- NumPy 教程
- NumPy - 主页
- NumPy - 简介
- NumPy - 环境
- NumPy - Ndarray 对象
- NumPy - 数据类型
- NumPy - 数组属性
- NumPy - 数组创建例程
- NumPy - 来自现有数据的数组
- 来自数值范围的数组
- NumPy - 索引和切片
- NumPy - 高级索引
- NumPy - 广播
- NumPy - 迭代数组
- NumPy - 数组操作
- NumPy - 二元运算符
- NumPy - 字符串函数
- NumPy - 数学函数
- NumPy - 算术运算
- NumPy - 统计函数
- 排序、搜索和计数功能
- NumPy - 字节交换
- NumPy - 副本和视图
- NumPy - 矩阵库
- NumPy - 线性代数
- NumPy-Matplotlib
- NumPy - 使用 Matplotlib 绘制直方图
- NumPy - 使用 NumPy 进行 I/O
- NumPy 有用资源
- NumPy - 快速指南
- NumPy - 有用的资源
- NumPy - 讨论
NumPy - 快速指南
NumPy - 简介
NumPy 是一个 Python 包。它代表“数字Python”。它是一个由多维数组对象和数组处理例程集合组成的库。
Numeric是 NumPy 的祖先,由 Jim Hugunin 开发。还开发了另一个软件包 Numarray,具有一些附加功能。2005 年,Travis Oliphant 将 Numarray 的功能合并到 Numeric 包中,创建了 NumPy 包。这个开源项目有很多贡献者。
使用 NumPy 进行运算
使用 NumPy,开发人员可以执行以下操作 -
数组的数学和逻辑运算。
傅里叶变换和形状操作例程。
与线性代数相关的运算。NumPy 具有用于线性代数和随机数生成的内置函数。
NumPy – MatLab 的替代品
NumPy 通常与SciPy(科学 Python)和Mat−plotlib(绘图库)等软件包一起使用。这种组合被广泛用作 MatLab(一种流行的技术计算平台)的替代品。然而,Python 替代 MatLab 现在被视为一种更现代、更完整的编程语言。
它是开源的,这是 NumPy 的另一个优势。
NumPy - 环境
标准 Python 发行版不与 NumPy 模块捆绑在一起。一种轻量级的替代方案是使用流行的 Python 包安装程序pip安装 NumPy 。
pip install numpy
启用 NumPy 的最佳方法是使用特定于您的操作系统的可安装二进制包。这些二进制文件包含完整的SciPy堆栈(包括NumPy、SciPy、matplotlib、IPython、SymPy和nose包以及核心Python)。
Windows
Anaconda(来自https://www.continuum.io)是 SciPy 堆栈的免费 Python 发行版。它还适用于 Linux 和 Mac。
Canopy ( https://www.enthought.com/products/canopy/ ) 既可以免费提供,也可以作为商业发行版提供,具有适用于 Windows、Linux 和 Mac 的完整 SciPy 堆栈。
Python (x,y):它是一个免费的 Python 发行版,带有适用于 Windows 操作系统的 SciPy 堆栈和 Spyder IDE。(可从https://www.python-xy.github.io/下载)
Linux
各个 Linux 发行版的包管理器用于在 SciPy 堆栈中安装一个或多个包。
对于Ubuntu
sudo apt-get install python-numpy python-scipy python-matplotlibipythonipythonnotebook python-pandas python-sympy python-nose
对于软呢帽
sudo yum install numpyscipy python-matplotlibipython python-pandas sympy python-nose atlas-devel
从源头构建
核心 Python(2.6.x、2.7.x 和 3.2.x 及以上)必须使用 distutils 安装,并且应启用 zlib 模块。
GNU gcc(4.2 及更高版本)C 编译器必须可用。
要安装 NumPy,请运行以下命令。
Python setup.py install
要测试 NumPy 模块是否正确安装,请尝试从 Python 提示符导入它。
import numpy
如果未安装,将显示以下错误消息。
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
import numpy
ImportError: No module named 'numpy'
或者,使用以下语法导入 NumPy 包 -
import numpy as np
NumPy - Ndarray 对象
NumPy 中定义的最重要的对象是称为ndarray 的N 维数组类型。它描述了相同类型的项目的集合。可以使用从零开始的索引来访问集合中的项目。
ndarray 中的每个项目在内存中占用相同大小的块。ndarray 中的每个元素都是数据类型对象(称为dtype )的对象。
从 ndarray 对象(通过切片)提取的任何项目都由数组标量类型之一的 Python 对象表示。下图显示了 ndarray、数据类型对象 (dtype) 和数组标量类型之间的关系 -
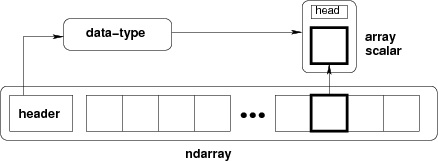
