- XML DOM 基础知识
- XML DOM - 主页
- XML DOM - 概述
- XML DOM - 模型
- XML DOM - 节点
- XML DOM - 节点树
- XML DOM - 方法
- XML DOM - 加载
- XML DOM - 遍历
- XML DOM - 导航
- XML DOM - 访问
- XML DOM 操作
- XML DOM - 获取节点
- XML DOM - 设置节点
- XML DOM - 创建节点
- XML DOM - 添加节点
- XML DOM - 替换节点
- XML DOM - 删除节点
- XML DOM - 克隆节点
- XML DOM 对象
- DOM - 节点对象
- DOM - 节点列表对象
- DOM - 命名节点映射对象
- DOM - DOMI 实现
- DOM - 文档类型对象
- DOM - 处理指令
- DOM-实体对象
- DOM - 实体引用对象
- DOM - 表示法对象
- DOM - 元素对象
- DOM - 属性对象
- DOM - CDATASection 对象
- DOM - 评论对象
- DOM - XMLHttpRequest 对象
- DOM - DOMException 对象
- XML DOM 有用的资源
- XML DOM - 快速指南
- XML DOM - 有用的资源
- XML DOM - 讨论
XML DOM - 快速指南
XML DOM - 概述
文档对象模型(DOM)是W3C标准。它定义了访问 HTML 和 XML 等文档的标准。
W3C对 DOM 的定义是 -
文档对象模型 (DOM) 是 HTML 和 XML 文档的应用程序编程接口 (API)。它定义了文档的逻辑结构以及访问和操作文档的方式。
DOM 定义了访问所有 XML 元素的对象、属性和方法(接口)。它分为 3 个不同的部分/级别 -
Core DOM - 任何结构化文档的标准模型
XML DOM - XML 文档的标准模型
HTML DOM - HTML 文档的标准模型
XML DOM 是 XML 的标准对象模型。XML 文档具有称为节点的信息单元的层次结构;DOM 是描述这些节点及其之间关系的标准编程接口。
由于 XML DOM 还提供了一个 API,允许开发人员在树上的任何点添加、编辑、移动或删除节点,以便创建应用程序。
下图是 DOM 结构图。该图描述了解析器通过遍历每个节点将 XML 文档评估为 DOM 结构。
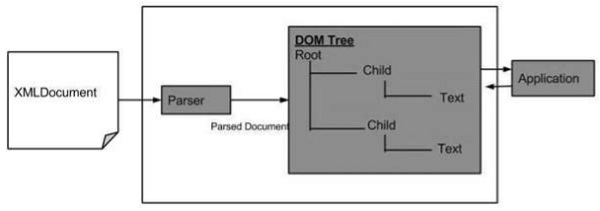
XML DOM 的优点
以下是 XML DOM 的优点。
XML DOM 与语言和平台无关。
XML DOM 是可遍历的- XML DOM 中的信息按层次结构组织,允许开发人员在层次结构中导航以查找特定信息。
XML DOM 是可修改的- 它本质上是动态的,为开发人员提供了在树上任何点添加、编辑、移动或删除节点的范围。
XML DOM 的缺点
它会消耗更多内存(如果 XML 结构很大),因为编写一次的程序一直保留在内存中,直到明确删除为止。
由于大量使用内存,其运行速度相比SAX要慢一些。
XML DOM - 模型
现在我们知道了 DOM 的含义,让我们看看什么是 DOM 结构。DOM 文档是按层次结构组织的节点或信息片段的集合。某些类型的节点可能具有各种类型的子节点,而其他类型的节点是在文档结构中其下不能有任何内容的叶节点。以下是节点类型的列表,以及它们可能作为子节点的节点类型的列表 -
文档- 元素(最多一个)、处理指令、注释、文档类型(最多一个)
DocumentFragment - 元素、处理指令、注释、文本、CDATASection、EntityReference
EntityReference - 元素、处理指令、注释、文本、CDATASection、EntityReference
元素- 元素、文本、注释、处理指令、CDATASection、EntityReference
Attr - 文本、EntityReference
处理指令- 没有子项
评论- 没有孩子
文本- 没有孩子
CDATASection - 没有子项
实体- 元素、处理指令、注释、文本、CDATASection、EntityReference
符号- 没有孩子
例子
考虑以下 XML 文档node.xml的 DOM 表示形式。
<?xml version = "1.0"?>
<Company>
<Employee category = "technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "non-technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>
上述 XML 文档的文档对象模型如下 -
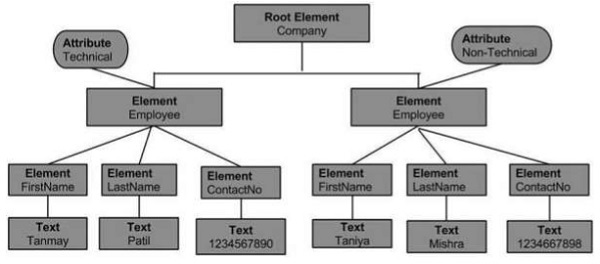
从上面的流程图,我们可以推断 -
节点对象只能有一个父节点对象。它占据所有节点之上的位置。这是公司。
父节点可以有多个称为子节点的节点。这些子节点可以具有称为属性节点的附加节点。在上面的示例中,我们有两个属性节点Technical和Non-technical。属性节点实际上并不是元素节点的子节点,但仍与其关联。
这些子节点又可以有多个子节点。节点内的文本称为文本节点。
同一级别的节点对象称为兄弟节点。
DOM 标识 -
表示界面和操作文档的对象。
对象和接口之间的关系。
XML DOM - 节点
在本章中,我们将研究 XML DOM节点。每个 XML DOM 都包含称为节点的分层单元中的信息,并且 DOM 描述这些节点以及它们之间的关系。
节点类型
以下流程图显示了所有节点类型 -
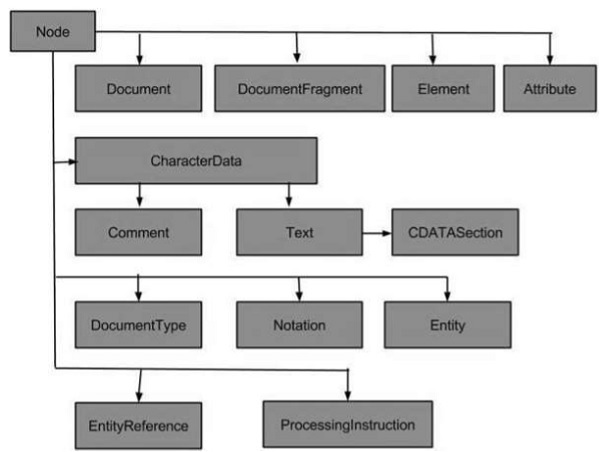
XML 中最常见的节点类型是 -
文档节点- 完整的 XML 文档结构是文档节点。
