无服务器 - 快速指南
无服务器 - 简介
什么是无服务器?
嗯,这个名字给了你很多暗示。无需维护服务器的麻烦即可进行计算——这是无服务器计算(或简称无服务器)的关键。这个概念是相当革命性和颠覆性的。它已被广泛采用。一些新的应用程序从设计无服务器后端开始,而具有专用服务器的遗留应用程序也正在慢慢迁移到无服务器架构。那么是什么导致了无服务器的广泛采用呢?与所有事物一样,经济因素使得无服务器变得非常有利。
您会看到,使用无服务器,您只需为您使用的内容付费。想象一下,您每天需要对数据库执行一些例行维护。这个过程每天可能需要大约 10 分钟。
现在,在没有无服务器计算的情况下,您的维护 cron 可能驻留在服务器中。除非您在剩余时间内有其他事情需要处理服务器,否则您最终可能会为需要 10 分钟的任务支付 24 小时的费用。相当浪费钱,对吧?如果您被告知有一项新服务将按照您的维护 cron 执行所需的 10 分钟准确收费,该怎么办?您不想简单地切换到新服务吗?这正是无服务器采用如此迅速和广泛的原因。它降低了多个组织的后端费用,并减少了服务器维护的麻烦。
云服务提供商(AWS、Azure 等)很头疼地确保无服务器应用程序在需要时准确可用且数量充足。因此,在高负载期间,您可以调用多个无服务器应用程序,而在正常负载期间您可以调用单个应用程序。当然,您只需在高负载期间支付额外的调用费用。
什么是无服务器?
上面解释的概念看起来很棒,但是如何实现呢?你需要一个框架。它被称为,呃,无服务器。
无服务器框架帮助我们开发和部署旨在以无服务器方式运行的功能/应用程序。该框架向前迈出了一步,负责部署无服务器函数运行所需的整个堆栈。什么是堆栈?该堆栈包含部署、存储和监控无服务器应用程序所需的所有资源。
它包括实际的函数/应用程序、存储容器、监控解决方案等等。例如,在 AWS 的上下文中,您的堆栈将包含实际的 Lambda 函数、用于函数文件的 S3 存储桶、链接到您的 Cloudwatch 资源。无服务器框架为我们创建了整个堆栈。这使我们能够完全专注于我们的功能。无服务器消除了维护服务器的麻烦,无服务器(框架)消除了创建和部署运行我们的功能所需的堆栈的麻烦。
无服务器框架还负责为我们的功能/应用程序分配必要的权限。一些应用程序(我们将在本教程中看到的示例)甚至需要将数据库链接到它们。无服务器框架再次负责创建和链接数据库。无服务器如何知道堆栈中包含哪些内容以及提供哪些权限?所有这些都在 serverless.yml 文件中提到,这将是我们在本教程中的主要关注点。在接下来的章节中将详细介绍它。
AWS 中的无服务器
AWS 的许多服务都属于“无服务器计算”的范畴。您可以在此处找到完整的组织列表。有计算服务、集成服务,甚至数据存储服务(是的,AWS 甚至有无服务器数据库)。在整个教程中,我们将重点关注 AWS Lambda 函数。那么什么是AWS Lambda?AWS Lambda 网站将其定义如下 -
AWS Lambda 是一种无服务器计算服务,让您无需预置或管理服务器、创建工作负载感知集群扩展逻辑、维护事件集成或管理运行时即可运行代码。
通俗地说,AWS Lambda 是您在 AWS 上进行无服务器计算的窗口。正是 AWS Lambda 让无服务器概念如此流行。您需要做的就是定义您的函数和函数的触发器,并且该函数将在您希望调用它时准确地调用它,并且您只需为该函数执行所需的时间付费。此外,您可以将 AWS Lambda 与 AWS 提供的几乎所有其他服务链接 - EC2、S3、dynamoDB 等。
因此,如果您已经成为AWS生态系统的一部分,那么Lambda集成是相当无缝的。如果您像我第一次了解 AWS Lambda 时一样刚接触 AWS 生态系统,那么它将成为通往 AWS 世界的良好门户。
在本教程中,我们将学习有关使用无服务器框架部署 AWS Lambda 函数的所有信息。你兴奋吗?然后继续下一章开始。
无服务器 - 安装
无服务器安装已在另一个教程点教程中介绍。在这里复制它,并进行一些修改和添加。
步骤1 - 安装nodejs
首先,您需要先安装nodejs。您可以通过打开命令提示符并输入node -v来检查您的计算机中是否安装了nodejs 。如果安装了,您将获得节点的版本号。否则,您可以从此处下载并安装节点。

步骤 2 - 使用 npm 命令安装无服务器
您可以使用以下命令安装无服务器(npm 代表节点包管理器) -
npm install -g serverless
您可以通过运行serverless create --help检查它是否已成功安装。如果无服务器安装成功,您应该会看到创建插件的帮助屏幕。
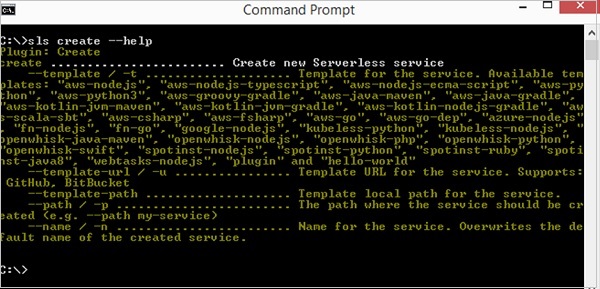
请注意,您可以在所有命令中使用简写sls而不是serverless 。
步骤 3 - 配置凭证
您需要从 AWS 获取凭证才能配置无服务器。为此,可以在 AWS 控制台中创建一个用户(通过 IAM -> 用户 -> 添加用户),或者单击 IAM -> 用户中的现有用户。如果您要创建新用户,则需要附加一些必需的策略(例如 Lambda 访问权限、S3 访问权限等)或向用户提供管理员访问权限。
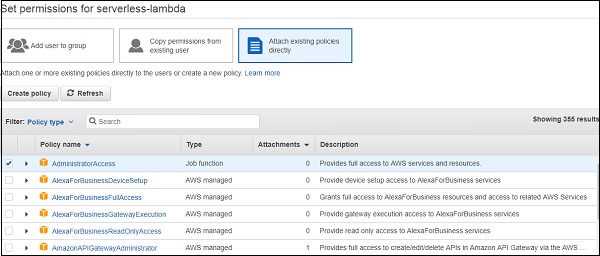
创建用户后,您将能够看到访问密钥和秘密密钥。请对此保密。

如果您是现有用户,您可以按照此处提到的步骤生成新的 Access Key 和 Secret 。
一旦您拥有方便的访问密钥和密钥,您可以使用以下命令在无服务器中配置凭据 -
serverless config credentials --provider aws --key 1234 --secret 5678 --profile custom-profile
配置文件字段是可选的。如果将其留空,则默认配置文件为“aws”。请记住您设置的配置文件名称,因为您必须在我们将在下一个教程中看到的 serverless.yml 文件中提及它。
如果您已完成上述步骤,则无服务器配置已完成。继续下一章创建您的第一个无服务器项目。
Serverless - 部署功能
创建一个新项目
导航到一个新文件夹,您要在其中创建第一个要部署到无服务器的项目。在该文件夹中,运行以下命令 -
sls create --template aws-python3
此命令将创建用于使用无服务器和 python 运行时部署 lambda 函数的样板代码。
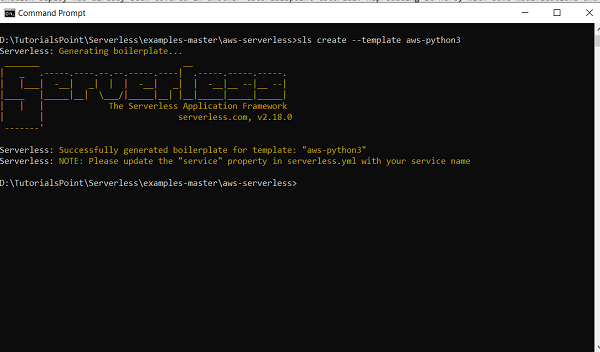
请注意,您也可以使用其他运行时。运行sls create --help以获取所有模板的列表。