ndarray 类的实例可以通过本教程后面描述的不同数组创建例程来构造。基本 ndarray 是使用 NumPy 中的数组函数创建的,如下所示 -
numpy.array
它从任何公开数组接口的对象或任何返回数组的方法创建一个 ndarray。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
上面的构造函数采用以下参数 -
| 先生。 | 参数及说明 |
|---|---|
| 1 | 目的 公开数组接口方法的任何对象都会返回数组或任何(嵌套)序列。 |
| 2 | 数据类型 所需的数组数据类型,可选 |
| 3 | 复制 选修的。默认情况下(true),对象被复制 |
| 4 | 命令 C(行专业)或 F(列专业)或 A(任意)(默认) |
| 5 | 苏博克 默认情况下,返回的数组强制为基类数组。如果为 true,则子类通过 |
| 6 | 最小 指定结果数组的最小尺寸 |
请看以下示例以更好地理解。
实施例1
import numpy as np a = np.array([1,2,3]) print a
输出如下 -
[1, 2, 3]
实施例2
# more than one dimensions import numpy as np a = np.array([[1, 2], [3, 4]]) print a
输出如下 -
[[1, 2] [3, 4]]
实施例3
# minimum dimensions import numpy as np a = np.array([1, 2, 3,4,5], ndmin = 2) print a
输出如下 -
[[1, 2, 3, 4, 5]]
实施例4
# dtype parameter import numpy as np a = np.array([1, 2, 3], dtype = complex) print a
输出如下 -
[ 1.+0.j, 2.+0.j, 3.+0.j]
ndarray对象由计算机内存的连续一维段组成,并结合将每个项目映射到内存块中的位置的索引方案。内存块以行优先顺序(C 风格)或列优先顺序(FORTRAN 或 MatLab 风格)保存元素。
NumPy - 数据类型
NumPy 比 Python 支持更多种类的数值类型。下表显示了 NumPy 中定义的不同标量数据类型。
| 先生。 | 数据类型和描述 |
|---|---|
| 1 | 布尔_ 布尔值(True 或 False)存储为字节 |
| 2 | 整数_ 默认整数类型(与 C long 相同;通常为 int64 或 int32) |
| 3 | 国际委员会 与 C int 相同(通常为 int32 或 int64) |
| 4 | INTP 用于索引的整数(与 C ssize_t 相同;通常为 int32 或 int64) |
| 5 | 整型8 字节(-128 到 127) |
| 6 | 整型16 整数(-32768 至 32767) |
| 7 | 整型32 整数(-2147483648 至 2147483647) |
| 8 | 整型64 整数(-9223372036854775808 至 9223372036854775807) |
| 9 | uint8 无符号整数(0 到 255) |
| 10 | uint16 无符号整数(0 到 65535) |
| 11 | uint32 无符号整数(0 到 4294967295) |
| 12 | uint64 无符号整数(0 到 18446744073709551615) |
| 13 | 漂浮_ float64 的简写 |
| 14 | 浮动16 半精度浮点数:符号位,5位指数,10位尾数 |
| 15 | 浮动32 单精度浮点数:符号位、8位指数、23位尾数 |
| 16 | 浮动64 双精度浮点数:符号位、11 位指数、52 位尾数 |
| 17 号 | 复杂的_ Complex128 的简写 |
| 18 | 复杂64 复数,由两个 32 位浮点数(实部和虚部)表示 |
| 19 | 复杂128 复数,由两个 64 位浮点数(实部和虚部)表示 |
NumPy 数值类型是 dtype(数据类型)对象的实例,每个对象都具有独特的特征。数据类型可用作 np.bool_、np.float32 等。
数据类型对象(dtype)
数据类型对象描述了与数组对应的固定内存块的解释,具体取决于以下方面 -
数据类型(整数、浮点或 Python 对象)
数据大小
字节顺序(小端或大端)
如果是结构化类型,则为字段名称、每个字段的数据类型以及每个字段占用的内存块的一部分。
如果数据类型是子数组,则其形状和数据类型
字节顺序由数据类型前缀“<”或“>”决定。'<' 表示编码是小尾数法(最低有效位存储在最小地址中)。'>' 表示编码是大端字节序(最高有效字节存储在最小地址中)。
dtype 对象是使用以下语法构造的 -
numpy.dtype(object, align, copy)
参数是 -
对象- 转换为数据类型对象
Align - 如果为 true,则向字段添加填充以使其类似于 C 结构
复制- 制作 dtype 对象的新副本。如果为 false,则结果是对内置数据类型对象的引用
实施例1
# using array-scalar type import numpy as np dt = np.dtype(np.int32) print dt
输出如下 -
int32
实施例2
#int8, int16, int32, int64 can be replaced by equivalent string 'i1', 'i2','i4', etc.
