- ggplot2 教程
- ggplot2 - 主页
- ggplot2 - 简介
- ggplot2 - R 的安装
- ggplot2 - R 中的默认绘图
- ggplot2 - 使用轴
- ggplot2 - 使用图例
- ggplot2 - 散点图和抖动图
- ggplot2 - 条形图和直方图
- ggplot2 - 饼图
- ggplot2 - 边缘图
- ggplot2 - 气泡图和计数图表
- ggplot2 - 发散图表
- ggplot2 - 主题
- ggplot2 - 多面板图
- ggplot2 - 多图
- ggplot2 - 背景颜色
- ggplot2 - 时间序列
- ggplot2 有用的资源
- ggplot2 - 快速指南
- ggplot2 - 有用的资源
- ggplot2 - 讨论
ggplot2 - 快速指南
ggplot2 - 简介
ggplot2 是一个 R 包,专为数据可视化和提供最佳探索性数据分析而设计。它提供了美丽、无忧无虑的绘图,可以处理微小的细节,例如绘制图例并表示它们。可以迭代地创建绘图并在以后进行编辑。该软件包设计为以分层方式工作,首先显示使用 R 进行探索性数据分析期间收集的原始数据的层,然后添加注释和统计摘要层。
即使是最有经验的 R 用户也需要帮助来创建优雅的图形。该库是在 R 中创建图形的出色工具,但即使经过多年的几乎日常使用,我们仍然需要参考我们的备忘单。
该包在称为“图形语法”的深层语法下工作,它由一组可以通过多种方式创建的独立组件组成。“图形语法”是使 ggplot2 非常强大的唯一原因,因为 R 开发人员不限于其他软件包中使用的一组预先指定的图形。语法包括一组简单的核心规则和原则。
2005年,威尔金森创建了或者更确切地说是首创了图形语法的概念,以描述所有统计图形之间包含的深层特征。它侧重于主要层,其中包括调整 R 嵌入的功能。
《图形语法》与R的关系
它告诉用户或开发人员,统计图形用于将数据映射到美学属性,例如相关几何对象(如点、线和条)的颜色、形状、大小。该图还可以包含在提到的坐标系上绘制的相关数据的各种统计变换。它还包括一个称为“Faceting”的功能,该功能通常用于为上述数据集的不同子集创建相同的图。R 包含各种内置数据集。这些独立的组成部分的组合就完整地构成了一个特定的图形。
现在让我们关注可以参考语法创建的不同类型的绘图 -
数据
如果用户想要可视化给定的一组美学映射,该映射描述了如何将数据中所需的变量映射在一起以创建映射的美学属性。
层数
它由几何元素和所需的统计变换组成。图层包括几何对象、短数据几何对象,它们实际上借助点、线、多边形等来表示绘图。最好的演示是对观测值进行分箱和计数,以创建特定的直方图来总结特定线性模型的二维关系。
秤
比例尺用于映射数据空间中的值,该数据空间用于创建值,无论是颜色、大小还是形状。它有助于绘制提供逆映射所需的图例或轴,从而可以从上述图中读取原始数据值。
坐标系
它描述了如何将数据坐标一起映射到所提到的图形平面。它还提供读取图表所需的轴和网格线信息。通常它被用作笛卡尔坐标系,其中包括极坐标和地图投影。
刻面
它包括有关如何将数据分解为所需子集以及如何将子集显示为数据的倍数的规范。这也称为调节或网格化过程。
主题
它控制显示的细节,例如字体大小和背景颜色属性。为了创造一个有吸引力的Plotly,最好考虑参考文献。
现在,讨论语法不提供的限制或功能也同样重要 -
它缺乏应使用哪些图形或用户有兴趣做什么的建议。
它不描述交互性,因为它仅包括静态图形的描述。为了创建动态图形,应应用其他替代解决方案。
下面提到了用 ggplot2 创建的简单图表 -

ggplot2 - R 的安装
R 包具有各种功能,例如分析统计信息或深入研究地理空间数据,或者我们可以简单地创建基本报告。
R 包可以定义为具有明确定义格式的 R 函数、数据和编译代码。存储包的文件夹或目录称为库。

如上图所示,libPaths()是显示所在库的函数,库函数显示库中保存的包。
R 包含许多操作包的函数。我们将重点关注主要使用的三个主要功能,它们是 -
- 安装包
- 加载包
- 了解套餐
在 R 中安装包的函数语法是 -
Install.packages(“<package-name>”)
安装软件包的简单演示如下所示。考虑到我们需要安装数据可视化库“ggplot2”包,使用以下语法 -
Install.packages(“ggplot2”)

要加载特定的包,我们需要遵循下面提到的语法 -
Library(<package-name>)
这同样适用于 ggplot2,如下所述 -
library(“ggplot2”)
输出如下面的快照所示 -

为了了解所需包和基本功能的需求,R 提供了帮助功能,该功能提供了已安装包的完整详细信息。
完整的语法如下 -
help(ggplot2)

ggplot2 - R 中的默认绘图
在本章中,我们将重点关注在 ggplot2 的帮助下创建一个简单的绘图。我们将使用以下步骤在 R 中创建默认绘图。
将库和数据集包含在工作区中
将库包含在 R 中。加载所需的包。现在我们将重点关注 ggplot2 包。
# Load ggplot2 library(ggplot2)
我们将实现名为“Iris”的数据集。该数据集包含 3 个类,每个类 50 个实例,其中每个类指一种鸢尾植物。一类与其他两类是线性可分的;后者彼此不可线性分离。
# Read in dataset data(iris)
数据集中包含的属性列表如下 -