创建样板代码后,您将在文件夹中看到两个文件:handler.py 和 serverless.yml。handler.py 是包含 lambda 函数代码的文件。serverless.yml 是告诉 AWS 如何创建 lambda 函数的文件。配置文件或设置文件将成为本教程几章的重点。让我们首先浏览一下 handler.py 文件。
import json
def hello(event, context):
body = {
"message": "Go Serverless v1.0! Your function executed successfully!", "input": event
}
response = {
"statusCode": 200, "body": json.dumps(body)
}
return response
# Use this code if you don't use the http event with the LAMBDA-PROXY
# integration
"""
return {
"message": "Go Serverless v1.0! Your function executed successfully!", "event": event
}
"""
它包含一个函数hello。该函数接受两个参数:事件和上下文。这两个参数都是任何 AWS Lambda 函数的必需参数。每当调用 lambda 函数时,lambda 运行时都会向函数传递两个参数 - 事件和上下文。
事件参数包含 lambda 函数要处理的数据。例如,如果您通过 REST API 触发 lambda 函数,则您在路径参数或 API 正文中发送的任何数据都将发送到事件参数中的 lambda 函数。在后面的章节中将详细介绍。需要注意的重要一点是,事件通常是 python dict类型,但也可以是str、float、int、list或NoneType类型。
上下文对象是运行时传递给 lambda 函数的另一个参数。它不经常使用。AWS 官方文档指出,该对象提供了提供有关调用、函数和运行时环境信息的方法和属性。您可以在此处阅读有关事件和上下文对象的更多信息。
该功能非常简单。它只是返回一条状态代码为 200 的消息。如果我们不将 HTTP 事件与 LAMBDA-PROXY 设置一起使用,则应使用底部的注释。更多内容请参见 API 触发的 lambda 章节。
现在,让我们看一下 serverless.yml 文件。这是一个带有大量注释的文件。这些评论对于刚开始接触无服务器的人来说非常有用。我们鼓励您彻底阅读这些评论。我们将在接下来的章节中讨论许多与 serverless.yml 相关的概念。让我们浏览一下这里的基本概念。
如果您在删除注释后查看 serverless.yml 文件,它会是这样的 -
service: aws-serverless
frameworkVersion: '2'
provider:
name: aws
runtime: python3.8
lambdaHashingVersion: 20201221
functions:
hello:
handler: handler.hello
service 字段确定将在其中创建 lambda 函数和所有必需资源的 CloudFormation 堆栈的名称。将服务视为您的项目。AWS Lambda 函数执行所需的一切都将在该服务中创建。您可以设置您选择的服务名称。
框架版本是指Serverless框架的版本。它是一个可选字段,通常保留它是为了确保与您共享代码的人使用相同的版本号。如果 serverless.yml 中提到的 FrameworkVersion 与您计算机中安装的 Serverless 版本不同,您将在部署过程中收到错误。您还可以指定frameworkVersion的范围,例如frameworkVersion - >=2.1.0 && <3.0.0。您可以在此处阅读有关框架版本的更多信息。
下一部分,provider,可以被视为一组全局设置。我们将在后面的章节中讨论提供程序中涵盖的其他参数。在这里,我们将重点关注可用的参数。名称字段确定您的平台环境的名称,在本例中为 aws 。运行时是python3.8,因为我们使用了python3模板。lambdaHashingVersion 是指框架应使用的哈希算法的名称。
请注意,如果您在上一章的配置凭据步骤中添加了自定义配置文件,则需要在提供中添加配置文件参数。例如,我将我的个人资料名称设置为 yash-sanghvi。因此,我的提供者看起来像 -
provider: name: aws runtime: python3.8 lambdaHashingVersion: 20201221 profile: yash-sanghvi
最后,函数块定义了所有 lambda 函数。我们这里只有一个函数,位于处理程序文件中。该函数的名称是 hello。函数的路径在处理程序字段中提到。
部署功能
要部署该功能,您需要打开命令提示符,导航到包含 serverless.yml 的文件夹,然后输入以下命令 -
sls deploy -v
-v是一个可选参数,指示详细输出。它可以帮助您更好地了解后台进程。部署函数后,您应该能够在 us-east-1 区域(默认区域)的 AWS 控制台上看到它。您可以使用“测试”功能从控制台调用它(您可以保留相同的默认事件,因为我们的 lambda 函数无论如何都不使用事件输入)。您还可以使用命令提示符来测试它 -
sls invoke --function hello
请注意,如果您的函数与 S3 或 dynamoDB 等其他 AWS 服务交互,您无法始终在本地测试您的函数。只能在本地测试非常基本的函数。
从现有项目部署功能
如果您想要将现有项目部署到 AWS,请修改现有函数以仅接受事件和上下文作为参数。接下来,在该文件夹中添加一个 serverless.yml 文件,并在 serverless.yml 中定义您的函数。然后打开命令提示符,导航到该文件夹,然后点击sls deploy -v。这样,您现有的函数也可以部署到 AWS Lambda。
无服务器 - 区域、内存大小、超时
我们在上一章中了解了如何使用无服务器部署第一个功能。在本章中,我们将了解可以对该函数执行的一些配置。我们将主要关注区域、内存大小和超时。
地区
默认情况下,使用无服务器部署的所有 lambda 函数都在 us-east-1 区域中创建。如果您希望在不同区域创建 lambda 函数,您可以在提供程序中指定。
