- Plotly教程
- 阴谋 - 主页
- Plotly - 简介
- Plotly - 环境设置
- Plotly - 在线和离线绘图
- 使用 Jupyter Notebook 内联绘图
- Plotly - 包结构
- Plotly - 导出到静态图像
- Plotly - 传奇
- Plotly - 设置轴和刻度的格式
- Plotly - 子图和插图
- Plotly - 条形图和饼图
- Plotly - 散点图、Scattergl 图和气泡图
- Plotly - 点图和表格
- Plotly - 直方图
- Plotly - 箱线图小提琴图和等高线图
- Plotly - 分布图、密度图和误差条图
- Plotly - 热图
- Plotly - 极坐标图和雷达图
- Plotly - OHLC 图表瀑布图和漏斗图
- Plotly - 3D 散点图和曲面图
- Plotly - 添加按钮/下拉菜单
- Plotly - 滑块控制
- Plotly -FigureWidget 类
- 与pandas和袖扣密谋
- 使用 Matplotlib 和 Chart Studio 绘图
- 非常有用的资源
- Plotly - 快速指南
- Plotly - 有用的资源
- Plotly - 讨论
Plotly - 快速指南
Plotly - 简介
Plotly 是一家总部位于蒙特利尔的技术计算公司,致力于开发数据分析和可视化工具,例如Dash和Chart Studio。它还为 Python、R、MATLAB、Javascript 和其他计算机编程语言开发了开源图形应用程序编程接口 (API) 库。
Plotly 的一些重要特征如下 -
它生成交互式图表。
这些图表以 JavaScript 对象表示法(JSON) 数据格式存储,以便可以使用其他编程语言(例如 R、Julia、MATLAB 等)的脚本读取它们。
图形可以以各种光栅和矢量图像格式导出
Plotly - 环境设置
本章重点介绍如何借助 Plotly 在 Python 中进行环境搭建。
Python包的安装
始终建议使用 Python 的虚拟环境功能来安装新包。以下命令在指定文件夹中创建虚拟环境。
python -m myenv
要激活如此创建的虚拟环境,请运行bin子文件夹中的激活脚本,如下所示。
source bin/activate
现在我们可以使用 pip 实用程序安装plotly 的Python 包,如下所示。
pip install plotly
您可能还想安装Jupyter Notebook应用程序,它是Ipython解释器的基于 Web 的界面。
pip install jupyter notebook
首先,您需要在网站上创建一个帐户,网址为https://plot.ly。您可以使用此处提到的链接https://plot.ly/api_signup进行注册,然后成功登录。

接下来,从仪表板的设置页面获取 API 密钥。

使用您的用户名和 API 密钥在Python 解释器会话上设置凭据。
import plotly plotly.tools.set_credentials_file(username='test', api_key='********************')
您的主目录下的.plotly子文件夹中会创建一个名为credentials的特殊文件。它看起来类似于以下内容 -
{
"username": "test",
"api_key": "********************",
"proxy_username": "",
"proxy_password": "",
"stream_ids": []
}
为了生成绘图,我们需要从plotly包中导入以下模块 -
import plotly.plotly as py import plotly.graph_objs as go
plotly.plotly 模块包含帮助我们与 Plotly 服务器通信的函数。plotly.graph_objs模块中的函数生成图形对象
Plotly - 在线和离线绘图
下一章介绍在线和离线绘图的设置。我们先来研究一下在线绘图的设置。
在线绘图设置
在线绘图的数据和图表保存在您的plot.ly 帐户中。在线绘图通过两种方法生成,这两种方法都为绘图创建唯一的url并将其保存在您的 Plotly 帐户中。
py.plot() - 返回唯一的 url 并可选择打开该 url。
py.iplot() - 在Jupyter Notebook中工作时在笔记本中显示绘图。
我们现在将显示以弧度表示的角度与其正弦值的简单绘图。首先,使用numpy 库中的arange()函数获取角度在 0 到 2π 之间的 ndarray 对象。该 ndarray 对象用作图表x 轴上的值。必须在y 轴上显示的 x 角度的相应正弦值通过以下语句获得 -
import numpy as np import math #needed for definition of pi xpoints = np.arange(0, math.pi*2, 0.05) ypoints = np.sin(xpoints)
接下来,使用graph_objs 模块中的Scatter()函数创建散点跟踪。
trace0 = go.Scatter( x = xpoints, y = ypoints ) data = [trace0]
使用上面的列表对象作为plot()函数的参数。
py.plot(data, filename = 'Sine wave', auto_open=True)
将以下脚本保存为plotly1.py
import plotly plotly.tools.set_credentials_file(username='lathkar', api_key='********************') import plotly.plotly as py import plotly.graph_objs as go import numpy as np import math #needed for definition of pi xpoints = np.arange(0, math.pi*2, 0.05) ypoints = np.sin(xpoints) trace0 = go.Scatter( x = xpoints, y = ypoints ) data = [trace0] py.plot(data, filename = 'Sine wave', auto_open=True)
从命令行执行上述脚本。结果图将显示在浏览器中指定的 URL 处,如下所述。
$ python plotly1.py High five! You successfully sent some data to your account on plotly. View your plot in your browser at https://plot.ly/~lathkar/0
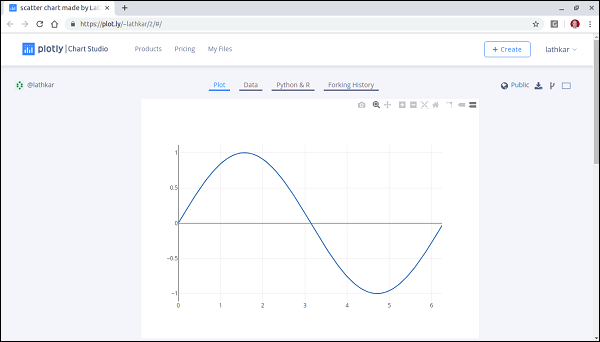
在显示的图表上方,您将找到“绘图”、“数据”、“Python 和 Rand Forking 历史记录”选项卡。
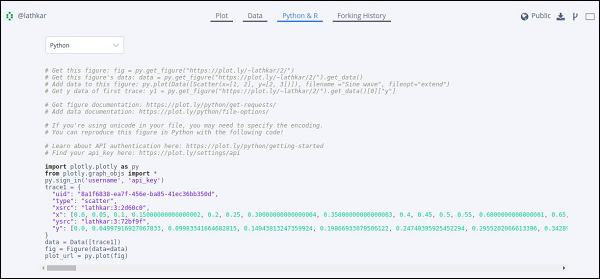
当前,“绘图”选项卡处于选中状态。数据选项卡显示包含 x 和y数据点的网格。从 Python & R 选项卡中,您可以查看与 Python、R、JSON、Matlab 等中的当前绘图相对应的代码。以下快照显示了上面生成的绘图的 Python 代码 -
离线绘图设置
Plotly 允许您离线生成图表并将其保存在本地计算机中。plotly.offline.plot ()函数创建一个独立的 HTML,该 HTML 保存在本地并在 Web 浏览器中打开。
在Jupyter Notebook中离线工作时,使用plotly.offline.iplot()在笔记本中显示绘图。
注意-离线绘图需要Plotly 版本1.9.4+ 。
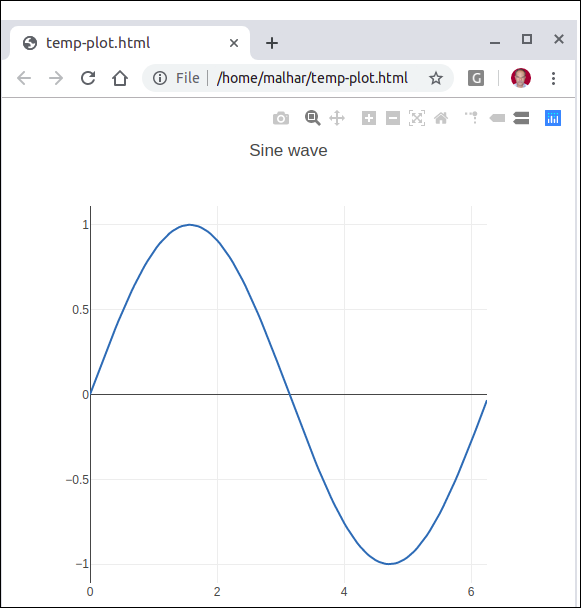
更改脚本中的plot()函数语句并运行。将在本地创建名为temp-plot.html的 HTML 文件并在 Web 浏览器中打开。
plotly.offline.plot(
{ "data": data,"layout": go.Layout(title = "hello world")}, auto_open = True)
Plotly - 使用 Jupyter Notebook 内联绘图
在本章中,我们将研究如何使用 Jupyter Notebook 进行内联绘图。
为了在笔记本内显示绘图,您需要启动plotly的笔记本模式,如下所示 -
from plotly.offline import init_notebook_mode init_notebook_mode(connected = True)
保持脚本的其余部分不变,并按Shift+Enter运行笔记本单元。图表将在笔记本内部离线显示。
import plotly
plotly.tools.set_credentials_file(username = 'lathkar', api_key = '************')
from plotly.offline import iplot, init_notebook_mode
init_notebook_mode(connected = True)
import plotly
import plotly.graph_objs as go
import numpy as np
import math #needed for definition of pi
xpoints = np.arange(0, math.pi*2, 0.05)
ypoints = np.sin(xpoints)
trace0 = go.Scatter(
x = xpoints, y = ypoints
)
data = [trace0]
plotly.offline.iplot({ "data": data,"layout": go.Layout(title="Sine wave")})
Jupyter 笔记本输出如下所示 -