使用样本图的属性
以更简单的方式使用 ggplot2 绘制 iris 数据集图涉及以下语法 -
# Plot IrisPlot <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point() print(IrisPlot)
第一个参数将数据集作为输入,第二个参数提到需要在数据库中绘制的图例和属性。在此示例中,我们使用图例物种。Geom_point() 表示散点图,这将在后面的章节中详细讨论。
生成的输出如下 -

在这里我们可以修改标题、x 标签和 y 标签,这意味着系统格式的 x 轴和 y 轴标签,如下所示 -
print(IrisPlot + labs(y="Petal length (cm)", x = "Sepal length (cm)")
+ ggtitle("Petal and sepal length of iris"))

ggplot2 - 使用轴
当我们谈论图中的轴时,都是关于以二维方式表示的 x 和 y 轴。在本章中,我们将重点关注数据科学家常用的两个数据集“Plantgrowth”和“Iris”数据集。
在 Iris 数据集中实现轴
我们将使用 R 的 ggplot2 包按照以下步骤处理 x 和 y 轴。
加载库以获得包的功能始终很重要。
# Load ggplot library(ggplot2) # Read in dataset data(iris)
创建绘图点
就像前一章中讨论的那样,我们将创建一个包含点的绘图。换句话说,它被定义为散点图。
# Plot p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point() p
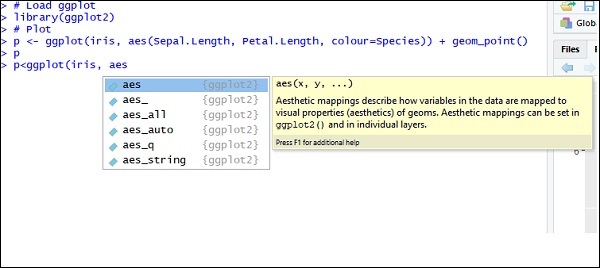
现在让我们了解一下aes的功能,其中提到了“ggplot2”的映射结构。美学映射描述了绘图所需的变量结构以及应以单层格式管理的数据。
输出如下 -
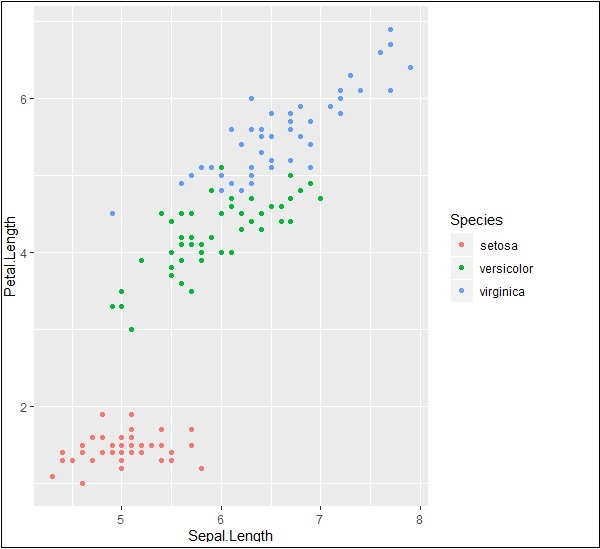
突出显示和刻度线
使用提到的 x 轴和 y 轴坐标绘制标记,如下所述。它包括添加文本、重复文本、突出显示特定区域和添加片段,如下所示 -
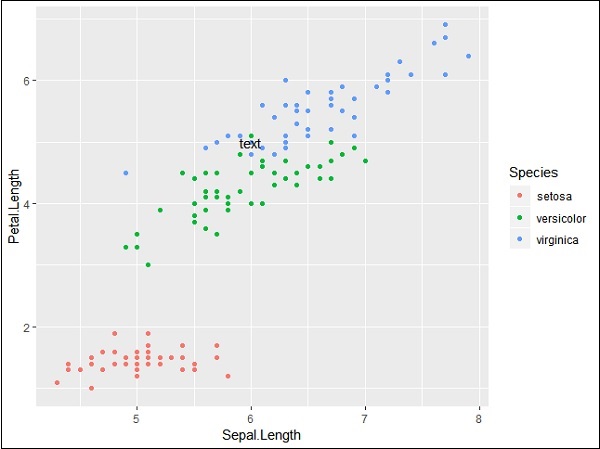
# add text
p + annotate("text", x = 6, y = 5, label = "text")
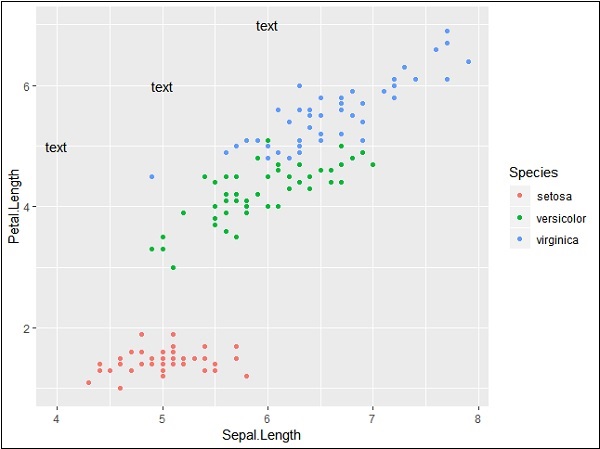
# add repeat
p + annotate("text", x = 4:6, y = 5:7, label = "text")
# highlight an area
p + annotate("rect", xmin = 5, xmax = 7, ymin = 4, ymax = 6, alpha = .5)
# segment
p + annotate("segment", x = 5, xend = 7, y = 4, yend = 5, colour = "black")
