Python 中的逻辑回归 - 获取数据
本章详细讨论了获取数据以在 Python 中执行逻辑回归所涉及的步骤。
下载数据集
如果您尚未下载前面提到的 UCI 数据集,请立即从此处下载。单击数据文件夹。您将看到以下屏幕 -

单击给定的链接下载bank.zip 文件。zip 文件包含以下文件 -

我们将使用bank.csv 文件进行模型开发。Bank-names.txt 文件包含您稍后需要的数据库的描述。bank-full.csv 包含一个更大的数据集,您可以将其用于更高级的开发。
这里,我们已将bank.csv 文件包含在可下载的源zip 中。该文件包含逗号分隔的字段。我们还对该文件进行了一些修改。建议您使用项目源 zip 中包含的文件进行学习。
加载数据中
要从刚刚复制的 csv 文件加载数据,请键入以下语句并运行代码。
In [2]: df = pd.read_csv('bank.csv', header=0)
您还可以通过运行以下代码语句来检查加载的数据 -
IN [3]: df.head()
运行命令后,您将看到以下输出 -
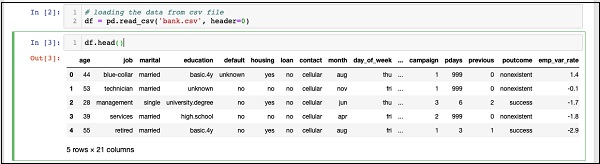
基本上,它已经打印了加载数据的前五行。检查存在的 21 列。我们将仅使用其中的几列来进行模型开发。
接下来,我们需要清理数据。数据可能包含一些带有NaN的行。要消除此类行,请使用以下命令 -
IN [4]: df = df.dropna()
幸运的是,bank.csv 不包含任何带有 NaN 的行,因此在我们的示例中并不真正需要此步骤。然而,一般来说,在巨大的数据库中很难发现这样的行。因此,运行上述语句来清理数据总是更安全。
注意- 您可以使用以下语句轻松检查任意时间点的数据大小 -
IN [5]: print (df.shape) (41188, 21)
行数和列数将打印在输出中,如上面第二行所示。
接下来要做的事情是检查每一列对于我们正在尝试构建的模型的适用性。