- Peewee教程
- Peewee - 主页
- Peewee - 概述
- Peewee - 数据库类
- Peewee - 模型
- Peewee - 野外课程
- Peewee - 插入新记录
- Peewee - 选择记录
- Peewee - 过滤器
- Peewee - 主键和复合键
- Peewee - 更新现有记录
- Peewee - 删除记录
- Peewee - 创建索引
- Peewee - 约束
- Peewee - 使用 MySQL
- Peewee - 使用 PostgreSQL
- Peewee - 动态定义数据库
- Peewee - 连接管理
- Peewee - 关系与加入
- Peewee - 子查询
- Peewee - 排序
- Peewee - 计数和聚合
- Peewee - SQL 函数
- Peewee - 检索行元组/字典
- Peewee - 用户定义的运算符
- Peewee - 原子事务
- Peewee - 数据库错误
- Peewee - 查询生成器
- Peewee - 与 Web 框架集成
- Peewee - SQLite 扩展
- Peewee - PostgreSQL 和 MySQL 扩展
- Peewee - 使用 CockroachDB
- Peewee有用资源
- Peewee - 快速指南
- Peewee - 有用的资源
- Peewee - 讨论
Peewee - 快速指南
Peewee - 概述
Peewee是一个Python对象关系映射(ORM)库,由美国软件工程师Charles Leifer于2010年10月开发,最新版本为3.13.3。Peewee 支持 SQLite、MySQL、PostgreSQL 和 Cockroach 数据库。
对象关系映射是一种编程技术,用于在面向对象编程语言中的不兼容类型系统之间转换数据。
在面向对象 (OO) 编程语言(例如 Python)中定义的类被视为非标量。它不能表示为原始类型,例如整数和字符串。
另一方面,Oracle、MySQL、SQLite 等数据库只能存储和操作标量值,例如表中组织的整数和字符串。
程序员必须将对象值转换为标量数据类型组以便存储在数据库中或在检索时将它们转换回来,或者仅在程序中使用简单的标量值。
在 ORM 系统中,每个类都映射到底层数据库中的一个表。ORM可以解决这些问题,而您无需自己编写繁琐的数据库接口代码,而您可以专注于对系统逻辑进行编程。
环境设置
要安装 PyPI(Python 包索引)上托管的最新版本的 Peewee,请使用 pip 安装程序。
pip3 install peewee
Peewee 的工作没有其他依赖项。它可以与 SQLite 一起使用,无需安装任何其他包,因为 sqlite3 模块与标准库捆绑在一起。
但是,要使用 MySQL 和 PostgreSQL,您可能必须分别安装 DB-API 兼容的驱动程序模块 pymysql 和 pyscopg2。Cockroach 数据库通过 Playhouse 扩展进行处理,该扩展默认与 Peewee 一起安装。
Peewee 是一个托管在https://github.com/coleifer/peewee存储库上的开源项目。因此,可以使用 git 从此处安装它。
git clone https://github.com/coleifer/peewee.git cd peewee python setup.py install
Peewee - 数据库类
Peewee 包中的 Database 类的对象表示与数据库的连接。Peewee 通过 Database 类的相应子类为 SQLite、PostgreSQL 和 MySQL 数据库提供开箱即用的支持。
数据库类实例拥有与数据库引擎打开连接所需的所有信息,用于执行查询、管理事务以及执行表、列等的内省。
Database 类有SqliteDatabase、PostgresqlDatabase和MySQLDatabase子类。虽然 SQLite 的 DB-API 驱动程序以 sqlite3 模块的形式包含在 Python 的标准库中,但必须首先安装psycopg2和pymysql模块才能在 Peewee 中使用 PostgreSql 和 MySQL 数据库。
使用Sqlite数据库
Python 以 sqlite3 模块的形式内置了对 SQLite 数据库的支持。因此,连接非常容易。Peewee中SqliteDatabase类的对象代表连接对象。
con=SqliteDatabase(name, pragmas, timeout)
这里,pragma是SQLite扩展,用于修改SQLite库的操作。此参数可以是字典或二元组列表,其中包含每次打开连接时要设置的 pragma 键和值。
Timeout 参数以秒为单位指定,用于设置 SQLite 驱动程序的繁忙超时。这两个参数都是可选的。
以下语句创建与新 SQLite 数据库的连接(如果该数据库尚不存在)。
>>> db = peewee.SqliteDatabase('mydatabase.db')
通常为新的数据库连接提供杂注参数。pragmase 字典中提到的典型属性有journal_mode、cache_size、locking_mode、foreign-keys等。
>>> db = peewee.SqliteDatabase(
'test.db', pragmas={'journal_mode': 'wal', 'cache_size': 10000,'foreign_keys': 1}
)
以下编译指示设置是理想的指定方式 -
| 附注属性 | 推荐值 | 意义 |
|---|---|---|
| 日志模式 | 沃尔 | 让读者和作者共存 |
| 缓存大小 | -1 * 数据大小_kb | 设置页面缓存大小(以 KiB 为单位) |
| 外键 | 1 | 强制执行外键约束 |
| 忽略检查约束 | 0 | 强制执行 CHECK 约束 |
| 同步 | 0 | 让操作系统处理 fsync |
Peewee 还有 Another Python SQLite Wrapper (apsw),一个高级 sqlite 驱动程序。它提供了虚拟表和文件系统以及共享连接等高级功能。APSW 比标准库 sqlite3 模块更快。
Peewee - 模型
Peewee API中Model子类的一个对象对应数据库中已建立连接的一张表。它允许借助 Model 类中定义的方法执行数据库表操作。
一个用户定义的Model有一个或多个类属性,每个属性都是Field类的一个对象。Peewee 有许多子类用于保存不同类型的数据。例子有TextField、DatetimeField等。它们对应于数据库表中的字段或列。Meta类中提到了关联的数据库和表以及模型配置的参考。以下属性用于指定配置 -
元类属性
元类属性解释如下 -
| 先生编号 | 属性及描述 |
|---|---|
| 1 | 数据库 模型数据库。 |
| 2 | 数据库表 存储数据的表的名称。默认情况下,它是模型类的名称。 |
| 3 | 索引 要索引的字段列表。 |
| 4 | 首要的关键 复合键实例。 |
| 5 | 约束条件 表约束的列表。 |
| 6 | 模式 模型的数据库架构。 |
| 7 | 暂时的 表示临时表。 |
| 8 | 依赖于取决于 指示该表依赖于另一个表的创建。 |
| 9 | 没有_rowid 指示表不应有 rowid(仅限 SQLite)。 |
以下代码定义 mydatabase.db 中用户表的模型类 -
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
User.create_table()
create_table ()方法是 Model 类的类方法,它执行等效的 CREATE TABLE 查询。另一个实例方法save()添加与对象对应的行。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
User.create_table()
rec1=User(name="Rajesh", age=21)