绘图输出在右上角显示一个工具栏。它包含用于下载png、放大和缩小、框和套索、选择和悬停的按钮。

Plotly - 包结构
Plotly Python 包具有三个主要模块,如下所示:
- Plotly地
- plotly.graph_objs
- 绘图工具
plotly.plotly 模块包含需要 Plotly 服务器响应的函数。该模块中的函数是本地计算机和 Plotly 之间的接口。
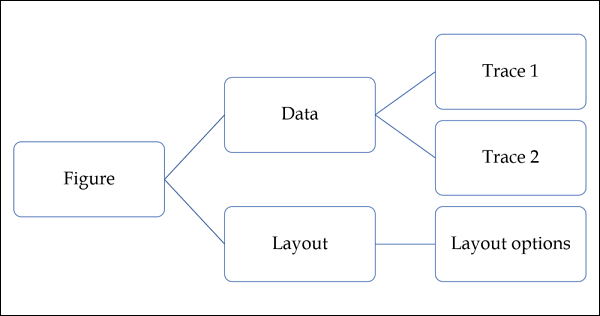
plotly.graph_objs 模块是最重要的模块,其中包含构成您所看到的绘图的对象的所有类定义。定义了以下图形对象 -
- 数字,
- 数据,
- 阿约特,
- 不同的图形轨迹,如散点图、方框图、直方图等。
所有图形对象都是字典和类似列表的对象,用于生成和/或修改 Plotly 图的每个特征。
plotly.tools模块包含许多有用的功能,可促进和增强 Plotly 体验。此模块中定义了子图生成、在IPython 笔记本中嵌入 Plotly 绘图、保存和检索凭据的函数。
绘图由Figure 对象表示,该对象表示plotly.graph_objs 模块中定义的Figure 类。它的构造函数需要以下参数 -
import plotly.graph_objs as go fig = go.Figure(data, layout, frames)
data参数是Python中的列表对象。它是您想要绘制的所有轨迹的列表。迹线只是我们给要绘制的数据集合起的名称。跟踪对象根据您希望数据在绘图表面上显示的方式来命名。
Plotly 提供了许多跟踪对象,例如散点图、条形图、饼图、热图等,每个对象都由graph_objs函数中的相应函数返回。例如:go.scatter()返回分散轨迹。
import numpy as np import math #needed for definition of pi xpoints=np.arange(0, math.pi*2, 0.05) ypoints=np.sin(xpoints) trace0 = go.Scatter( x = xpoints, y = ypoints ) data = [trace0]
布局参数定义绘图的外观以及与数据无关的绘图特征。因此,我们将能够更改标题、轴标题、注释、图例、间距、字体等内容,甚至可以在绘图上绘制形状。
layout = go.Layout(title = "Sine wave", xaxis = {'title':'angle'}, yaxis = {'title':'sine'})
绘图可以有绘图标题和轴标题。它还可能有注释来指示其他描述。
最后,有一个由go.Figure() 函数创建的Figure 对象。它是一个类似字典的对象,包含数据对象和布局对象。最终绘制图形对象。
py.iplot(fig)
Plotly - 导出到静态图像
离线图形的输出可以导出为各种光栅和矢量图像格式。为此,我们需要安装两个依赖项 - orca和psutil。
虎鲸
Orca 代表开源报告创建应用程序。它是一个 Electron 应用程序,可以从命令行生成图形、破折号应用程序、仪表板的图像和报告。Orca 是 Plotly 图像服务器的支柱。
普苏蒂尔
psutil (Python 系统和进程实用程序)是一个跨平台库,用于检索有关 Python 中正在运行的进程和系统利用率的信息。它实现了UNIX命令行工具提供的许多功能,例如:ps、top、netstat、ifconfig、who等。 psutil 支持所有主要操作系统,例如 Linux、Windows 和 MacOs
Orca 和 psutil 的安装
如果您使用 Python 的 Anaconda 发行版,则可以通过conda 包管理器轻松安装 orca 和 psutil,如下所示 -
conda install -c plotly plotly-orca psutil
因为,orca 在 PyPi 存储库中不可用。您可以使用npm 实用程序来安装它。
npm install -g electron@1.8.4 orca
使用 pip 安装 psutil
pip install psutil
如果您无法使用 npm 或 conda,也可以从以下网站下载 orca 的预构建二进制文件,该网站位于https://github.com/plotly/orca/releases。
要将Figure对象导出为png、jpg或WebP格式,首先,导入plotly.io模块
import plotly.io as pio
现在,我们可以调用write_image()函数,如下所示 -
pio.write_image(fig, ‘sinewave.png’) pio.write_image(fig, ‘sinewave.jpeg’) pio.write_image(fig,’sinewave.webp)
orca 工具还支持将plotly 导出为svg、pdf 和eps 格式。
Pio.write_image(fig, ‘sinewave.svg’) pio.write_image(fig, ‘sinewave.pdf’)
在Jupyter Notebook中,通过pio.to_image()函数获得的图像对象可以内联显示,如下所示 -

