- Python 取证教程
- 家
- 介绍
- Python的安装
- Python概述
- 基本法医应用
- 哈希函数
- 破解加密
- 虚拟化
- 网络取证
- Python 模块
- Dshell 和 Scapy
- 搜寻中
- 索引
- Python 图像库
- 移动取证
- 网络时间协议
- 多处理支持
- 记忆与取证
- Linux 中的取证
- 妥协指标
- 云实施
- Python 取证有用资源
- Python 取证 - 快速指南
- Python 取证 - 有用的资源
- Python 取证 - 讨论
Python 取证 - 快速指南
Python 取证 - 简介
Python 是一种通用编程语言,具有简单易读的代码,专业开发人员和新手程序员都可以轻松理解。Python 包含许多有用的库,可以与任何堆栈框架一起使用。许多实验室依靠 Python 来构建用于预测和运行实验的基本模型。它还有助于控制关键操作系统。
Python 具有支持数字调查并在调查期间保护证据完整性的内置功能。在本教程中,我们将解释在数字或计算取证中应用 Python 的基本概念。
什么是计算取证?
计算取证是一个新兴的研究领域。它涉及使用数字方法解决法医问题。它使用计算科学来研究数字证据。
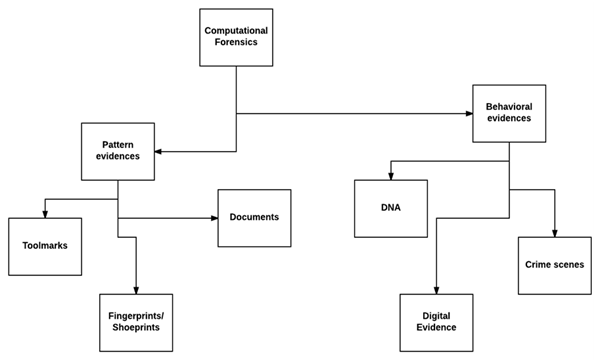
计算取证包括广泛的学科,主要基于模式证据,如工具痕迹、指纹、鞋印、文件等,调查对象、物质和过程,还包括生理和Behave模式、DNA和数字证据。犯罪现场。
下图显示了计算取证涵盖的广泛主题。
计算取证是在一些算法的帮助下实现的。这些算法用于信号和图像处理、计算机视觉和图形。它还包括数据挖掘、机器学习和机器人技术。
计算取证涉及多种数字方法。简化取证中所有数字方法的最佳解决方案是使用 Python 等通用编程语言。
Python 取证 - Python 的安装
由于我们需要 Python 来进行计算取证的所有活动,因此让我们逐步了解如何安装它。
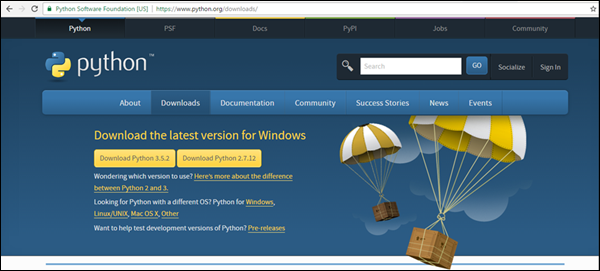
步骤 1 - 访问https://www.python.org/downloads/并根据您系统上的操作系统下载 Python 的安装文件。
步骤 2 - 下载软件包/安装程序后,单击 exe 文件开始安装过程。

安装完成后您将看到以下屏幕。

步骤 3 - 下一步是在系统中设置 Python 的环境变量。

步骤 4 - 设置环境变量后,在命令提示符下键入命令“python”以验证安装是否成功。
如果安装成功,您将在控制台上看到以下输出。

Python 取证 - Python 概述
用 Python 编写的代码看起来与用其他传统编程语言(例如 C 或 Pascal)编写的代码非常相似。也有人说Python的语法大量借鉴了C语言,其中包括许多与C语言类似的Python关键字。
Python 包含条件语句和循环语句,可用于准确提取数据以进行取证。对于流程控制,它提供if/else、while以及循环任何“可迭代”对象的高级for语句。
if a < b: max = b else: max = a
Python 与其他编程语言的主要区别在于它使用动态类型。它使用引用对象的变量名称。这些变量不需要声明。
数据类型
Python 包含一组内置数据类型,例如字符串、布尔值、数字等。还有不可变类型,这意味着在执行过程中不能更改值。
Python 还具有复合内置数据类型,其中包括作为不可变数组的元组、作为哈希表的列表和字典。所有这些都用于数字取证,以在收集证据的同时存储值。
第三方模块和软件包
Python 支持模块和/或包组,这些模块和/或包也称为第三方模块(相关代码组合在一个源文件中),用于组织程序。
Python 包含一个广泛的标准库,这是它在计算取证中流行的主要原因之一。
Python代码的生命周期
首先,当您执行Python代码时,解释器会检查代码是否有语法错误。如果解释器发现任何语法错误,则会立即将其显示为错误消息。
如果没有语法错误,则代码将被编译以生成字节码并发送到 PVM(Python 虚拟机)。
PVM 检查字节码是否有任何运行时或逻辑错误。如果 PVM 发现任何运行时错误,则会立即将其报告为错误消息。
如果字节码没有错误,则代码将被处理并获得其输出。
下图以图形方式显示了 Python 代码如何首先被解释以生成字节码,以及 PVM 如何处理字节码以生成输出。