rec1.save()
模型类中的方法
Model 类中的其他方法如下 -
| 先生编号 | 型号类别及描述 |
|---|---|
| 1 | 类方法别名() 创建模型类的别名。它允许同一模型在查询中多次引用。 |
| 2 | 类方法 select() 执行 SELECT 查询操作。如果没有显式提供字段作为参数,则查询默认情况下将使用 SELECT * 等效项。 |
| 3 | 类方法 update() 执行 UPDATE 查询功能。 |
| 4 | 类方法insert() 在映射到模型的基础表中插入新行。 |
| 5 | 类方法delete() 执行删除查询,通常与筛选器 by where 子句相关联。 |
| 6 | 类方法 get() 从映射表中检索与给定过滤器匹配的单行。 |
| 7 | 获取id() 实例方法返回行的主键。 |
| 8 | 节省() 将对象的数据保存为新行。如果主键值已经存在,则会导致执行 UPDATE 查询。 |
| 9 | 类方法bind() 将模型绑定到给定的数据库。 |
Peewee - 野外课程
Model 类包含一个或多个属性,这些属性是 Peewee 中 Field 类的对象。基字段类不是直接实例化的。Peewee 为等效的 SQL 数据类型定义了不同的子类。
Field 类的构造函数具有以下参数 -
| 先生编号 | 构造函数及描述 |
|---|---|
| 1 | 列名(字符串) 指定字段的列名称。 |
| 2 | 主键(布尔值) 字段是主键。 |
| 3 | 约束(列表) 应用于列的约束列表 |
| 4 | 选择(列表) 映射列值以显示标签的二元组的迭代。 |
| 5 | 空(布尔值) 字段允许 NULL。 |
| 6 | 索引(布尔值) 在字段上创建索引。 |
| 7 | 唯一(布尔) 在字段上创建唯一索引。 |
| 8 | 默认 默认值。 |
| 9 | 排序规则(str) 字段的排序规则名称。 |
| 10 | 帮助文本 (str) 用于字段、元数据目的的帮助文本。 |
| 11 | 详细名称 (str) 用于字段、元数据目的的详细名称。 |
Field类的子类映射到各种数据库中相应的数据类型,即SQLite、PostgreSQL、MySQL等。
数值字段类
Peewee 中的数字字段类如下 -
| 先生编号 | 字段类别和描述 |
|---|---|
| 1 | 整数字段 用于存储整数的字段类。 |
| 2 | 大整数字段 用于存储大整数的字段类(分别映射到 SQLite、PostegreSQL 和 MySQL 中的 integer、bigint 和 bigint 类型)。 |
| 3 | 小整数字段 用于存储小整数的字段类(如果数据库支持)。 |
| 4 | 浮点字段 用于存储浮点数的字段类对应于实际数据类型。 |
| 5 | 双场 用于存储双精度浮点数的字段类映射到相应 SQL 数据库中的等效数据类型。 |
| 6 | 小数字段 用于存储十进制数字的字段类。参数如下 -
|
文本字段
Peewee 中可用的文本字段如下 -
| 先生编号 | 字段和描述 |
|---|---|
| 1 | 查菲尔德 用于存储字符串的字段类。最多 255 个字符。等效的 SQL 数据类型是 varchar。 |
| 2 | 固定字符字段 用于存储固定长度字符串的字段类。 |
| 3 | 文本域 用于存储文本的字段类。映射到 SQLite 和 PostgreSQL 中的 TEXT 数据类型以及 MySQL 中的长文本。 |
二进制字段
Peewee 中的二进制字段解释如下 -
| 先生编号 | 字段和描述 |
|---|---|
| 1 | 斑点字段 用于存储二进制数据的字段类。 |
| 2 | 位域 用于在 64 位整数列中存储选项的字段类。 |
| 3 | 大位字段 用于在二进制大对象 (BLOB) 中存储任意大位图的字段类。该字段将根据需要增加底层缓冲区。 |
| 4 | UUID字段 用于存储通用唯一标识符 (UUID) 对象的字段类。映射到 Postgres 中的 UUID 类型。SQLite 和 MySQL 没有 UUID 类型,它存储为 VARCHAR。 |
日期和时间字段
Peewee 中的日期和时间字段如下 -
| 先生编号 | 字段和描述 |
|---|---|
| 1 | 日期时间字段 用于存储 datetime.datetime 对象的字段类。接受特殊的参数字符串格式,可以使用该格式对日期时间进行编码。 |
| 2 | 日期字段 用于存储 datetime.date 对象的字段类。接受特殊的参数字符串格式来编码日期。 |
| 3 | 时间场 用于存储 datetime.time 对象的字段类接受特殊的参数格式以显示编码时间。 |
由于 SQLite 没有 DateTime 数据类型,因此该字段被映射为字符串。
外键字段
此类用于在两个模型中建立外键关系,从而在数据库中的相应表中建立外键关系。此类使用以下参数实例化 -
| 先生编号 | 字段和描述 |
|---|---|
| 1 | 型号(模型) 型号可供参考。如果设置为“self”,则它是自引用外键。 |
| 2 | 场(场) 模型上引用的字段(默认为主键)。 |
| 3 | 反向引用 (str) 用于反向引用的访问器名称。“+”禁用反向引用访问器。 |
| 4 | on_delete (str) 关于删除操作。 |
| 5 | on_update(str) 更新操作。 |
| 6 | 惰性加载(布尔值) 当访问外键字段属性时,获取相关对象。如果为 FALSE,访问外键字段将返回存储在外键列中的值。 |
例子
这是ForeignKeyField 的示例。
from peewee import *
db = SqliteDatabase('mydatabase.db')
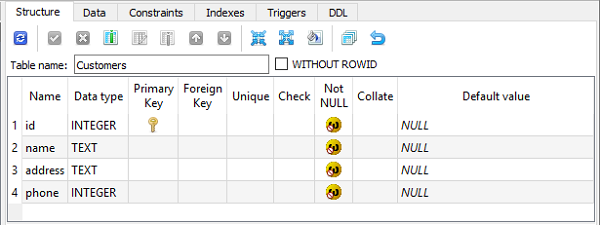
class Customer(Model):
id=IntegerField(primary_key=True)
name = TextField()
address = TextField()
phone = IntegerField()
class Meta:
database=db
db_table='Customers'
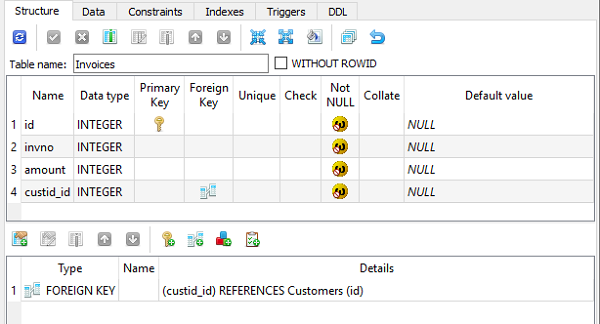
class Invoice(Model):
id=IntegerField(primary_key=True)
invno=IntegerField()
amount=IntegerField()
custid=ForeignKeyField(Customer, backref='Invoices')
class Meta:
database=db
db_table='Invoices'
db.create_tables([Customer, Invoice])
执行上述脚本时,将运行以下 SQL 查询 -
CREATE TABLE Customers (
id INTEGER NOT NULL
PRIMARY KEY,
name TEXT NOT NULL,
address TEXT NOT NULL,
phone INTEGER NOT NULL
);
CREATE TABLE Invoices (
id INTEGER NOT NULL
PRIMARY KEY,
invno INTEGER NOT NULL,
amount INTEGER NOT NULL,
custid_id INTEGER NOT NULL,
FOREIGN KEY (
custid_id
)
REFERENCES Customers (id)
);
在 SQLiteStuidio GUI 工具中验证时,表结构如下所示 -
其他字段类型
Peewee 中的其他字段类型包括 -
| 先生编号 | 字段和描述 |
|---|---|
| 1 | IP字段 用于有效存储 IPv4 地址(作为整数)的字段类。 |
| 2 | 布尔字段 用于存储布尔值的字段类。 |
| 3 | 自动场 用于存储自增主键的字段类。 |