添加文本生成的输出如下 -
使用提到的坐标重复特定文本会生成以下输出。生成的文本的 x 坐标为 4 到 6,y 坐标为 5 到 7 -
特定区域输出的分割和突出显示如下 -
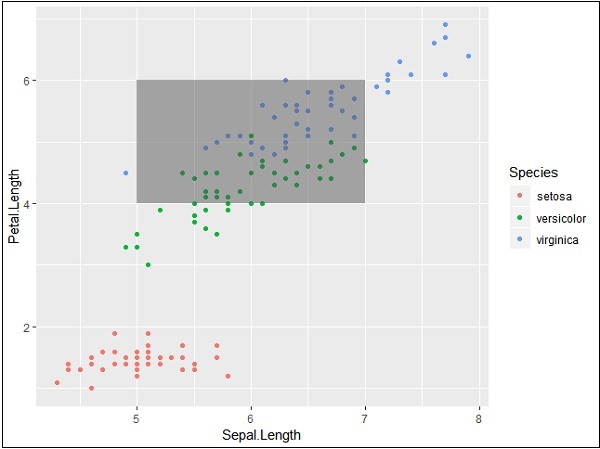
植物生长数据集
现在让我们专注于使用名为“Plantgrowth”的其他数据集,下面给出了所需的步骤。
前往图书馆查看“Plantgrowth”的属性。该数据集包括比较在对照和两种不同处理条件下获得的产量(按植物干重测量)的实验结果。
> PlantGrowth weight group 1 4.17 ctrl 2 5.58 ctrl 3 5.18 ctrl 4 6.11 ctrl 5 4.50 ctrl 6 4.61 ctrl 7 5.17 ctrl 8 4.53 ctrl 9 5.33 ctrl 10 5.14 ctrl 11 4.81 trt1 12 4.17 trt1 13 4.41 trt1 14 3.59 trt1 15 5.87 trt1 16 3.83 trt1 17 6.03 trt1
使用轴添加属性
尝试使用图形所需的 x 和 y 轴绘制一个简单的图,如下所述 -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) + + geom_point() > bp
生成的输出如下 -
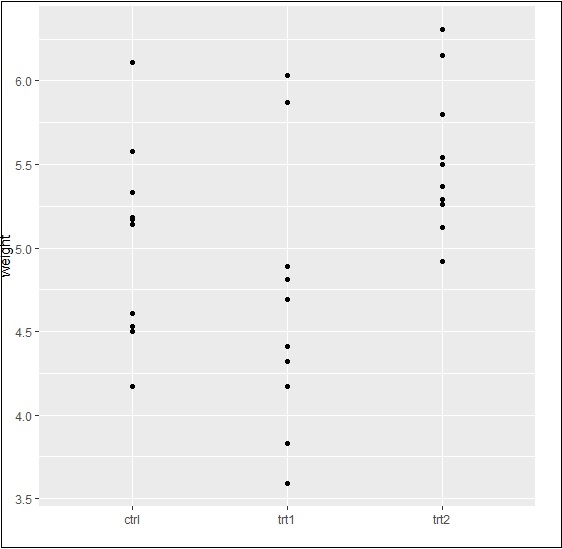
最后,我们可以根据我们的要求使用基本功能滑动 x 和 y 轴,如下所述 -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) + + geom_point() > bp
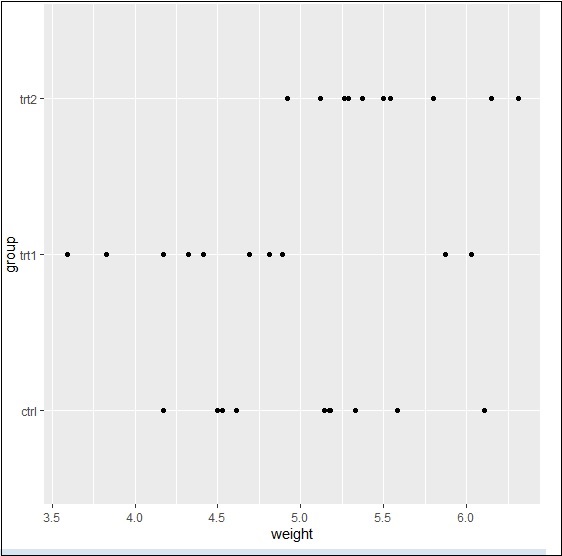
基本上,我们可以使用许多具有美学映射的属性来使用 ggplot2 来处理轴。
ggplot2 - 使用图例
轴和图例统称为指南。它们使我们能够从图中读取观察结果并将其映射回原始值。图例键和刻度标签均由刻度分隔符决定。图例和轴是根据绘图所需的相应比例和几何图形自动生成的。
将执行以下步骤来了解 ggplot2 中图例的工作原理 -
将包和数据集包含在工作区中
让我们创建相同的图来关注使用 ggplot2 生成的图的图例 -
> # Load ggplot > library(ggplot2) > > # Read in dataset > data(iris) > > # Plot > p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point() > p

如果您观察该图,则会在最左上角创建图例,如下所述 -

在这里,图例包括给定数据集的各种类型的物种。
更改图例的属性
我们可以借助属性“legend.position”删除图例,并得到适当的输出 -
> # Remove Legend > p + theme(legend.position="none")

