- Scikit 学习教程
- Scikit Learn - 主页
- Scikit Learn - 简介
- Scikit Learn - 建模过程
- Scikit Learn - 数据表示
- Scikit Learn - 估计器 API
- Scikit Learn - 约定
- Scikit Learn - 线性建模
- Scikit Learn - 扩展线性建模
- 随机梯度下降
- Scikit Learn - 支持向量机
- Scikit Learn - 异常检测
- Scikit Learn - K 最近邻
- Scikit Learn - KNN 学习
- 使用朴素贝叶斯分类
- Scikit Learn - 决策树
- 随机决策树
- Scikit Learn - Boosting 方法
- Scikit Learn - 聚类方法
- 集群性能评估
- 使用 PCA 降维
- Scikit Learn 有用资源
- Scikit Learn - 快速指南
- Scikit Learn - 有用的资源
- Scikit Learn - 讨论
Scikit Learn - 估计器 API
在本章中,我们将学习Estimator API(应用程序编程接口)。让我们首先了解什么是 Estimator API。
什么是估算器 API
它是 Scikit-learn 实现的主要 API 之一。它为各种 ML 应用程序提供了一致的接口,这就是 Scikit-Learn 中的所有机器学习算法都是通过 Estimator API 实现的原因。从数据中学习(拟合数据)的对象是估计器。它可以与任何算法一起使用,例如分类、回归、聚类,甚至可以与变压器一起使用,从原始数据中提取有用的特征。
为了拟合数据,所有估计器对象都公开一个拟合方法,该方法采用如下所示的数据集 -
estimator.fit(data)
接下来,当通过相应的属性实例化估计器时,可以设置估计器的所有参数,如下所示。
estimator = Estimator (param1=1, param2=2) estimator.param1
上面的输出将为 1。
一旦数据与估计器相匹配,就可以根据手头的数据估计参数。现在,所有估计参数都将是以下划线结尾的估计器对象的属性,如下所示 -
estimator.estimated_param_
估算器 API 的使用
估计器的主要用途如下 -
模型的估计和解码
估计器对象用于模型的估计和解码。此外,该模型被估计为以下确定性函数 -
对象构造中提供的参数。
如果估计器的 random_state 参数设置为 none,则全局随机状态 (numpy.random)。
传递到最近一次调用fit、fit_transform 或 fit_predict 的任何数据。
在对partial_fit的一系列调用中传递的任何数据。
将非矩形数据表示映射到矩形数据
它将非矩形数据表示映射为矩形数据。简而言之,它接受输入,其中每个样本不表示为固定长度的类似数组的对象,并为每个样本生成类似数组的特征对象。
核心样本和外围样本之间的区别
它使用以下方法对核心样本和外围样本之间的区别进行建模 -
合身
fit_predict 如果是传导性的
预测是否有感性
指导原则
在设计 Scikit-Learn API 时,请牢记以下指导原则 -
一致性
该原则规定所有对象应该共享一个从有限的方法集得出的公共接口。文档也应该一致。
有限的对象层次结构
该指导原则说:
算法应该用Python类来表示
数据集应以标准格式表示,例如 NumPy 数组、Pandas DataFrames、SciPy 稀疏矩阵。
参数名称应使用标准 Python 字符串。
作品
众所周知,机器学习算法可以表示为许多基本算法的序列。Scikit-learn 在需要时会利用这些基本算法。
合理的默认值
根据这一原则,只要 ML 模型需要用户指定的参数,Scikit-learn 库就会定义适当的默认值。
检查
根据此指导原则,每个指定的参数值都作为公共属性公开。
使用 Estimator API 的步骤
以下是使用 Scikit-Learn 估计器 API 的步骤 -
第 1 步:选择模型类别
在第一步中,我们需要选择一类模型。这可以通过从 Scikit-learn 导入适当的 Estimator 类来完成。
步骤2:选择模型超参数
在这一步中,我们需要选择类模型超参数。这可以通过使用所需值实例化类来完成。
第三步:整理数据
接下来,我们需要将数据排列成特征矩阵(X)和目标向量(y)。
第四步:模型拟合
现在,我们需要使模型适合您的数据。可以通过调用模型实例的 fit() 方法来完成。
第 5 步:应用模型
拟合模型后,我们可以将其应用于新数据。对于监督学习,使用predict()方法来预测未知数据的标签。而对于无监督学习,使用predict()或transform()来推断数据的属性。
监督学习示例
在这里,作为此过程的示例,我们采用将直线拟合到 (x,y) 数据的常见情况,即简单线性回归。
首先,我们需要加载数据集,我们使用的是 iris 数据集 -
例子