Python Forensics - 基本取证应用程序
为了根据取证指南创建应用程序,了解并遵循其命名约定和模式非常重要。
命名约定
在Python取证应用程序的开发过程中,需要遵循的规则和约定如下表所示。
| 常数 | 大写字母下划线分隔 | 高温 |
| 局部变量名 | 带凹凸大写字母的小写字母(下划线可选) | 当前温度 |
| 全局变量名 | 前缀 gl 小写字母,带凹凸大写(下划线可选) | gl_maximumRecordedTemperature |
| 函数名称 | 带凹凸大写字母的大写字母(可选下划线),带主动语态 | 将华氏度转换为摄氏度(...) |
| 对象名称 | 带有凹凸大写的前缀 ob_ 小写 | ob_myTempRecorder |
| 模块 | 下划线后跟带凹凸大写字母的小写字母 | _tempRecorder |
| 类名 | 前缀 class_ 然后颠簸大写并保持简短 | 类_临时系统 |
让我们通过一个场景来了解命名约定在计算取证中的重要性。假设我们有一个通常用于加密数据的哈希算法。单向哈希算法将输入视为二进制数据流;这可以是密码、文件、二进制数据或任何数字数据。然后,散列算法根据输入中接收到的数据生成消息摘要(md)。
实际上不可能创建一个新的二进制输入来生成给定的消息摘要。即使二进制输入数据的一位,如果发生更改,也会生成一条与之前不同的唯一消息。
例子
看一下下面的示例程序,它遵循上述约定。
import sys, string, md5 # necessary libraries print "Please enter your full name" line = sys.stdin.readline() line = line.rstrip() md5_object = md5.new() md5_object.update(line) print md5_object.hexdigest() # Prints the output as per the hashing algorithm i.e. md5 exit
上述程序产生以下输出。

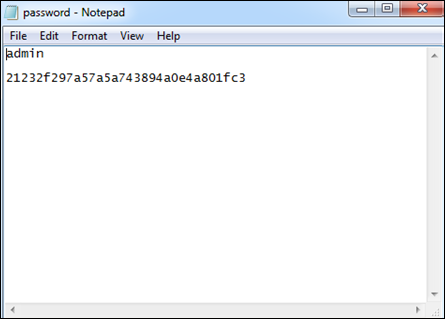
在此程序中,Python 脚本接受输入(您的全名)并根据 md5 哈希算法对其进行转换。如果需要,它会加密数据并保护信息。根据法医指南,证据名称或任何其他证据都可以通过这种模式得到保护。
Python 取证 - 哈希函数
哈希函数被定义为将大量数据映射到具有指定长度的固定值的函数。该函数确保相同的输入产生相同的输出,这实际上被定义为哈希和。哈希和包括具有特定信息的特征。
该功能实际上不可能恢复。因此,任何第三方攻击(例如暴力攻击)实际上是不可能的。另外,这种算法称为单向密码算法。
理想的加密哈希函数有四个主要属性 -
- 计算任何给定输入的哈希值必须很容易。
- 从其哈希生成原始输入肯定是不可行的。
- 在不改变哈希值的情况下修改输入肯定是不可行的。
- 找到具有相同哈希值的两个不同输入肯定是不可行的。
例子
请考虑以下示例,该示例有助于使用十六进制格式的字符来匹配密码。
import uuid
import hashlib
def hash_password(password):
# userid is used to generate a random number
salt = uuid.uuid4().hex #salt is stored in hexadecimal value
return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ':' + salt
def check_password(hashed_password, user_password):
# hexdigest is used as an algorithm for storing passwords
password, salt = hashed_password.split(':')
return password == hashlib.sha256(salt.encode()
+ user_password.encode()).hexdigest()
new_pass = raw_input('Please enter required password ')
hashed_password = hash_password(new_pass)
print('The string to store in the db is: ' + hashed_password)
old_pass = raw_input('Re-enter new password ')
if check_password(hashed_password, old_pass):
print('Yuppie!! You entered the right password')
else:
print('Oops! I am sorry but the password does not match')
流程图
我们借助以下流程图解释了该程序的逻辑 -

输出
我们的代码将产生以下输出 -

输入两次的密码与哈希函数匹配。这可以确保输入两次的密码是准确的,这有助于收集有用的数据并以加密格式保存它们。
Python 取证 - 破解加密
在本章中,我们将学习如何破解在分析和证据过程中获取的文本数据。
密码学中的纯文本是一些正常可读的文本,例如消息。另一方面,密文是输入纯文本后获取的加密算法的输出。
将纯文本消息转换为密文的简单算法是凯撒密码,由朱利叶斯·凯撒发明,用于向敌人保密纯文本。该密码涉及将消息中的每个字母在字母表中“向前”移动三个位置。
以下是演示图。
一个→D
b → E
c → F
....
w → Z
x → A
y → B
z → C
例子
运行Python脚本时输入的消息给出了字符的所有可能性,这用于模式证据。
使用的模式证据类型如下 -
- 轮胎痕迹和痕迹
- 印象数
- 指纹
每个生物识别数据都包含矢量数据,我们需要破解这些数据来收集充分的证据。
以下 Python 代码展示了如何从纯文本生成密文 -
import sys
def decrypt(k,cipher):
plaintext = ''
for each in cipher:
p = (ord(each)-k) % 126
if p < 32:
p+=95
plaintext += chr(p)
print plaintext
def main(argv):
if (len(sys.argv) != 1):
sys.exit('Usage: cracking.py')
cipher = raw_input('Enter message: ')
for i in range(1,95,1):
decrypt(i,cipher)
if __name__ == "__main__":
main(sys.argv[1:])
输出
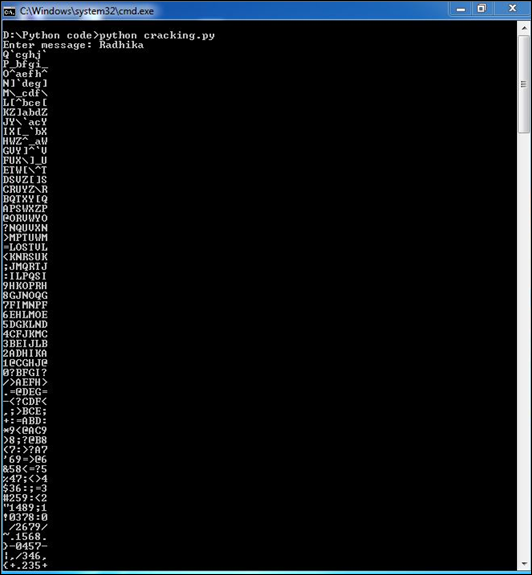
现在,检查此代码的输出。当我们输入简单的文本“Radhika”时,程序会产生以下密文。
Python 取证 - 虚拟化
虚拟化是模拟服务器、工作站、网络和存储等 IT 系统的过程。它只不过是创建任何操作系统、服务器、存储设备或网络进程的虚拟版本而不是实际版本。
有助于模拟虚拟硬件的主要组件被定义为虚拟机管理程序。
下图解释了所使用的两种主要系统虚拟化类型。