import numpy as np
dt = np.dtype('i4')
print dt
输出如下 -
int32
实施例3
# using endian notation
import numpy as np
dt = np.dtype('>i4')
print dt
输出如下 -
>i4
以下示例展示了结构化数据类型的使用。这里,要声明字段名称和相应的标量数据类型。
实施例4
# first create structured data type
import numpy as np
dt = np.dtype([('age',np.int8)])
print dt
输出如下 -
[('age', 'i1')]
实施例5
# now apply it to ndarray object
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print a
输出如下 -
[(10,) (20,) (30,)]
实施例6
# file name can be used to access content of age column
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print a['age']
输出如下 -
[10 20 30]
实施例7
以下示例定义了一个名为Student 的结构化数据类型,其中包含字符串字段“name”、整数字段“age”和浮点字段“marks”。此 dtype 应用于 ndarray 对象。
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print student
输出如下 -
[('name', 'S20'), ('age', 'i1'), ('marks', '<f4')])
实施例8
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print a
输出如下 -
[('abc', 21, 50.0), ('xyz', 18, 75.0)]
每个内置数据类型都有一个唯一标识它的字符代码。
'b' - 布尔值
'i' - (有符号)整数
'u' - 无符号整数
'f' - 浮点数
'c' - 复数浮点
'm' - 时间增量
'M' - 日期时间
'O' - (Python) 对象
'S', 'a' - (字节)字符串
'U' - 统一码
'V' - 原始数据(无效)
NumPy - 数组属性
在本章中,我们将讨论 NumPy 的各种数组属性。
ndarray.shape
此数组属性返回一个由数组维度组成的元组。它还可以用于调整数组的大小。
实施例1
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print a.shape
输出如下 -
(2, 3)
实施例2
# this resizes the ndarray import numpy as np a = np.array([[1,2,3],[4,5,6]]) a.shape = (3,2) print a
输出如下 -
[[1, 2] [3, 4] [5, 6]]
实施例3
NumPy 还提供了一个 reshape 函数来调整数组的大小。
import numpy as np a = np.array([[1,2,3],[4,5,6]]) b = a.reshape(3,2) print b
输出如下 -
[[1, 2] [3, 4] [5, 6]]
ndarray.ndim
此数组属性返回数组维数。
实施例1
# an array of evenly spaced numbers import numpy as np a = np.arange(24) print a
输出如下 -
[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
实施例2
# this is one dimensional array import numpy as np a = np.arange(24) a.ndim # now reshape it b = a.reshape(2,4,3) print b # b is having three dimensions
输出如下 -
[[[ 0, 1, 2] [ 3, 4, 5] [ 6, 7, 8] [ 9, 10, 11]] [[12, 13, 14] [15, 16, 17] [18, 19, 20] [21, 22, 23]]]
numpy.itemsize
此数组属性返回数组每个元素的长度(以字节为单位)。
实施例1
# dtype of array is int8 (1 byte) import numpy as np x = np.array([1,2,3,4,5], dtype = np.int8) print x.itemsize
输出如下 -
1
实施例2
# dtype of array is now float32 (4 bytes) import numpy as np x = np.array([1,2,3,4,5], dtype = np.float32) print x.itemsize
输出如下 -
4
numpy.flags
ndarray 对象具有以下属性。该函数返回其当前值。
| 先生。 | 属性及描述 |
|---|---|
| 1 | C_连续 (C) 数据位于单个 C 风格的连续段中 |
| 2 | F_连续 (F) 数据位于单个 Fortran 风格的连续段中 |