provider: name: aws runtime: python3.6 region: us-east-2 profile: yash-sanghvi
无法在同一 serverless.yml 文件中为不同功能指定不同区域。您应该仅在特定的 serverless.yml 文件中包含属于单个区域的函数。属于单独区域的功能可以使用单独的 serverless.yml 文件进行部署。
内存大小
AWS Lambda 根据所选内存的比例分配 CPU。根据最近宣布的更改,您可以为 lambda 函数选择高达 10GB 的 RAM(之前约为 3GB)。
选择的 RAM 越高,分配的 CPU 就越高,函数执行的速度就越快,执行时间就越短。AWS Lambda 按消耗的 GB 数向您收费。因此,如果一个函数在 1 GB RAM 上执行需要 10 秒,而在 2 GB RAM 上执行需要 5 秒,则两次调用将收取相同的费用。将内存加倍所需的时间是否减半很大程度上取决于函数的性质,并且您可能会也可能不会通过增加内存而受益。关键要点是分配的内存量对于每个 lambda 函数以及您想要控制的函数来说都是一项重要设置。
使用无服务器,可以很容易地为 serverless.yml 文件中定义的函数设置内存大小的默认值。还可以为不同的功能定义不同的内存大小。让我们看看如何。
为所有函数设置默认内存大小
默认值始终在提供程序中提及。该值将由该 serverless.yml 中的所有函数继承。memorySize键用于设置该值。该值以MB表示。
provider: name: aws runtime: python3.6 region: us-east-2 profile: yash-sanghvi memorySize: 512 #will be inherited by all functions
如果您未在提供程序或单个函数中指定内存大小,则将考虑默认值 1024。
为某些功能设置自定义内存大小
如果您希望某些函数具有与默认内存不同的值,则可以在 serverless.yml 的函数部分中指定它。
functions:
custom_memory_func: #will override the default memorySize
handler: handler.custom_memory
memorySize: 2048
default_memory_func: #will inherit the default memorySize from provider
handler: handler.default_memory
暂停
就像内存大小一样,可以在提供程序中设置超时的默认值(以秒为单位),并且可以在函数部分中指定各个函数的自定义超时。
如果您未指定全局或自定义超时,则默认值为 6 秒。
provider:
name: aws
runtime: python3.6
region: us-east-2
profile: yash-sanghvi
memorySize: 512 #will be inherited by all functions
timeout: 50 #will be inherited by all functions
functions:
custom_timeout: #will override the default timeout
handler: handler.custom_memory
timeout: 30
default_timeout_func: #will inherit the default timeout from provider
handler: handler.default_memory
确保将超时保持在保守值。它不应该太小,以至于您的函数经常超时,也不应该太大,以免您的函数中的错误导致您需要支付巨额费用。
无服务器 - 服务
您不想为部署的每个函数创建单独的 serverless.yml 文件。那会非常乏味。幸运的是,无服务器可以在同一个 serverless.yml 文件中部署多个功能。所有这些功能都属于一个称为“服务”的组。服务名称通常是 serverless.yml 文件中定义的第一个内容。
service: my-first-service
provider:
name: aws
runtime: python3.6
stage: prod
region: us-east-2
profile: yash-sanghvi
functions:
func1:
handler: handler1.func1
func2:
handler: handler2.func2
服务中的所有函数在部署时在 AWS Lambda 控制台上采用以下名称格式 - service_name-stage_name-function_name。因此,上面示例中的两个函数在部署时将采用名称 - my-first-service-prod-func1和my-first-service-prod-func2。stage 参数可帮助您区分代码开发的不同阶段。
因此,如果您的功能处于开发阶段,您可以使用 stage dev;如果是测试阶段,可以使用阶段测试;如果是在生产中,您可以使用 stage prod。这样,您可以确保对开发阶段所做的更改不会影响生产代码。艺名并不是一成不变的。开发、测试、生产只是示例。
您可以选择任何艺名。请注意,如果您有 API Gateway 触发的 lambda(将在后面的章节中详细介绍),那么每个阶段的端点都会不同。
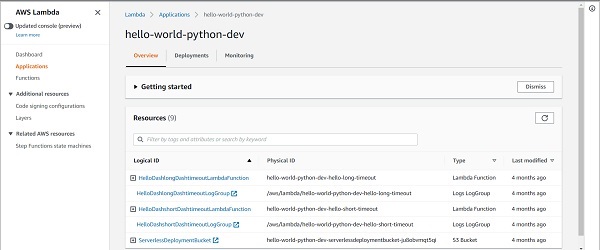
此外,如果您转到 AWS Lambda 控制台中较少使用的“应用程序”部分,您将能够看到该阶段的整个服务。
如果您单击您选择的服务和阶段组合,您将能够在一处查看该服务使用的所有资源 - Lambda 函数、API 网关、事件规则、日志组、S3 存储桶,一切。
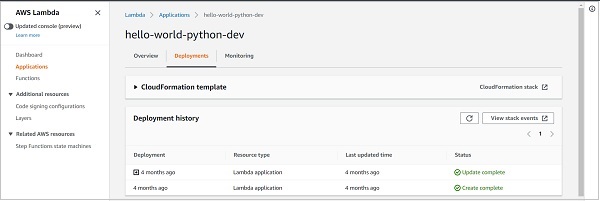
更有趣的是,您可以转到“监控”选项卡,查看整个服务的性能 -> 调用次数、平均持续时间、错误计数等。您可以了解哪个功能对服务的贡献最大你的账单。当您的服务中有多个功能时,监控每个功能的性能就变得非常困难。服务级别监控选项卡在这里有很大帮助。
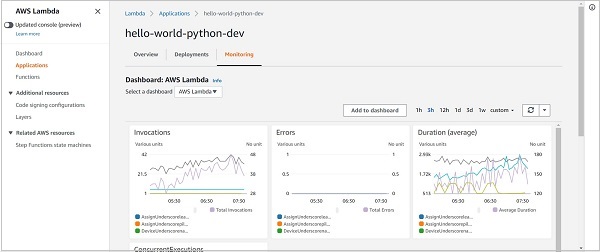
最后,“部署”选项卡可帮助您查看服务的所有过去部署以及部署的状态。
无服务器 - 预定的 Lambda