虚拟化已以多种方式应用于计算取证。它可以帮助分析人员在每次调查中以经过验证的状态使用工作站。特别是,通过将驱动器的 dd 映像附加为虚拟机上的辅助驱动器,可以实现数据恢复。同一台机器可以用作恢复软件来收集证据。
以下示例有助于理解使用 Python 编程语言创建虚拟机。
步骤 1 - 将虚拟机命名为“dummy1”。
每个虚拟机的最小容量必须为 512 MB(以字节为单位)。
vm_memory = 512 * 1024 * 1024
步骤 2 - 虚拟机必须连接到已计算的默认集群。
vm_cluster = api.clusters.get(name = "Default")
步骤 3 - 虚拟机必须从虚拟硬盘驱动器启动。
vm_os = params.OperatingSystem(boot = [params.Boot(dev = "hd")])
在使用 vms 集合的 add 方法添加到虚拟机之前,所有选项都会组合成一个虚拟机参数对象。
例子
以下是用于添加虚拟机的完整 Python 脚本。
from ovirtsdk.api import API #importing API library
from ovirtsdk.xml import params
try: #Api credentials is required for virtual machine
api = API(url = "https://HOST",
username = "Radhika",
password = "a@123",
ca_file = "ca.crt")
vm_name = "dummy1"
vm_memory = 512 * 1024 * 1024 #calculating the memory in bytes
vm_cluster = api.clusters.get(name = "Default")
vm_template = api.templates.get(name = "Blank")
#assigning the parameters to operating system
vm_os = params.OperatingSystem(boot = [params.Boot(dev = "hd")])
vm_params = params.VM(name = vm_name,
memory = vm_memory,
cluster = vm_cluster,
template = vm_template
os = vm_os)
try:
api.vms.add(vm = vm_params)
print "Virtual machine '%s' added." % vm_name #output if it is successful.
except Exception as ex:
print "Adding virtual machine '%s' failed: %s" % (vm_name, ex)
api.disconnect()
except Exception as ex:
print "Unexpected error: %s" % ex
输出
我们的代码将产生以下输出 -

Python 取证 - 网络取证
现代网络环境的情况使得调查可能由于许多困难而充满困难。无论您是在响应违规支持、调查内部活动、执行与漏洞相关的评估还是验证监管合规性,都可能发生这种情况。
网络编程的概念
网络编程中使用以下定义。
客户端- 客户端是网络编程的客户端-服务器架构的一部分,运行在个人计算机和工作站上。
服务器- 服务器是客户端-服务器体系结构的一部分,为同一台或其他计算机中的其他计算机程序提供服务。
WebSockets - WebSockets 提供客户端和服务器之间的协议,该协议在持久的 TCP 连接上运行。通过这种方式,可以在 TCP 套接字连接之间(同时)发送双向消息。
WebSocket 是继许多其他允许服务器向客户端发送信息的技术之后出现的。除了握手升级标头之外,WebSockets 独立于 HTTP。

这些协议用于验证第三方用户发送或接收的信息。由于加密是用于保护消息安全的方法之一,因此保护消息传输通道的安全也很重要。
考虑以下 Python 程序,客户端使用该程序进行握手。
例子
# client.py
import socket
# create a socket object
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8080
# connection to hostname on the port.
s.connect((host, port))
# Receive no more than 1024 bytes
tm = s.recv(1024)
print("The client is waiting for connection")
s.close()
输出
它将产生以下输出 -