我们还可以使用属性“element_blank()”隐藏图例的标题,如下所示 -
> # Hide the legend title > p + theme(legend.title=element_blank())
我们还可以在需要时使用图例位置。该属性用于生成准确的绘图表示。
> #Change the legend position > p + theme(legend.position="top") > > p + theme(legend.position="bottom")
顶级代表

底部表示

更改图例的字体样式
我们可以更改标题的字体样式和字体类型以及图例的其他属性,如下所述 -
> #Change the legend title and text font styles > # legend title > p + theme(legend.title = element_text(colour = "blue", size = 10, + face = "bold")) > # legend labels > p + theme(legend.text = element_text(colour = "red", size = 8, + face = "bold"))
生成的输出如下 -


接下来的章节将重点关注具有各种背景属性(例如颜色、主题)的各种类型的绘图,以及从数据科学的角度来看它们中每一个的重要性。
ggplot2 - 散点图和抖动图
散点图类似于通常用于绘图的折线图。散点图显示一个变量与另一个变量的相关程度。变量之间的关系称为相关性,通常在统计方法中使用。我们将使用名为“Iris”的相同数据集,其中每个变量之间存在很多变化。这是一个著名的数据集,它给出了 3 种鸢尾花各 50 朵花的变量萼片长度和宽度以及花瓣长度和宽度的测量值(以厘米为单位)。该物种被称为山鸢尾、云芝和维吉尼亚鸢尾。
创建基本散点图
使用“ggplot2”包创建散点图涉及以下步骤 -
要创建基本散点图,请执行以下命令 -
> # Basic Scatter Plot > ggplot(iris, aes(Sepal.Length, Petal.Length)) + + geom_point()

添加属性
我们可以使用 geom_point() 函数中名为 shape 的属性来更改点的形状。
> # Change the shape of points > ggplot(iris, aes(Sepal.Length, Petal.Length)) + + geom_point(shape=1)

我们可以为所需散点图中添加的点添加颜色。
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1)

在此示例中,我们根据传说中提到的物种创建了颜色。这三个物种在上述图中具有独特的区别。
现在我们将重点关注建立变量之间的关系。
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1) + + geom_smooth(method=lm)
geom_smooth函数有助于重叠模式和创建所需变量的模式。
属性方法“lm”提到了需要开发的回归线。
> # Add a regression line > ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1) + + geom_smooth(method=lm)

我们还可以使用下面提到的语法添加没有阴影置信区域的回归线 -
># Add a regression line but no shaded confidence region > ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1) + + geom_smooth(method=lm, se=FALSE)

阴影区域代表置信区域以外的区域。
抖动图
抖动图包括可以描绘分散图的特殊效果。抖动只不过是分配给点以将它们分开的随机值,如下所述 -
> ggplot(mpg, aes(cyl, hwy)) + + geom_point() + + geom_jitter(aes(colour = class))

ggplot2 - 条形图和直方图
条形图以矩形方式表示分类数据。条形图可以垂直和水平绘制。高度或长度与图表中表示的值成正比。条形图的 x 轴和 y 轴指定特定数据集中包含的类别。
直方图是表示原始数据的条形图,清晰地显示了上述数据集的分布情况。
在本章中,我们将重点介绍借助 ggplot2 创建条形图和直方图。
了解 MPG 数据集
让我们了解将使用的数据集。MPG 数据集包含 EPA 在以下链接中提供的燃油经济性数据的子集 -
它由 1999 年至 2008 年间每年推出新车型的车型组成。这被用来衡量该车的受欢迎程度。
执行以下命令来了解数据集所需的属性列表。
> library(ggplot2)
附带的包是ggplot2。
以下对象被 _by_ .GlobalEnv 屏蔽 -
mpg
警告信息
- arules 包是在 R 版本 3.5.1 下构建的
- 包tunerR是在R版本3.5.3下构建的
- 包 ggplot2 是在 R 版本 3.5.3 下构建的

创建条形计数图
条形计数图可以用下面提到的图创建 -
> # A bar count plot > p <- ggplot(mpg, aes(x=factor(cyl)))+ + geom_bar(stat="count") > p

geom_bar() 是用于创建条形图的函数。它具有统计值的属性,称为计数。
直方图
可以使用下面提到的图创建直方图计数图 -
> # A historgram count plot > ggplot(data=mpg, aes(x=hwy)) + + geom_histogram( col="red", + fill="green", + alpha = .2, + binwidth = 5)
geom_histogram() 包含创建直方图的所有必要属性。在这里,它采用 hwy 的属性以及相应的计数。颜色按要求取。

堆积条形图
条形图和直方图的一般图可以创建如下 -
> p <- ggplot(mpg, aes(class)) > p + geom_bar() > p + geom_bar()

该图包括条形图中定义的所有类别以及相应的类别。该图称为堆叠图。
ggplot2 - 饼图
饼图被视为圆形统计图,将其划分为多个切片以说明数值比例。在上述饼图中,每个切片的弧长与其代表的数量成正比。弧长代表饼图的角度。饼图的总度数为 360 度。半圆或半饼图由 180 度组成。
创建饼图
在提到的工作区中加载包,如下所示 -
> # Load modules
> library(ggplot2)
>
> # Source: Frequency table
> df <- as.data.frame(table(mpg$class))
> colnames(df) <- c("class", "freq")

