws.write('B2', '=A2', f2)
ws.write('B3', '=A3', f3)
ws.write('B4', 'Hello World', f4)
wb.close()
输出
以下输出显示具有不同对齐方式的文本“Hello World”。请注意,工作表对象的set_column()方法将 B 列的宽度设置为 30 。
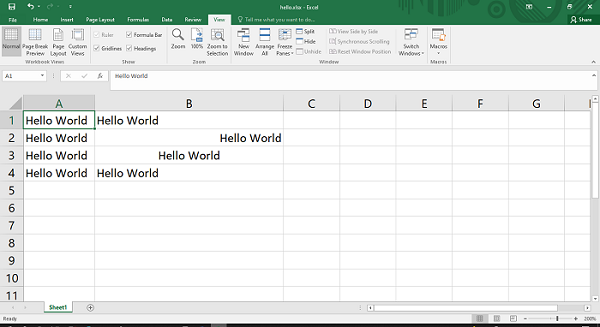
例子
Format 对象还具有valign属性来控制单元格的垂直放置。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
for row in range(4):
ws.write(row,0, "Hello World")
ws.set_column('B:B', 30)
for row in range(4):
ws.set_row(row, 40)
f1=wb.add_format({'valign':'top'})
f2=wb.add_format({'valign':'bottom'})
f3=wb.add_format({'align':'vcenter'})
f4=wb.add_format({'align':'vjustify'})
ws.write('B1', '=A1', f1)
ws.write('B2', '=A2', f2)
ws.write('B3', '=A3', f3)
ws.write('B4', '=A4', f4)
wb.close()
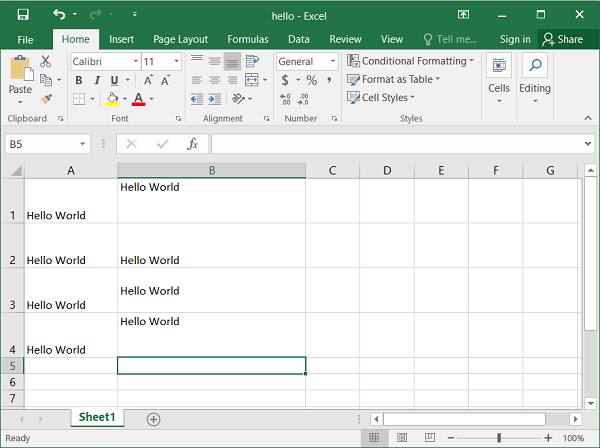
输出
在上面的代码中,使用 set_row() 方法将第 1 行到第 4 行的高度设置为 40。
单元格背景和前景色
Format对象的两个重要属性是bg_color和fg_color,用于设置单元格的背景和前景色。
例子
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
ws.set_column('B:B', 30)
f1=wb.add_format({'bg_color':'red', 'font_size':20})
f2=wb.add_format({'bg_color':'#0000FF', 'font_size':20})
ws.write('B1', 'Hello World', f1)
ws.write('B2', 'HELLO WORLD', f2)
wb.close()
输出
上面代码的结果如下所示 -

Python XlsxWriter - 数字格式
在 Excel 中, “设置单元格格式”菜单的“数字”选项卡中提供了数字数据的不同格式设置选项。
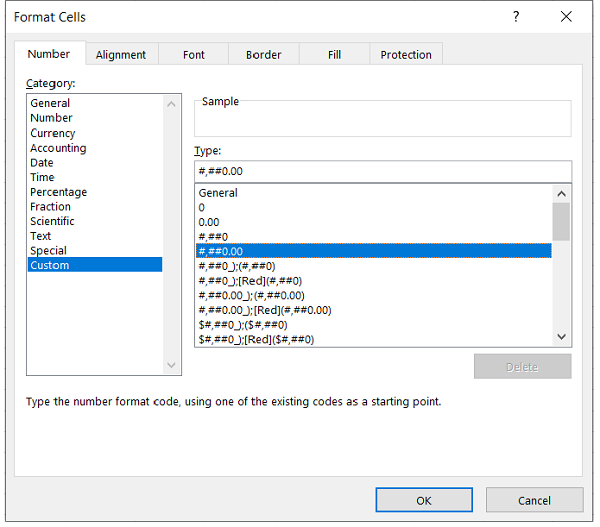
要使用 XlsxWriter 控制数字的格式,我们可以使用set_num_format()方法或定义add_format()方法的num_format属性。
f1 = wb.add_format()
f1.set_num_format(FormatCode)
#or
f1 = wb.add_format('num_format': FormatCode)
Excel 具有多种预定义的数字格式。它们可以在“数字”选项卡的自定义类别下找到,如上图所示。例如,带有两位小数和逗号分隔符的数字的格式代码为#,##0.00。
例子
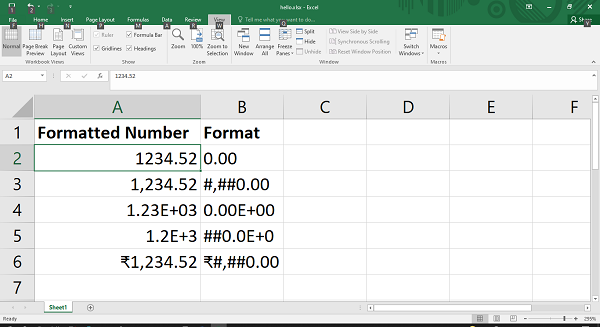
在以下示例中,数字 1234.52 使用不同的格式代码进行格式化。
import xlsxwriter
wb = xlsxwriter.Workbook('hello.xlsx')
ws = wb.add_worksheet()
ws.set_column('B:B', 30)
num=1234.52
num_formats = (
'0.00',
'#,##0.00',
'0.00E+00',
'##0.0E+0',
'₹#,##0.00',
)
ws.write('A1', 'Formatted Number')
ws.write('B1', 'Format')
row = 1
for fmt in num_formats:
format = wb.add_format({'num_format': fmt})
ws.write_number(row, 0, num, format)
ws.write_string(row, 1, fmt)
row += 1
wb.close()
输出
格式化的数字以及使用的格式代码如下图所示 -
Python XlsxWriter - 边框
本节介绍如何应用单元格边框以及文本框周围的边框并设置其外观格式。
使用单元格边框
add_format()方法中控制单元格边框外观的属性如下表所示 -
| 描述 | 财产 | 方法 |
|---|---|---|
| 单元格边框 | '边界' | 设置边框() |
| 下边框 | '底部' | 设置底部() |
| 顶部边框 | '顶部' | 设置顶部() |
| 左边框 | '左边' | set_left() |
| 右边框 | '正确的' | 设置权限() |
| 边框颜色 | '边框颜色' | 设置边框颜色() |
| 底色 | '底部颜色' | 设置底部颜色() |
| 顶部颜色 | '顶部颜色' | 设置顶部颜色() |
| 左颜色 | '左颜色' | 设置左颜色() |
| 正确的颜色 | '右颜色' | 设置右颜色() |
请注意,对于add_format()方法的每个属性,都有一个以set_propertyname()方法开头的相应格式类方法。
为了