| 4 | 身份字段 用于使用新的 Postgres 10 IDENTITY存储自动递增主键的字段类用于使用新的 Postgres 10 IDENTITY 列类型存储自动递增主键的字段类。列类型。 |
Peewee - 插入新记录
在 Peewee 中,有多个命令可以在表中添加新记录。我们已经使用了 Model 实例的 save() 方法。
rec1=User(name="Rajesh", age=21) rec1.save()
Peewee.Model 类还有一个 create() 方法,用于创建一个新实例并将其数据添加到表中。
User.create(name="Kiran", age=19)
除此之外,Model 还具有insert()作为构造 SQL 插入查询对象的类方法。Query 对象的execute ()方法执行在基础表中添加一行。
q = User.insert(name='Lata', age=20) q.execute()
查询对象是一个等效的 INSERT query.q.sql() 返回查询字符串。
print (q.sql())
('INSERT INTO "User" ("name", "age") VALUES (?, ?)', ['Lata', 20])
这是演示上述插入记录方式的使用的完整代码。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
db.create_tables([User])
rec1=User(name="Rajesh", age=21)
rec1.save()
a=User(name="Amar", age=20)
a.save()
User.create(name="Kiran", age=19)
q = User.insert(name='Lata', age=20)
q.execute()
db.close()
我们可以在 SQLiteStudio GUI 中验证结果。
批量插入
为了一次使用表中的多行,Peewee 提供了两种方法:bulk_create和 insert_many。
insert_many()
insert_many() 方法使用字典对象列表生成等效的 INSERT 查询,每个字典对象都具有一个对象的字段值对。
rows=[{"name":"Rajesh", "age":21}, {"name":"Amar", "age":20}]
q=User.insert_many(rows)
q.execute()
在这里,q.sql() 也返回 INSERT 查询字符串,如下所示 -
print (q.sql())
('INSERT INTO "User" ("name", "age") VALUES (?, ?), (?, ?)', ['Rajesh', 21, 'Amar', 20])
批量创建()
此方法采用一个列表参数,其中包含映射到表的模型的一个或多个未保存的实例。
a=User(name="Kiran", age=19) b=User(name='Lata', age=20) User.bulk_create([a,b])
以下代码使用这两种方法来执行批量插入操作。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
db.create_tables([User])
rows=[{"name":"Rajesh", "age":21}, {"name":"Amar", "age":20}]
q=User.insert_many(rows)
q.execute()
a=User(name="Kiran", age=19)
b=User(name='Lata', age=20)
User.bulk_create([a,b])
db.close()
Peewee - 选择记录
从表中检索数据的最简单、最明显的方法是调用相应模型的select()方法。在 select() 方法中,我们可以指定一个或多个字段属性。但是,如果未指定任何列,则选择所有列。
Model.select() 返回与行对应的模型实例列表。这类似于SELECT查询返回的结果集,可以通过for循环来遍历。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class User (Model):
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
rows=User.select()
print (rows.sql())
for row in rows:
print ("name: {} age: {}".format(row.name, row.age))
db.close()
上面的脚本显示以下输出 -
('SELECT "t1"."id", "t1"."name", "t1"."age" FROM "User" AS "t1"', [])
name: Rajesh age: 21
name: Amar age : 20
name: Kiran age : 19
name: Lata age : 20
Peewee - 过滤器
可以使用 where 子句从 SQLite 表中检索数据。Peewee 支持以下逻辑运算符列表。
| == | x 等于 y |
| < | x 小于 y |
| <= | x 小于或等于 y |
| > | x 大于 y |
| >= | x 大于或等于 y |
| != | x 不等于 y |
| << | x IN y,其中 y 是列表或查询 |
| >> | x IS y,其中 y 为 None/NULL |
| % | x LIKE y 其中 y 可以包含通配符 |
| ** | x ILIKE y 其中 y 可以包含通配符 |
| ^ | x 异或 y |
| 〜 | 一元否定(例如 NOT x) |
以下代码显示年龄 >=20 的姓名:
rows=User.select().where (User.age>=20)
for row in rows:
print ("name: {} age: {}".format(row.name, row.age))
以下代码仅显示名称列表中存在的名称。
names=['Anil', 'Amar', 'Kiran', 'Bala']
rows=User.select().where (User.name << names)
for row in rows:
print ("name: {} age: {}".format(row.name, row.age))
Peewee 生成的 SELECT 查询将是 -
('SELECT "t1"."id", "t1"."name", "t1"."age" FROM "User" AS "t1" WHERE
("t1"."name" IN (?, ?, ?, ?))', ['Anil', 'Amar', 'Kiran', 'Bala'])
结果输出如下 -
name: Amar age: 20 name: Kiran age: 19
过滤方法
除了核心 Python 中定义的上述逻辑运算符之外,Peewee 还提供以下过滤方法 -
| 先生编号 | 方法与说明 |
|---|---|
| 1 | .in_(值) IN 查找(与 << 相同)。 |
| 2 | .not_in(值) 不在查找中。 |
| 3 | .is_null(is_null) IS NULL 或 IS NOT NULL。接受布尔参数。 |
| 4 | .包含(子字符串) 子字符串的通配符搜索。 |
| 5 | .startswith(前缀) 搜索以前缀开头的值。 |
| 6 | .endswith(后缀) 搜索以后缀结尾的值。 |
| 7 | .之间(低,高) 搜索低值和高值之间的值。 |
| 8 | .regexp(exp) 正则表达式匹配(区分大小写)。 |
| 9 | .iregexp(exp) 正则表达式匹配(不区分大小写)。 |
| 10 | .bin_and(值) 二进制与。 |
| 11 | .bin_or(值) 二元或。 |
| 12 | .concat(其他) 使用 || 连接两个字符串或对象。 |