可以使用以下命令创建示例图表 -
> pie <- ggplot(df, aes(x = "", y=freq, fill = factor(class))) + + geom_bar(width = 1, stat = "identity") + + theme(axis.line = element_blank(), + plot.title = element_text(hjust=0.5)) + + labs(fill="class", + x=NULL, + y=NULL, + title="Pie Chart of class", + caption="Source: mpg") > pie
如果您观察输出,就会发现图表不是以循环方式创建的,如下所述 -

创建坐标
让我们执行以下命令来创建所需的饼图,如下所示 -
> pie + coord_polar(theta = "y", start=0)

ggplot2 - 边缘图
在本章中,我们将讨论边际图。
了解边缘图
边际图用于评估两个变量之间的关系并检查它们的分布。当我们谈论创建边际图时,它们只不过是在各自 x 轴和 y 轴的边距中具有直方图、箱线图或点图的散点图。
以下步骤将用于使用 R 包“ggExtra”创建边际图。该软件包旨在增强“ggplot2”软件包的功能,并包含用于创建成功的边缘图的各种功能。
步骤1
使用以下命令安装“ggExtra”包以成功执行(如果您的系统中未安装该包)。
> install.packages("ggExtra")
第2步
在工作区中包含所需的库以创建边缘图。
> library(ggplot2) > library(ggExtra)
步骤3
读取我们在前面的章节中使用过的所需数据集“mpg”。
> data(mpg) > head(mpg) # A tibble: 6 x 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~ 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~ 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~ 4 audi a4 2 2008 4 auto(av) f 21 30 p compa~ 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~ 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~ >
步骤4
现在让我们使用“ggplot2”创建一个简单的图,这将帮助我们理解边际图的概念。
> #Plot > g <- ggplot(mpg, aes(cty, hwy)) + + geom_count() + + geom_smooth(method="lm", se=F) > g
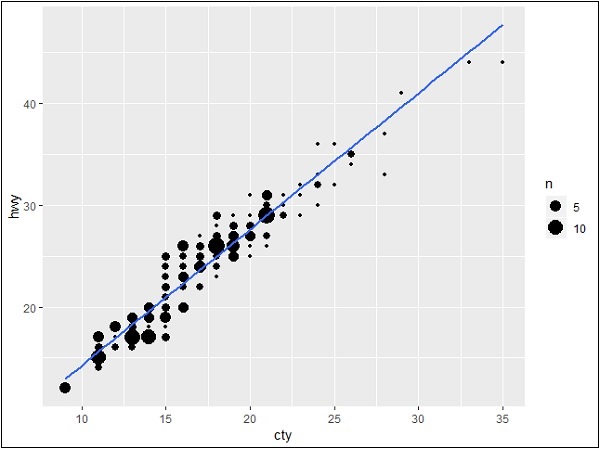
变量之间的关系
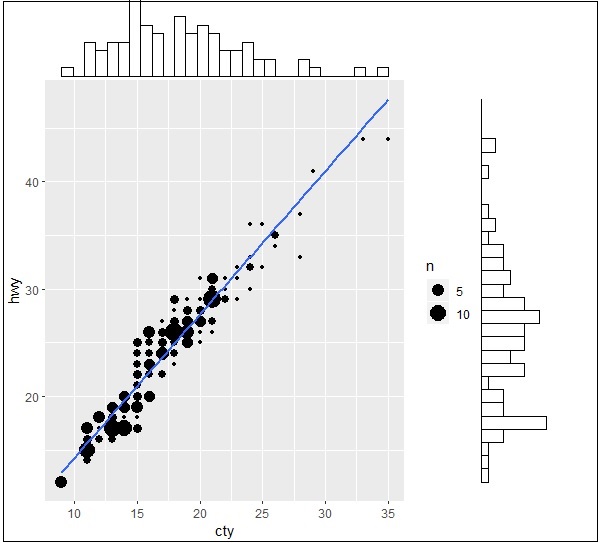
现在让我们使用 ggMarginal 函数创建边际图,该函数有助于生成两个属性“hwy”和“cty”之间的关系。
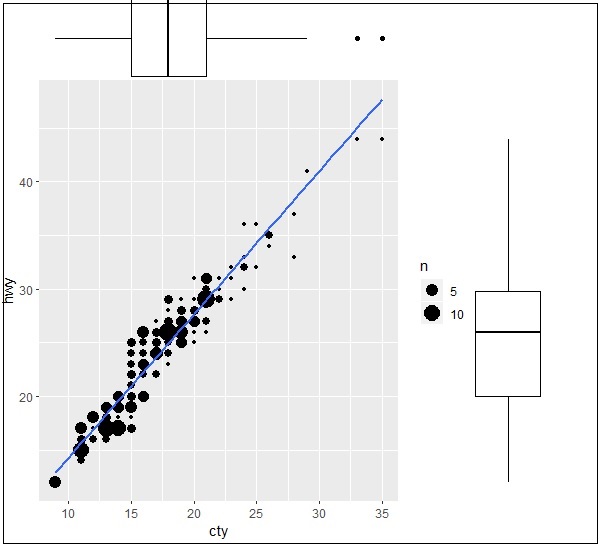
> ggMarginal(g, type = "histogram", fill="transparent") > ggMarginal(g, type = "boxplot", fill="transparent")
直方图边缘图的输出如下 -
下面提到了盒式边缘图的输出 -
ggplot2 - 气泡图和计数图表
气泡图只不过是气泡图,它基本上是一个散点图,其中第三个数字变量用于圆圈大小。在本章中,我们将重点关注条形计数图和直方图计数图的创建,它们被视为气泡图的复制品。
以下步骤用于使用上述包创建气泡图和计数图 -
了解数据集
加载相应的包和所需的数据集以创建气泡图和计数图。
> # Load ggplot > library(ggplot2) > > # Read in dataset > data(mpg) > head(mpg) # A tibble: 6 x 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~ 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~ 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~ 4 audi a4 2 2008 4 auto(av) f 21 30 p compa~ 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~ 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~
可以使用以下命令创建条形计数图 -
> # A bar count plot > p <- ggplot(mpg, aes(x=factor(cyl)))+ + geom_bar(stat="count") > p

