Q 语言 - 磁盘上的表
硬盘上的数据(也称为历史数据库)可以以三种不同的格式保存 - 平面文件、展开表和分区表。这里我们将学习如何使用这三种格式来保存数据。
平面文件
平面文件完全加载到内存中,这就是它们的大小(内存占用)应该很小的原因。表完全保存在磁盘上的一个文件中(因此大小很重要)。
用于操作这些表的函数是设置/获取-
`:path_to_file/filename set tablename
让我们举一个例子来演示它是如何工作的 -
q)tables `. `s#`t`tab`tab1 q)`:c:/q/w32/tab1_test set tab1 `:c:/q/w32/tab1_test
在 Windows 环境中,平面文件保存在以下位置 - C:\q\w32
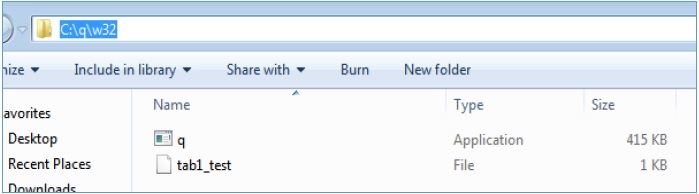
从磁盘(历史数据库)获取平面文件并使用get命令,如下所示 -
q)tab2: get `:c:/q/w32/tab1_test q)tab2 sym | time price size --------- | ------------------------------- APPLE | 11:16:39.779 8.388858 12 MSFT | 11:16:39.779 19.59907 10 IBM | 11:16:39.779 37.5638 1 SAMSUNG | 11:16:39.779 61.37452 90 APPLE | 11:16:39.779 52.94808 73
创建一个新表tab2,其内容存储在tab1_test文件中。
八字桌
如果表中的列太多,那么我们以展开格式存储这些表,即将它们保存在磁盘上的一个目录中。在目录内,每列都保存在与列名称相同的名称的单独文件中。每列都保存为 kdb+ 二进制文件中相应类型的列表。
当我们必须经常访问表的众多列中的少数列时,以展开格式保存表非常有用。展开的表目录包含.d二进制文件,其中包含列的顺序。
与平面文件非常相似,可以使用set命令将表格另存为展开形式。要将表格保存为展开状态,文件路径应以反冲结尾 -
`:path_to_filename/filename/ set tablename
为了读取展开的表格,我们可以使用get函数 -
tablename: get `:path_to_file/filename
注意- 对于要保存为展开的表,应该取消键控并枚举它。
在 Windows 环境中,您的文件结构将如下所示 -
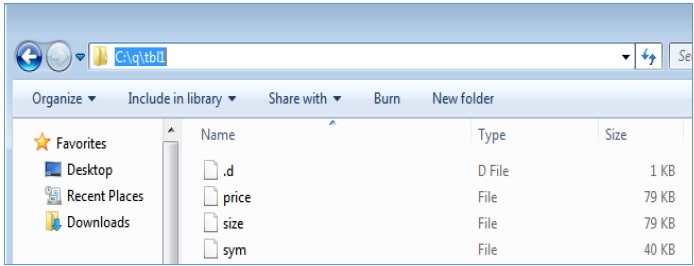
分区表
分区表提供了一种有效的方法来管理包含大量数据的大型表。分区表是分布在更多分区(目录)上的展开表。
在每个分区内,表将有自己的目录,具有展开表的结构。这些表格可以按日/月/年进行拆分,以便提供对其内容的优化访问。
要获取分区表的内容,请使用以下代码块 -
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0…. trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ….
让我们尝试获取交易表的内容 -
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 A
注意- 分区模式适用于每天有数百万条记录的表(即时间序列数据)
符号文件
sym 文件是一个 kdb+ 二进制文件,包含所有展开和分区表中的符号列表。可以用它来阅读,
get `:sym
par.txt 文件(可选)
这是一个配置文件,当分区分布在多个目录/磁盘驱动器上时使用,并包含磁盘分区的路径。