| 13 | 。清楚的() 将列标记为 DISTINCT 选择。 |
| 14 | .整理(整理) 指定具有给定排序规则的列。 |
| 15 | .cast(类型) 将列的值转换为给定类型。 |
作为上述方法的示例,请查看以下代码。它检索以“R”开头或以“r”结尾的名称。
rows=User.select().where (User.name.startswith('R') | User.name.endswith('r'))
等效的 SQL SELECT 查询是:
('SELECT "t1"."id", "t1"."name", "t1"."age" FROM "User" AS "t1" WHERE
(("t1"."name" LIKE ?) OR ("t1"."name" LIKE ?))', ['R%', '%r'])
备择方案
Python 的内置运算符 in、not in、and、or 等将不起作用。相反,请使用 Peewee 替代品。
您可以使用 -
.in_() 和 .not_in() 方法而不是 in 和 not in 运算符。
& 而不是 and。
| 而不是或。
〜而不是不。
.is_null() 而不是 is。
无或 == 无。
Peewee - 主键和复合键
建议关系数据库中的表应具有应用主键约束的列之一。因此,Peewee Model 类还可以指定主键参数设置为 True 的字段属性。然而,如果模型类没有任何主键,Peewee 会自动创建一个名为“id”的主键。请注意,上面定义的用户模型没有任何明确定义为主键的字段。因此,我们数据库中映射的 User 表有一个 id 字段。
要定义自动递增整数主键,请使用AutoField对象作为模型中的一个属性。
class User (Model):
user_id=AutoField()
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
这将转换为以下 CREATE TABLE 查询 -
CREATE TABLE User ( user_id INTEGER NOT NULL PRIMARY KEY, name TEXT NOT NULL, age INTEGER NOT NULL );
您还可以通过将primary_key参数设置为True来将任何非整数字段指定为主键。假设我们想要将某个字母数字值存储为 user_id。
class User (Model):
user_id=TextField(primary_key=True)
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
但是,当模型包含非整数字段作为主键时,模型实例的save()方法不会导致数据库驱动程序自动生成新的 ID,因此我们需要传递force_insert=True参数。但请注意,create()方法隐式指定了force_insert 参数。
User.create(user_id='A001',name="Rajesh", age=21) b=User(user_id='A002',name="Amar", age=20) b.save(force_insert=True)
save() 方法还会更新表中的现有行,此时,force_insert Primary 不是必需的,因为具有唯一主键的 ID 已经存在。
Peewee 允许定义复合主键的功能。CompositeKey类的对象在 Meta 类中定义为主键。在以下示例中,由用户模型的名称和城市字段组成的复合键已被指定为复合键。
class User (Model):
name=TextField()
city=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
primary_key=CompositeKey('name', 'city')
该模型转换为以下 CREATE TABLE 查询。
CREATE TABLE User (
name TEXT NOT NULL,
city TEXT NOT NULL,
age INTEGER NOT NULL,
PRIMARY KEY (
name,
city
)
);
如果您愿意,表不应有主键,然后在模型的 Meta 类中指定primary_key=False。
Peewee - 更新现有记录
可以通过调用模型实例上的save()方法以及update()类方法来修改现有数据。
以下示例借助get()方法从 User 表中获取一行,并通过更改年龄字段的值来更新它。
row=User.get(User.name=="Amar")
print ("name: {} age: {}".format(row.name, row.age))
row.age=25
row.save()
Method 类的 update() 方法生成 UPDATE查询。然后调用查询对象的execute() 方法。
以下示例使用 update() 方法更改年龄列 >20 的行。
qry=User.update({User.age:25}).where(User.age>20)
print (qry.sql())
qry.execute()
update() 方法呈现的 SQL 查询如下 -
('UPDATE "User" SET "age" = ? WHERE ("User"."age" > ?)', [25, 20])
Peewee 还有一个bulk_update()方法来帮助在单个查询操作中更新多个模型实例。该方法需要更新模型对象和更新字段列表。
以下示例用新值更新指定行的年龄字段。
rows=User.select() rows[0].age=25 rows[2].age=23 User.bulk_update([rows[0], rows[2]], fields=[User.age])
Peewee - 删除记录
在模型实例上运行delete_instance()方法从映射表中删除相应的行。
obj=User.get(User.name=="Amar") obj.delete_instance()
另一方面,delete() 是模型类中定义的类方法,它生成 DELETE 查询。执行它会有效地从表中删除行。
db.create_tables([User]) qry=User.delete().where (User.age==25) qry.execute()
数据库中的相关表显示 DELETE 查询的效果如下 -
('DELETE FROM "User" WHERE ("User"."age" = ?)', [25])
Peewee - 创建索引
通过使用 Peewee ORM,可以定义一个模型,该模型将创建一个在单列以及多列上有索引的表。
根据 Field 属性定义,将唯一约束设置为 True 将在映射字段上创建索引。类似地,将index=True参数传递给字段构造函数也会在指定字段上创建索引。
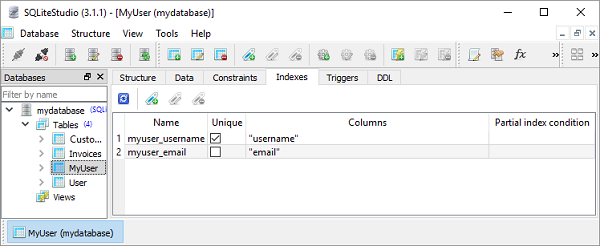
在下面的示例中,我们在 MyUser 模型中有两个字段,其中 username 字段的唯一参数设置为 True ,而 email 字段的index=True。
class MyUser(Model):
username = CharField(unique=True)
email = CharField(index=True)
class Meta:
database=db
db_table='MyUser'
因此,SQLiteStudio 图形用户界面 (GUI) 显示创建的索引,如下所示 -
为了定义多列索引,我们需要在模型类定义内的 Meta 类中添加索引属性。它是一个由 2 项元组组成的元组,一个元组对应一个索引定义。在每个 2 元素元组中,第一部分是字段名称的元组,第二部分设置为 True 以使其唯一,否则为 False。
我们使用两列唯一索引定义 MyUser 模型,如下所示 -
class MyUser (Model):
name=TextField()
city=TextField()
age=IntegerField()