| 3 | 自有数据 (O) 数组拥有它使用的内存或从另一个对象借用内存 |
| 4 | 可写(W) 数据区可写入。将其设置为 False 会锁定数据,使其只读 |
| 5 | 对齐 (A) 数据和所有元素都针对硬件进行适当对齐 |
| 6 | 更新复制 (U) 该数组是其他数组的副本。当该数组被释放时,基数组将被更新为该数组的内容 |
例子
以下示例显示了标志的当前值。
import numpy as np x = np.array([1,2,3,4,5]) print x.flags
输出如下 -
C_CONTIGUOUS : True F_CONTIGUOUS : True OWNDATA : True WRITEABLE : True ALIGNED : True UPDATEIFCOPY : False
NumPy - 数组创建例程
新的ndarray对象可以通过以下任何数组创建例程或使用低级 ndarray 构造函数来构造。
numpy.empty
它创建指定形状和数据类型的未初始化数组。它使用以下构造函数 -
numpy.empty(shape, dtype = float, order = 'C')
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 形状 int 或 int 元组中的空数组的形状 |
| 2 | 数据类型 所需的输出数据类型。选修的 |
| 3 | 命令 'C' 表示 C 样式行优先数组,'F' 表示 FORTRAN 样式列优先数组 |
例子
以下代码显示了空数组的示例。
import numpy as np x = np.empty([3,2], dtype = int) print x
输出如下 -
[[22649312 1701344351] [1818321759 1885959276] [16779776 156368896]]
注意- 数组中的元素显示随机值,因为它们未初始化。
numpy.zeros
返回指定大小的新数组,并用零填充。
numpy.zeros(shape, dtype = float, order = 'C')
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 形状 int 或 int 序列中的空数组的形状 |
| 2 | 数据类型 所需的输出数据类型。选修的 |
| 3 | 命令 'C' 表示 C 样式行优先数组,'F' 表示 FORTRAN 样式列优先数组 |
实施例1
# array of five zeros. Default dtype is float import numpy as np x = np.zeros(5) print x
输出如下 -
[ 0. 0. 0. 0. 0.]
实施例2
import numpy as np x = np.zeros((5,), dtype = np.int) print x
现在,输出如下 -
[0 0 0 0 0]
实施例3
# custom type
import numpy as np
x = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])
print x
它应该产生以下输出 -
[[(0,0)(0,0)] [(0,0)(0,0)]]
numpy.ones
返回指定大小和类型的新数组,并用 1 填充。
numpy.ones(shape, dtype = None, order = 'C')
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 形状 int 或 int 元组中的空数组的形状 |
| 2 | 数据类型 所需的输出数据类型。选修的 |
| 3 | 命令 'C' 表示 C 样式行优先数组,'F' 表示 FORTRAN 样式列优先数组 |
实施例1
# array of five ones. Default dtype is float import numpy as np x = np.ones(5) print x
输出如下 -
[ 1. 1. 1. 1. 1.]
实施例2
import numpy as np x = np.ones([2,2], dtype = int) print x
现在,输出如下 -
[[1 1] [1 1]]
NumPy - 来自现有数据的数组
在本章中,我们将讨论如何从现有数据创建数组。
numpy.asarray
该函数与 numpy.array 类似,只是参数较少。此例程对于将 Python 序列转换为 ndarray 很有用。
numpy.asarray(a, dtype = None, order = None)
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | A 以任何形式输入数据,例如列表、元组列表、元组、元组的元组或列表的元组 |
| 2 | 数据类型 默认情况下,输入数据的数据类型应用于结果 ndarray |
| 3 | 命令 C(行专业)或 F(列专业)。C为默认值 |
以下示例展示了如何使用asarray函数。
实施例1
# convert list to ndarray import numpy as np x = [1,2,3] a = np.asarray(x) print a
其输出如下 -
[1 2 3]
实施例2
# dtype is set import numpy as np x = [1,2,3] a = np.asarray(x, dtype = float) print a
现在,输出如下 -
[ 1. 2. 3.]