通常,您需要以固定的时间间隔调用您的函数。可以是每天一次、每周两次、工作日每分钟一次等等。Serverless 提供两种类型的事件来以固定频率调用函数。它们是 cron 事件和rate 事件。
计划任务事件
cron 事件比rate 事件具有更大的灵活性。唯一的缺点是它不如利率事件那么容易理解。AWS 文档中定义了 cron 表达式的语法-
cron(minutes hours day-of-month month day-of-week year)
可以看出,cron 表达式由 6 个字段组成。每个字段都可以接受一些可接受的值,以及一些(AWS 称之为通配符)。
让我们先看看可接受的值 -
分钟- 0-59
小时- 0-23
一个月中的某一天- 1-31
月− 1-12 或 JAN-DEC
星期几- 1-7 或 SUN-SAT
年- 1970-2199
现在接受的值已经很清楚了,让我们看一下通配符。cron 表达式中总共有 8 个可能的通配符(有些允许所有 6 个字段,有些仅适用于特定字段)。将它们列在这里 -
*(星号,允许所有 6 个字段) - 这是最流行的通配符。它只是说包含该字段的所有值。小时字段中的 * 表示 cron 每小时运行一次。日期字段中的 * 表示 cron 将每天运行。
,(逗号,允许所有 6 个字段) - 这用于指定多个值。例如。如果您希望 cron 在每小时的第 5、7 和 9 分钟运行,您的分钟字段将类似于 5,7,9。同样,星期几中的 MON,TUE,WED,THU,FRI字段可能意味着 cron 应该只在工作日运行。
-(破折号,允许所有 6 个字段) - 此通配符指定范围。在前面的通配符示例中,为了指定工作日,我们可以简单地写为 MON-FRI,而不是指定 5 个逗号分隔值
?(问号,仅允许用于月份中的某一天和星期几) - 这就像一个无关通配符。如果您在星期几字段中指定了 MON,则您不必关心星期一是哪一天。因此,您将输入?代替月份中的某一天。同样,如果您希望 cron 在每个月的 5 日运行,您将在日期字段中输入 5,然后输入 ? 在星期几字段中,因为您不关心每个月的 5 号是哪一天。请注意,AWS 文档明确指出您不能将 * 用于星期几和月份字段。如果您使用 * 作为其中之一,则必须使用 ? 对于另一个
/(正斜杠,允许用于除月份之外的 5 个字段) - 该字段指定增量。如果您在小时字段中输入 0/2,则该 cron 将每隔偶数小时运行一次(0、0+2、0+2+2 等)。如果您在小时字段中指定 1/2,则此 cron 将每隔奇数小时运行一次(1、1+2、1+2+2 等)。正如您所猜测的,/ 之前的值是起始值,其之后的值定义增量。
L(仅允许用于月份中的某一天和星期几) - 指定该月的最后一天或一周的最后一天
W(仅允许用于月份中的某一天) - 这指定最接近该月特定日期的工作日(周一至周五)。因此,如果您在日期字段中指定 8W,并且它对应于工作日(例如星期二),那么 cron 将在 8 号本身触发。但如果 8 对应周末,比如周六,那么 cron 将会在 7 日(周五)触发。如果 8 日对应星期日,则 cron 将在 9 日(星期一)触发。这是最少使用的通配符之一。
#(仅允许用于星期几) - 这是一个非常特殊的通配符,最好通过示例来理解。假设您希望在母亲节运行一个 cron。现在,母亲节是每年 5 月的第 2 个星期日。因此,您的月份字段将包含 MAY 或 5。但是如何指定第 2 个星期日呢?进来主题标签。表达式为0#2。通配符前面的值是星期几(0 表示星期日,1 表示星期一,依此类推)。通配符后面的值指定出现的情况。因此,这里的2指的是第二次出现的星期日或第二个星期日。
现在,要为 lambda 函数定义 cron 触发器,您所需要做的就是在 serverless.yml 函数的 events 键中指定 cron 表达式。
functions:
cron_triggered_lambda:
handler: handler.hello
events:
- schedule: cron(10 03 * * ? *) #run at 03:10 (UTC) every day.
一些例子
下面给出了 cron 表达式的一些示例 -
cron(30 15 ? * MON-FRI *) - 每个工作日 15:30 (UTC) 触发
cron(0 9 ? 6 0#3 *) - 在六月第三个星期日(父亲节)09:00(UTC)触发
cron(0/15 * ? * MON *) - 周一每 15 分钟触发一次
cron(0/30 9-18 ? * MON-FRI *) - 工作日上午 9 点到下午 5:30 每 30 分钟触发一次(对应于多个地方的办公时间)
评价事件
与 cron 表达式相比,这要简单得多。语法很简单:rate(value unit)。例如,速率(5 分钟)。
该值可以是任何正整数,允许的单位是分钟、小时、天。
为 lambda 函数定义速率触发器与定义 cron 触发器类似。
functions:
rate_triggered_lambda:
handler: handler.hello
events:
- schedule: rate(10 minutes) #run every 10 minutes
一些例子
rate(2 小时) − 每 2 小时触发一次
速率(1 天) - 每天触发(在 00:00 UTC)
rate(90 分钟) − 每 90 分钟触发一次
正如您所意识到的,利率表达式的简单性是以降低灵活性为代价的。您可以使用每 N 分钟/小时/天运行一次的 lambda 速率。要执行任何更复杂的操作,例如仅在工作日触发 lambda,您必须使用 cron 表达式。
请注意,如果您的 cron 表达式以某种方式导致触发时间少于一分钟,则它将不受支持。
参考
无服务器 - API 网关触发 Lambda
API 网关是触发 lambda 的另一种流行方法,就像 cron/rate 事件一样。基本上,您会获得 lambda 函数的 URL 端点。此 URL 属于连接到您的 lambda 的 API 网关。每当您在浏览器中或通过应用程序调用 URL 时,您的 lambda 函数都会被调用。在本章中,我们将了解如何使用无服务器框架将 API 网关连接到 lambda 函数,以及如何测试它。
HTTP 事件
要将 API 网关链接到 lambda 函数,我们需要在 serverless.yml 的函数定义中创建 HTTP 事件。以下示例演示如何将 lambda 函数链接到 REST API 并使用 GET 请求触发它。
functions:
user_details_api:
handler: handler.send_user_details