Plotly - 传奇
默认情况下,具有多条迹线的 Plotly 图表会自动显示图例。如果只有一条迹线,则不会自动显示。要显示,请将Layout 对象的showlegend参数设置为 True。
layout = go.Layoyt(showlegend = True)
图例的默认标签是跟踪对象名称。要设置图例标签,请显式设置迹线的名称属性。
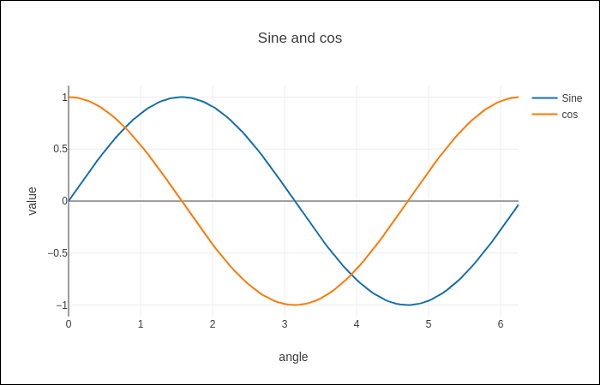
在以下示例中,绘制了两条具有 name 属性的散点迹线。
import numpy as np
import math #needed for definition of pi
xpoints = np.arange(0, math.pi*2, 0.05)
y1 = np.sin(xpoints)
y2 = np.cos(xpoints)
trace0 = go.Scatter(
x = xpoints,
y = y1,
name='Sine'
)
trace1 = go.Scatter(
x = xpoints,
y = y2,
name = 'cos'
)
data = [trace0, trace1]
layout = go.Layout(title = "Sine and cos", xaxis = {'title':'angle'}, yaxis = {'title':'value'})
fig = go.Figure(data = data, layout = layout)
iplot(fig)
该图如下所示 -
Plotly - 设置轴和刻度的格式
您可以通过指定线宽和颜色来配置每个轴的外观。还可以定义网格宽度和网格颜色。让我们在本章中详细了解这一点。
带轴和刻度线的绘图
在 Layout 对象的属性中,将showticklabels设置为 true 将启用刻度。tickfont 属性是一个 dict 对象,指定字体名称、大小、颜色等。tickmode 属性可以有两个可能的值 - 线性和数组。如果是线性的,则起始刻度的位置由tick0确定,刻度之间的步长由dtick属性确定。
如果tickmode设置为数组,则必须提供值和标签列表作为tickval和ticktext属性。
Layout 对象还具有Exponentformat属性,设置为“e”将导致刻度值以科学计数法显示。您还需要将showexponent属性设置为'all'。
现在,我们通过指定行、网格和标题字体属性以及刻度模式、值和字体来格式化上面示例中的 Layout 对象,以配置 x 和y 轴。
layout = go.Layout(
title = "Sine and cos",
xaxis = dict(
title = 'angle',
showgrid = True,
zeroline = True,
showline = True,
showticklabels = True,
gridwidth = 1
),
yaxis = dict(
showgrid = True,
zeroline = True,
showline = True,
gridcolor = '#bdbdbd',
gridwidth = 2,
zerolinecolor = '#969696',
zerolinewidth = 2,
linecolor = '#636363',
linewidth = 2,
title = 'VALUE',
titlefont = dict(
family = 'Arial, sans-serif',
size = 18,
color = 'lightgrey'
),
showticklabels = True,
tickangle = 45,
tickfont = dict(
family = 'Old Standard TT, serif',
size = 14,
color = 'black'
),
tickmode = 'linear',
tick0 = 0.0,
dtick = 0.25
)
)

多轴绘图
有时,在图形中具有双 x或 y 轴很有用;例如,当一起绘制具有不同单位的曲线时。Matplotlib 通过twinx和twiny函数支持这一点。在下面的示例中,该图具有双 y 轴,一个显示exp(x),另一个显示log(x)
x = np.arange(1,11)
y1 = np.exp(x)
y2 = np.log(x)
trace1 = go.Scatter(
x = x,
y = y1,
name = 'exp'
)
trace2 = go.Scatter(
x = x,
y = y2,
name = 'log',
yaxis = 'y2'
)
data = [trace1, trace2]
layout = go.Layout(
title = 'Double Y Axis Example',
yaxis = dict(
title = 'exp',zeroline=True,
showline = True
),
yaxis2 = dict(
title = 'log',
zeroline = True,
showline = True,
overlaying = 'y',
side = 'right'
)
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
此处,附加 y 轴配置为yaxis2并显示在右侧,标题为“log”。结果图如下 -

Plotly - 子图和插图
在这里,我们将了解 Plotly 中的子图和插图的概念。
制作次要Plotly
有时并排比较不同的数据视图会很有帮助。这支持了子图的概念。它在plotly.tools模块中提供了make_subplots()函数。该函数返回一个Figure 对象。
以下语句在一行中创建两个子图。
fig = tools.make_subplots(rows = 1, cols = 2)
我们现在可以向图中添加两个不同的跟踪(上面示例中的 exp 和 log 跟踪)。
fig.append_trace(trace1, 1, 1) fig.append_trace(trace2, 1, 2)
通过使用update()方法指定标题、宽度、高度等来进一步配置图形的布局。
fig['layout'].update(height = 600, width = 800s, title = 'subplots')
这是完整的脚本 -
from plotly import tools import plotly.plotly as py import plotly.graph_objs as go from plotly.offline import iplot, init_notebook_mode init_notebook_mode(connected = True) import numpy as np x = np.arange(1,11) y1 = np.exp(x) y2 = np.log(x) trace1 = go.Scatter( x = x, y = y1, name = 'exp' ) trace2 = go.Scatter( x = x, y = y2, name = 'log' ) fig = tools.make_subplots(rows = 1, cols = 2) fig.append_trace(trace1, 1, 1) fig.append_trace(trace2, 1, 2) fig['layout'].update(height = 600, width = 800, title = 'subplot') iplot(fig)
这是绘图网格的格式: [ (1,1) x1,y1 ] [ (1,2) x2,y2 ]

插图
要将子图显示为插图,我们需要配置其跟踪对象。首先,插图的xaxis和 yaxis 属性分别为“x2”和“y2”。以下语句将“日志”跟踪放入插图中。
trace2 = go.Scatter( x = x, y = y2, xaxis = 'x2', yaxis = 'y2', name = 'log' )
其次,配置布局对象,其中插图的 x 轴和 y 轴位置由指定相对于长轴的位置的域属性定义。
xaxis2=dict( domain = [0.1, 0.5], anchor = 'y2' ), yaxis2 = dict( domain = [0.5, 0.9], anchor = 'x2' )
下面给出了在主轴上的插图和 exp 跟踪中显示日志跟踪的完整脚本 -
trace1 = go.Scatter(
x = x,
y = y1,
name = 'exp'
)
trace2 = go.Scatter(
x = x,
y = y2,
xaxis = 'x2',
yaxis = 'y2',
name = 'log'
)
data = [trace1, trace2]
layout = go.Layout(
yaxis = dict(showline = True),
xaxis2 = dict(
domain = [0.1, 0.5],
anchor = 'y2'
),
yaxis2 = dict(
showline = True,
domain = [0.5, 0.9],
anchor = 'x2'
)
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
输出如下 -