接受通信通道请求的服务器将包含以下脚本。
# server.py
import socket
import time
# create a socket object
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8080
# bind to the port
serversocket.bind((host, port))
# queue up to 5 requests
serversocket.listen(5)
while True:
# establish a connection
clientsocket,addr = serversocket.accept()
print("Got a connection from %s" % str(addr))
currentTime = time.ctime(time.time()) + "\r\n"
clientsocket.send(currentTime.encode('ascii'))
clientsocket.close()
通过Python编程创建的客户端和服务器监听主机号。最初,客户端向服务器发送关于主机号中发送的数据的请求,服务器接受该请求并立即发送响应。这样,我们就可以拥有安全的沟通渠道。
Python 取证 - Python 模块
Python 程序中的模块有助于组织代码。它们有助于将相关代码分组到单个模块中,从而使其更易于理解和使用。它包括任意命名的值,可用于绑定和引用。简而言之,模块是由 Python 代码组成的文件,其中包括函数、类和变量。
模块(文件)的 Python 代码以.py扩展名保存,并在需要时进行编译。
例子
def print_hello_func( par ): print "Hello : ", par return
进口声明
通过执行导入其他包或第三方库的import语句,Python 源文件可以用作模块。使用的语法如下 -
import module1[, module2[,... moduleN]
当Python解释器遇到import语句时,它会导入搜索路径中存在的指定模块。
例子
考虑以下示例。
#!/usr/bin/python
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Radhika")
它将产生以下输出 -
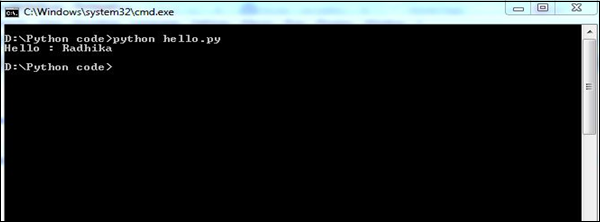
模块仅加载一次,无论 Python 代码导入多少次。
来自...导入声明
From属性有助于将特定属性从模块导入到当前命名空间中。这是它的语法。
from modname import name1[, name2[, ... nameN]]
例子
要从模块fib导入函数fibonacci,请使用以下语句。
from fib import fibonacci
定位模块
导入模块时,Python 解释器会搜索以下序列 -
当前目录。
如果该模块不存在,Python 将搜索 shell 变量 PYTHONPATH 中的每个目录。
如果 shell 变量位置失败,Python 将检查默认路径。
计算取证使用 Python 模块和第三方模块来更轻松地获取信息并提取证据。其他章节重点介绍模块的实现以获得必要的输出。
Python 取证 - Dshell 和 Scapy
外壳程序
Dshell是一个基于Python的网络取证分析工具包。该工具包由美国陆军研究实验室开发。该开源工具包于 2014 年发布。该工具包的主要重点是轻松进行取证调查。
该工具包由大量解码器组成,如下表所列。
| 先生。 | 解码器名称和描述 |
|---|---|
| 1 | 域名系统 这用于提取 DNS 相关查询 |
| 2 | 保留提示 确定 DNS 问题的解决方案 |
| 3 | 大流量 网络流量列表 |
| 4 | rip-http 它用于从 HTTP 流量中提取文件 |
| 5 | 协议 用于非标准协议的识别 |
美国陆军实验室在 GitHub 中维护了克隆存储库,链接如下:
https://github.com/USArmyResearchLab/Dshell
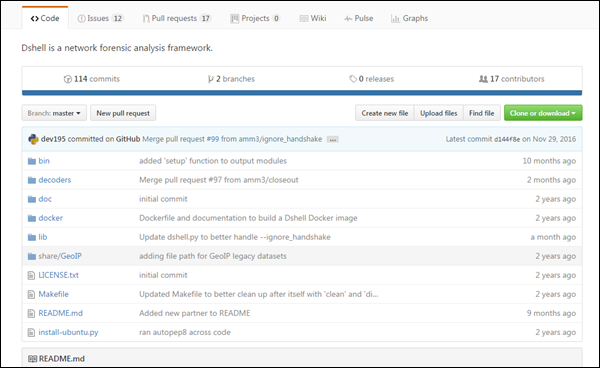
该克隆包含一个用于安装该工具包的脚本install-ubuntu.py () 。
一旦安装成功,它会自动构建稍后使用的可执行文件和依赖项。
依赖关系如下 -
dependencies = {
"Crypto": "crypto",
"dpkt": "dpkt",
"IPy": "ipy",
"pcap": "pypcap"
}
该工具包可用于 pcap(数据包捕获)文件,该文件通常在事件或警报期间记录。这些 pcap 文件要么由 Linux 平台上的 libpcap 创建,要么由 Windows 平台上的 WinPcap 创建。
斯卡皮
Scapy 是一个基于 Python 的工具,用于分析和操纵网络流量。以下是 Scapy 工具包的链接 -
http://www.secdev.org/projects/scapy/
该工具包用于分析数据包操作。它非常有能力解码多种协议的数据包并捕获它们。Scapy 与 Dshell 工具包的不同之处在于,它向调查人员提供有关网络流量的详细描述。这些描述已被实时记录。
Scapy 能够使用第三方工具或操作系统指纹进行绘图。
考虑以下示例。
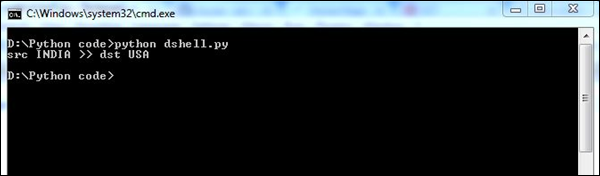
import scapy, GeoIP #Imports scapy and GeoIP toolkit
from scapy import *
geoIp = GeoIP.new(GeoIP.GEOIP_MEMORY_CACHE) #locates the Geo IP address
def locatePackage(pkg):
src = pkg.getlayer(IP).src #gets source IP address
dst = pkg.getlayer(IP).dst #gets destination IP address
srcCountry = geoIp.country_code_by_addr(src) #gets Country details of source
dstCountry = geoIp.country_code_by_addr(dst) #gets country details of destination
print src+"("+srcCountry+") >> "+dst+"("+dstCountry+")\n"
该脚本给出了网络数据包中相互通信的国家详细信息的详细描述。
上面的脚本将产生以下输出。
Python 取证 - 搜索
搜索无疑是法医调查的支柱之一。如今,搜索的好坏取决于调查证据的调查员。
当我们借助关键字搜索证据时,从消息中搜索关键字在取证中起着至关重要的作用。了解要在特定文件中搜索什么以及在已删除文件中搜索什么需要经验和知识。
Python 有各种内置机制和标准库模块来支持搜索操作。从根本上说,调查人员使用搜索操作来查找“谁”、“什么”、“哪里”、“何时”等问题的答案。
例子
在下面的示例中,我们声明了两个字符串,然后使用 find 函数检查第一个字符串是否包含第二个字符串。
# Searching a particular word from a message str1 = "This is a string example for Computational forensics of gathering evidence!"; str2 = "string"; print str1.find(str2) print str1.find(str2, 10) print str1.find(str2, 40)
上面的脚本将产生以下输出。