元素节点- 每个 XML 元素都是一个元素节点。这也是唯一可以具有属性的节点类型。
属性节点- 每个属性都被视为一个属性节点。它包含有关元素节点的信息,但实际上并不被视为该元素的子节点。
文本节点- 文档文本被视为文本节点。它可以包含更多信息或仅包含空白。
一些不太常见的节点类型是 -
CData 节点- 该节点包含解析器不应分析的信息。相反,它应该以纯文本形式传递。
注释节点- 该节点包含有关数据的信息,通常被应用程序忽略。
处理指令节点- 该节点包含专门针对应用程序的信息。
文档片段节点
实体节点
实体参考节点
符号节点
XML DOM - 节点树
在本章中,我们将研究 XML DOM节点树。在 XML 文档中,信息以层次结构维护;这种层次结构称为节点树。这种层次结构允许开发人员在树中导航以查找特定信息,从而允许节点访问。然后可以更新这些节点的内容。
节点树的结构从根元素开始,扩展到子元素,直到最低级别。
例子
下面的例子演示了一个简单的XML文档,其节点树结构如下图所示:
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>
从上面的例子中可以看出,其 DOM 的图形表示如下所示 -
树的最顶层节点称为根。根节点是<Company> ,它又包含<Employee> 的两个节点。这些节点称为子节点。
根节点 <Company> 的子节点 <Employee> 又由其自己的子节点 (<FirstName>、<LastName>、<ContactNo>) 组成。
两个子节点 <Employee> 具有属性值 Technical 和 Non-Technical,称为属性节点。
每个节点内的文本称为文本节点。
XML DOM - 方法
DOM 作为 API 包含表示可在 XML 文档中找到的不同类型信息的接口,例如元素和文本。这些接口包括使用这些对象所需的方法和属性。属性定义节点的特征,而方法提供操作节点的方法。
下表列出了 DOM 类和接口 -
| 编号 | 接口及说明 |
|---|---|
| 1 | DOM实现 它提供了许多用于执行独立于文档对象模型的任何特定实例的操作的方法。 |
| 2 | 文档片段 它是“轻量级”或“最小”文档对象,并且它(作为 Document 的超类)将 XML/HTML 树锚定在成熟的文档中。 |
| 3 | 文档 它代表 XML 文档的顶级节点,提供对文档中所有节点(包括根元素)的访问。 |
| 4 | 节点 它代表 XML 节点。 |
| 5 | 节点列表 它表示Node对象的只读列表。 |
| 6 | 命名节点映射 它表示可以通过名称访问的节点的集合。 |
| 7 | 数据 它使用一组属性和方法扩展了Node ,用于访问 DOM 中的字符数据。 |
| 8 | 属性 它表示 Element 对象中的属性。 |
| 9 | 元素 它代表元素节点。源自节点。 |
| 10 | 文本 它代表文本节点。派生自CharacterData。 |
| 11 | 评论 它代表评论节点。派生自CharacterData。 |
| 12 | 加工说明 它代表一条“处理指令”。它在 XML 中用作将处理器特定信息保留在文档文本中的一种方式。 |
| 13 | CDATA部分 它代表 CDATA 部分。源自文本。 |
| 14 | 实体 它代表一个实体。源自节点。 |
| 15 | 实体引用 这代表树中的实体引用。源自节点。 |
我们将在各自的章节中讨论上述每个接口的方法和属性。
XML DOM - 加载
在本章中,我们将学习 XML加载和解析。
为了描述API提供的接口,W3C使用一种称为接口定义语言(IDL)的抽象语言。使用 IDL 的优点是开发人员可以学习如何使用他或她最喜欢的语言来使用 DOM,并且可以轻松切换到不同的语言。
缺点是,由于IDL是抽象的,Web开发人员不能直接使用IDL。由于编程语言之间的差异,它们需要在抽象接口与其具体语言之间进行映射(或绑定)。DOM 已映射到 Javascript、JScript、Java、C、C++、PLSQL、Python 和 Perl 等编程语言。
在接下来的章节中,我们将使用 Javascript 作为编程语言来加载 XML 文件。
解析器
解析器是一种软件应用程序,旨在分析文档(在我们的例子中是 XML 文档)并对该信息执行特定操作。下表列出了一些基于 DOM 的解析器 -
| 序列号 | 解析器和描述 |
|---|---|
| 1 |
JAXP Sun Microsystem 的用于 XML 解析的 Java API (JAXP) |
| 2 | XML4J IBM 的 Java XML 解析器 (XML4J) |
| 3 | 微软XML Microsoft 的 XML 解析器 (msxml) 2.0 版内置于 Internet Explorer 5.5 中 |
| 4 | 4DOM 4DOM 是 Python 编程语言的解析器 |
| 5 | XML::DOM XML::DOM 是一个 Perl 模块,用于使用 Perl 操作 XML 文档 |
| 6 | 薛西斯 Apache 的 Xerces Java 解析器 |
在像 DOM 这样的基于树的 API 中,解析器遍历 XML 文件并创建相应的 DOM 对象。然后就可以来回遍历 DOM 结构了。
加载和解析 XML
加载 XML 文档时,XML 内容可以有两种形式 -
- 直接作为 XML 文件
- 作为 XML 字符串
XML 文件形式的内容
以下示例演示了当 XML 内容作为 XML 文件接收时如何使用 Ajax 和 Javascript 加载 XML ( node.xml ) 数据。这里,Ajax 函数获取 xml 文件的内容并将其存储在 XML DOM 中。一旦创建了 DOM 对象,就会对其进行解析。