class Meta:
database=db
db_table='MyUser'
indexes=(
(('name', 'city'), True),
)
因此,SQLiteStudio 显示索引定义如下图所示 -
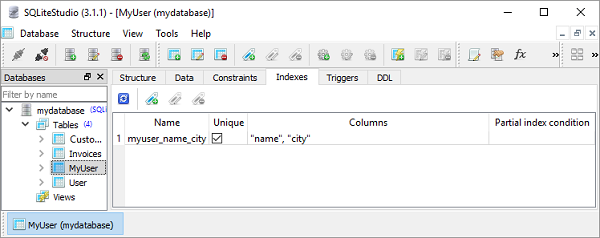
索引也可以在模型定义之外构建。
您还可以通过手动提供 SQL 帮助程序语句作为add_index()方法的参数来创建索引。
MyUser.add_index(SQL('CREATE INDEX idx on MyUser(name);'))
使用SQLite时尤其需要上述方法。对于 MySQL 和 PostgreSQL,我们可以获取 Index 对象并通过add_index()方法使用它。
ind=MyUser.index(MyUser.name) MyUser.add_index(ind)
Peewee - 约束
约束是对可以放入字段中的可能值施加的限制。其中一个约束就是主键。当字段定义中指定primary_key=True时,每行只能存储唯一值——相同的字段值不能在另一行中重复。
如果字段不是主键,仍然可以限制它在表中存储唯一值。字段构造函数也有约束参数。
以下示例对年龄字段应用CHECK约束。
class MyUser (Model):
name=TextField()
city=TextField()
age=IntegerField(constraints=[Check('name<10')])
class Meta:
database=db
db_table='MyUser'
这将生成以下数据定义语言(DDL)表达式 -
CREATE TABLE MyUser ( id INTEGER NOT NULL PRIMARY KEY, name TEXT NOT NULL, city TEXT NOT NULL, age INTEGER NOT NULL CHECK (name < 10) );
因此,如果年龄<10的新行将导致错误。
MyUser.create(name="Rajesh", city="Mumbai",age=9) peewee.IntegrityError: CHECK constraint failed: MyUser
在字段定义中,我们还可以使用DEFAULT约束,如以下城市字段定义所示。
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
因此,可以在有或没有明确的城市值的情况下构建模型对象。如果不使用,城市字段将填充默认值 – 孟买。
Peewee - 使用 MySQL
前面提到,Peewee 通过MySQLDatabase类支持 MySQL 数据库。然而,与 SQLite 数据库不同,Peewee 无法创建MySql数据库。您需要手动创建它或使用 DB-API 兼容模块的功能(例如pymysql )。
首先,您的计算机上应该安装有 MySQL 服务器。它可以是从 https://dev.mysql.com/downloads/installer/ 安装的独立 MySQL 服务器。
您还可以使用与 MySQL 捆绑在一起的 Apache(例如从https://www.apachefriends.org/download.html下载并安装的 XAMPP )。
接下来,我们安装 pymysql 模块、DB-API 兼容的 Python 驱动程序。
pip install pymysql
创建一个名为 mydatabase 的新数据库。我们将使用XAMPP 中提供的phpmyadmin界面。

如果您选择以编程方式创建数据库,请使用以下 Python 脚本 -
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='')
conn.cursor().execute('CREATE DATABASE mydatabase')
conn.close()
在服务器上创建数据库后,我们现在可以声明一个模型,从而在其中创建一个映射表。
MySQLDatabase 对象需要服务器凭据,例如主机、端口、用户名和密码。
from peewee import *
db = MySQLDatabase('mydatabase', host='localhost', port=3306, user='root', password='')
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
class Meta:
database=db
db_table='MyUser'
db.connect()
db.create_tables([MyUser])
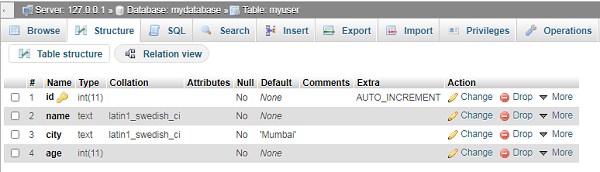
Phpmyadmin Web 界面现在显示已创建的 myuser 表。
Peewee - 使用 PostgreSQL
Peewee 还支持 PostgreSQL 数据库。它有用于此目的的PostgresqlDatabase类。在本章中,我们将了解如何在 Peewee 模型的帮助下连接到 Postgres 数据库并在其中创建表。
与 MySQL 一样,无法使用 Peewee 的功能在 Postgres 服务器上创建数据库。必须使用 Postgres shell 或 PgAdmin 工具手动创建数据库。
首先,我们需要安装 Postgres 服务器。对于Windows操作系统,我们可以下载https://get.enterprisdb.com/postgresql/postgresql-13.1-1-windows-x64.exe并安装。
接下来,使用 pip 安装程序安装 Postgres – Psycopg2包的 Python 驱动程序。
pip install psycopg2
然后从 PgAdmin 工具或 psql shell 启动服务器。我们现在可以创建一个数据库。运行以下 Python 脚本在 Postgres 服务器上创建 mydatabase。
import psycopg2
conn = psycopg2.connect(host='localhost', user='postgres', password='postgres')
conn.cursor().execute('CREATE DATABASE mydatabase')
conn.close()
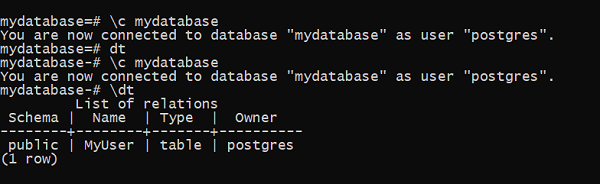
检查数据库是否已创建。在 psql shell 中,可以使用 \l 命令进行验证 -

要声明 MyUser 模型并在上述数据库中创建同名表,请运行以下 Python 代码 -
from peewee import *
db = PostgresqlDatabase('mydatabase', host='localhost', port=5432, user='postgres', password='postgres')
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
class Meta:
database=db
db_table='MyUser'
db.connect()
db.create_tables([MyUser])
我们可以验证表是否已创建。在 shell 内,连接到 mydatabase 并获取其中的表列表。
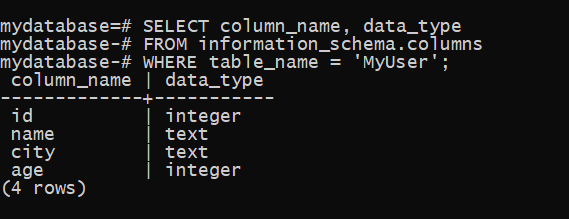
要检查新创建的 MyUser 数据库的结构,请在 shell 中运行以下查询。
Peewee - 动态定义数据库
如果您的数据库计划在运行时发生变化,请使用DatabaseProxy帮助程序更好地控制初始化它的方式。DatabaseProxy 对象是一个占位符,借助它可以在运行时选择数据库。
在以下示例中,根据应用程序的配置设置选择适当的数据库。
from peewee import *
db_proxy = DatabaseProxy() # Create a proxy for our db.