Plotly - 条形图和饼图
在本章中,我们将学习如何借助 Plotly 制作条形图和饼图。让我们首先了解条形图。
条形图
条形图用矩形条显示分类数据,矩形条的高度或长度与其所表示的值成比例。条形可以垂直或水平显示。它有助于显示离散类别之间的比较。图表的一个轴显示正在比较的特定类别,另一轴表示测量值。
以下示例绘制了一个简单的条形图,显示了注册不同课程的学生人数。go.Bar ()函数返回一个条形轨迹,其中 x 坐标设置为科目列表,y 坐标设置为学生数量。
import plotly.graph_objs as go langs = ['C', 'C++', 'Java', 'Python', 'PHP'] students = [23,17,35,29,12] data = [go.Bar( x = langs, y = students )] fig = go.Figure(data=data) iplot(fig)
输出如下所示 -

要显示分组条形图,必须将 Layout 对象的barmode属性设置为group。在下面的代码中,根据科目绘制了代表每年学生的多个轨迹,并显示为分组条形图。
branches = ['CSE', 'Mech', 'Electronics'] fy = [23,17,35] sy = [20, 23, 30] ty = [30,20,15] trace1 = go.Bar( x = branches, y = fy, name = 'FY' ) trace2 = go.Bar( x = branches, y = sy, name = 'SY' ) trace3 = go.Bar( x = branches, y = ty, name = 'TY' ) data = [trace1, trace2, trace3] layout = go.Layout(barmode = 'group') fig = go.Figure(data = data, layout = layout) iplot(fig)
其输出如下 -

barmode属性确定相同位置坐标处的条形在图表上的显示方式。定义的值有“stack”(条形堆叠在一起)、“relative”(条形堆叠在一起,负值位于轴下方,正值位于轴上方)、“group”(条形绘制在轴旁边)另一个)。
通过将 barmode 属性更改为“ stack ”,绘制的图表如下所示 -

饼形图
饼图仅显示一系列数据。饼图显示一个数据系列中项目的大小(称为楔形),与项目总和成正比。数据点显示为整个饼图的百分比。
graph_objs模块中的pie ()函数go.Pie()返回 Pie 轨迹。两个必需的参数是labels和value。让我们绘制一个简单的饼图,显示语言课程与学生数量的关系,如本文给出的示例所示。
import plotly plotly.tools.set_credentials_file( username = 'lathkar', api_key = 'U7vgRe1hqmRp4ZNf4PTN' ) from plotly.offline import iplot, init_notebook_mode init_notebook_mode(connected = True) import plotly.graph_objs as go langs = ['C', 'C++', 'Java', 'Python', 'PHP'] students = [23,17,35,29,12] trace = go.Pie(labels = langs, values = students) data = [trace] fig = go.Figure(data = data) iplot(fig)
以下输出显示在 Jupyter 笔记本中 -

甜甜圈图是一种饼图,中心有一个圆孔,使其看起来像甜甜圈。在以下示例中,两个圆环图以 1X2 网格布局显示。虽然两个饼图的“标签”布局相同,但每个子图的行和列目标由域属性决定。
为此,我们使用 2019 年议会选举中各党派席位和选票份额的数据。在 Jupyter 笔记本单元中输入以下代码 -
parties = ['BJP', 'CONGRESS', 'DMK', 'TMC', 'YSRC', 'SS', 'JDU','BJD', 'BSP','OTH']
seats = [303,52,23,22,22,18,16,12,10, 65]
percent = [37.36, 19.49, 2.26, 4.07, 2.53, 2.10, 1.46, 1.66, 3.63, 25.44]
import plotly.graph_objs as go
data1 = {
"values": seats,
"labels": parties,
"domain": {"column": 0},
"name": "seats",
"hoverinfo":"label+percent+name",
"hole": .4,
"type": "pie"
}
data2 = {
"values": percent,
"labels": parties,
"domain": {"column": 1},
"name": "vote share",
"hoverinfo":"label+percent+name",
"hole": .4,
"type": "pie"
}
data = [data1,data2]
layout = go.Layout(
{
"title":"Parliamentary Election 2019",
"grid": {"rows": 1, "columns": 2},
"annotations": [
{
"font": {
"size": 20
},
"showarrow": False,
"text": "seats",
"x": 0.20,
"y": 0.5
},
{
"font": {
"size": 20
},
"showarrow": False,
"text": "votes",
"x": 0.8,
"y": 0.5
}
]
}
)
fig = go.Figure(data = data, layout = layout)
iplot(fig)
其输出如下 -

散点图、Scattergl 图和气泡图
本章重点介绍散点图、散点图和气泡图的详细信息。首先,我们来学习一下散点图。
散点图
散点图用于在水平轴和垂直轴上绘制数据点,以显示一个变量如何影响另一个变量。数据表中的每一行都由一个标记表示,该标记的位置取决于其在X轴和Y轴上设置的列中的值。
graph_objs 模块(go.Scatter)的scatter ()方法生成散点轨迹。这里,模式属性决定数据点的外观。mode 的默认值是lines,显示连接数据点的连续线。如果设置为标记,则仅显示由小实心圆圈表示的数据点。当模式指定为“线条+标记”时,会显示圆形和线条。
在以下示例中,在笛卡尔坐标系中绘制三组随机生成的点的散点轨迹。下面解释了以不同模式属性显示的每条迹线。
import numpy as np N = 100 x_vals = np.linspace(0, 1, N) y1 = np.random.randn(N) + 5 y2 = np.random.randn(N) y3 = np.random.randn(N) - 5 trace0 = go.Scatter( x = x_vals, y = y1, mode = 'markers', name = 'markers' ) trace1 = go.Scatter( x = x_vals, y = y2, mode = 'lines+markers', name = 'line+markers' ) trace2 = go.Scatter( x = x_vals, y = y3, mode = 'lines', name = 'line' ) data = [trace0, trace1, trace2] fig = go.Figure(data = data) iplot(fig)
Jupyter 笔记本单元的输出如下 -

散点图
WebGL(Web 图形库)是一种 JavaScript API,用于在任何兼容的 Web 浏览器中渲染交互式2D和3D 图形,而无需使用插件。WebGL 与其他 Web 标准完全集成,允许图形处理单元 (GPU) 加速图像处理的使用。
Plotly 您可以使用Scattergl()代替 Scatter() 来实现 WebGL,以提高速度、改进交互性以及绘制更多数据的能力。go.scattergl ()函数在涉及大量数据点时提供更好的性能。
import numpy as np N = 100000 x = np.random.randn(N) y = np.random.randn(N) trace0 = go.Scattergl( x = x, y = y, mode = 'markers' ) data = [trace0] layout = go.Layout(title = "scattergl plot ") fig = go.Figure(data = data, layout = layout) iplot(fig)
输出如下 -