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>ContactNo:</b> <span id = "ContactNo"></span><br>
<b>Email:</b> <span id = "Email"></span>
</div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest();
} else { // code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
xmlDoc = xmlhttp.responseXML;
//parsing the DOM object
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("ContactNo").innerHTML =
xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue;
document.getElementById("Email").innerHTML =
xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
节点.xml
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
大部分代码细节都在脚本代码中。
Internet Explorer 使用ActiveXObject("Microsoft.XMLHTTP")创建 XMLHttpRequest 对象的实例,其他浏览器使用XMLHttpRequest()方法。
responseXML直接在 XML DOM中转换 XML 内容。
一旦 XML 内容转换为 JavaScript XML DOM,您就可以使用 JS DOM 方法和属性来访问任何 XML 元素。我们使用了 DOM 属性,例如childNodes、nodeValue和 DOM 方法,例如 getElementsById(ID)、getElementsByTagName(tags_name)。
执行
将此文件另存为loadingexample.html 并在浏览器中打开它。您将收到以下输出 -

XML 字符串形式的内容
以下示例演示了当 XML 内容作为 XML 文件接收时如何使用 Ajax 和 Javascript 加载 XML 数据。这里,Ajax 函数获取 xml 文件的内容并将其存储在 XML DOM 中。一旦 DOM 对象被创建,它就会被解析。
<!DOCTYPE html>
<html>
<head>
<script>
// loads the xml string in a dom object
function loadXMLString(t) { // for non IE browsers
if (window.DOMParser) {
// create an instance for xml dom object parser = new DOMParser();
xmlDoc = parser.parseFromString(t,"text/xml");
}
// code for IE
else { // create an instance for xml dom object
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.loadXML(t);
}
return xmlDoc;
}
</script>
</head>
<body>
<script>
// a variable with the string
var text = "<Employee>";
text = text+"<FirstName>Tanmay</FirstName>";
text = text+"<LastName>Patil</LastName>";
text = text+"<ContactNo>1234567890</ContactNo>";
text = text+"<Email>tanmaypatil@xyz.com</Email>";
text = text+"</Employee>";
// calls the loadXMLString() with "text" function and store the xml dom in a variable
var xmlDoc = loadXMLString(text);
//parsing the DOM object
y = xmlDoc.documentElement.childNodes;
for (i = 0;i<y.length;i++) {
document.write(y[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
大部分代码细节都在脚本代码中。
Internet Explorer 使用ActiveXObject("Microsoft.XMLDOM")将 XML 数据加载到 DOM 对象中,其他浏览器使用DOMParser()函数和parseFromString(text, 'text/xml')方法。
变量文本应包含带有 XML 内容的字符串。
一旦 XML 内容转换为 JavaScript XML DOM,您就可以使用 JS DOM 方法和属性来访问任何 XML 元素。我们使用了 DOM 属性,例如childNodes、nodeValue。
执行
将此文件另存为loadingexample.html 并在浏览器中打开它。您将看到以下输出 -

现在我们已经了解了 XML 内容如何转换为 JavaScript XML DOM,您现在可以使用 XML DOM 方法访问任何 XML 元素。
XML DOM - 遍历