直方图分析
可以使用以下命令创建直方图计数图 -
> # A historgram count plot > ggplot(data=mpg, aes(x=hwy)) + + geom_histogram( col="red", + fill="green", + alpha = .2, + binwidth = 5)

气泡图
现在让我们创建最基本的气泡图,其中包含增加散点图中提到的点的维度所需的属性。
ggplot(mpg, aes(x=cty, y=hwy, size = pop)) +geom_point(alpha=0.7)

该图描述了包含在图例格式中的制造商的性质。所表示的值包括“hwy”属性的各个维度。
ggplot2 - 发散图表
在前面的章节中,我们了解了可以使用“ggplot2”包创建的各种类型的图表。我们现在将重点关注相同的变化,例如发散条形图、棒棒糖图等等。首先,我们将从创建发散条形图开始,下面提到要遵循的步骤 -
了解数据集
加载所需的包并在 mpg 数据集中创建一个名为“汽车名称”的新列。
#Load ggplot > library(ggplot2) > # create new column for car names > mtcars$`car name` <- rownames(mtcars) > # compute normalized mpg > mtcars$mpg_z <- round((mtcars$mpg - mean(mtcars$mpg))/sd(mtcars$mpg), 2) > # above / below avg flag > mtcars$mpg_type <- ifelse(mtcars$mpg_z < 0, "below", "above") > # sort > mtcars <- mtcars[order(mtcars$mpg_z), ]
上述计算涉及为汽车名称创建一个新列,并借助舍入函数计算归一化数据集。我们还可以使用上面和下面的 avg 标志来获取“type”功能的值。稍后,我们对值进行排序以创建所需的数据集。
收到的输出如下 -

将值转换为因子以保留特定图中的排序顺序,如下所述 -
> # convert to factor to retain sorted order in plot. > mtcars$`car name` <- factor(mtcars$`car name`, levels = mtcars$`car name`)
获得的输出如下 -

发散条形图
现在创建一个具有上述属性的发散条形图,该属性被视为所需的坐标。
> # Diverging Barcharts
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_bar(stat='identity', aes(fill=mpg_type), width=.5) +
+ scale_fill_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ labs(subtitle="Normalised mileage from 'mtcars'",
+ title= "Diverging Bars") +
+ coord_flip()
注意- 某些维度成员的发散条形图标记相对于提到的值指向向上或向下方向。
下面提到了发散条形图的输出,其中我们使用函数 geom_bar 来创建条形图 -

发散棒棒糖图
创建具有相同属性和坐标的发散棒棒糖图表,只需更改要使用的函数,即 geom_segment(),它有助于创建棒棒糖图表。
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) + + geom_point(stat='identity', fill="black", size=6) + + geom_segment(aes(y = 0, + x = `car name`, + yend = mpg_z, + xend = `car name`), + color = "black") + + geom_text(color="white", size=2) + + labs(title="Diverging Lollipop Chart", + subtitle="Normalized mileage from 'mtcars': Lollipop") + + ylim(-2.5, 2.5) + + coord_flip()

发散点图
以类似的方式创建发散点图,其中点代表更大维度的分散图中的点。
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_point(stat='identity', aes(col=mpg_type), size=6) +
+ scale_color_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ geom_text(color="white", size=2) +
+ labs(title="Diverging Dot Plot",
+ subtitle="Normalized mileage from 'mtcars': Dotplot") +
+ ylim(-2.5, 2.5) +
+ coord_flip()

在这里,图例用不同的绿色和红色表示“高于平均水平”和“低于平均水平”的值。点图传达静态信息。原理与Diverging条形图相同,只是只使用点。
ggplot2 - 主题
在本章中,我们将重点讨论如何使用自定义主题来更改工作区的外观和感觉。我们将使用“ggthemes”包来理解R工作区中主题管理的概念。
让我们实施以下步骤来使用上述数据集中所需的主题。
GG主题
在 R 工作区中安装“ggthemes”包以及所需的包。
> install.packages("ggthemes")
> Library(ggthemes)

实施新主题,以生产年份和排量产生制造商的传奇。
> library(ggthemes)
> ggplot(mpg, aes(year, displ, color=factor(manufacturer)))+
+ geom_point()+ggtitle("This plot looks a lot different from the default")+
+ theme_economist()+scale_colour_economist()

可以看出,与以前的主题管理相比,刻度文本、图例和其他元素的默认大小有点小。一次更改所有文本元素的大小非常容易。这可以通过创建自定义主题来完成,我们可以在下面的步骤中观察到所有元素的大小都是相对于 base_size (rel()) 的。
> theme_set(theme_gray(base_size = 30)) > ggplot(mpg, aes(x=year, y=class))+geom_point(color="red")

ggplot2 - 多面板图
多面板图意味着在单个图中一起创建多个图形。我们将使用 par() 函数通过传递图形参数 mfrow 和 mfcol 将多个图形放入单个图中。
这里我们将使用“AirQuality”数据集来实现多面板图。让我们首先了解数据集,看看如何创建多面板图。该数据集包含部署在意大利城市现场的气体多传感器设备的响应。记录每小时响应平均值以及来自认证分析仪的气体浓度参考值。
par()函数的见解
了解 par() 函数以创建所需多面板图的维度。
> par(mfrow=c(1,2)) > # set the plotting area into a 1*2 array
这将创建一个尺寸为 1*2 的空白图。