Python 中的“查找”功能有助于搜索消息或段落中的关键字。这对于收集适当的证据至关重要。
Python 取证 - 索引
索引实际上使调查人员能够全面查看文件并从中收集潜在的证据。证据可以包含在文件、磁盘映像、内存快照或网络跟踪中。
索引有助于减少关键字搜索等耗时任务的时间。取证调查还涉及交互式搜索阶段,其中索引用于快速定位关键字。
索引还有助于在排序列表中列出关键字。
例子
以下示例展示了如何在 Python 中使用索引。
aList = [123, 'sample', 'zara', 'indexing'];
print "Index for sample : ", aList.index('sample')
print "Index for indexing : ", aList.index('indexing')
str1 = "This is sample message for forensic investigation indexing";
str2 = "sample";
print "Index of the character keyword found is "
print str1.index(str2)
上面的脚本将产生以下输出。

Python Forensics - Python 成像库
从可用资源中提取有价值的信息是数字取证的重要组成部分。获取所有可用信息对于调查过程至关重要,因为它有助于检索适当的证据。
包含数据的资源可以是简单的数据结构(例如数据库),也可以是复杂的数据结构(例如 JPEG 图像)。使用简单的桌面工具可以轻松访问简单的数据结构,而从复杂的数据结构中提取信息则需要复杂的编程工具。
Python 图像库
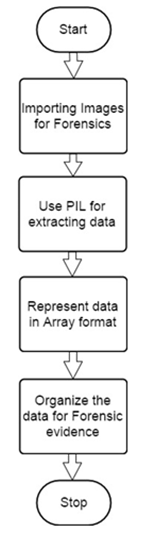
Python 成像库 (PIL) 为您的 Python 解释器添加了图像处理功能。该库支持多种文件格式,并提供强大的图像处理和图形功能。您可以从以下网址下载PIL的源文件:http ://www.pythonware.com/products/pil/
下图展示了PIL中从图像(复杂数据结构)中提取数据的完整流程图。
例子
现在,让我们通过一个编程示例来了解它的实际工作原理。
步骤 1 - 假设我们有以下图像,需要从中提取信息。

步骤 2 - 当我们使用 PIL 打开此图像时,它首先会记录提取证据所需的必要点,其中包括各种像素值。这是打开图像并记录其像素值的代码 -
from PIL import Image
im = Image.open('Capture.jpeg', 'r')
pix_val = list(im.getdata())
pix_val_flat = [x for sets in pix_val for x in sets]
print pix_val_flat
步骤 3 - 提取图像的像素值后,我们的代码将产生以下输出。
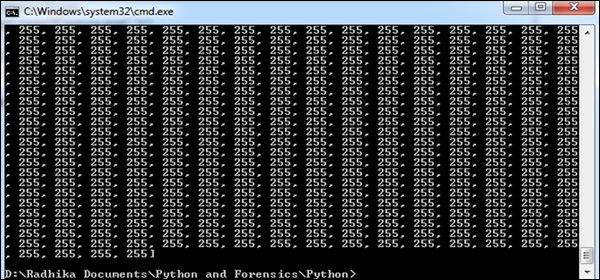
提供的输出表示 RGB 组合的像素值,可以更好地了解证据所需的数据。获取的数据以数组的形式表示。
Python 取证 - 移动取证
对硬盘等标准计算机硬件的取证调查和分析已发展成为一门稳定的学科,并借助分析非标准硬件或瞬态证据的技术进行跟踪。
尽管智能手机越来越多地用于数字调查,但它们仍然被认为是非标准的。
法医分析
取证调查搜索数据,例如从智能手机接听的电话或拨打的号码。它可以包括短信、照片或任何其他犯罪证据。大多数智能手机都具有使用密码或字母数字字符的屏幕锁定功能。
在这里,我们将通过一个例子来展示Python如何帮助破解锁屏密码并从智能手机中检索数据。
手工检查
Android 支持使用 PIN 码或字母数字密码进行密码锁定。两个密码的长度都必须在 4 到 16 个数字或字符之间。智能手机的密码存储在 Android 系统中/data/system中一个名为password.key的特殊文件中。
Android 存储密码的加盐 SHA1 哈希和和 MD5 哈希和。这些密码可以用下面的代码进行处理。
public byte[] passwordToHash(String password) {
if (password == null) {
return null;
}
String algo = null;
byte[] hashed = null;
try {
byte[] saltedPassword = (password + getSalt()).getBytes();
byte[] sha1 = MessageDigest.getInstance(algo = "SHA-1").digest(saltedPassword);
byte[] md5 = MessageDigest.getInstance(algo = "MD5").digest(saltedPassword);
hashed = (toHex(sha1) + toHex(md5)).getBytes();
} catch (NoSuchAlgorithmException e) {
Log.w(TAG, "Failed to encode string because of missing algorithm: " + algo);
}
return hashed;
}
由于散列密码存储在盐文件中,因此借助字典攻击来破解密码是不可行的。该盐是一串 64 位随机整数的十六进制表示形式。使用已 Root 的智能手机或JTAG 适配器可以轻松访问盐。
已root的智能手机
文件/data/system/password.key的转储存储在 SQLite 数据库中的lockscreen.password_salt键下。在settings.db下,存储了密码,并且该值在以下屏幕截图中清晰可见。
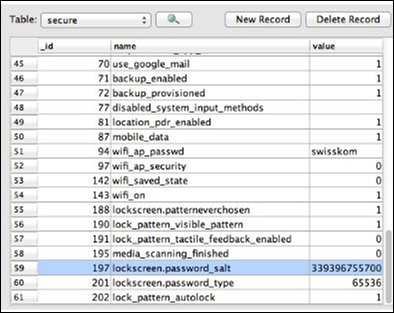
JTAG适配器
可以使用称为 JTAG(联合测试行动组)适配器的特殊硬件来访问salt。同样,Riff-Box或JIG-Adapter也可用于相同的功能。
利用从 Riff-box 获得的信息,我们可以找到加密数据的位置,即salt。以下是规则 -
搜索关联的字符串“lockscreen.password_salt”。
该字节表示 salt 的实际宽度,即它的length。
这是实际搜索以获取智能手机存储的密码/PIN 码的长度。
这些规则有助于获取适当的盐数据。
Python 取证 - 网络时间协议
使用最广泛的时间同步协议是通过网络时间协议 (NTP) 完成的,该协议已被广泛接受为一种实践。
NTP 使用用户数据报协议 (UDP),该协议使用最短时间在服务器和希望与给定时间源同步的客户端之间传送数据包。