气泡图
气泡图显示数据的三个维度。每个实体及其关联数据的三个维度都被绘制为一个圆盘(气泡),其中两个维度通过圆盘的xy 位置表示,第三个维度通过其大小表示。气泡的大小由第三个数据系列中的值确定。
气泡图是散点图的变体,其中数据点被气泡替换。如果您的数据具有如下所示的三个维度,那么创建气泡图将是一个不错的选择。
| 公司 | 产品 | 销售 | 分享 |
|---|---|---|---|
| A | 13 | 2354 | 23 |
| 乙 | 6 | 5423 | 47 |
| C | 23 | 2451 | 30 |
气泡图是通过go.Scatter()跟踪生成的。上述数据系列中的两个作为 x 和 y 属性给出。第三维由标记显示,其大小代表第三数据系列。在上述情况下,我们使用产品和销售额作为x和y属性,使用市场份额作为标记大小。
在 Jupyter 笔记本中输入以下代码。
company = ['A','B','C']
products = [13,6,23]
sale = [2354,5423,4251]
share = [23,47,30]
fig = go.Figure(data = [go.Scatter(
x = products, y = sale,
text = [
'company:'+c+' share:'+str(s)+'%'
for c in company for s in share if company.index(c)==share.index(s)
],
mode = 'markers',
marker_size = share, marker_color = ['blue','red','yellow'])
])
iplot(fig)
输出如下所示 -

Plotly - 点图和表格
在这里,我们将学习Plotly中的点图和表格函数。首先,让我们从点图开始。
点图
点图以非常简单的比例显示点。它只适合少量数据,因为大量的点会使其看起来非常混乱。点图也称为克利夫兰点图。它们显示两个(或更多)时间点之间或两个(或更多)条件之间的变化。
点图类似于水平条形图。然而,它们可以不那么混乱,并且可以更容易地比较条件。该图绘制了模式属性设置为标记的散点迹线。
以下示例显示了印度独立后每次人口普查记录的男性和女性识字率的比较。图中的两条迹线代表 1951 年至 2011 年每次人口普查中男性和女性的识字率。
from plotly.offline import iplot, init_notebook_mode init_notebook_mode(connected = True) census = [1951,1961,1971,1981,1991,2001, 2011] x1 = [8.86, 15.35, 21.97, 29.76, 39.29, 53.67, 64.63] x2 = [27.15, 40.40, 45.96, 56.38,64.13, 75.26, 80.88] traceA = go.Scatter( x = x1, y = census, marker = dict(color = "crimson", size = 12), mode = "markers", name = "Women" ) traceB = go.Scatter( x = x2, y = census, marker = dict(color = "gold", size = 12), mode = "markers", name = "Men") data = [traceA, traceB] layout = go.Layout( title = "Trend in Literacy rate in Post independent India", xaxis_title = "percentage", yaxis_title = "census" ) fig = go.Figure(data = data, layout = layout) iplot(fig)
输出如下所示 -

Plotly 中的表格
Plotly 的 Table 对象由go.Table()函数返回。表跟踪是一个图形对象,可用于在行和列的网格中查看详细数据。表使用列主顺序,即网格表示为列向量的向量。
go.Table()函数的两个重要参数是标题(表的第一行)和构成其余行的单元格。两个参数都是字典对象。headers 的 value 属性是一个列标题列表和一个列表列表,每个列表对应一行。
进一步的样式定制是通过 linecolor、fill_color、font 和其他属性来完成的。
以下代码显示了最近结束的 2019 年板球世界杯循环赛阶段的积分表。
trace = go.Table(
header = dict(
values = ['Teams','Mat','Won','Lost','Tied','NR','Pts','NRR'],
line_color = 'gray',
fill_color = 'lightskyblue',
align = 'left'
),
cells = dict(
values =
[
[
'India',
'Australia',
'England',
'New Zealand',
'Pakistan',
'Sri Lanka',
'South Africa',
'Bangladesh',
'West Indies',
'Afghanistan'
],
[9,9,9,9,9,9,9,9,9,9],
[7,7,6,5,5,3,3,3,2,0],
[1,2,3,3,3,4,5,5,6,9],
[0,0,0,0,0,0,0,0,0,0],
[1,0,0,1,1,2,1,1,1,0],
[15,14,12,11,11,8,7,7,5,0],
[0.809,0.868,1.152,0.175,-0.43,-0.919,-0.03,-0.41,-0.225,-1.322]
],
line_color='gray',
fill_color='lightcyan',
align='left'
)
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)
输出如下 -
表数据也可以从 Pandas 数据框中填充。让我们创建一个逗号分隔的文件(points-table.csv),如下所示 -
| 团队 | 垫 | 韩元 | 丢失的 | 并列 | NR | 分 | NRR |
|---|---|---|---|---|---|---|---|
| 印度 | 9 | 7 | 1 | 0 | 1 | 15 | 0.809 |
| 澳大利亚 | 9 | 7 | 2 | 0 | 0 | 14 | 0.868 |
| 英国 | 9 | 6 | 3 | 0 | 0 | 14 | 1.152 |
| 新西兰 | 9 | 5 | 3 | 0 | 1 | 11 | 0.175 |
| 巴基斯坦 | 9 | 5 | 3 | 0 | 1 | 11 | -0.43 |
| 斯里兰卡 | 9 | 3 | 4 | 0 | 2 | 8 | -0.919 |
| 南非 | 9 | 3 | 5 | 0 | 1 | 7 | -0.03 |
| 孟加拉国 | 9 | 3 | 5 | 0 | 1 | 7 | -0.41 |
Teams,Matches,Won,Lost,Tie,NR,Points,NRR India,9,7,1,0,1,15,0.809 Australia,9,7,2,0,0,14,0.868 England,9,6,3,0,0,12,1.152 New Zealand,9,5,3,0,1,11,0.175 Pakistan,9,5,3,0,1,11,-0.43 Sri Lanka,9,3,4,0,2,8,-0.919 South Africa,9,3,5,0,1,7,-0.03 Bangladesh,9,3,5,0,1,7,-0.41 West Indies,9,2,6,0,1,5,-0.225 Afghanistan,9,0,9,0,0,0,-1.322
我们现在从此 csv 文件构造一个数据框对象,并使用它来构造表跟踪,如下所示 -
import pandas as pd
df = pd.read_csv('point-table.csv')
trace = go.Table(
header = dict(values = list(df.columns)),
cells = dict(
values = [
df.Teams,
df.Matches,
df.Won,
df.Lost,
df.Tie,
df.NR,
df.Points,
df.NRR
]
)
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)
Plotly - 直方图
由 Karl Pearson 提出,直方图是数值数据分布的准确表示,是连续变量 (CORAL) 概率分布的估计。它看起来与条形图类似,但是条形图涉及两个变量,而直方图仅涉及一个变量。
直方图需要bin(或bucket),它将整个值范围划分为一系列间隔,然后计算每个间隔内有多少值。bin 通常被指定为变量的连续、不重叠的间隔。垃圾箱必须相邻,并且通常大小相同。在垃圾箱上方竖立一个矩形,其高度与频率(每个垃圾箱中的箱数)成正比。
直方图跟踪对象由go.Histogram()函数返回。它的定制是通过各种参数或属性来完成的。一个重要参数是将 x 或 y 设置为要分布在 bin 中的列表、numpy 数组或Pandas 数据框对象。
默认情况下,Plotly 将数据点分布在自动调整大小的箱中。但是,您可以定义自定义 bin 大小。为此,您需要将 autobins 设置为 false,指定nbins(bin 数量)、其开始值和结束值以及大小。
以下代码生成一个简单的直方图,显示班级 inbins 中学生的分数分布(自动调整大小) -
import numpy as np x1 = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27]) data = [go.Histogram(x = x1)] fig = go.Figure(data) iplot(fig)
输出如下所示 -