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
class Meta:
database=db_proxy
db_table='MyUser'
# Based on configuration, use a different database.
if app.config['TESTING']:
db = SqliteDatabase(':memory:')
elif app.config['DEBUG']:
db = SqliteDatabase('mydatabase.db')
else:
db = PostgresqlDatabase(
'mydatabase', host='localhost', port=5432, user='postgres', password='postgres'
)
# Configure our proxy to use the db we specified in config.
db_proxy.initialize(db)
db.connect()
db.create_tables([MyUser])
您还可以在运行时使用数据库类和模型类中声明的bind()方法将模型关联到任何数据库对象。
以下示例使用数据库类中的bind()方法。
from peewee import *
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
db = MySQLDatabase('mydatabase', host='localhost', port=3306, user='root', password='')
db.connect()
db.bind([MyUser])
db.create_tables([MyUser])
Model 类中也定义了相同的bind() 方法。
from peewee import *
class MyUser (Model):
name=TextField()
city=TextField(constraints=[SQL("DEFAULT 'Mumbai'")])
age=IntegerField()
db = MySQLDatabase('mydatabase', host='localhost', port=3306, user='root', password='')
db.connect()
MyUser.bind(db)
db.create_tables([MyUser])
Peewee - 连接管理
默认情况下,使用设置为 True的自动连接参数创建数据库对象。相反,为了以编程方式管理数据库连接,它最初设置为 False。
db=SqliteDatabase("mydatabase", autoconnect=False)
数据库类具有connect()方法,可与服务器上存在的数据库建立连接。
db.connect()
始终建议在执行的操作结束时关闭连接。
db.close()
如果您尝试打开一个已经打开的连接,Peewee 会引发OperationError。
>>> db.connect()
True
>>> db.connect()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "c:\peewee\lib\site-packages\peewee.py", line 3031, in connect
raise OperationalError('Connection already opened.')
peewee.OperationalError: Connection already opened.
为了避免此错误,请使用reuse_if_open=True作为connect()方法的参数。
>>> db.connect(reuse_if_open=True) False
在已经关闭的连接上调用close()不会导致错误。但是,您可以使用is_close()方法检查连接是否已关闭。
>>> if db.is_closed()==True: db.connect() True >>>
也可以使用数据库对象作为context_manager,而不是最终显式调用 db.close() 。
from peewee import *
db = SqliteDatabase('mydatabase.db', autoconnect=False)
class User (Model):
user_id=TextField(primary_key=True)
name=TextField()
age=IntegerField()
class Meta:
database=db
db_table='User'
with db:
db.connect()
db.create_tables([User])
Peewee - 关系和连接
Peewee 支持实现不同类型的 SQL JOIN 查询。它的 Model 类有一个join()方法,该方法返回一个 Join 实例。
M1.joint(m2, join_type, on)
将 M1 模型映射到 m2 模型的连接表连接起来,并返回 Join 类实例。on 参数默认为 None,是用作连接谓词的表达式。
连接类型
Peewee 支持以下连接类型(默认为 INNER)。
加入.内部
JOIN.LEFT_OUTER
JOIN.RIGHT_OUTER
加入.完整
JOIN.FULL_OUTER
加入.交叉
为了展示 join() 方法的使用,我们首先声明以下模型 -
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Item(BaseModel):
itemname = TextField()
price = IntegerField()
class Brand(BaseModel):
brandname = TextField()
item = ForeignKeyField(Item, backref='brands')
class Bill(BaseModel):
item = ForeignKeyField(Item, backref='bills')
brand = ForeignKeyField(Brand, backref='bills')
qty = DecimalField()
db.create_tables([Item, Brand, Bill])
表格
接下来,我们用以下测试数据填充这些表 -
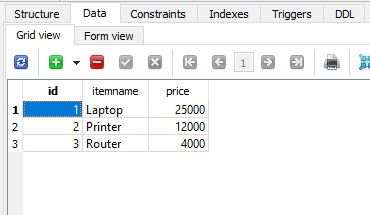
项目表
项目表如下 -
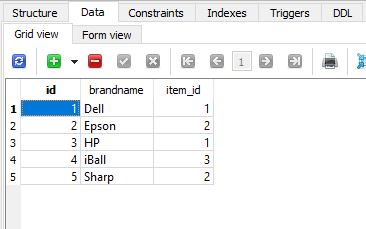
品牌表
下面给出的是品牌表 -
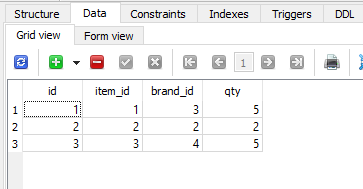
账单表
账单表如下 -
要在 Brand 和 Item 表之间执行简单的联接操作,请执行以下代码 -
qs=Brand.select().join(Item)
for q in qs:
print ("Brand ID:{} Item Name: {} Price: {}".format(q.id, q.brandname, q.item.price))
结果输出如下 -
Brand ID:1 Item Name: Dell Price: 25000 Brand ID:2 Item Name: Epson Price: 12000 Brand ID:3 Item Name: HP Price: 25000 Brand ID:4 Item Name: iBall Price: 4000 Brand ID:5 Item Name: Sharp Price: 12000
连接多个表
我们有一个 Bill 模型,与项目和品牌模型有两个外键关系。要从所有三个表中获取数据,请使用以下代码 -
qs=Bill.select().join(Brand).join(Item)
for q in qs:
print ("BillNo:{} Brand:{} Item:{} price:{} Quantity:{}".format(q.id, \
q.brand.brandname, q.item.itemname, q.item.price, q.qty))
根据我们的测试数据,将显示以下输出 -
BillNo:1 Brand:HP Item:Laptop price:25000 Quantity:5 BillNo:2 Brand:Epson Item:Printer price:12000 Quantity:2 BillNo:3 Brand:iBall Item:Router price:4000 Quantity:5
Peewee - 子查询