events:
- http:
path: details/{user_id}
method: get
integration: lambda-proxy
cors: true
location_api:
handler: handler.send_location
events:
- http:
path: location/{user_id}
method: get
integration: lambda-proxy
cors: true
让我们一一打开钥匙。我们将只讨论上面列表中的第一个函数 (user_details_api)。下面介绍的概念也适用于其他函数。
路径的值指定调用URL的端点之后的地址。上例中定义的两个函数将共享相同的端点,但一个将使用端点/详细信息/{user_id}调用,而另一个将通过端点/位置/{user_id}调用。大括号内的元素是路径参数。我可以发送任何值来代替 user_id,并且 lambda 函数可以编程为返回该特定用户的详细信息(请参阅下面的示例函数)。
method的值表示请求的方法。流行的方法是 get 和 post。还有其他几种方法。深入研究这些方法的细节超出了本章的范围。在tutorialspoint上有另一篇文章,您可以参考以了解详细信息。
集成字段指定 lambda 函数如何与 API 网关集成。默认是lambda-proxy,而其他可能的选项是lambda、http、http-proxy、mock。这两个选项中使用最广泛的选项是 lambda 和 lambda-proxy。用外行人的话来说,lambda-proxy将全部控制权交给 lambda 函数,而lambda将部分控制权交给 API 网关,将部分控制权交给 lambda 函数。
如果您选择lambda-proxy作为集成类型,则整个 HTTP 请求将以原始形式传递给您的 lambda 函数,并且 lambda 函数发送的响应将不经更改地传递给发出请求的客户端。因此,您必须在 lambda 函数的响应中定义 statusCode 和标头。
如果您选择lambda作为集成类型,您的 API 网关可以对收到的请求进行更改,然后再将其传递给 lambda 函数。同样,它也可以在将 lambda 函数发送的响应转发到客户端之前对其进行修改。API 网关将状态代码和标头添加到响应中,因此 lambda 函数只需担心发送正文。两种选择都有其优点和缺点。
如果您喜欢简单性,可以使用lambda-proxy。如果您可以接受一定的复杂性(因为您将不得不担心 lambda 函数的代码以及 API 网关的配置),但需要更多的控制,则可以选择 lambda 。
您可以在此处详细了解这两种类型之间的区别。在其他集成类型中,在将 API 网关与 HTTP 后端集成时使用http和http-proxy,而不是 lambda 函数,因此与我们无关。当您只想测试API而不调用后端时,可以使用mock 。
cors - true配置启用 CORS(跨源资源共享)。通俗地说,这意味着您允许来自另一个域的服务器的请求。如果没有cors - true,则仅允许来自同一域的请求。当然,您可以仅允许某些特定域,而不是允许所有域。要了解如何执行此操作,请参阅文档。
对于 API 网关触发的 lambda,无服务器中还有更多可能的配置。强烈建议您仔细阅读文档,或者至少为链接添加书签,以便您可以在需要时进行查找。
示例 Lambda 函数
此时,您可能想知道您创建了 API Gateway 触发函数,但是如何访问 lambda 函数中的路径参数呢?以下 Python 中的 lambda 函数示例将回答这个问题。当集成类型为lambda-proxy时,我们基本上使用'pathParameters'属性。
import json
def lambda_handler(event, context):
# TODO implement
# print(event)
#helps you see the entire input request. The printed output can be found in CloudWatch logs
user = event['pathParameters']['user_id']
return {
'statusCode': 200,
'body': json.dumps('Hello ' + str(user))
}
访问端点
现在,您可能遇到的另一个问题是如何访问端点。有多种方法可以做到这一点。第一种方式是通过无服务器部署。每当您通过服务部署一个或多个功能时,端点都会显示在无服务器部署的末尾。
第二种方法是通过 Lambda 控制台。如果您在 lambda 控制台上导航到您的函数,您可以看到附加到它的 API 网关。单击它应该会显示端点。
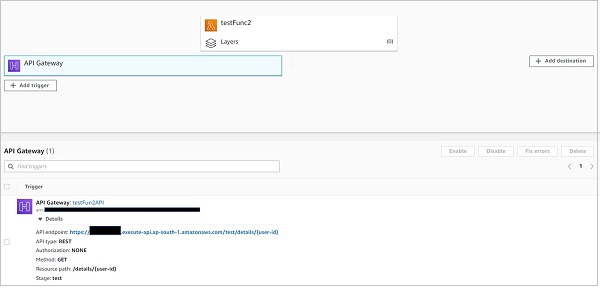
请注意,如上所述,服务中的所有功能共享相同的端点。路径属性将一个功能的实际触发 URL 与另一个功能区分开来。
参考
无服务器 - 包含/排除
我们已经在“部署函数”一章中看到,要将函数从现有项目部署到 AWS lambda,您需要修改函数以将事件和上下文作为参数,并且需要在项目文件夹,其中定义了函数。然后点击无服务器部署即可完成工作。
通常,特别是当您被要求将某些函数从庞大的现有项目迁移到 AWS Lambda 时,您会面临大小挑战。如果您的项目足够大,您很可能会超出 AWS 对 Lambda 函数施加的大小限制(250 MB,包括应用程序代码及其依赖项)。
一些依赖项(例如 NumPy)本身占用了大量空间。例如,NumPy 大约有 80 MB 大,SciPy 也差不多,等等。在这种情况下,留给应用程序代码的空间非常有限,需要一种从 lambda 部署包中排除不必要文件的方法。幸运的是,无服务器使这变得非常容易。
包含和排除字段
正如您所猜测的,您可以使用“排除”标签指定要从部署构建中排除的文件和文件夹。默认情况下,包含排除部分中未指定的所有文件/文件夹。那么“include”标签有什么用呢?那么,如果您希望一般排除某个文件夹,但只想包含该文件夹中的几个文件或子文件夹,则可以在“include”标记中指定这些文件/子文件夹。这样,该文件夹中的所有其他文件都将被排除,并且仅保留“include”部分中指定的文件。下面的例子将更好地解释这一点。
service: influx-archive-pipeline
provider:
name: aws
runtime: python3.6
stage: prod