现在使用以下命令创建上述数据集的条形图和饼图。使用图形参数 mfcol 也可以实现同样的现象。
创建多面板图
两者之间的唯一区别在于,mfrow 按行填充子图区域,而 mfcol 按列填充。
> Temperature <- airquality$Temp > Ozone <- airquality$Ozone > par(mfrow=c(2,2)) > hist(Temperature) > boxplot(Temperature, horizontal=TRUE) > hist(Ozone) > boxplot(Ozone, horizontal=TRUE)

箱线图和条形图是在单个窗口中创建的,基本上创建了多面板图。
par 函数中尺寸发生变化的相同绘图如下所示 -
par(mfcol = c(2, 2))

ggplot2 - 多图
在本章中,我们将重点关注多个绘图的创建,这些绘图可进一步用于创建 3 维绘图。将涵盖的地块列表包括 -
- 密度图
- 箱形图
- 点图
- 小提琴Plotly
我们将使用前面章节中使用的“mpg”数据集。该数据集提供了 1999 年至 2008 年 38 种流行车型的燃油经济性数据。该数据集随 ggplot2 包一起提供。请务必遵循下面提到的步骤来创建不同类型的绘图。
> # Load Modules > library(ggplot2) > > # Dataset > head(mpg) # A tibble: 6 x 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~ 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~ 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~ 4 audi a4 2 2008 4 auto(av) f 21 30 p compa~ 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~ 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~
密度图
密度图是上述数据集中任何数值变量分布的图形表示。它使用核密度估计来显示变量的概率密度函数。
“ggplot2”包包含一个名为 geom_densis() 的函数来创建密度图。
我们将执行以下命令来创建密度图 -
> p −- ggplot(mpg, aes(cty)) + + geom_density(aes(fill=factor(cyl)), alpha=0.8) > p
我们可以从下面创建的图中观察到各种密度 -

我们可以通过重命名 x 和 y 轴来创建绘图,这样可以通过包含不同颜色组合的标题和图例来保持更好的清晰度。
> p + labs(title="Density plot", + subtitle="City Mileage Grouped by Number of cylinders", + caption="Source: mpg", + x="City Mileage", + fill="# Cylinders")

箱形图
箱线图也称为盒须图,表示数据的五数汇总。五个数字摘要包括最小值、第一四分位数、中位数、第三四分位数和最大值等值。穿过箱线图中间部分的垂直线被视为“中位数”。
我们可以使用以下命令创建箱线图 -
> p <- ggplot(mpg, aes(class, cty)) + + geom_boxplot(varwidth=T, fill="blue") > p + labs(title="A Box plot Example", + subtitle="Mileage by Class", + caption="MPG Dataset", + x="Class", + y="Mileage") >p
在这里,我们正在创建关于 class 和 cty 属性的箱线图。

点图
点图与散点图类似,只是维度不同。在本节中,我们将在现有箱线图中添加点图,以获得更好的图片和清晰度。
可以使用以下命令创建箱线图 -
> p <- ggplot(mpg, aes(manufacturer, cty)) + + geom_boxplot() + + theme(axis.text.x = element_text(angle=65, vjust=0.6)) > p

点图的创建如下 -
> p + geom_dotplot(binaxis='y', + stackdir='center', + dotsize = .5 + )

小提琴Plotly
小提琴图也以类似的方式创建,仅改变小提琴而不是盒子的结构。下面清楚地提到了输出 -
> p <- ggplot(mpg, aes(class, cty)) > > p + geom_violin()