在本章中,我们将讨论 XML DOM 遍历。我们在上一章学习了如何加载XML文档并解析由此获得的DOM对象。可以遍历这个解析后的 DOM 对象。遍历是通过一步步遍历节点树中的每一个元素,以系统的方式进行循环的过程。
例子
以下示例(traverse_example.htm)演示了 DOM 遍历。这里我们遍历<Employee>元素的每个子节点。
<!DOCTYPE html>
<html>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center">
<tr>
<th>Employee Category</th>
<th>FirstName</th>
<th>LastName</th>
<th>ContactNo</th>
<th>Email</th>
</tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr>
<td>'+ employee_cat+ '</td>
<td>'+ employee_firstName+ '</td>
<td>'+ employee_lastName+ '</td>
<td>'+ employee_contactno+ '</td>
<td>'+ employee_email+ '</td>
</tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>
此代码加载node.xml。
XML 内容被转换为 JavaScript XML DOM 对象。
使用 getElementsByTagName() 方法获得元素数组(带有标签 Element)。
接下来,我们遍历这个数组并在表格中显示子节点值。
执行
将此文件保存为服务器路径上的traverse_example.html (此文件和 node.xml 应位于服务器中的同一路径上)。您将收到以下输出 -

XML DOM - 导航
到目前为止我们学习了 DOM 结构,如何加载和解析 XML DOM 对象以及遍历 DOM 对象。在这里,我们将了解如何在 DOM 对象中的节点之间导航。XML DOM 由节点的各种属性组成,这些属性帮助我们在节点中导航,例如 -
- 父节点
- 子节点
- 第一个孩子
- 最后一个孩子
- 下一个兄弟姐妹
- 上一个兄弟姐妹
下图是节点树图,显示了它与其他节点的关系。
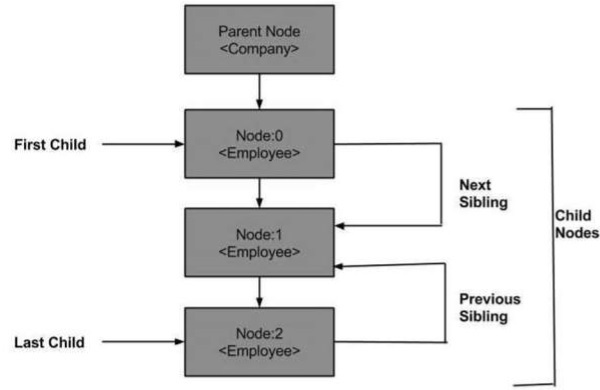
DOM - 父节点
该属性将父节点指定为节点对象。
例子
以下示例 (navigate_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象。然后 DOM 对象通过子节点导航到父节点 -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
var y = xmlDoc.getElementsByTagName("Employee")[0];
document.write(y.parentNode.nodeName);
</script>
</body>
</html>
正如您在上面的示例中看到的,子节点Employee导航到其父节点。
执行
在服务器路径上将此文件保存为navigate_example.html (此文件和node.xml应位于服务器中的同一路径上)。在输出中,我们得到Employee的父节点,即Company。
第一个孩子
该属性属于Node类型,表示 NodeList 中存在的第一个子名称。
例子
以下示例 (first_node_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,然后导航到 DOM 对象中存在的第一个子节点。
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_firstChild(p) {
a = p.firstChild;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(firstchild.nodeName);
</script>
</body>
</html>
函数get_firstChild(p)用于避免空节点。它有助于从节点列表中获取第一个子元素。
x = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0])获取标签名称Employee的第一个子节点。
执行
将此文件保存为服务器路径上的first_node_example.htm (此文件和node.xml应位于服务器中的同一路径上)。在输出中,我们得到Employee的第一个子节点, 即FirstName。
最后一个孩子
此属性属于Node类型,表示 NodeList 中存在的最后一个子名称。
例子
以下示例 (last_node_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,然后导航到 xml DOM 对象中存在的最后一个子节点。
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_lastChild(p) {
a = p.lastChild;
while (a.nodeType != 1){
a = a.previousSibling;
}
return a;
}
var lastchild = get_lastChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(lastchild.nodeName);
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的last_node_example.htm (此文件和node.xml 应位于服务器中的同一路径上)。在输出中,我们得到Employee 的最后一个子节点,即Email。