go.Histogram ()函数接受histnorm,它指定用于此直方图跟踪的标准化类型。默认值为“”,每个条形的跨度对应于出现次数(即位于箱内的数据点的数量)。如果指定“百分比”/“概率”,则每个条形的跨度对应于相对于样本点总数的出现百分比/分数。如果它等于“密度”,则每个条的跨度对应于箱中出现的次数除以箱间隔的大小。
还有histfunc参数,其默认值为count。因此,箱上方矩形的高度对应于数据点的计数。它可以设置为总和、平均值、最小值或最大值。
histogram ()函数可以设置为显示连续箱中值的累积分布。为此,您需要将累积属性设置为启用。结果如下 -
data=[go.Histogram(x = x1, cumulative_enabled = True)] fig = go.Figure(data) iplot(fig)
输出如下 -

Plotly - 箱线图、小提琴图和等高线图
本章重点详细了解各种图,包括箱线图、小提琴图、等高线图和箭袋图。首先,我们将从箱线图开始。
箱形图
箱线图显示一组数据的摘要,其中包含最小值、第一四分位数、中位数、第三四分位数和最大值。在箱线图中,我们从第一个四分位数到第三个四分位数绘制一个方框。一条垂直线穿过中间的盒子。从方框垂直延伸的线表示上四分位数和下四分位数之外的变异性,这些线称为须线。因此,箱线图也称为箱须图。须线从每个四分位数到最小值或最大值。

要绘制箱形图,我们必须使用go.Box()函数。数据系列可以分配给 x 或 y 参数。因此,箱线图将水平或垂直绘制。在下面的示例中,将某公司各个分支机构的销售额数据转换为水平箱线图。它显示最小值和最大值的中位数。
trace1 = go.Box(y = [1140,1460,489,594,502,508,370,200]) data = [trace1] fig = go.Figure(data) iplot(fig)
其输出如下 -

go.Box ()函数可以被赋予各种其他参数来控制箱线图的外观和Behave。boxmean 参数就是其中之一。
boxmean参数默认设置为 true。因此,框的基础分布的平均值被绘制为框内的虚线。如果设置为sd,还绘制分布的标准差。
boxpoints参数默认等于“异常值”。仅显示位于晶须外部的样本点。如果“可疑异常值”,则显示异常值点,并且突出显示小于 4"Q1-3"Q3 或大于 4"Q3-3"Q1 的点。如果“False”,则仅显示框,不显示样本点。
在以下示例中,使用标准差和离群点绘制框迹线。
trc = go.Box(
y = [
0.75, 5.25, 5.5, 6, 6.2, 6.6, 6.80, 7.0, 7.2, 7.5, 7.5, 7.75, 8.15,
8.15, 8.65, 8.93, 9.2, 9.5, 10, 10.25, 11.5, 12, 16, 20.90, 22.3, 23.25
],
boxpoints = 'suspectedoutliers', boxmean = 'sd'
)
data = [trc]
fig = go.Figure(data)
iplot(fig)
其输出如下所示 -

小提琴Plotly
小提琴图与箱线图类似,不同之处在于它们还显示不同值下数据的概率密度。小提琴图将包括数据中位数的标记和指示四分位数范围的框,如标准箱线图一样。覆盖在该箱形图上的是核密度估计。与箱线图类似,小提琴图用于表示不同“类别”之间的变量分布(或样本分布)的比较。
小提琴图比普通箱线图提供更多信息。事实上,虽然箱形图仅显示平均值/中位数和四分位距等汇总统计数据,但小提琴图显示了数据的完整分布。
Violin 跟踪对象由graph_objects模块中的go.Violin()函数返回。为了显示底层箱线图,boxplot_visible属性设置为 True。类似地,通过将meanline_visible属性设置为true,与样本平均值相对应的线会显示在小提琴内部。
以下示例演示了如何使用plotly 的功能显示小提琴图。
import numpy as np np.random.seed(10) c1 = np.random.normal(100, 10, 200) c2 = np.random.normal(80, 30, 200) trace1 = go.Violin(y = c1, meanline_visible = True) trace2 = go.Violin(y = c2, box_visible = True) data = [trace1, trace2] fig = go.Figure(data = data) iplot(fig)
输出如下 -

等值线图
二维等高线图显示二维数值数组 z 的等高线,即 z 等值的插值线。两个变量的函数的等高线是一条曲线,沿该曲线函数具有恒定值,因此该曲线连接了相等值的点。
如果您想查看某个值 Z 作为两个输入X和Y的函数如何变化,使得Z = f(X,Y) ,那么等高线图是合适的。两个变量函数的等值线或等值线是函数具有恒定值的曲线。
自变量 x 和 y 通常仅限于称为 meshgrid 的规则网格。numpy.meshgrid 使用 x 值数组和 y 值数组创建一个矩形网格。
让我们首先使用Numpy 库中的linspace()函数创建 x、y 和 z 的数据值。我们从 x 和 y 值创建一个网格,并获得由x2+y2的平方根组成的 z 数组
我们在graph_objects模块中有go.Contour()函数,它接受 x、y和z属性。以下代码片段显示了按上述方法计算的 x、 y和z值的等值线图。
import numpy as np xlist = np.linspace(-3.0, 3.0, 100) ylist = np.linspace(-3.0, 3.0, 100) X, Y = np.meshgrid(xlist, ylist) Z = np.sqrt(X**2 + Y**2) trace = go.Contour(x = xlist, y = ylist, z = Z) data = [trace] fig = go.Figure(data) iplot(fig)
输出如下 -