ggplot2 - 背景颜色
有多种方法可以使用一个函数来改变绘图的整体外观,如下所述。但如果您想简单地更改面板的背景颜色,可以使用以下命令 -
实施小组背景
我们可以使用以下命令更改背景颜色,这有助于更改面板(panel.background) -
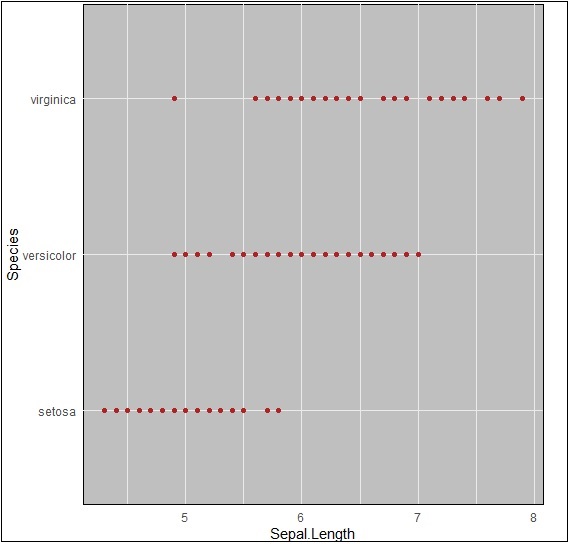
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+ + theme(panel.background = element_rect(fill = 'grey75'))
下图清楚地描绘了颜色的变化 -
实施Panel.grid.major
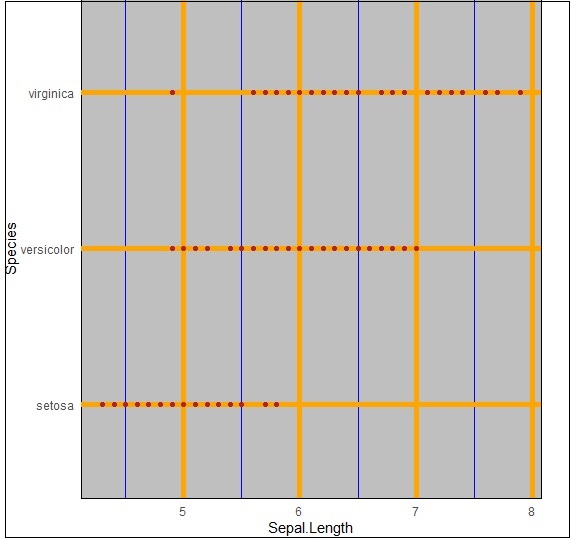
我们可以使用属性“panel.grid.major”更改网格线,如下面的命令中所述 -
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+ + theme(panel.background = element_rect(fill = 'grey75'), + panel.grid.major = element_line(colour = "orange", size=2), + panel.grid.minor = element_line(colour = "blue"))
我们甚至可以更改绘图背景,特别是使用“plot.background”属性排除面板,如下所述 -
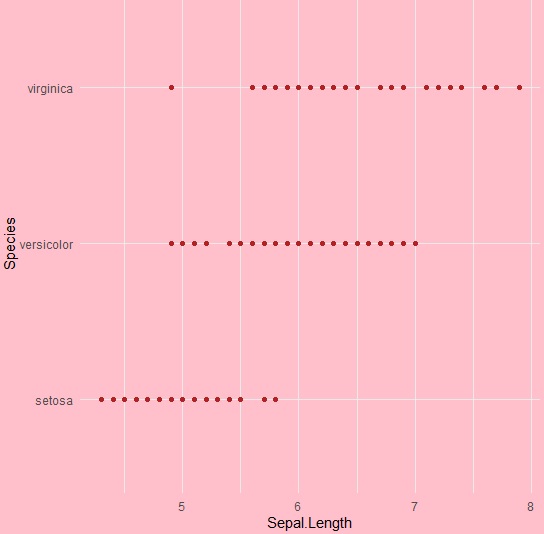
ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+ + theme(plot.background = element_rect(fill = 'pink'))
ggplot2 - 时间序列
时间序列是表示按特定时间顺序排列的一系列数据点的图形。时间序列是在连续的等间隔时间点处的序列所得到的序列。时间序列可以被视为离散时间数据。我们将在本章中使用的数据集是“经济”数据集,其中包括美国经济时间序列的所有详细信息。
数据框包括以下属性:
| 日期 | 数据收集月份 |
| 普萨维特 | 个人储蓄率 |
| 聚氯乙烯 | 个人消费支出 |
| 失业 | 失业人数(千) |
| 不受阻碍 | 失业持续时间中位数 |
| 流行音乐 | 总人口(千) |
加载所需的包并设置默认主题以创建时间序列。
> library(ggplot2) > theme_set(theme_minimal()) > # Demo dataset > head(economics) # A tibble: 6 x 6 date pce pop psavert uempmed unemploy <date> <dbl> <dbl> <dbl> <dbl> <dbl> 1 1967-07-01 507. 198712 12.6 4.5 2944 2 1967-08-01 510. 198911 12.6 4.7 2945 3 1967-09-01 516. 199113 11.9 4.6 2958 4 1967-10-01 512. 199311 12.9 4.9 3143 5 1967-11-01 517. 199498 12.8 4.7 3066 6 1967-12-01 525. 199657 11.8 4.8 3018
创建一个基本线图,以创建时间序列结构。
> # Basic line plot > ggplot(data = economics, aes(x = date, y = pop))+ + geom_line(color = "#00AFBB", size = 2)

我们可以使用以下命令绘制数据子集 -
> # Plot a subset of the data
> ss <- subset(economics, date > as.Date("2006-1-1"))
> ggplot(data = ss, aes(x = date, y = pop)) +
+ geom_line(color = "#FC4E07", size = 2)

创建时间序列
在这里,我们将按日期绘制变量 psavert 和 uempmed。这里我们必须使用 tidyr 包重塑数据。这可以通过折叠同一列(新列)中的 psavert 和 uempmed 值来实现。R 函数:gather()[tidyr]。下一步涉及创建一个分组变量,其级别 = psavert 和 uempmed。
> library(tidyr) > library(dplyr) Attaching package: ‘dplyr’ The following object is masked from ‘package:ggplot2’: vars The following objects are masked from ‘package:stats’: filter, lag The following objects are masked from ‘package:base’: intersect, setdiff, setequal, union > df <- economics %>% + select(date, psavert, uempmed) %>% + gather(key = "variable", value = "value", -date) > head(df, 3) # A tibble: 3 x 3 date variable value <date> <chr> <dbl> 1 1967-07-01 psavert 12.6 2 1967-08-01 psavert 12.6 3 1967-09-01 psavert 11.9
使用以下命令创建多线图来查看“psavert”和“unempmed”之间的关系 -
> ggplot(df, aes(x = date, y = value)) +
+ geom_line(aes(color = variable), size = 1) +
+ scale_color_manual(values = c("#00AFBB", "#E7B800")) +
+ theme_minimal()
