数据科学 - 生命周期
什么是数据科学生命周期?
数据科学生命周期是一种寻找数据问题解决方案的系统方法,它显示了开发、交付/部署和维护数据科学项目所采取的步骤。我们可以假设一个通用的数据科学生命周期,其中包含一些最重要的常见步骤,如下图所示,但有些步骤可能因项目而异,因为每个项目都不同,因此生命周期可能会有所不同,因为并非每个数据科学项目都是以同样的方式建造
标准数据科学生命周期方法包括使用机器学习算法和统计程序,从而产生更准确的预测模型。数据提取、准备、清理、建模、评估等是数据科学最重要的阶段。该技术在数据科学领域被称为“数据挖掘的跨行业标准程序”。
数据科学生命周期有几个阶段?
数据科学生命周期主要有六个阶段 -
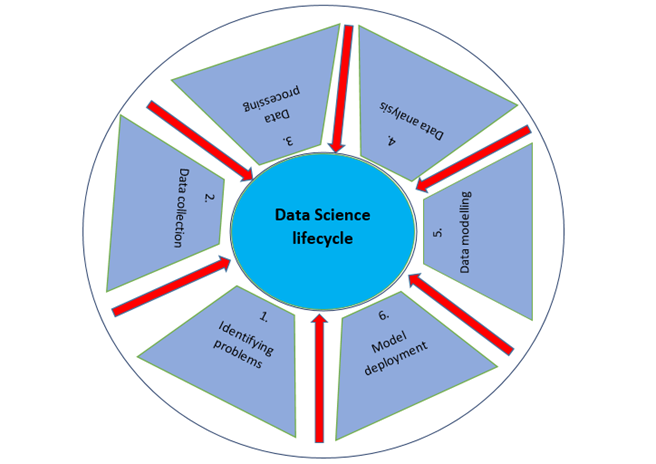
识别问题并了解业务
数据科学生命周期始于“为什么?” 就像任何其他业务生命周期一样。数据科学过程中最重要的部分之一是找出问题所在。这有助于找到一个明确的目标,围绕该目标可以规划所有其他步骤。简而言之,尽早了解业务目标很重要,因为它将决定分析的最终目标是什么。
此阶段应评估业务趋势,评估可比分析的案例研究,并研究行业领域。该小组将根据可用的员工、设备、时间和技术评估该项目的可行性。当发现并评估这些因素时,将制定初步假设来解决现有环境所产生的业务问题。这句话应该 -
明确问题为何必须立即解决并要求答复。
指定业务项目的潜在价值。
识别与项目相关的危险,包括道德问题。
创建并传达灵活、高度集成的项目计划。
数据采集
数据科学生命周期的下一步是数据收集,这意味着从适当且可靠的来源获取原始数据。收集的数据可以是有组织的,也可以是无组织的。数据可以从网站日志、社交媒体数据、在线数据存储库,甚至使用 API、网络抓取从在线源流式传输的数据或 Excel 或任何其他来源的数据中收集。
从事这项工作的人员应该了解可用的不同数据集之间的区别以及组织如何投资其数据。专业人士发现很难跟踪每条数据的来源以及它是否是最新的。在数据科学项目的整个生命周期中,跟踪这些信息非常重要,因为它可以帮助测试假设或运行任何其他新实验。
这些信息可以通过调查或更流行的自动数据收集方法来收集,例如互联网 cookie,它是未经分析的数据的主要来源。
我们还可以使用辅助数据,即开源数据集。例如,我们可以从许多可用网站收集数据
python 中提供了一些预定义的数据集。让我们从 python 导入 Iris 数据集并使用它来定义数据科学的阶段。
from sklearn.datasets import load_iris import pandas as pd # Load Data iris = load_iris() # Create a dataframe df = pd.DataFrame(iris.data, columns = iris.feature_names) df['target'] = iris.target X = iris.data
数据处理
从可靠来源收集高质量数据后,下一步就是对其进行处理。数据处理的目的是确保获取的数据是否存在问题,以便能够在进入下一阶段之前解决问题。如果没有这一步,我们可能会产生错误或不准确的发现。
所获得的数据可能存在一些困难。例如,数据可能在多行或多列中存在多个缺失值。它可能包括多个异常值、不准确的数字、不同时区的时间戳等。数据可能存在日期范围问题。在某些国家/地区,日期格式为 DD/MM/YYYY,而在其他国家/地区,日期格式为 MM/DD/YYYY。在数据收集过程中可能会出现许多问题,例如,如果从许多温度计收集数据并且其中任何一个有缺陷,则可能需要丢弃或重新收集数据。
在此阶段,必须解决与数据有关的各种问题。其中一些问题有多种解决方案,例如,如果数据包含缺失值,我们可以用零或列的平均值替换它们。但是,如果该列缺少大量值,则最好完全删除该列,因为它的数据太少,无法在我们的数据科学生命周期方法中使用它来解决问题。
当时区全部混合时,我们无法利用这些列中的数据,并且可能必须删除它们,直到我们可以定义提供的时间戳中使用的时区。如果我们知道收集每个时间戳的时区,我们可以将所有时间戳数据转换为某个时区。通过这种方式,有多种策略可以解决所获取的数据中可能存在的问题。
我们将访问数据,然后使用 python 将其存储在数据框中。
from sklearn.datasets import load_iris import pandas as pd import numpy as np # Load Data iris = load_iris() # Create a dataframe df = pd.DataFrame(iris.data, columns = iris.feature_names) df['target'] = iris.target X = iris.data
对于机器学习模型,所有数据都必须采用数字表示形式。这意味着如果数据集包含分类数据,则必须先将其转换为数值,然后才能执行模型。所以我们将实现标签编码。
标签编码
species = []
for i in range(len(df['target'])):
if df['target'][i] == 0:
species.append("setosa")
elif df['target'][i] == 1:
species.append('versicolor')
else:
species.append('virginica')
df['species'] = species
labels = np.asarray(df.species)
df.sample(10)