网络时间协议的特点如下:
默认服务器端口为 123。
该协议由许多与国家实验室同步的可访问时间服务器组成。
NTP 协议标准由 IETF 管理,提议的标准是 RFC 5905,标题为“网络时间协议版本 4:协议和算法规范”[NTP RFC]
操作系统、程序和应用程序使用 NTP 以正确的方式同步时间。
在本章中,我们将重点介绍 NTP 与 Python 的使用,这可以通过第三方 Python 库 ntplib 实现。该库有效地处理繁重的工作,它将结果与我的本地系统时钟进行比较。
安装 NTP 库
ntplib可以在https://pypi.python.org/pypi/ntplib/下载,如下图所示。
该库借助可转换 NTP 协议字段的方法,为 NTP 服务器提供了一个简单的接口。这有助于访问其他关键值,例如闰秒。

以下Python程序有助于理解NTP的用法。
import ntplib import time NIST = 'nist1-macon.macon.ga.us' ntp = ntplib.NTPClient() ntpResponse = ntp.request(NIST) if (ntpResponse): now = time.time() diff = now-ntpResponse.tx_time print diff;
上述程序将产生以下输出。

时间差是在上述程序中计算的。这些计算有助于法医调查。获得的网络数据与对硬盘上的数据的分析有根本的不同。
时区的差异或获取准确的时区可以帮助收集通过此协议捕获消息的证据。
Python 取证 - 多处理支持
法医专家通常发现很难应用数字解决方案来分析常见犯罪中大量的数字证据。大多数数字调查工具都是单线程的,它们一次只能执行一个命令。
在本章中,我们将重点关注 Python 的多处理功能,这可能与常见的取证挑战相关。
多重处理
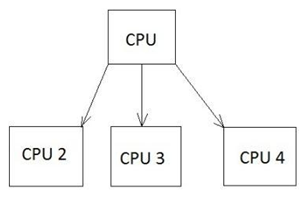
多重处理被定义为计算机系统支持多个进程的能力。支持多处理的操作系统允许多个程序同时运行。
多重处理有多种类型,例如对称处理和非对称处理。下图是取证调查中通常遵循的对称多处理系统。
例子
以下代码显示了如何在 Python 编程中内部列出不同的进程。
import random
import multiprocessing
def list_append(count, id, out_list):
#appends the count of number of processes which takes place at a time
for i in range(count):
out_list.append(random.random())
if __name__ == "__main__":
size = 999
procs = 2
# Create a list of jobs and then iterate through
# the number of processes appending each process to
# the job list
jobs = []
for i in range(0, procs):
out_list = list() #list of processes
process1 = multiprocessing.Process(
target = list_append, args = (size, i, out_list))
# appends the list of processes
jobs.append(process)
# Calculate the random number of processes
for j in jobs:
j.start() #initiate the process
# After the processes have finished execution
for j in jobs:
j.join()
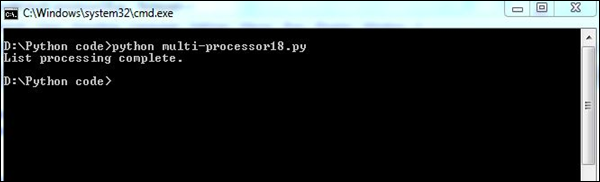
print "List processing complete."
这里,函数list_append()有助于列出系统中的进程集。
输出
我们的代码将产生以下输出 -
Python 取证 - 内存和取证
在本章中,我们将借助Volatility重点研究易失性内存,Volatility 是一个基于 Python 的取证框架,适用于以下平台:Android和Linux。
易失性内存
易失性存储器是一种存储类型,当系统电源关闭或中断时,其内容会被擦除。RAM 是易失性存储器的最好例子。这意味着,如果您正在处理尚未保存到非易失性存储器(例如硬盘驱动器)的文档,并且计算机断电,则所有数据都将丢失。
一般来说,易失性内存取证遵循与其他取证调查相同的模式 -
- 选择调查对象
- 获取法医数据
- 法医分析
用于 Android 的基本波动率插件收集RAM 转储进行分析。收集 RAM 转储进行分析后,开始寻找 RAM 中的恶意软件非常重要。
雅苒规则
YARA 是一种流行的工具,它提供了强大的语言,与基于 Perl 的正则表达式兼容,并用于检查可疑文件/目录和匹配字符串。
在本节中,我们将使用基于模式匹配实现的 YARA 并将它们与实用功能结合起来。完整的过程将有利于法医分析。
例子
考虑以下代码。此代码有助于提取代码。
import operator
import os
import sys
sys.path.insert(0, os.getcwd())
import plyara.interp as interp
# Plyara is a script that lexes and parses a file consisting of one more Yara
# rules into a python dictionary representation.
if __name__ == '__main__':
file_to_analyze = sys.argv[1]
rulesDict = interp.parseString(open(file_to_analyze).read())
authors = {}
imps = {}
meta_keys = {}
max_strings = []
max_string_len = 0
tags = {}
rule_count = 0
for rule in rulesDict:
rule_count += 1
# Imports
if 'imports' in rule:
for imp in rule['imports']:
imp = imp.replace('"','')
if imp in imps:
imps[imp] += 1
else:
imps[imp] = 1
# Tags
if 'tags' in rule:
for tag in rule['tags']:
if tag in tags:
tags[tag] += 1
else:
tags[tag] = 1
# Metadata
if 'metadata' in rule:
for key in rule['metadata']:
if key in meta_keys:
meta_keys[key] += 1
else:
meta_keys[key] = 1
if key in ['Author', 'author']:
if rule['metadata'][key] in authors:
authors[rule['metadata'][key]] += 1
else:
authors[rule['metadata'][key]] = 1
#Strings
if 'strings' in rule:
for strr in rule['strings']:
if len(strr['value']) > max_string_len:
max_string_len = len(strr['value'])
max_strings = [(rule['rule_name'], strr['name'], strr['value'])]
elif len(strr['value']) == max_string_len:
max_strings.append((rule['rule_name'], strr['key'], strr['value']))
print("\nThe number of rules implemented" + str(rule_count))
ordered_meta_keys = sorted(meta_keys.items(), key = operator.itemgetter(1),
reverse = True)
ordered_authors = sorted(authors.items(), key = operator.itemgetter(1),
reverse = True)
ordered_imps = sorted(imps.items(), key = operator.itemgetter(1), reverse = True)
ordered_tags = sorted(tags.items(), key = operator.itemgetter(1), reverse = True)
上面的代码将产生以下输出。
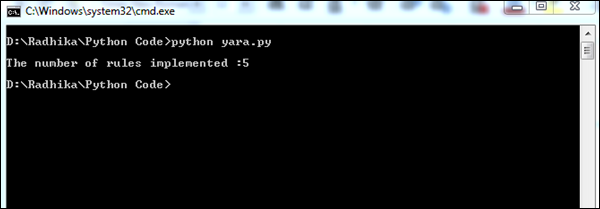
实施的 YARA 规则数量有助于更好地了解可疑文件。间接地,可疑文件列表有助于收集适当的信息以进行取证。
以下是github中的源代码: https: //github.com/radhikascs/Python_yara
Linux 中的 Python 取证
数字调查的主要关注点是通过加密或任何其他格式保护重要证据或数据。基本示例是存储密码。因此,有必要了解 Linux 操作系统在数字取证实施中的使用,以保护这些有价值的数据。
所有本地用户的信息主要存储在以下两个文件中 -
- /etc/密码
- 等/阴影
第一个是强制性的,它存储所有密码。第二个文件是可选的,它存储有关本地用户的信息,包括哈希密码。
将密码信息存储在每个用户都可读的文件中的安全问题会出现问题。因此,散列密码存储在/etc/passwd中,其中内容被特殊值“ x ”替换。
必须在/etc/shadow中查找相应的哈希值。/etc/passwd中的设置可能会覆盖/etc/shadow中的详细信息。
Linux 中的两个文本文件每行都包含一个条目,并且该条目由多个字段组成,并用冒号分隔。
/etc/passwd的格式如下 -
| 先生。 | 字段名称和描述 |
|---|---|
| 1 | 用户名 该字段由人类可读格式的属性组成 |
| 2 | 密码哈希 它由根据 Posix crypt 函数编码形式的密码组成 |
如果哈希密码保存为空,则相应的用户将不需要任何密码即可登录系统。如果该字段包含哈希算法无法生成的值(例如感叹号),则用户无法使用密码登录。
密码锁定的用户仍然可以使用其他身份验证机制(例如 SSH 密钥)登录。如前所述,特殊值“ x ”意味着必须在影子文件中找到密码散列。
密码哈希包括以下内容 -
加密盐-加密盐有助于维护屏幕锁、PIN 码和密码。
数字用户 ID - 该字段表示用户的 ID。Linux 内核将此用户 ID 分配给系统。
数字组 ID - 此字段指用户的主要组。
主目录- 新进程通过引用该目录启动。
命令 shell - 此可选字段表示成功登录系统后要启动的默认 shell。
数字取证包括收集与跟踪证据相关的信息。因此,用户 ID 对于维护记录很有用。
使用Python,所有这些信息都可以自动分析为分析指标,从而重建最近的系统活动。通过 Linux Shell 的实现,跟踪变得简单又容易。
使用 Linux 进行 Python 编程
例子
import sys
import hashlib
import getpass
def main(argv):
print '\nUser & Password Storage Program in Linux for forensic detection v.01\n'
if raw_input('The file ' + sys.argv[1] + ' will be erased or overwrite if
it exists .\nDo you wish to continue (Y/n): ') not in ('Y','y') :
sys.exit('\nChanges were not recorded\n')
user_name = raw_input('Please Enter a User Name: ')
password = hashlib.sha224(getpass.getpass('Please Enter a Password:')).hexdigest()
# Passwords which are hashed
try:
file_conn = open(sys.argv[1],'w')
file_conn.write(user_name + '\n')
file_conn.write(password + '\n')
file_conn.close()
except:
sys.exit('There was a problem writing the passwords to file!')
if __name__ == "__main__":
main(sys.argv[1:])
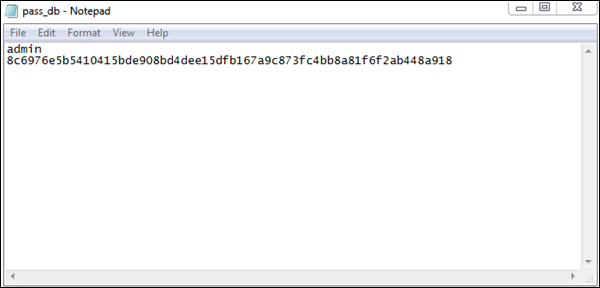
输出
密码以十六进制格式存储在pass_db.txt中,如下图所示。保存文本文件以供计算取证进一步使用。
Python 取证 - 妥协指标
妥协指标 (IOC) 被定义为“取证数据片段,其中包括系统日志条目或文件中发现的数据,可识别系统或网络上的潜在恶意活动。”
通过监控 IOC,组织可以检测攻击并迅速采取行动,以防止此类违规Behave的发生,或通过在早期阶段阻止攻击来限制损失。
有一些用例允许查询取证工件,例如 -
- 通过MD5查找特定文件
- 搜索实际存储在内存中的特定实体
- 存储在 Windows 注册表中的特定条目或条目集
上述所有内容的组合为搜索工件提供了更好的结果。如上所述,Windows注册表为生成和维护IOC提供了一个完美的平台,这直接有助于计算取证。
方法
查找文件系统中的位置,特别是现在查找 Windows 注册表中的位置。
搜索由取证工具设计的一组文物。
寻找任何不良活动的迹象。
调查生命周期
调查生命周期遵循 IOC,并在注册表中搜索特定条目。
第 1 阶段:初始证据- 在主机或网络上检测到妥协的证据。响应人员将调查并确定确切的解决方案,这是一个具体的取证指标。
第 2 阶段:为主机和网络创建 IOC - 收集数据后,创建 IOC,这可以通过 Windows 注册表轻松实现。OpenIOC 的灵活性为如何制作指标提供了无限数量的排列。
第 3 阶段:在企业中部署 IOC - 创建指定的 IOC 后,调查人员将借助 Windows 寄存器中的 API 来部署这些技术。
第 4 阶段:嫌疑人识别- IOC 的部署有助于以正常方式识别嫌疑人。甚至还将确定其他系统。
第五阶段:收集和分析证据- 收集并分析针对嫌疑人的证据。
第 6 阶段:完善和创建新的 IOC - 调查团队可以根据在企业中发现的证据和数据以及其他情报来创建新的 IOC,并继续完善其周期。
下图显示了调查生命周期的各个阶段 -