下一个兄弟姐妹
该属性的类型为Node,代表下一个子元素,即 NodeList 中存在的指定子元素的下一个兄弟元素。
例子
以下示例 (nextSibling_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,该对象立即导航到 xml 文档中存在的下一个节点。
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
}
else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_nextSibling(p) {
a = p.nextSibling;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var nextsibling = get_nextSibling(xmlDoc.getElementsByTagName("FirstName")[0]);
document.write(nextsibling.nodeName);
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的nextSibling_example.htm (此文件和 node.xml 应位于服务器中的同一路径上)。在输出中,我们得到FirstName 的下一个兄弟节点,即LastName。
以前的兄弟姐妹
该属性的类型为Node,表示前一个子元素,即 NodeList 中存在的指定子元素的前一个同级元素。
例子
以下示例 (previoussibling_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,然后导航 xml 文档中存在的最后一个子节点的 before 节点。
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest)
{
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_previousSibling(p) {
a = p.previousSibling;
while (a.nodeType != 1) {
a = a.previousSibling;
}
return a;
}
prevsibling = get_previousSibling(xmlDoc.getElementsByTagName("Email")[0]);
document.write(prevsibling.nodeName);
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的previoussibling_example.htm (此文件和node.xml应位于服务器中的同一路径上)。在输出中,我们得到了Email的前一个同级节点,即ContactNo。
XML DOM - 访问
在本章中,我们将研究如何访问被视为 XML 文档信息单元的 XML DOM 节点。XML DOM 的节点结构允许开发人员在树中导航以查找特定信息并同时访问该信息。
访问节点
以下是访问节点的三种方式 -
通过使用getElementsByTagName ()方法
通过循环或遍历节点树
通过导航节点树,使用节点关系
通过标签名称获取元素 ()
该方法允许通过指定节点名称来访问节点的信息。它还允许访问节点列表和节点列表长度的信息。
句法
getElementByTagName() 方法具有以下语法 -
node.getElementByTagName("tagname");
在哪里,
节点- 是文档节点。
tagname - 保存您想要获取其值的节点的名称。
例子
以下是一个简单的程序,说明了 getElementByTagName 方法的用法。
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>Category:</b> <span id = "Employee"></span><br>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("Employee").innerHTML =
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue;
</script>
</body>
</html>
在上面的示例中,我们正在访问节点FirstName、 LastName和Employee的信息。
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue; 此行使用 getElementByTagName() 方法访问子节点FirstName的值。
xmlDoc.getElementsByTagName("员工")[0].attributes[0].nodeValue; 此行访问节点Employee getElementByTagName() 方法的属性值。
遍历节点
DOM 遍历一章中的示例对此进行了介绍。
浏览节点
DOM 导航一章中的示例对此进行了介绍。
XML DOM - 获取节点
在本章中,我们将研究如何获取XML DOM 对象的节点值。XML 文档具有称为节点的信息单元层次结构。Node 对象有一个属性nodeValue,它返回元素的值。
在以下部分中,我们将讨论 -
获取元素的节点值
获取节点的属性值
以下所有示例中使用的node.xml如下-
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
获取节点值
getElementsByTagName()方法返回具有给定标签名称的按文档顺序排列的所有元素的NodeList 。
例子