在 SQL 中,子查询是另一个查询的 WHERE 子句中的嵌入查询。我们可以将子查询实现为model.select()作为外部 model.select() 语句的 where 属性内的参数。
为了演示 Peewee 中子查询的使用,让我们使用定义的以下模型 -
from peewee import *
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Contacts(BaseModel):
RollNo = IntegerField()
Name = TextField()
City = TextField()
class Branches(BaseModel):
RollNo = IntegerField()
Faculty = TextField()
db.create_tables([Contacts, Branches])
创建表后,将使用以下示例数据填充它们 -
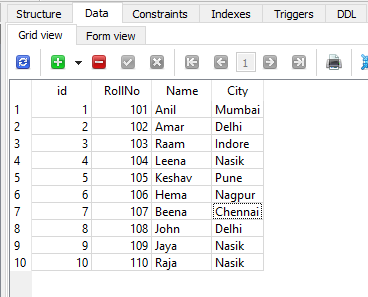
联系人表
联系人表如下 -
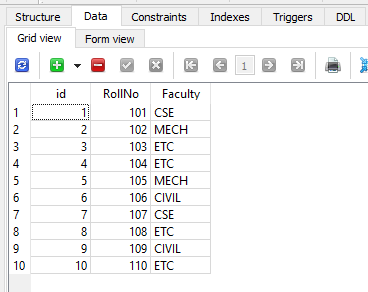
为了仅显示为 ETC 教员注册的 RollNo 的联系人表中的姓名和城市,以下代码生成一个 SELECT 查询,并在其 WHERE 子句中包含另一个 SELECT 查询。
#this query is used as subquery
faculty=Branches.select(Branches.RollNo).where(Branches.Faculty=="ETC")
names=Contacts.select().where (Contacts.RollNo .in_(faculty))
print ("RollNo and City for Faculty='ETC'")
for name in names:
print ("RollNo:{} City:{}".format(name.RollNo, name.City))
db.close()
上面的代码将显示以下结果:
RollNo and City for Faculty='ETC' RollNo:103 City:Indore RollNo:104 City:Nasik RollNo:108 City:Delhi RollNo:110 City:Nasik
Peewee - 排序
可以使用order_by子句以及模型的 select() 方法从表中选择记录。此外,通过将desc()附加到要执行排序的字段属性,记录将按降序收集。
例子
以下代码按城市名称升序显示联系人表中的记录。
rows=Contacts.select().order_by(Contacts.City)
print ("Contact list in order of city")
for row in rows:
print ("RollNo:{} Name: {} City:{}".format(row.RollNo,row.Name, row.City))
输出
这是按照城市名称升序排列的排序列表。
Contact list in order of city RollNo:107 Name: Beena City:Chennai RollNo:102 Name: Amar City:Delhi RollNo:108 Name: John City:Delhi RollNo:103 Name: Raam City:Indore RollNo:101 Name: Anil City:Mumbai RollNo:106 Name: Hema City:Nagpur RollNo:104 Name: Leena City:Nasik RollNo:109 Name: Jaya City:Nasik RollNo:110 Name: Raja City:Nasik RollNo:105 Name: Keshav City:Pune
例子
以下代码按名称字段的降序显示列表。
rows=Contacts.select().order_by(Contacts.Name.desc())
print ("Contact list in descending order of Name")
for row in rows:
print ("RollNo:{} Name: {} City:{}".format(row.RollNo,row.Name, row.City))
输出
输出如下 -
Contact list in descending order of Name RollNo:110 Name: Raja City:Nasik RollNo:103 Name: Raam City:Indore RollNo:104 Name: Leena City:Nasik RollNo:105 Name: Keshav City:Pune RollNo:108 Name: John City:Delhi RollNo:109 Name: Jaya City:Nasik RollNo:106 Name: Hema City:Nagpur RollNo:107 Name: Beena City:Chennai RollNo:101 Name: Anil City:Mumbai RollNo:102 Name: Amar City:Delhi
Peewee - 计数和聚合
我们可以通过附加count()方法来查找任何 SELECT 查询中报告的记录数。例如,以下语句返回 Contacts 表中 City='Nasik' 的行数。
qry=Contacts.select().where (Contacts.City=='Nasik').count() print (qry)
例子
SQL 在 SELECT 查询中有GROUP BY子句。Peewee 以group_by()方法的形式支持它。以下代码返回“联系人”表中按城市划分的姓名计数。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class Contacts(BaseModel):
RollNo = IntegerField()
Name = TextField()
City = TextField()
class Meta:
database = db
db.create_tables([Contacts])
qry=Contacts.select(Contacts.City, fn.Count(Contacts.City).alias('count')).group_by(Contacts.City)
print (qry.sql())
for q in qry:
print (q.City, q.count)
Peewee 发出的 SELECT 查询如下 -
('SELECT "t1"."City", Count("t1"."City") AS "count" FROM "contacts" AS "t1" GROUP BY "t1"."City"', [])
输出
根据联系人表中的示例数据,显示以下输出 -
Chennai 1 Delhi 2 Indore 1 Mumbai 1 Nagpur 1 Nasik 3 Pune 1
Peewee - SQL 函数
美国国家标准协会 (ANSI) 结构化查询语言 (SQL) 标准定义了许多 SQL 函数。
像下面这样的聚合函数在 Peewee 中很有用。
AVG() - 返回平均值。
COUNT() - 返回行数。
FIRST() - 返回第一个值。
LAST() - 返回最后一个值。
MAX() - 返回最大值。
MIN() - 返回最小值。
SUM() - 返回总和。
为了实现这些 SQL 函数,Peewee 有一个 SQL 辅助函数 fn()。在上面的示例中,我们使用它来查找每个城市的记录数。
以下示例构建一个使用 SUM() 函数的 SELECT 查询。
使用前面定义的模型中的账单和项目表,我们将显示账单表中输入的每个项目的数量总和。
项目表
包含数据的项目表如下 -
| ID | 项目名 | 价格 |
|---|---|---|
| 1 | 笔记本电脑 | 25000 |
| 2 | 打印机 | 12000 |
| 3 | 路由器 | 4000 |
账单表
账单表如下 -
| ID | 商品编号 | 品牌ID | 数量 |
|---|---|---|---|
| 1 | 1 | 3 | 5 |
| 2 | 2 | 2 | 2 |
| 3 | 3 | 4 | 5 |
| 4 | 2 | 2 | 6 |
| 5 | 3 | 4 | 3 |
| 6 | 1 | 3 | 1 |
例子
我们在 Bill 和 Item 表之间创建联接,从 Item 表中选择项目名称,并从 Bill 表中选择数量总和。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Item(BaseModel):