region: us-east-2
profile: yash-sanghvi
timeout: 900
memorySize: 1024
# you can add packaging information here
package:
include:
- src/models/config.py
- src/models/lambda_apis/**
- src/models/scheduled_lambdas/**
exclude:
- docs/**
- models/**
- notebooks/**
- references/**
- reports/**
- src/data/**
- src/visualization/**
- src/models/**
- utils/**
functions:
user_details_api:
handler: src/models/lambda_apis/user_details_api.sync_user_details
events:
- http:
path: details/{user_id}
method: get
integration: lambda
cors: true
monitoring_lambda:
handler: src/models/scheduled_lambdas/monitoring_lambda.periodic_monitoring
events:
- schedule: cron(15 16 * * ? *)
正如您可以从上面的 severless.yml 文件中看到的那样,我们排除了包含 serverless.yml 的根文件夹中的大多数文件夹。我们甚至排除了 src/models 文件夹。但是,我们希望在 src/models 中包含 2 个子文件夹和 1 个文件。因此,这些内容已被专门添加到“包含”部分中。请注意,默认情况下将包含不属于排除部分的任何文件/文件夹。
请注意两个 lambda 函数的路径。它们都位于 src/models 中。虽然默认情况下排除 src/models,但这些函数具体位于include部分中提到的子文件夹中。因此他们将毫无问题地执行。如果我添加一个位于 src/data 中的函数,这是不允许的,因为 src/data 的所有内容都已被排除。
请注意,指定/**表示覆盖该文件夹中的所有内容(文件/子文件夹)。因此,如果 docs 文件夹包含 10 个子文件夹和 12 个文件(所有这些都需要排除),则-docs/**可以完成这项工作。我们不需要单独提及每个文件/文件夹。
无服务器 - 插件
随着无服务器的普及,针对利基用户案例的更多功能的需求自然会增加。这些需求都是通过插件来满足的。顾名思义,插件是可选的,您只需安装您需要的插件。在本章中,我们将了解如何访问可用于 Serverless 的几个插件、如何安装这些插件以及如何在 serverless.yml 中引用它们。
浏览插件列表
所有可用于 Serverless 的插件都可以在www.serverless.com/plugins/上找到
您可以在这里搜索插件。例如,如果您搜索“Python”,您将看到几个专门为 python 运行时开发的插件。它们按照受欢迎程度排列。
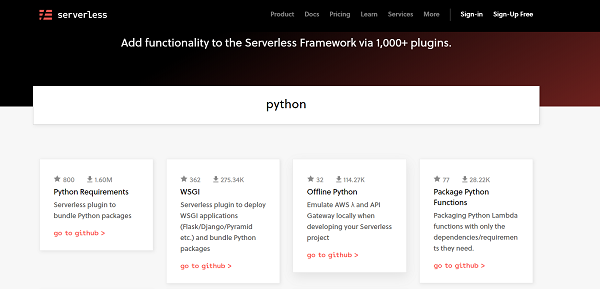
让我们看看最流行的 python 插件(在撰写本文时):Python 要求。单击该插件。这将打开与该插件相关的详细文档。
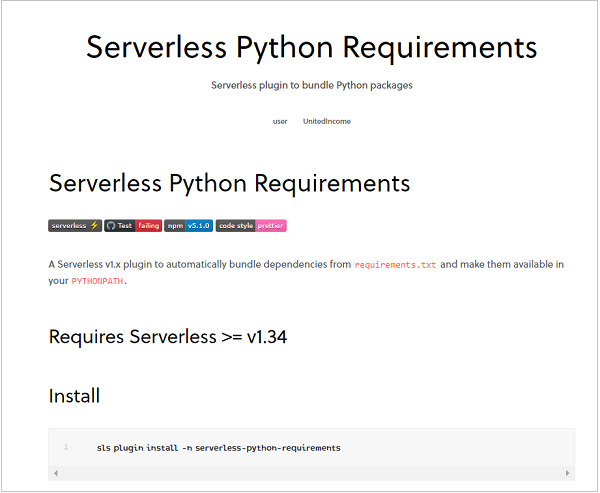
本文档涵盖了两个最重要的方面 - 安装插件并在 serverless.yml 中引用它。对于任何插件都是如此。你只需要打开它的文档就可以知道该插件的安装和使用。回到 Python 需求插件,文档指出该插件会自动捆绑requirements.txt 中的依赖项,并使它们在您的 PYTHONPATH 中可用。
换句话说,如果您的 lambda 函数需要其他依赖项,例如 pandas、numpy、matplotlib 等,您只需在与 serverless.yml 文件位于同一文件夹中的 requests.txt 文件中指定这些依赖项。然后这个插件将完成剩下的工作。您甚至可以在requirements.txt中指定库的版本号。例如,示例requirements.txt文件如下所示:
aws-psycopg2==1.2.1 boto boto3==1.7.62 botocore==1.10.62 numpy==1.14.5 pandas==0.25.0 scipy==1.5.2 sqlalchemy==1.2.15
正如您所看到的,您可以仅提及依赖项名称,也可以添加版本号(用 == 符号分隔)。当然,依赖项以及应用程序代码的大小不应超过 250 MB。因此,仅包含您实际需要的依赖项至关重要。
现在,让我们回到我们的插件。我们已准备好requirements.txt 文件。下一步是安装插件。打开命令提示符并导航到包含 serverless.yml 文件的项目文件夹。然后,按照文档,运行以下命令来安装插件 -
sls plugin install -n serverless-python-requirements
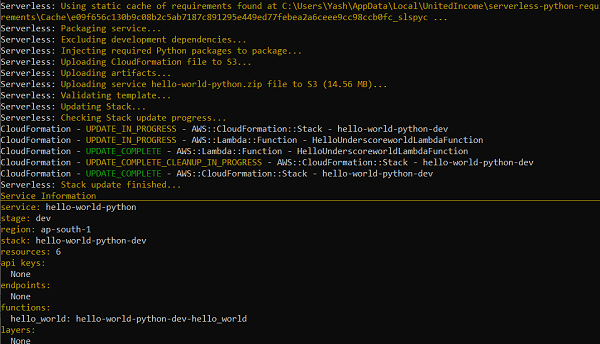
事实上,如果您将serverless-python-requirements替换为任何其他插件名称,上述命令仍然适用于大多数插件。但是,建议您在安装新插件时遵循文档中给出的安装命令。当您运行上述命令时,您应该看到类似于下图中的消息 -

如您所见,在项目文件夹中创建了一个packages.json 文件。如果项目文件夹中存在packages.json 文件,则会对其进行编辑以包含上述插件。此外,serverless.yml 文件将自动进行编辑以包含已安装的插件。如果您现在打开 serverless.yml 文件,您应该会看到添加了以下几行 -
plugins: - serverless-python-requirements
这意味着 serverless.yml 中插件的引用是自动完成的。有几个与此插件相关的设置,可以在文档中找到。我们将在下一章介绍与“交叉编译”相关的设置。不过现在让我们看看使用这个插件的效果。我在我的requirements.txt中添加了numpy。这就是我的 handler.py 文件的样子 -
import time
import numpy
def hello(event, context):
print("second update!")