Python 取证 - 云的实现
云计算可以定义为通过互联网向用户提供的托管服务的集合。它使组织能够使用甚至计算资源,其中包括虚拟机 (VM)、存储或作为实用程序的应用程序。
使用 Python 编程语言构建应用程序的最重要优势之一是它能够在任何平台(包括云)上虚拟部署应用程序。这意味着Python可以在云服务器上执行,也可以在台式机、平板电脑或智能手机等便捷设备上启动。
有趣的观点之一是通过生成Rainbow 表来创建云基础。它有助于集成应用程序的单处理版本和多处理版本,这需要一些考虑。
圆周率云
Pi Cloud 是一个云计算平台,它将 Python 编程语言与 Amazon Web Services 的计算能力集成在一起。
让我们看一下使用彩虹表实现 Pi 云的示例。
彩虹桌
彩虹表被定义为特定于给定哈希算法的加密密码的所有可能的纯文本排列的列表。
彩虹表遵循标准模式,创建哈希密码列表。
文本文件用于生成密码,其中包括需要加密的字符或明文密码。
该文件由Pi cloud使用,调用main函数进行存储。
哈希密码的输出也存储在文本文件中。
该算法也可用于将密码保存在数据库中,并在云系统中进行备份存储。
以下内置程序在文本文件中创建加密密码列表。
例子
import os
import random
import hashlib
import string
import enchant #Rainbow tables with enchant
import cloud #importing pi-cloud
def randomword(length):
return ''.join(random.choice(string.lowercase) for i in range(length))
print('Author- Radhika Subramanian')
def mainroutine():
engdict = enchant.Dict("en_US")
fileb = open("password.txt","a+")
# Capture the values from the text file named password
while True:
randomword0 = randomword(6)
if engdict.check(randomword0) == True:
randomkey0 = randomword0+str(random.randint(0,99))
elif engdict.check(randomword0) == False:
englist = engdict.suggest(randomword0)
if len(englist) > 0:
randomkey0 = englist[0]+str(random.randint(0,99))
else:
randomkey0 = randomword0+str(random.randint(0,99))
randomword3 = randomword(5)
if engdict.check(randomword3) == True:
randomkey3 = randomword3+str(random.randint(0,99))
elif engdict.check(randomword3) == False:
englist = engdict.suggest(randomword3)
if len(englist) > 0:
randomkey3 = englist[0]+str(random.randint(0,99))
else:
randomkey3 = randomword3+str(random.randint(0,99))
if 'randomkey0' and 'randomkey3' and 'randomkey1' in locals():
whasher0 = hashlib.new("md5")
whasher0.update(randomkey0)
whasher3 = hashlib.new("md5")
whasher3.update(randomkey3)
whasher1 = hashlib.new("md5")
whasher1.update(randomkey1)
print(randomkey0+" + "+str(whasher0.hexdigest())+"\n")
print(randomkey3+" + "+str(whasher3.hexdigest())+"\n")
print(randomkey1+" + "+str(whasher1.hexdigest())+"\n")
fileb.write(randomkey0+" + "+str(whasher0.hexdigest())+"\n")
fileb.write(randomkey3+" + "+str(whasher3.hexdigest())+"\n")
fileb.write(randomkey1+" + "+str(whasher1.hexdigest())+"\n")
jid = cloud.call(randomword) #square(3) evaluated on PiCloud
cloud.result(jid)
print('Value added to cloud')
print('Password added')
mainroutine()
输出
该代码将产生以下输出 -
密码存储在可见的文本文件中,如以下屏幕截图所示。