以下示例 (getnode_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并提取子节点Firstname的节点值(索引为 0) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('FirstName')[0]
y = x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的getnode_example.htm (此文件和 node.xml 应位于服务器中的同一路径上)。在输出中,我们得到的节点值为Tanmay。
获取属性值
属性是 XML 节点元素的一部分。一个节点元素可以有多个唯一的属性。属性提供有关 XML 节点元素的更多信息。更准确地说,它们定义了节点元素的属性。XML 属性始终是名称/值对。该属性的值称为属性节点。
getAttribute ()方法通过元素名称检索属性值。
例子
以下示例 (get_attribute_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并提取类别Employee的属性值(索引为 2) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('Employee')[2];
document.write(x.getAttribute('category'));
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的get_attribute_example.htm (此文件和 node.xml 应位于服务器中的同一路径上)。在输出中,我们得到的属性值为Management。
XML DOM - 设置节点
在本章中,我们将研究如何更改 XML DOM 对象中的节点值。节点值可以更改如下 -
var value = node.nodeValue;
如果节点是属性,则值变量将是属性的值;如果节点是文本节点,则它将是文本内容;如果节点是一个Element它将是null。
以下部分将演示每种节点类型(属性、文本节点和元素)的节点值设置。
以下所有示例中使用的node.xml如下-
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
更改文本节点的值
当我们说 Node 元素的更改值时,我们的意思是编辑元素(也称为文本节点)的文本内容。以下示例演示了如何更改元素的文本节点。
例子
以下示例 (set_text_node_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象并更改元素的文本节点的值。在本例中,将每个员工的电子邮件发送至support@xyz.com并打印值。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Email");
for(i = 0;i<x.length;i++) {
x[i].childNodes[0].nodeValue = "support@xyz.com";
document.write(i+');
document.write(x[i].childNodes[0].nodeValue);
document.write('<br>');
}
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的set_text_node_example.htm (此文件和node.xml应位于服务器中的同一路径上)。您将收到以下输出 -
0) support@xyz.com 1) support@xyz.com 2) support@xyz.com
改变属性节点的值
以下示例演示了如何更改元素的属性节点。
例子
以下示例 (set_attribute_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象并更改元素属性节点的值。在这种情况下,每个员工的类别分别为admin-0、admin-1、admin-2并打印值。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Employee");
for(i = 0 ;i<x.length;i++){
newcategory = x[i].getAttributeNode('category');
newcategory.nodeValue = "admin-"+i;
document.write(i+');
document.write(x[i].getAttributeNode('category').nodeValue);
document.write('<br>');
}
</script>
</body>
</html>
执行
将此文件保存为服务器路径上的set_node_attribute_example.htm (此文件和node.xml应位于服务器中的同一路径上)。结果如下 -
0) admin-0 1) admin-1 2) admin-2
XML DOM - 创建节点
在本章中,我们将讨论如何使用文档对象的几个方法创建新节点。这些方法提供了创建新元素节点、文本节点、注释节点、CDATA 节节点和属性节点的范围。如果新创建的节点已存在于元素对象中,则将其替换为新节点。以下部分通过示例对此进行了演示。
创建新的元素节点
createElement()方法创建一个新的元素节点。如果新创建的元素节点存在于元素对象中,则将其替换为新的元素节点。
句法
使用createElement()方法的语法如下 -
var_name = xmldoc.createElement("tagname");
在哪里,
var_name - 是用户定义的变量名称,它保存新元素的名称。