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
输出
(150, 4)
例子
y_iris = iris['species'] y_iris.shape
输出
(150,)
例子
现在,对于这个回归示例,我们将使用以下示例数据 -
%matplotlib inline import matplotlib.pyplot as plt import numpy as np rng = np.random.RandomState(35) x = 10*rng.rand(40) y = 2*x-1+rng.randn(40) plt.scatter(x,y);
输出
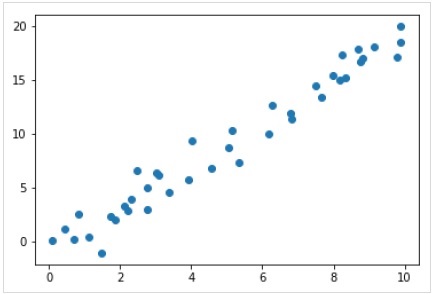
因此,我们的线性回归示例就有了上述数据。
现在,有了这些数据,我们就可以应用上述步骤了。
选择型号类别
在这里,为了计算一个简单的线性回归模型,我们需要导入线性回归类,如下所示 -
from sklearn.linear_model import LinearRegression
选择模型超参数
一旦我们选择了一类模型,我们就需要做出一些重要的选择,这些选择通常表示为超参数,或者在模型适合数据之前必须设置的参数。在这里,对于这个线性回归的示例,我们希望使用fit_intercept超参数来拟合截距,如下所示 -
例子
model = LinearRegression(fit_intercept = True) model
输出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)
整理数据
现在,我们知道目标变量y的形式正确,即长度为n_samples的一维数组。但是,我们需要重塑特征矩阵X,使其成为大小为[n_samples, n_features]的矩阵。可以按如下方式完成 -
例子
X = x[:, np.newaxis] X.shape
输出
(40, 1)
模型拟合
一旦我们安排了数据,就该拟合模型了,即将我们的模型应用到数据上。这可以借助fit()方法来完成,如下所示 -
例子
model.fit(X, y)
输出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)
在 Scikit-learn 中,fit()过程有一些尾随下划线。
对于此示例,以下参数显示了数据的简单线性拟合的斜率 -
例子
model.coef_
输出
array([1.99839352])
以下参数表示数据的简单线性拟合的截距 -
例子
model.intercept_
输出
-0.9895459457775022
将模型应用于新数据
训练模型后,我们可以将其应用到新数据中。由于监督机器学习的主要任务是基于不属于训练集的新数据来评估模型。可以借助Predict()方法来完成,如下所示 -
例子
xfit = np.linspace(-1, 11) Xfit = xfit[:, np.newaxis] yfit = model.predict(Xfit) plt.scatter(x, y) plt.plot(xfit, yfit);
输出
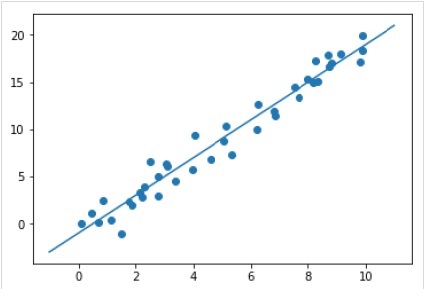
完整的工作/可执行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);
无监督学习示例
在这里,作为此过程的一个示例,我们采用降低 Iris 数据集维度的常见情况,以便我们可以更轻松地对其进行可视化。对于此示例,我们将使用主成分分析 (PCA),这是一种快速线性降维技术。
就像上面给出的示例一样,我们可以加载并绘制 iris 数据集中的随机数据。之后我们可以按照以下步骤操作 -
选择型号类别
from sklearn.decomposition import PCA
选择模型超参数
例子
model = PCA(n_components=2) model
输出
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None, svd_solver = 'auto', tol = 0.0, whiten = False)
模型拟合
例子
model.fit(X_iris)
输出
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None, svd_solver = 'auto', tol = 0.0, whiten = False)
将数据转换为二维
例子
X_2D = model.transform(X_iris)
现在,我们可以绘制结果如下 -
输出
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);
输出
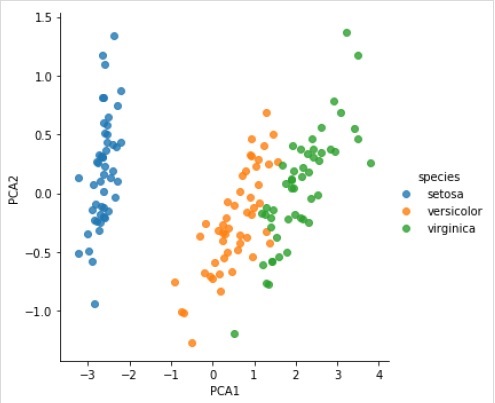
完整的工作/可执行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);