labels = np.asarray(df.species)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(labels)
labels = le.transform(labels)
df_selected1 = df.drop(['sepal length (cm)', 'sepal width (cm)', "species"], axis=1)
数据分析
数据分析 探索性数据分析(EDA)是一套用于分析数据的可视化技术。通过这种方法,我们可以得到具体的详细数据的统计汇总。此外,我们将能够处理重复的数字、异常值,并识别集合中的趋势或模式。
在此阶段,我们尝试更好地了解获取和处理的数据。我们应用统计和分析技术来得出有关数据的结论,并确定数据集中多个列之间的链接。使用图片、图表、图表、绘图等,我们可以使用可视化来更好地理解和描述数据。
专业人员使用平均值和中位数等数据统计技术来更好地理解数据。他们还使用直方图、频谱分析和总体分布来可视化数据并评估其分布模式。将根据问题对数据进行分析。
例子
下面的代码用于检查数据集中是否有空值 -
df.isnull().sum()
输出
sepal length (cm) 0 sepal width (cm) 0 petal length (cm) 0 petal width (cm) 0 target 0 species 0 dtype: int64
从上面的输出我们可以得出结论,数据集中不存在空值,因为列中所有空值的总和为 0。
我们将使用形状参数来检查数据集的形状(行、列) -
例子
df.shape
输出
(150, 5)
现在我们将使用 info() 检查列及其数据类型 -
例子
df.info()
输出
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal length (cm) 150 non-null float64 1 sepal width (cm) 150 non-null float64 2 petal length (cm) 150 non-null float64 3 petal width (cm) 150 non-null float64 4 target 150 non-null int64 dtypes: float64(4), int64(1) memory usage: 6.0 KB
只有一列包含类别数据,而其他列包含非空数值。
现在我们将对数据使用describe()。describe() 方法对数据集执行基本统计计算,例如极值、数据点数量、标准差等。任何缺失值或 NaN 值都会立即被忽略。describe()方法准确地描述了数据的分布。
例子
df.describe()
输出

数据可视化
目标列- 我们的目标列将是“物种”列,因为我们最终只希望基于物种的结果。
Matplotlib 和seaborn 库将用于数据可视化。
以下是物种计数图 -
例子
import seaborn as sns import matplotlib.pyplot as plt sns.countplot(x='species', data=df, ) plt.show()
输出

数据科学中还有许多其他可视化图。要了解有关它们的更多信息,请参阅https://www.tutorialspoint.com/machine_learning_with_python
数据建模
数据建模是数据科学最重要的方面之一,有时被称为数据分析的核心。模型的预期输出应来自准备和分析的数据。在达到指定标准之前,将选择并构建执行数据模型所需的环境。
在此阶段,我们开发用于训练和测试生产相关任务模型的数据集。它还涉及选择正确的模式类型并确定问题是否涉及分类、回归或聚类。分析完模型类型后,我们必须选择合适的实现算法。必须谨慎执行,因为从提供的数据中提取相关见解至关重要。
这里机器学习就出现了。机器学习基本上分为分类、回归或聚类模型,每种模型都有一些应用于数据集以获得相关信息的算法。这些模型在此阶段使用。我们将在机器学习章节中详细讨论这些模型。
模型部署
我们已经到达数据科学生命周期的最后阶段。经过详细的审查过程后,该模型最终准备好以所需的格式和选择的渠道进行部署。请注意,机器学习模型除非部署在生产中,否则没有任何用处。一般来说,这些模型与产品和应用相关联并集成。
模型部署包含建立将模型部署到市场消费者或另一个系统所需的交付方法。机器学习模型也正在设备上实施并获得认可和吸引力。根据项目的复杂性,此阶段的范围可能从 Tableau 仪表板上的基本模型输出到具有数百万用户的复杂的基于云的部署。
谁都参与了数据科学生命周期?
从个人层面到组织层面,数据正在生成、收集并存储在大量服务器和数据仓库中。但是您将如何访问这个庞大的数据存储库呢?这就是数据科学家的用武之地,因为他或她是从非结构化文本和统计数据中提取见解和模式的专家。
下面,我们介绍了参与数据科学生命周期的数据科学团队的许多工作概况。
| 序列号 | 职位简介和角色 |
|---|---|
| 1 | 业务分析师
了解业务需求并找到合适的目标客户。 |
| 2 | 数据分析师
格式化和清理原始数据,解释和可视化它们以执行分析并提供相同的技术摘要 |
| 3 | 数据科学家
提高机器学习模型的质量。 |
| 4 | 数据工程师
他们负责从社交网络、网站、博客和其他内部和外部网络来源收集数据,以备进一步分析。 |
| 5 | 数据架构师
连接、集中、保护和跟上组织的数据源。 |
| 6 | 机器学习工程师
设计和实现机器学习相关的算法和应用程序。 |