(“tagname”) - 是要创建的新元素节点的名称。
例子
以下示例 (createnewelement_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并在 XML 文档中创建一个新元素节点PhoneNo 。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
new_element = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(new_element);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>
new_element = xmlDoc.createElement("电话号码"); 创建新元素节点 <PhoneNo>
x.appendChild(new_element); x保存新元素节点所附加到的指定子节点 <FirstName> 的名称。
执行
将此文件保存为服务器路径上的createnewelement_example.htm (此文件和node.xml应位于服务器中的同一路径上)。在输出中,我们得到的属性值为PhoneNo。
创建新的文本节点
createTextNode()方法创建一个新的文本节点。
句法
使用createTextNode()的语法如下 -
var_name = xmldoc.createTextNode("tagname");
在哪里,
var_name - 它是用户定义的变量名称,保存新文本节点的名称。
(“tagname”) - 括号内是要创建的新文本节点的名称。
例子
以下示例 (createtextnode_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并在 XML 文档中创建一个新文本节点(即新文本节点) 。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
create_t = xmlDoc.createTextNode("Im new text node");
create_e.appendChild(create_t);
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_e);
document.write(" PhoneNO: ");
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue);
</script>
</body>
</html>
上述代码的详细信息如下 -
create_e = xmlDoc.createElement("电话号码"); 创建一个新元素<PhoneNo>。
create_t = xmlDoc.createTextNode("我是新的文本节点"); 创建一个新的文本节点“Im new text node”。
x.appendChild(create_e); 文本节点“Im new text node”被附加到元素<PhoneNo>。
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue); 将新的文本节点值写入元素 <PhoneNo>。
执行
将此文件保存为服务器路径上的createtextnode_example.htm (此文件和node.xml 应位于服务器中的同一路径上)。在输出中,我们得到属性值,即PhoneNO: Im new text node。
创建新的评论节点
createComment()方法创建一个新的注释节点。程序中包含注释节点,以便于理解代码功能。
句法
使用createComment()的语法如下 -
var_name = xmldoc.createComment("tagname");
在哪里,
var_name - 是用户定义的变量名称,它保存新注释节点的名称。
(“tagname”) - 是要创建的新注释节点的名称。
例子
以下示例 (createcommentnode_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的注释节点“Company 是父节点” 。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_comment = xmlDoc.createComment("Company is the parent node");
x = xmlDoc.getElementsByTagName("Company")[0];
x.appendChild(create_comment);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>
在上面的例子中 -
create_comment = xmlDoc.createComment("Company 是父节点") 创建指定的注释行。
x.appendChild(create_comment)在此行中,“x”保存注释行所附加到的元素 <Company> 的名称。
执行
将此文件保存为服务器路径上的createcommentnode_example.htm (此文件和node.xml应位于服务器中的同一路径上)。在输出中,我们得到属性值,因为Company 是父节点。
创建新的CDATA 节节点
createCDATASection()方法创建一个新的 CDATA 节节点。如果元素对象中存在新创建的 CDATA 节节点,则将其替换为新节点。
句法
使用createCDATASection()的语法如下 -
var_name = xmldoc.createCDATASection("tagname");
在哪里,