等值线图可以通过以下一个或多个参数自定义 -
Transpose (boolean) - 转置 z 数据。
如果xtype(或ytype)等于“array”,则 x/y 坐标由“x”/“y”给出。如果“缩放”,则 x 坐标由“x0”和“ dx ”给出。
connectgaps参数确定是否填充 z 数据中的间隙。
ncontours参数的默认值为15。实际轮廓数将自动选择小于或等于“ncontours”的值。仅当“autocontour”为“True”时才有效。
等值线类型默认为:“级别”,因此数据表示为显示多个级别的等值线图。如果constrain,则数据表示为约束,其中无效区域按操作和值参数指定着色。
showlines - 确定是否绘制等高线。
zauto默认情况下为True,并确定是否根据输入数据(此处为“z”)或“ zmin ”和“ zmax ”中设置的边界计算颜色域,当“zmin”和“zmin ”时默认为“ False ” `zmax` 由用户设置。
箭袋图
箭袋图也称为速度图。它将速度矢量显示为箭头,其分量 ( u,v ) 位于点 (x,y)。为了绘制 Quiver 图,我们将使用Plotly 中的figure_factory模块中定义的create_quiver()函数。
Plotly 的 Python API 包含一个图形工厂模块,其中包含许多包装函数,这些函数可创建尚未包含在Plotly 开源图形库plotly.js中的独特图表类型。
create_quiver() 函数接受以下参数 -
x - 箭头位置的 x 坐标
y − 箭头位置的 y 坐标
u − 箭头向量的 x 分量
箭头向量的v − y 分量
scale - 缩放箭头的大小
arrow_scale - 箭头的长度。
角度- 箭头的角度。
以下代码在 Jupyter 笔记本中呈现一个简单的颤动图 -
import plotly.figure_factory as ff import numpy as np x,y = np.meshgrid(np.arange(-2, 2, .2), np.arange(-2, 2, .25)) z = x*np.exp(-x**2 - y**2) v, u = np.gradient(z, .2, .2) # Create quiver figure fig = ff.create_quiver(x, y, u, v, scale = .25, arrow_scale = .4, name = 'quiver', line = dict(width = 1)) iplot(fig)
代码的输出如下 -

Plotly - Distplots 密度图和误差条图
在本章中,我们将详细了解分布图、密度图和误差条图。让我们首先了解 distplots。
分布图
distplot 图形工厂显示数值数据的统计表示形式的组合,例如直方图、核密度估计或正态曲线以及地毯图。
distplot 可以由以下 3 个组件的全部或任意组合组成 -
- 直方图
- 曲线:(a) 核密度估计或 (b) 正态曲线,以及
- 地毯图
figure_factory模块具有create_distplot()函数,该函数需要一个名为 hist_data 的强制参数。
以下代码创建一个由直方图、kde 图和 rug 图组成的基本 distplot。
x = np.random.randn(1000) hist_data = [x] group_labels = ['distplot'] fig = ff.create_distplot(hist_data, group_labels) iplot(fig)
上述代码的输出如下 -

密度图
密度图是根据数据估计的直方图的平滑连续版本。最常见的估计形式称为核密度估计(KDE)。在此方法中,在每个单独的数据点处绘制连续曲线(内核),然后将所有这些曲线加在一起以进行单个平滑密度估计。
模块plotly.figure_factory._2d_密度中的create_2d_密度()函数返回二维密度图的图形对象。
以下代码用于生成直方图数据的二维密度图。
t = np.linspace(-1, 1.2, 2000) x = (t**3) + (0.3 * np.random.randn(2000)) y = (t**6) + (0.3 * np.random.randn(2000)) fig = ff.create_2d_density( x, y) iplot(fig)
下面提到的是上面给出的代码的输出。

误差条图
误差线是数据中误差或不确定性的图形表示,它们有助于正确解释。出于科学目的,报告错误对于理解给定数据至关重要。
误差线对于问题解决者很有用,因为误差线显示了一组测量值或计算值的置信度或精度。
大多数误差线代表数据集的范围和标准差。它们可以帮助可视化数据如何围绕平均值分布。可以在各种图上生成误差线,例如条形图、线图、散点图等。
go.Scatter ()函数具有error_x和error_y属性,用于控制误差线的生成方式。
visible (boolean) - 确定这组误差线是否可见。
Type 属性的可能值是“ percent ” | “常数” | “开方” | “ data ”。它设置用于生成误差线的规则。如果为“percent”,则条形长度对应于基础数据的百分比。在“value”中设置此百分比。如果为“sqrt”,则条形长度对应于基础数据的百分比。基础数据的平方。如果为“data”,则条形长度由数据集“array”设置。
对称属性可以是 true 或 false。因此,误差条在两个方向上都将具有相同的长度或不同的长度(垂直条的顶部/底部,水平条的左/右)。
array - 设置与每个误差条的长度相对应的数据。值是相对于基础数据绘制的。
arrayminus - 设置与垂直(水平)条的底部(左)方向上每个误差条的长度相对应的数据。值是相对于基础数据绘制的。
以下代码在散点图上显示对称误差线 -
trace = go.Scatter( x = [0, 1, 2], y = [6, 10, 2], error_y = dict( type = 'data', # value of error bar given in data coordinates array = [1, 2, 3], visible = True) ) data = [trace] layout = go.Layout(title = 'Symmetric Error Bar') fig = go.Figure(data = data, layout = layout) iplot(fig)
下面给出的是上述代码的输出。

非对称误差图由以下脚本呈现 -
trace = go.Scatter(
x = [1, 2, 3, 4],
y =[ 2, 1, 3, 4],
error_y = dict(
type = 'data',
symmetric = False,
array = [0.1, 0.2, 0.1, 0.1],
arrayminus = [0.2, 0.4, 1, 0.2]
)
)
data = [trace]
layout = go.Layout(title = 'Asymmetric Error Bar')
fig = go.Figure(data = data, layout = layout)
iplot(fig)
其输出如下 -

Plotly - 热图
热图(或热图)是数据的图形表示形式,其中矩阵中包含的各个值以颜色表示。热图的主要目的是更好地可视化数据集中的位置/事件量,并帮助引导查看者看到最重要的数据可视化区域。
由于依赖颜色来传达值,热图可能最常用于显示更通用的数值视图。热图在吸引人们对趋势的关注方面非常通用且高效,正是由于这些原因,它们在分析社区中变得越来越受欢迎。
热图本质上是不言自明的。色调越深,数量越大(值越高,分散越紧密等)。Plotly 的 graph_objects 模块包含Heatmap()函数。它需要 x、y和z属性。它们的值可以是列表、numpy 数组或 Pandas 数据框。
在下面的示例中,我们有一个二维列表或数组,用于将数据(不同农民的收获量,以吨/年为单位)定义为颜色代码。然后我们还需要两份农民名单和他们种植的蔬菜名单。
vegetables = [
"cucumber",
"tomato",
"lettuce",
"asparagus",
"potato",
"wheat",
"barley"
]
farmers = [
"Farmer Joe",
"Upland Bros.",
"Smith Gardening",
"Agrifun",
"Organiculture",
"BioGoods Ltd.",
"Cornylee Corp."
]
harvest = np.array(
[
[0.8, 2.4, 2.5, 3.9, 0.0, 4.0, 0.0],
[2.4, 0.0, 4.0, 1.0, 2.7, 0.0, 0.0],
[1.1, 2.4, 0.8, 4.3, 1.9, 4.4, 0.0],
[0.6, 0.0, 0.3, 0.0, 3.1, 0.0, 0.0],
[0.7, 1.7, 0.6, 2.6, 2.2, 6.2, 0.0],
[1.3, 1.2, 0.0, 0.0, 0.0, 3.2, 5.1],
[0.1, 2.0, 0.0, 1.4, 0.0, 1.9, 6.3]
]
)
trace = go.Heatmap(
x = vegetables,
y = farmers,
z = harvest,
type = 'heatmap',
colorscale = 'Viridis'
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)
上述代码的输出如下 -