实施例3
# ndarray from tuple import numpy as np x = (1,2,3) a = np.asarray(x) print a
它的输出将是 -
[1 2 3]
实施例4
# ndarray from list of tuples import numpy as np x = [(1,2,3),(4,5)] a = np.asarray(x) print a
在这里,输出如下 -
[(1, 2, 3) (4, 5)]
numpy.frombuffer
该函数将缓冲区解释为一维数组。任何公开缓冲区接口的对象都用作返回ndarray的参数。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 缓冲 任何公开缓冲区接口的对象 |
| 2 | 数据类型 返回的 ndarray 的数据类型。默认为浮动 |
| 3 | 数数 读取的条数,默认-1表示所有数据 |
| 4 | 抵消 读取的起始位置。默认值为 0 |
例子
以下示例演示了frombuffer函数的使用。
import numpy as np s = 'Hello World' a = np.frombuffer(s, dtype = 'S1') print a
这是它的输出 -
['H' 'e' 'l' 'l' 'o' ' ' 'W' 'o' 'r' 'l' 'd']
numpy.fromiter
此函数从任何可迭代对象构建ndarray对象。该函数返回一个新的一维数组。
numpy.fromiter(iterable, dtype, count = -1)
这里,构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 可迭代的 任何可迭代对象 |
| 2 | 数据类型 结果数组的数据类型 |
| 3 | 数数 要从迭代器读取的项目数。默认为-1,表示读取所有数据 |
以下示例演示如何使用内置range()函数返回列表对象。该列表的迭代器用于形成ndarray对象。
实施例1
# create list object using range function import numpy as np list = range(5) print list
其输出如下 -
[0, 1, 2, 3, 4]
实施例2
# obtain iterator object from list import numpy as np list = range(5) it = iter(list) # use iterator to create ndarray x = np.fromiter(it, dtype = float) print x
现在,输出如下 -
[0. 1. 2. 3. 4.]
NumPy - 数值范围的数组
在本章中,我们将了解如何从数值范围创建数组。
numpy.arange
此函数返回一个ndarray对象,其中包含给定范围内均匀间隔的值。函数的格式如下 -
numpy.arange(start, stop, step, dtype)
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 开始 间隔的开始。如果省略,则默认为 0 |
| 2 | 停止 间隔结束(不包括该数字) |
| 3 | 步 值之间的间距,默认为 1 |
| 4 | 数据类型 生成的 ndarray 的数据类型。如果未给出,则使用输入的数据类型 |
以下示例展示了如何使用此功能。
实施例1
import numpy as np x = np.arange(5) print x
其输出如下 -
[0 1 2 3 4]
实施例2
import numpy as np # dtype set x = np.arange(5, dtype = float) print x
在这里,输出将是 -
[0. 1. 2. 3. 4.]
实施例3
# start and stop parameters set import numpy as np x = np.arange(10,20,2) print x
其输出如下 -
[10 12 14 16 18]
numpy.linspace
该函数与arange()函数类似。在此函数中,指定了间隔之间均匀分布的值的数量,而不是步长。该函数的用法如下 -
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
构造函数采用以下参数。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 开始 序列的起始值 |
| 2 | 停止 序列的结束值,如果端点设置为 true,则包含在序列中 |
| 3 | 编号 要生成的均匀间隔样本的数量。默认值为 50 |
| 4 | 终点 默认情况下为 True,因此停止值包含在序列中。如果为 false,则不包含在内 |
| 5 | 重步 如果为 true,则返回样本并在连续数字之间步进 |
| 6 | 数据类型 输出ndarray的数据类型 |
以下示例演示了linspace函数的使用。
实施例1
import numpy as np x = np.linspace(10,20,5) print x
它的输出将是 -
[10. 12.5 15. 17.5 20.]
实施例2
# endpoint set to false import numpy as np x = np.linspace(10,20, 5, endpoint = False) print x
输出将是 -
[10. 12. 14. 16. 18.]
