Weka - 数据预处理
从现场收集的数据包含许多不需要的东西,会导致错误的分析。例如,数据可能包含空字段,可能包含与当前分析无关的列,等等。因此,必须对数据进行预处理以满足您正在寻求的分析类型的要求。这是在预处理模块中完成的。
为了演示预处理中的可用功能,我们将使用安装中提供的天气数据库。
使用预处理标签下的打开文件...选项选择weather-nominal.arff文件。
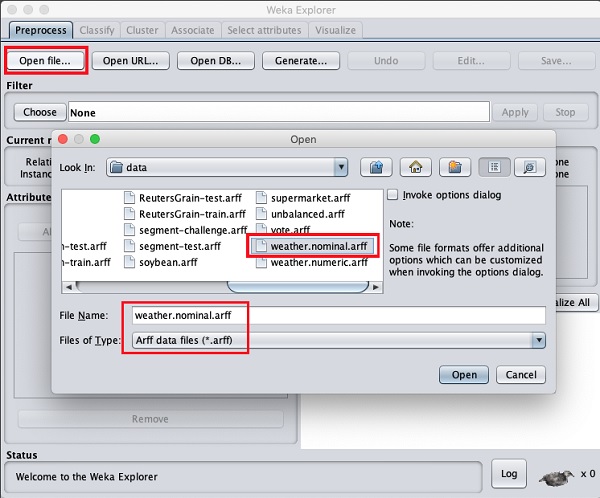
当您打开文件时,您的屏幕如下所示 -
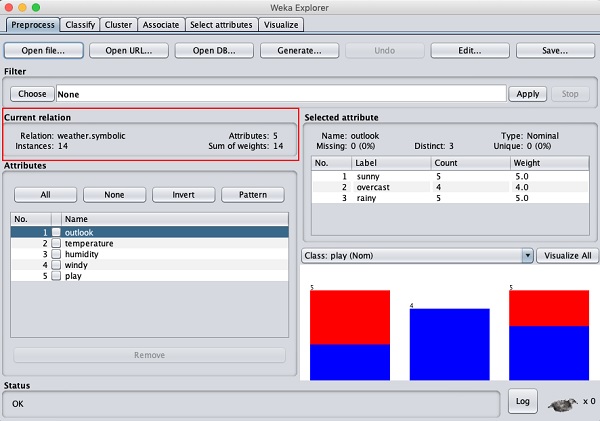
该屏幕告诉我们有关加载数据的一些信息,本章将进一步讨论这些信息。
了解数据
让我们首先看一下突出显示的当前关系子窗口。它显示当前加载的数据库的名称。您可以从这个子窗口推断出两点 -
有 14 个实例 - 表中的行数。
该表包含 5 个属性 - 字段,这些属性将在接下来的部分中讨论。
请注意左侧的“属性”子窗口,其中显示数据库中的各个字段。
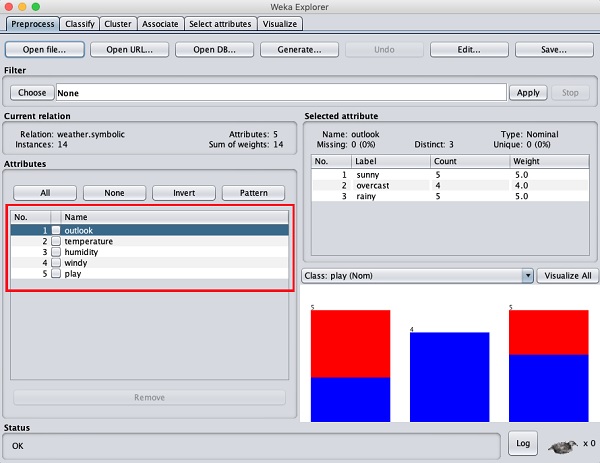
天气数据库包含五个字段 - 展望、温度、湿度、刮风和玩耍。当您通过单击从此列表中选择一个属性时,该属性本身的更多详细信息将显示在右侧。
让我们首先选择温度属性。当您点击它时,您将看到以下屏幕 -
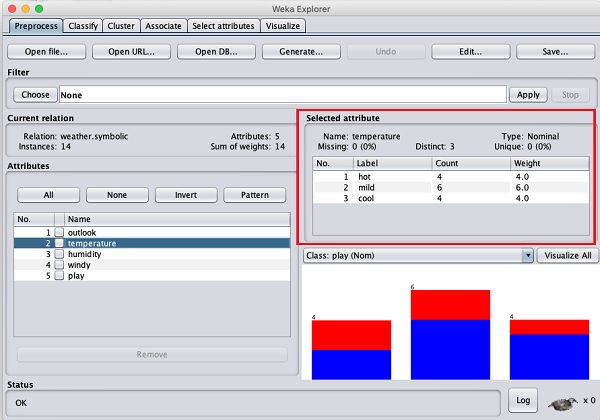
在“选定属性”子窗口中,您可以观察到以下内容 -
显示属性的名称和类型。
温度属性的类型是Nominal。
缺失值的数量为零。
存在三个不同的值,没有唯一的值。
该信息下面的表格显示了该字段的标称值(热、温和和冷)。