time.sleep(4)
print(numpy.random.randint(100))
return("hello")
现在让我将其部署到 lambda。您应该会看到类似于下图中的消息。重点关注包装的尺寸。现在它> 14 MB(这是压缩包的大小),而不是添加插件之前的约10 kB,因为numpy依赖项也被捆绑在一起。
这证明依赖项现在与应用程序代码捆绑在一起。您可以使用sls invoke local -f function_name在本地测试它。如果您是 Windows 或 Mac 用户,在 AWS Lambda 控制台上测试部署的 lambda 函数很可能会抛出错误,类似于下面给出的错误 -
Unable to import module 'handler': IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE! Importing the numpy C-extensions failed. This error can happen for many reasons, often due to issues with your setup or how NumPy was installed. We have compiled some common reasons and troubleshooting tips at: https://numpy.org/devdocs/user/troubleshooting-importerror.html Please note and check the following: * The Python version is: Python3.8 from "/var/lang/bin/python3.8" * The NumPy version is: "1.19.4" and make sure that they are the versions you expect. Please carefully study the documentation linked above for further help. Original error was: No module named 'numpy.core._multiarray_umath'
请继续阅读下一章,了解有关发生此错误的原因以及如何处理的更多信息。
无服务器 - 打包依赖项
在上一章中,我们了解了如何在无服务器中使用插件。我们专门研究了 Python 需求插件,并了解了如何使用它来将 numpy、scipy、pandas 等依赖项与 lambda 函数的应用程序代码捆绑在一起。我们甚至看到了部署需要 numpy 依赖项的函数的示例。我们看到它在本地运行良好,但在 AWS Lambda 控制台上,如果您使用的是 Windows 或 Mac 计算机,则会遇到错误。我们来了解一下为什么该函数在本地运行但部署后不运行。
如果您查看错误消息,您会得到一些提示。我特别提到一行 - “导入 numpy C 扩展失败。” 现在,许多重要的Python包如numpy、pandas、scipy等都需要编译C扩展。如果我们在 Windows 或 Mac 机器上编译它们,那么 Lambda(Linux 环境)在尝试加载它们时会抛出错误。所以重要的问题是,可以采取什么措施来避免这个错误。进来码头工人!
什么是码头工人?
根据维基百科的说法,docker 是一组平台即服务(PaaS)产品,它使用操作系统级虚拟化来交付称为容器的软件包中的软件。如果你再仔细浏览一下 docker 的维基百科页面,你会发现一些更相关的说法:Docker 可以将应用程序及其依赖项打包在一个可以在任何 Linux、Windows 或 macOS 计算机上运行的虚拟容器中。这使得应用程序能够在各种位置运行,例如本地、公共云和/或私有云。我想经过以上的阐述应该就很清楚了。我们出现错误,因为在 Windows/Mac 上编译的 C 扩展在 Linux 中不起作用。
我们可以通过将应用程序打包到可以在任何操作系统上运行的容器中来简单地绕过该错误。docker 在后台为实现操作系统级虚拟化所做的工作超出了本章的范围。
安装docker
您可以前往https://docs.docker.com/engine/install/来安装 Docker Desktop。如果您使用的是 Windows 10 家庭版,Windows 版本应至少为 1903(2019 年 5 月更新)。因此,您可能需要在安装 Docker Desktop 之前升级 Windows 10 操作系统。Windows 专业版或企业版没有此类限制。
在无服务器中使用 dockerizePip
在您的计算机上安装 Docker Desktop 后,您只需在 serverless.yml 文件中添加以下内容即可使用 docker 打包您的应用程序和依赖项 -
custom:
pythonRequirements:
dockerizePip: true
请注意,如果您从上一章开始就一直跟着我,那么您可能已经将代码部署到 lambda 一次。这将在您的本地存储中创建一个静态缓存。默认情况下,Serverless 将使用该缓存来捆绑依赖项,因此不会创建 docker 容器。因此,为了强制 Serverless 创建使用 docker,我们将在 pythonRequirements 中添加另一条语句 -
custom:
pythonRequirements:
dockerizePip: true
useStaticCache: false #not necessary if you will be deploying the code to lambda for the first time.
如果您是第一次部署到 lambda,则最后一条语句不是必需的。一般来说,您应该将 useStaticCache 设置为 true,因为当您没有对依赖项或它们必须打包的方式进行任何更改时,这将为您节省一些打包时间。
添加这些内容后,serverless.yml 文件现在看起来像 -
service: hello-world-python
provider:
name: aws
runtime: python3.6
profile: yash-sanghvi
region: ap-south-1
functions:
hello_world:
handler: handler.hello
timeout: 6
memorySize: 128
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
useStaticCache: false #not necessary if you will be deploying the code to lambda for the first time.
现在,当您运行sls deploy -v命令时,请确保 docker 在后台运行。在 Windows 上,您只需在“开始”菜单中搜索 Docker Desktop,然后双击该应用程序即可。您很快就会收到一条消息,表明它正在运行。您还可以通过 Windows 中电池图标附近的小弹出窗口来验证这一点。如果您可以在那里看到 docker 图标,则它正在运行。

现在,当您在 AWS Lambda 控制台上运行函数时,它就可以工作了。恭喜!
但是,在 AWS Lambda 控制台的“函数代码”部分中,您会看到一条消息,显示“您的 Lambda 函数“hello-world-python-dev-hello_world”的部署包太大,无法启用内联代码编辑”。但是,您仍然可以调用您的函数。
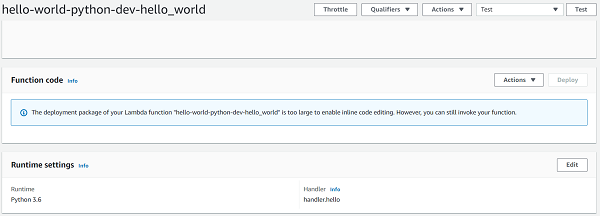
似乎添加 Numpy 依赖项使包大小太大,因此我们甚至无法在 lambda 控制台中编辑应用程序代码。我们如何解决这个问题?请继续阅读下一章来找出答案。
参考
无服务器 - 层创建
什么是层?