实施例3
# find retstep value import numpy as np x = np.linspace(1,2,5, retstep = True) print x # retstep here is 0.25
现在,输出将是 -
(array([ 1. , 1.25, 1.5 , 1.75, 2. ]), 0.25)
numpy.logspace
此函数返回一个ndarray对象,其中包含在对数刻度上均匀分布的数字。刻度的起始和终止端点是基数的索引,通常为 10。
numpy.logspace(start, stop, num, endpoint, base, dtype)
以下参数确定logspace函数的输出。
| 先生。 | 参数及说明 |
|---|---|
| 1 | 开始 序列的起点是碱基起始点 |
| 2 | 停止 序列的最终值为base stop |
| 3 | 编号 范围之间的值的数量。默认值为 50 |
| 4 | 终点 如果为 true,则 stop 是范围中的最后一个值 |
| 5 | 根据 日志空间的基数,默认为10 |
| 6 | 数据类型 输出数组的数据类型。如果没有给出,则取决于其他输入参数 |
以下示例将帮助您了解logspace功能。
实施例1
import numpy as np # default base is 10 a = np.logspace(1.0, 2.0, num = 10) print a
其输出如下 -
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402 35.93813664 46.41588834 59.94842503 77.42636827 100. ]
实施例2
# set base of log space to 2 import numpy as np a = np.logspace(1,10,num = 10, base = 2) print a
现在,输出将是 -
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
NumPy - 索引和切片
ndarray对象的内容可以通过索引或切片来访问和修改,就像Python内置的容器对象一样。
如前所述,ndarray 对象中的项目遵循从零开始的索引。提供三种类型的索引方法:字段访问、基本切片和高级索引。
基本切片是 Python 的 n 维切片基本概念的扩展。Python 切片对象是通过向内置切片函数提供start、stop和step参数来构造的。该切片对象被传递到数组以提取数组的一部分。
实施例1
import numpy as np a = np.arange(10) s = slice(2,7,2) print a[s]
其输出如下 -
[2 4 6]
在上面的例子中,一个ndarray对象是由arange()函数准备的。然后定义一个切片对象,其开始、停止和步长值分别为 2、7 和 2。当这个切片对象被传递到 ndarray 时,它的一部分从索引 2 开始到 7,步长为 2 被切片。
通过将用冒号 : (start:stop:step) 分隔的切片参数直接赋予ndarray对象也可以获得相同的结果。
实施例2
import numpy as np a = np.arange(10) b = a[2:7:2] print b
在这里,我们将得到相同的输出 -
[2 4 6]
如果只输入一个参数,则将返回与索引对应的单个项目。如果在其前面插入 :,则将从该索引开始的所有项目都将被提取。如果使用两个参数(它们之间有 : ),则默认步骤一的两个索引之间的项目(不包括停止索引)将被切片。
实施例3
# slice single item import numpy as np a = np.arange(10) b = a[5] print b
其输出如下 -
5
实施例4
# slice items starting from index import numpy as np a = np.arange(10) print a[2:]
现在,输出将是 -
[2 3 4 5 6 7 8 9]
实施例5
# slice items between indexes import numpy as np a = np.arange(10) print a[2:5]
在这里,输出将是 -
[2 3 4]
上述描述也适用于多维ndarray。
实施例6
import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print a # slice items starting from index print 'Now we will slice the array from the index a[1:]' print a[1:]
输出如下 -
[[1 2 3] [3 4 5] [4 5 6]] Now we will slice the array from the index a[1:] [[3 4 5] [4 5 6]]
切片还可以包含省略号 (...) 以生成与数组维度长度相同的选择元组。如果在行位置使用省略号,它将返回一个由行中的项目组成的 ndarray。
实施例7
# array to begin with import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print 'Our array is:' print a print '\n' # this returns array of items in the second column print 'The items in the second column are:' print a[...,1] print '\n' # Now we will slice all items from the second row print 'The items in the second row are:' print a[1,...] print '\n' # Now we will slice all items from column 1 onwards print 'The items column 1 onwards are:' print a[...,1:]
该程序的输出如下 -
Our array is: [[1 2 3] [3 4 5] [4 5 6]] The items in the second column are: [2 4 5] The items in the second row are: [3 4 5] The items column 1 onwards are: [[2 3] [4 5] [5 6]]
NumPy - 高级索引
可以从非元组序列、整数或布尔数据类型的 ndarray 对象或至少有一项是序列对象的元组中进行选择。高级索引始终返回数据的副本。与此相反,切片仅呈现一个视图。
有两种类型的高级索引 - Integer和Boolean。
整数索引
此机制有助于根据 N 维索引选择数组中的任意项目。每个整数数组表示该维度的索引数。当索引由与目标 ndarray 的维度一样多的整数数组组成时,它就变得简单了。