itemname = TextField()
price = IntegerField()
class Brand(BaseModel):
brandname = TextField()
item = ForeignKeyField(Item, backref='brands')
class Bill(BaseModel):
item = ForeignKeyField(Item, backref='bills')
brand = ForeignKeyField(Brand, backref='bills')
qty = DecimalField()
db.create_tables([Item, Brand, Bill])
qs=Bill.select(Item.itemname, fn.SUM(Bill.qty).alias('Sum'))
.join(Item).group_by(Item.itemname)
print (qs)
for q in qs:
print ("Item: {} sum: {}".format(q.item.itemname, q.Sum))
db.close()
上面的脚本执行以下 SELECT 查询 -
SELECT "t1"."itemname", SUM("t2"."qty") AS "Sum" FROM "bill" AS "t2"
INNER JOIN "item" AS "t1" ON ("t2"."item_id" = "t1"."id") GROUP BY "t1"."itemname"
输出
因此,输出如下 -
Item: Laptop sum: 6 Item: Printer sum: 8 Item: Router sum: 8
Peewee - 检索行元组/字典
可以在不创建模型实例的情况下迭代结果集。这可以通过使用以下方法来实现 -
tuples() 方法。
dicts() 方法。
例子
要将 SELECT 查询中的字段数据作为元组集合返回,请使用tuples()方法。
qry=Contacts.select(Contacts.City, fn.Count(Contacts.City).alias('count'))
.group_by(Contacts.City).tuples()
lst=[]
for q in qry:
lst.append(q)
print (lst)
输出
输出如下 -
[
('Chennai', 1),
('Delhi', 2),
('Indore', 1),
('Mumbai', 1),
('Nagpur', 1),
('Nasik', 3),
('Pune', 1)
]
例子
获取字典对象的集合 -
qs=Brand.select().join(Item).dicts() lst=[] for q in qs: lst.append(q) print (lst)
输出
输出如下:
[
{'id': 1, 'brandname': 'Dell', 'item': 1},
{'id': 2, 'brandname': 'Epson', 'item': 2},
{'id': 3, 'brandname': 'HP', 'item': 1},
{'id': 4, 'brandname': 'iBall', 'item': 3},
{'id': 5, 'brandname': 'Sharp', 'item': 2}
]
Peewee - 用户定义的运算符
Peewee 有Expression类,借助它我们可以在 Peewee 的运算符列表中添加任何自定义运算符。表达式的构造函数需要三个参数:左操作数、运算符和右操作数。
op=Expression(left, operator, right)
使用 Expression 类,我们定义一个mod()函数,它接受左和右参数以及“%”作为运算符。
from peewee import Expression # the building block for expressions def mod(lhs, rhs): return Expression(lhs, '%', rhs)
例子
我们可以在 SELECT 查询中使用它来获取 Contacts 表中具有偶数 id 的记录列表。
from peewee import *
db = SqliteDatabase('mydatabase.db')
class BaseModel(Model):
class Meta:
database = db
class Contacts(BaseModel):
RollNo = IntegerField()
Name = TextField()
City = TextField()
db.create_tables([Contacts])
from peewee import Expression # the building block for expressions
def mod(lhs, rhs):
return Expression(lhs,'%', rhs)
qry=Contacts.select().where (mod(Contacts.id,2)==0)
print (qry.sql())
for q in qry:
print (q.id, q.Name, q.City)
此代码将发出以下由字符串表示的 SQL 查询 -
('SELECT "t1"."id", "t1"."RollNo", "t1"."Name", "t1"."City" FROM "contacts" AS "t1" WHERE (("t1"."id" % ?) = ?)', [2, 0])
输出
因此,输出如下 -
2 Amar Delhi 4 Leena Nasik 6 Hema Nagpur 8 John Delhi 10 Raja Nasik
Peewee - Atomics事务
Peewee 的数据库类具有创建上下文管理器的atomic()方法。它开始一个新的事务。在上下文块内,可以提交或回滚事务,具体取决于事务是否已成功完成或遇到异常。
with db.atomic() as transaction:
try:
User.create(name='Amar', age=20)
transaction.commit()
except DatabaseError:
transaction.rollback()
atomic() 也可以用作装饰器。
@db.atomic()
def create_user(nm,n):
return User.create(name=nm, age=n)
create_user('Amar', 20)
还可以嵌套多个Atomics事务块。
with db.atomic() as txn1:
User.create('name'='Amar', age=20)
with db.atomic() as txn2:
User.get(name='Amar')
Peewee - 数据库错误
Python 的 DB-API 标准(PEP 249 推荐)指定了任何 DB-API 兼容模块(例如 pymysql、pyscopg2 等)定义的 Exception 类的类型。
Peewee API 为这些异常提供了易于使用的包装器。PeeweeException是 Peewee API 中定义以下 Exception 类的基类 -
数据库错误
数据错误
完整性错误
接口错误
内部错误
不支持错误
操作错误
编程错误
我们可以从 Peewee 实现上述异常,而不是尝试 DB-API 特定的异常。
Peewee - 查询生成器
Peewee 还提供非 ORM API 来访问数据库。我们可以将数据库表和列绑定到Peewee 中定义的Table和Column对象,并在它们的帮助下执行查询,而不是定义模型和字段。
首先,声明一个与我们数据库中的表对象相对应的表对象。您必须指定表名称和列列表。可选地,还可以提供主键。
Contacts=Table('Contacts', ('id', 'RollNo', 'Name', 'City'))
该表对象通过bind()方法与数据库绑定。
Contacts=Contacts.bind(db)
例子
现在,我们可以使用 select() 方法在此表对象上设置 SELECT 查询,并迭代结果集,如下所示 -
names=Contacts.select() for name in names: print (name)
输出
默认情况下,行作为字典返回。
{'id': 1, 'RollNo': 101, 'Name': 'Anil', 'City': 'Mumbai'}
{'id': 2, 'RollNo': 102, 'N