层是隔离代码块的一种方式。假设您想在应用程序中导入 NumPy 库。您信任该库,并且几乎没有机会更改该库的源代码。因此,如果 NumPy 的源代码使您的应用程序工作区变得混乱,您将不会喜欢它。非常粗略地说,您只是希望 NumPy 位于其他位置,与您的应用程序代码隔离。图层可以让你做到这一点。您可以简单地将所有依赖项(NumPy、Pandas、SciPy 等)捆绑在一个单独的层中,然后在无服务器中的 lambda 函数中简单地引用该层。繁荣!该层中捆绑的所有库现在都可以导入到您的应用程序中。同时,您的应用程序工作区仍然完全整洁。您只需查看要编辑的应用程序代码即可。

照片由Iva Rajovic在Unsplash上拍摄,表明代码分层分离
层的真正酷之处在于它们可以跨函数共享。假设您部署了一个带有包含 NumPy 和 Pandas 的 python 需求层的 lambda 函数。现在,如果另一个 lambda 函数需要 NumPy,则无需为此函数部署单独的层。您可以简单地使用先前功能的图层,它也可以与新功能很好地配合。
这将为您在部署过程中节省大量宝贵的时间。毕竟,您将仅部署应用程序代码。依赖关系已存在于现有层中。因此,一些开发人员将依赖项层保留在单独的堆栈中。然后他们在所有其他应用程序中使用该层。这样,他们就不需要一次又一次地部署依赖项。毕竟依赖性相当重。NumPy 库本身大约是。80 MB 大。每次更改应用程序代码(可能只有几KB)时都部署依赖项将非常不方便。
添加依赖项层只是一个示例。还有其他几个用例。例如, serverless.com上给出的示例涉及使用 FFmpeg 工具创建 GIF。在该示例中,他们将 FFmpeg 工具存储在一个层中。总之,AWS Lambda 允许我们为每个函数添加最多 5 层。唯一的条件是 5 层和应用程序的总大小应小于 250 MB。
创建 python 需求层
现在让我们看看如何使用无服务器创建和部署包含所有依赖项的层。为此,我们需要serverless-python-requirements插件。该插件仅适用于 Serverless 1.34 及更高版本。因此,如果您的版本 <1.34,您可能需要升级您的无服务器版本。您可以使用安装插件 -
sls plugin install -n serverless-python-requirements
接下来,您在 serverless.yml 的插件部分中添加此插件,并在自定义部分中提及它的配置 -
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
layer: true
在这里,dockerizePip - true启用 docker 的使用,并允许您将所有依赖项打包到 docker 容器中。我们在前面的章节中讨论了使用 docker 进行打包。Layer - true告诉 Serverless Python 需求应该存储在单独的层中。现在,您可能想知道 Serverless 如何理解要打包哪些依赖项?正如插件章节中提到的,答案位于requirements.txt 文件中。
定义层插件和自定义配置后,您可以将层添加到无服务器中的各个功能中,如下所示 -
functions:
hello:
handler: handler.hello
layers:
- { Ref: PythonRequirementsLambdaLayer }
关键字PythonRequirementsLambdaLayer来自CloudFormation Reference。通常,它源自层的名称。语法为“LayerNameLambdaLayer”(标题大小写,不含空格)。在我们的例子中,由于层名称是 pythonrequirements,因此引用变为PythonRequirementsLambdaLayer。如果您不确定 lambda 层的名称,可以通过以下步骤获取它 -
运行sls 包
打开 .serverless/cloudformation-template-update-stack.json
搜索“LambdaLayer”
使用同一区域中另一个函数的现有图层
正如我在开头提到的,关于层的一个非常酷的事情是能够在函数中使用现有的层。这可以通过使用现有层的 ARN 轻松完成。使用 ARN 将现有层添加到函数的语法非常简单 -
functions:
hello:
handler: handler.hello
layers:
- arn:aws:lambda:region:XXXXXX:layer:LayerName:Y
就是这样。现在,具有指定 ARN 的层将与您的函数配合使用。如果该层包含 NumPy 库,您只需在“hello”函数中调用import numpy即可。它将运行而不会出现任何错误。
如果您想知道从哪里可以获得 ARN,实际上很简单。只需导航到 AWS 控制台中包含该层的函数,然后单击“层”。
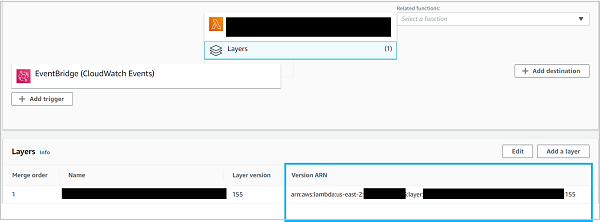
当然,如果该图层不属于您的帐户,则需要公开共享或专门与您的帐户共享。稍后会详细介绍。
另外,请记住该层应该与您的应用程序兼容。不要期望与 node.js 运行时兼容的层与 python3.6 运行时中创建的函数一起运行。
非要求/通用层
正如一开始提到的,这些层的主要功能是隔离代码块。因此,它们不需要只包含依赖项。它们可以包含您指定的任何代码段。在自定义中的pythonRequirements中调用layer: true是通过serverless-python-requirements插件实现的一种快捷方式。但是,要创建通用层,serverless.yml 中的语法(如serverless 文档中所述)如下 -
layers:
hello:
path: layer-dir # required, path to layer contents on disk
name: ${opt:stage, self:provider.stage, 'dev'}-layerName # optional, Deployed Lambda layer name
description: Description of what the lambda layer does # optional, Description to publish to AWS
compatibleRuntimes: # optional, a list of runtimes this layer is compatible with
- python3.8
licenseInfo: GPLv3 # optional, a string specifying license information
# allowedAccounts: # optional, a list of AWS account IDs allowed to access this layer.
# - '*'
# note: uncommenting this will give all AWS users access to this layer unconditionally.
retain: false # optional, false by default. If true, layer versions are not deleted as new ones are created
由于提供了注释,各种配置参数都是不言自明的。除了“路径”之外,所有其他属性都是可选的。path 属性是您选择的目录的路径,您希望将其与应用程序代码隔离。它将被压缩并发布为您的图层。例如,在serverless 的示例项目中,他们在层中托管 FFmpeg 工具,他们将该工具下载到名为“layer”的单独文件夹中,并在路径属性中指定该文件夹。
layers:
ffmpeg:
path: layer
如前所述,我们可以在Layers - 属性中添加最多 5 层。
要在函数中使用这些通用层,您可以使用 CloudFormation 参考或指定 ARN。
允许其他帐户访问图层
只需在“allowedAccounts”属性中提及帐号,即可向更多帐户提供对您的图层的访问权限。例如 -
layers:
testLayer:
path: testLayer
allowedAccounts:
- 999999999999 # a specific account ID
- 000123456789 # a different specific account ID
如果您希望该层可公开访问,您可以在 allowedAccounts 中添加“*” -
layers:
testLayer:
path: testLayer
allowedAccounts:
- '*'