在以下示例中,从 ndarray 对象的每一行中选择指定列的一个元素。因此,行索引包含所有行号,列索引指定要选择的元素。
实施例1
import numpy as np x = np.array([[1, 2], [3, 4], [5, 6]]) y = x[[0,1,2], [0,1,0]] print y
其输出如下 -
[1 4 5]
该选择包括第一个数组中 (0,0)、(1,1) 和 (2,0) 处的元素。
在以下示例中,选择放置在 4X3 阵列角上的元素。选择的行索引为 [0, 0] 和 [3,3],而列索引为 [0,2] 和 [0,2]。
实施例2
import numpy as np x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) print 'Our array is:' print x print '\n' rows = np.array([[0,0],[3,3]]) cols = np.array([[0,2],[0,2]]) y = x[rows,cols] print 'The corner elements of this array are:' print y
该程序的输出如下 -
Our array is: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] The corner elements of this array are: [[ 0 2] [ 9 11]]
结果选择是一个包含角元素的 ndarray 对象。
高级索引和基本索引可以通过使用一个切片 (:) 或省略号 (…) 与索引数组来组合。以下示例对行使用切片,对列使用高级索引。当切片同时用于两者时,结果是相同的。但高级索引会导致复制,并且可能具有不同的内存布局。
实施例3
import numpy as np x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) print 'Our array is:' print x print '\n' # slicing z = x[1:4,1:3] print 'After slicing, our array becomes:' print z print '\n' # using advanced index for column y = x[1:4,[1,2]] print 'Slicing using advanced index for column:' print y
该程序的输出如下 -
Our array is: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] After slicing, our array becomes: [[ 4 5] [ 7 8] [10 11]] Slicing using advanced index for column: [[ 4 5] [ 7 8] [10 11]]
布尔数组索引
当生成的对象是布尔运算(例如比较运算符)的结果时,使用这种类型的高级索引。
实施例1
在此示例中,大于 5 的项目将作为布尔索引的结果返回。
import numpy as np x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) print 'Our array is:' print x print '\n' # Now we will print the items greater than 5 print 'The items greater than 5 are:' print x[x > 5]
该程序的输出将是 -
Our array is: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] The items greater than 5 are: [ 6 7 8 9 10 11]
实施例2
在此示例中,使用 ~(补码运算符)省略 NaN(非数字)元素。
import numpy as np a = np.array([np.nan, 1,2,np.nan,3,4,5]) print a[~np.isnan(a)]
它的输出将是 -
[ 1. 2. 3. 4. 5.]
实施例3
以下示例演示如何从数组中过滤掉非复杂元素。
import numpy as np a = np.array([1, 2+6j, 5, 3.5+5j]) print a[np.iscomplex(a)]
这里,输出如下 -
[2.0+6.j 3.5+5.j]
NumPy - 广播
术语“广播”是指 NumPy 在算术运算期间处理不同形状的数组的能力。数组的算术运算通常是针对相应的元素进行的。如果两个数组的形状完全相同,那么这些操作就可以顺利执行。
实施例1
import numpy as np a = np.array([1,2,3,4]) b = np.array([10,20,30,40]) c = a * b print c
其输出如下 -
[10 40 90 160]
如果两个数组的维度不同,则无法进行元素到元素的操作。然而,由于广播功能,在 NumPy 中仍然可以对不相似形状的数组进行操作。较小的数组被广播到较大数组的大小,以便它们具有兼容的形状。
如果满足以下规则,则可以进行广播 -
ndim小于另一个的数组在其形状中添加“1”。
输出形状的每个维度的大小是该维度的输入大小的最大值。
如果输入在特定维度上的大小与输出大小匹配或者其值恰好为 1,则输入可以用于计算。
如果输入的维度大小为 1,则该维度中的第一个数据条目将用于沿该维度的所有计算。
如果上述规则产生有效结果并且以下其中一个为真,则一组数组被称为可广播-
数组具有完全相同的形状。
数组具有相同的维数,每个维的长度要么是公共长度,要么是 1。
维度太少的数组可以在其形状前面加上长度为 1 的维度,以便上述属性成立。
以下程序显示了广播的示例。
实施例2
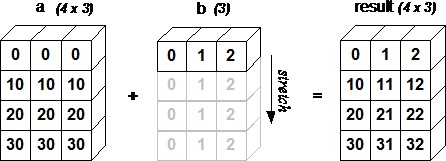
import numpy as np a = np.array([[0.0,0.0,0.0],[10.0,10.0,10.0],[20.0,20.0,20.0],[30.0,30.0,30.0]]) b = np.array([1.0,2.0,3.0]) print 'First array:' print a print '\n' print 'Second array:' print b print '\n' print 'First Array + Second Array' print a + b
该程序的输出如下 -
First array: [[ 0. 0. 0.] [ 10. 10. 10.] [ 20. 20. 20.] [ 30. 30. 30.]] Second array: [ 1. 2. 3.] First Array + Second Array [[ 1. 2. 3.] [ 11. 12. 13.] [ 21. 22. 23.] [ 31. 32. 33.]]