Plotly - 极坐标图和雷达图
在本章中,我们将学习如何借助 Plotly 制作极坐标图和雷达图。
首先,我们来学习一下极坐标图。
极坐标图
极坐标图是圆形图的常见变体。当数据点之间的关系可以最容易地以半径和角度的形式可视化时,它非常有用。
在极坐标图中,系列由连接极坐标系中的点的闭合曲线表示。每个数据点由距极点的距离(径向坐标)和距固定方向的角度(角坐标)确定。
极坐标图表示沿径向轴和角轴的数据。径向坐标和角坐标由go.Scatterpolar()函数的r和theta参数给出。Theta 数据可以是分类数据,但是数值数据也是可能的,并且是最常用的。
以下代码生成一个基本的极坐标图。除了 r 和 theta 参数之外,我们还将模式设置为线条(可以将其设置为标记,在这种情况下仅显示数据点)。
import numpy as np r1 = [0,6,12,18,24,30,36,42,48,54,60] t1 = [1,0.995,0.978,0.951,0.914,0.866,0.809,0.743,0.669,0.588,0.5] trace = go.Scatterpolar( r = [0.5,1,2,2.5,3,4], theta = [35,70,120,155,205,240], mode = 'lines', ) data = [trace] fig = go.Figure(data = data) iplot(fig)
输出如下 -
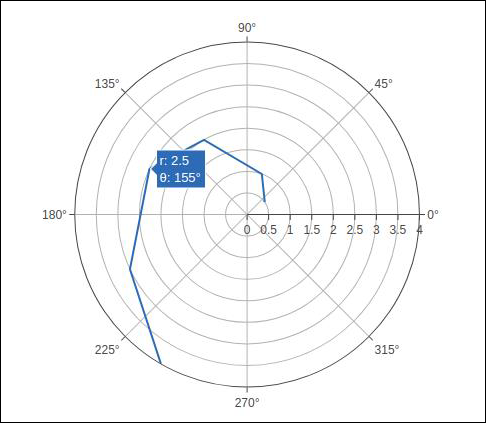
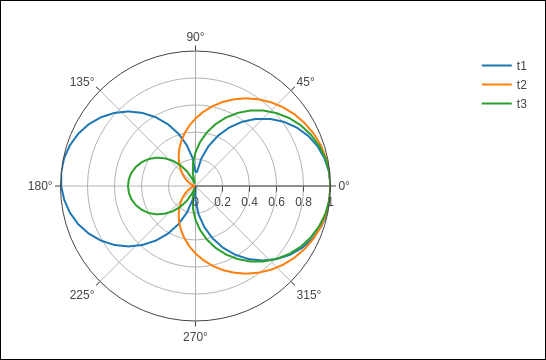
在以下示例中,使用逗号分隔值 (CSV) 文件中的数据来生成极坐标图。Polar.csv的前几行如下 -
y,x1,x2,x3,x4,x5, 0,1,1,1,1,1, 6,0.995,0.997,0.996,0.998,0.997, 12,0.978,0.989,0.984,0.993,0.986, 18,0.951,0.976,0.963,0.985,0.969, 24,0.914,0.957,0.935,0.974,0.946, 30,0.866,0.933,0.9,0.96,0.916, 36,0.809,0.905,0.857,0.943,0.88, 42,0.743,0.872,0.807,0.923,0.838, 48,0.669,0.835,0.752,0.901,0.792, 54,0.588,0.794,0.691,0.876,0.74, 60,0.5,0.75,0.625,0.85,0.685,
在笔记本的输入单元中输入以下脚本以生成极坐标图,如下所示 -
import pandas as pd
df = pd.read_csv("polar.csv")
t1 = go.Scatterpolar(
r = df['x1'], theta = df['y'], mode = 'lines', name = 't1'
)
t2 = go.Scatterpolar(
r = df['x2'], theta = df['y'], mode = 'lines', name = 't2'
)
t3 = go.Scatterpolar(
r = df['x3'], theta = df['y'], mode = 'lines', name = 't3'
)
data = [t1,t2,t3]
fig = go.Figure(data = data)
iplot(fig)
下面给出的是上述代码的输出 -
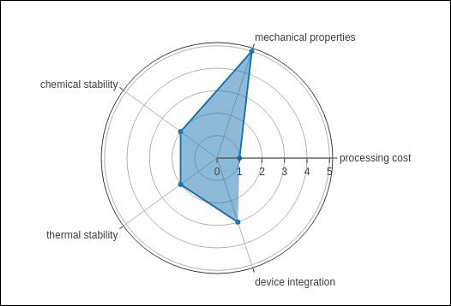
雷达图
雷达图(也称为蜘蛛图或星图)以定量变量二维图表的形式显示多变量数据,这些变量在源自中心的轴上表示。轴的相对位置和角度通常无法提供信息。
对于雷达图,一般情况下,在go.Scatterpolar()函数中使用带有分类角度变量的极坐标图。
以下代码使用Scatterpolar() 函数呈现基本雷达图-
radar = go.Scatterpolar(
r = [1, 5, 2, 2, 3],
theta = [
'processing cost',
'mechanical properties',
'chemical stability',
'thermal stability',
'device integration'
],
fill = 'toself'
)
data = [radar]
fig = go.Figure(data = data)
iplot(fig)
下面提到的输出是上面给出的代码的结果 -
OHLC 图、瀑布图和漏斗图
本章重点介绍其他三种类型的图表,包括 OHLC、瀑布图和漏斗图,这些图表可以借助 Plotly 制作。
OHLC 图表
开盘价-最高价-最低价-收盘图(也称为 OHLC)是一种条形图,通常用于说明股票等金融工具的价格变动。OHLC 图表很有用,因为它们显示了一段时间内的四个主要数据点。图表类型很有用,因为它可以显示增加或减少的动量。高点和低点数据对于评估波动性很有用。
图表上的每条垂直线显示一个时间单位(例如天或小时)内的价格范围(最高和最低价格)。刻度线从线的每一侧突出,指示左侧的开盘价(例如,对于每日条形图,这将是当天的起始价),以及右侧该时间段的收盘价。
用于演示 OHLC 图的示例数据如下所示。它具有与相应日期字符串上的最高价、最低价、开盘价和收盘价相对应的列表对象。使用 datetime 模块中的strtp()函数将字符串的日期表示形式转换为日期对象。
open_data = [33.0, 33.3, 33.5, 33.0, 34.1] high_data = [33.1, 33.3, 33.6, 33.2, 34.8] low_data = [32.7, 32.7, 32.8, 32.6, 32.8] close_data = [33.0, 32.9, 33.3, 33.1, 33.1] date_data = ['10-10-2013', '11-10-2013', '12-10-2013','01-10-2014','02-10-2014'] import datetime dates = [ datetime.datetime.strptime(date_str, '%m-%d-%Y').date() for date_str in date_data ]
我们必须使用上面的日期对象作为 x 参数,并使用其他参数作为返回 OHLC 跟踪的go.Ohlc()函数所需的开盘价、最高价、最低价和收盘价参数。
trace = go.Ohlc( x = dates, open = open_data, high = high_data, low = low_data, close = close_data ) data = [trace] fig = go.Figure(data = dat