var_name - 是用户定义的变量名称,它保存新的 CDATA 节节点的名称。
(“tagname”) - 是要创建的新 CDATA 节节点的名称。
例子
以下示例 (createcdatanode_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并在 XML 文档中创建一个新的 CDATA 节节点“Create CDATA Example” 。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example");
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_CDATA);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>
在上面的例子中 -
create_CDATA = xmlDoc.createCDATASection("创建 CDATA 示例")创建一个新的 CDATA 节节点,"创建 CDATA 示例"
x.appendChild(create_CDATA)此处,x保存索引为 0 的指定元素 <Employee>,并将 CDATA 节点值附加到该元素。
执行
将此文件保存为服务器路径上的createcdatanode_example.htm (此文件和node.xml 应位于服务器中的同一路径上)。在输出中,我们得到的属性值是Create CDATA Example。
创建新的属性节点
要创建新的属性节点,请使用setAttributeNode()方法。如果元素对象中存在新创建的属性节点,则将其替换为新的属性节点。
句法
使用createElement()方法的语法如下 -
var_name = xmldoc.createAttribute("tagname");
在哪里,
var_name - 是用户定义的变量名称,它保存新属性节点的名称。
(“tagname”) - 是要创建的新属性节点的名称。
例子
以下示例 (createattributenode_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并在 XML 文档中创建新的属性节点部分。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_a = xmlDoc.createAttribute("section");
create_a.nodeValue = "A";
x = xmlDoc.getElementsByTagName("Employee");
x[0].setAttributeNode(create_a);
document.write("New Attribute: ");
document.write(x[0].getAttribute("section"));
</script>
</body>
</html>
在上面的例子中 -
create_a=xmlDoc.createAttribute("Category")创建一个名为 <section> 的属性。
create_a.nodeValue="Management"为属性 <section>创建值“A” 。
x[0].setAttributeNode(create_a)该属性值设置为索引为 0 的节点元素 <Employee>。
XML DOM - 添加节点
在本章中,我们将讨论现有元素的节点。它提供了一种方法 -
在现有子节点之前或之后追加新的子节点
在文本节点中插入数据
添加属性节点
以下方法可用于将节点添加/附加到 DOM 中的元素 -
- 追加子对象()
- 在()之前插入
- 插入数据()
追加子对象()
方法appendChild()在现有子节点之后添加新的子节点。
句法
appendChild() 方法的语法如下 -
Node appendChild(Node newChild) throws DOMException
在哪里,
newChild - 是要添加的节点
该方法返回添加的Node。
例子
以下示例 (appendchildnode_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并将新的子PhoneNo附加到元素 <FirstName>。
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(create_e);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>
在上面的例子中 -
使用方法createElement(),创建一个新元素PhoneNo 。
使用方法appendChild()将新元素PhoneNo添加到元素FirstName 。
执行
将此文件保存为服务器路径上的appendchildnode_example.htm (此文件和node.xml 应位于服务器中的同一路径上)。在输出中,我们得到的属性值为PhoneNo。
在()之前插入
insertBefore()方法将新的子节点插入到指定的子节点之前。
句法
insertBefore() 方法的语法如下 -
Node insertBefore(Node newChild, Node refChild) throws DOMException
在哪里,
newChild - 是要插入的节点
refChild - 是参考节点,即必须在其之前插入新节点的节点。
该方法返回正在插入的节点。
例子
以下示例 (insertnodebefore_example.htm) 将 XML 文档 ( node.xml ) 解析为 XML DOM 对象,并在指定元素 <Email> 之前插入新的子Email 。
<!DOCTYPE html>
<html>
<head>
<script>
function load