下图演示了如何广播数组b以与a兼容。
NumPy - 迭代数组
NumPy 包包含一个迭代器对象numpy.nditer。它是一个高效的多维迭代器对象,使用它可以迭代数组。使用 Python 的标准 Iterator 接口访问数组的每个元素。
让我们使用 arange() 函数创建一个 3X4 数组,并使用nditer对其进行迭代。
实施例1
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Modified array is:' for x in np.nditer(a): print x,
该程序的输出如下 -
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Modified array is: 0 5 10 15 20 25 30 35 40 45 50 55
实施例2
选择迭代顺序以匹配数组的内存布局,而不考虑特定的顺序。这可以通过迭代上述数组的转置来看出。
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Transpose of the original array is:' b = a.T print b print '\n' print 'Modified array is:' for x in np.nditer(b): print x,
上述程序的输出如下 -
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Transpose of the original array is: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] Modified array is: 0 5 10 15 20 25 30 35 40 45 50 55
迭代顺序
如果使用 F 样式顺序存储相同的元素,则迭代器会选择更有效的方式来迭代数组。
实施例1
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Transpose of the original array is:' b = a.T print b print '\n' print 'Sorted in C-style order:' c = b.copy(order='C') print c for x in np.nditer(c): print x, print '\n' print 'Sorted in F-style order:' c = b.copy(order='F') print c for x in np.nditer(c): print x,
其输出如下 -
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Transpose of the original array is: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] Sorted in C-style order: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] 0 20 40 5 25 45 10 30 50 15 35 55 Sorted in F-style order: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] 0 5 10 15 20 25 30 35 40 45 50 55
实施例2
通过明确提及,可以强制nditer对象使用特定的顺序。
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Sorted in C-style order:' for x in np.nditer(a, order = 'C'): print x, print '\n' print 'Sorted in F-style order:' for x in np.nditer(a, order = 'F'): print x,
它的输出将是 -
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Sorted in C-style order: 0 5 10 15 20 25 30 35 40 45 50 55 Sorted in F-style order: 0 20 40 5 25 45 10 30 50 15 35 55
修改数组值
nditer对象有另一个可选参数,称为op_flags。其默认值为只读,但可以设置为读写或只写模式。这将允许使用此迭代器修改数组元素。
例子
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' for x in np.nditer(a, op_flags = ['readwrite']): x[...] = 2*x print 'Modified array is:' print a
其输出如下 -
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Modified array is: [[ 0 10 20 30] [ 40 50 60 70] [ 80 90 100 110]]
外环
nditer 类构造函数有一个“flags”参数,它可以采用以下值 -
| 先生。 | 参数及说明 |
|---|---|
| 1 | c_索引 C_order索引可追踪 |
| 2 | f_index Fortran_order 索引被跟踪 |
| 3 | 多索引 可以跟踪每次迭代一个索引的类型 |
| 4 | 外部循环 导致给定的值是具有多个值的一维数组而不是零维数组 |
例子
在下面的例子中,迭代器遍历了每一列对应的一维数组。
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Modified array is:' for x in np.nditer(a, flags = ['external_loop'], order = 'F'): print x,
输出如下 -
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Modified array is: [ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]
广播迭代
如果两个数组是可广播的,则组合的nditer对象能够同时迭代它们。假设数组a 的维度为 3X4,并且还有另一个维度为 1X4 的数组b,则使用以下类型的迭代器(数组b被广播到a的大小)。
例子
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'First array is:' print a print '\n' print 'Second array is:' b = np.array([1, 2, 3, 4], dtype = int) print b print '\n' print 'Modified array is:' for x,y in np.nditer([a,b]): print "%d:%d" % (x,y),
其输出如下 -
First array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Second array is: [1 2 3 4] Modified array is: 0:1 5:2 10:3 15:4 20:1 25:2 30:3 35:4 40:1 45:2 50:3 55:4
NumPy - 数组操作
NumPy 包中有几个例程可用于操作 ndarray 对象中的元素。它们可以分为以下类型 -
改变形状
转置操作
| 先生。 |
|---|