它还以每个标称值的百分比形式显示数量和重量。
在窗口底部,您可以看到类值的直观表示。
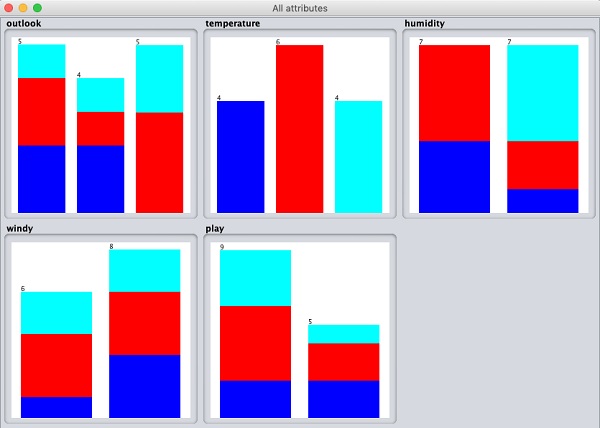
如果单击“全部可视化”按钮,您将能够在一个窗口中看到所有功能,如下所示 -
删除属性
很多时候,您想要用于模型构建的数据带有许多不相关的字段。例如,客户数据库可能包含与分析他的信用评级相关的他的手机号码。
要删除属性,请选择它们并单击底部的“删除”按钮。
选定的属性将从数据库中删除。完全预处理数据后,您可以将其保存以用于模型构建。
接下来,您将学习通过对数据应用过滤器来预处理数据。
应用过滤器
一些机器学习技术(例如关联规则挖掘)需要分类数据。为了说明过滤器的使用,我们将使用包含两个数字属性 -温度和湿度的 Weather-numeric.arff数据库。
我们将通过对原始数据应用过滤器将它们转换为名义值。单击“过滤器”子窗口中的“选择”按钮,然后选择以下过滤器 -
weka→过滤器→监督→属性→离散化
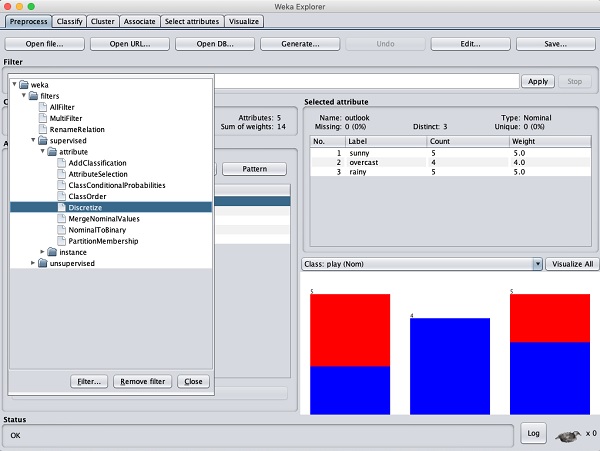
单击“应用”按钮并检查温度和/或湿度属性。您会注意到这些已从数字类型更改为名义类型。
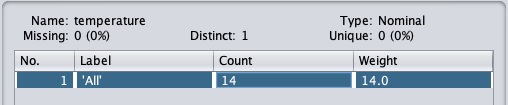
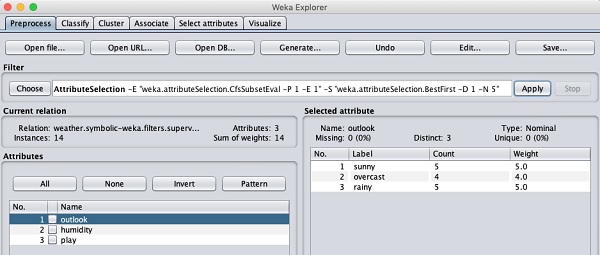
现在让我们看看另一个过滤器。假设您想要选择最佳属性来决定比赛。选择并应用以下过滤器 -
weka→过滤器→监督→属性→属性选择
您会注意到它从数据库中删除了温度和湿度属性。
对数据预处理感到满意后,单击“保存...”按钮保存数据。您将使用此保存的文件来构建模型。
在下一章中,我们将探索使用几种预定义的机器学习算法构建模型。