TIKA - 快速指南
TIKA - 概述
什么是阿帕奇蒂卡?
Apache Tika 是一个用于文档类型检测和从各种文件格式中提取内容的库。
在内部,Tika 使用现有的各种文档解析器和文档类型检测技术来检测和提取数据。
使用 Tika,人们可以开发一种通用类型检测器和内容提取器,以从不同类型的文档(例如电子表格、文本文档、图像、PDF,甚至在一定程度上的多媒体输入格式)中提取结构化文本和元数据。
Tika 提供了一个通用 API 来解析不同的文件格式。它对每种文档类型使用现有的专用解析器库。
所有这些解析器库都封装在一个称为Parser 接口的接口下。

为什么是蒂卡?
根据 filext.com 的数据,大约有 15k 到 51k 种内容类型,并且这个数字每天都在增长。数据以各种格式存储,例如文本文档、Excel 电子表格、PDF、图像和多媒体文件等。因此,搜索引擎和内容管理系统等应用程序需要额外的支持,以便轻松地从这些文档类型中提取数据。Apache Tika 通过提供通用 API 来从多种文件格式中查找和提取数据来实现此目的。
阿帕奇蒂卡应用程序
有多种应用程序使用 Apache Tika。在这里,我们将讨论一些严重依赖 Apache Tika 的著名应用程序。
搜索引擎
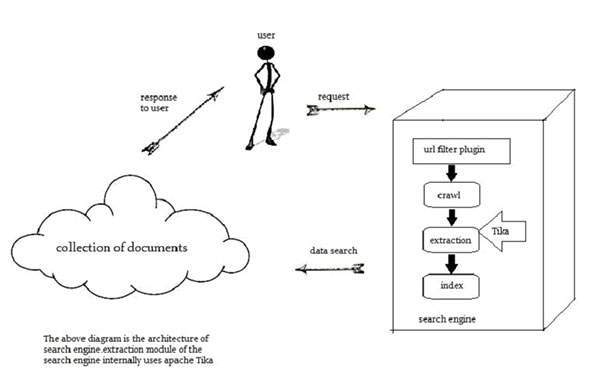
Tika 在开发搜索引擎以索引数字文档的文本内容时被广泛使用。
搜索引擎是一种信息处理系统,旨在从网络上搜索信息和索引文档。
爬虫是搜索引擎的重要组成部分,它通过网络爬行以获取要使用某种索引技术建立索引的文档。此后,爬虫将这些索引文档传输到提取组件。
提取组件的职责是从文档中提取文本和元数据。这样提取的内容和元数据对于搜索引擎非常有用。该提取成分含有蒂卡。
然后,提取的内容被传递到搜索引擎的索引器,搜索引擎使用它来构建搜索索引。除此之外,搜索引擎还以许多其他方式使用提取的内容。
文件分析
在人工智能领域,有一些工具可以在语义层面自动分析文档并从中提取各种数据。
在此类应用中,根据提取的文档内容中的突出术语对文档进行分类。
这些工具利用 Tika 进行内容提取来分析从纯文本到数字文档的各种文档。
数字资产管理
一些组织使用称为数字资产管理 (DAM) 的特殊应用程序来管理其数字资产,例如照片、电子书、绘图、音乐和视频。
此类应用程序借助文档类型检测器和元数据提取器对各种文档进行分类。
内容分析
亚马逊等网站会根据个人用户的兴趣向其推荐其网站新发布的内容。为此,这些网站遵循机器学习技术,或借助 Facebook 等社交媒体网站来提取所需信息,例如用户的喜好和兴趣。收集到的信息将采用 html 标签或其他需要进一步内容类型检测和提取的格式的形式。
对于文档的内容分析,我们拥有实现机器学习技术的技术,例如UIMA和Mahout。这些技术对于聚类和分析文档中的数据很有用。
Apache Mahout是一个在 Apache Hadoop(云计算平台)上提供机器学习算法的框架。Mahout 通过遵循某些集群和过滤技术来提供架构。通过遵循这种架构,程序员可以编写自己的机器学习算法,通过采用各种文本和元数据组合来生成推荐。为了向这些算法提供输入,最新版本的 Mahout 使用 Tika 从二进制内容中提取文本和元数据。
Apache UIMA分析和处理各种编程语言并生成 UIMA 注释。在内部,它使用 Tika Annotator 来提取文档文本和元数据。
历史
| 年 | 发展 |
|---|---|
| 2006年 | Tika 的想法已提交给 Lucene 项目管理委员会。 |
| 2006年 | 讨论了 Tika 的概念及其在 Jackrabbit 项目中的用途。 |
| 2007年 | Tika 进入 Apache 孵化器。 |
| 2008年 | 0.1和0.2版本发布,Tika从孵化器毕业到Lucene子项目。 |
| 2009年 | 发布了 0.3、0.4 和 0.5 版本。 |
| 2010年 | 0.6 和 0.7 版本发布,Tika 跻身 Apache 顶级项目。 |
| 2011年 | Tika 1.0 发布,同年还发布了关于 Tika 的书《Tika in Action》。 |
TIKA - 建筑
Tika应用层架构
应用程序程序员可以轻松地将 Tika 集成到他们的应用程序中。Tika 提供了命令行界面和 GUI,使其用户友好。
在本章中,我们将讨论构成 Tika 架构的四个重要模块。下图显示了 Tika 的架构及其四个模块 -
- 语言检测机制。
- MIME检测机制。
- 解析器接口。
- 蒂卡门面类。

语言检测机制
每当文本文档传递给 Tika 时,它都会检测其编写语言。它接受没有语言注释的文档,并通过检测语言将该信息添加到文档的元数据中。
为了支持语言识别,Tika在org.apache.tika.language包中提供了一个名为Language Identifier的类,以及一个语言识别存储库,其中包含用于从给定文本中进行语言检测的算法。Tika 内部使用 N-gram 算法进行语言检测。
MIME检测机制
Tika 可以根据 MIME 标准检测文档类型。Tika 中的默认 MIME 类型检测是使用org.apache.tika.mime.mimeTypes完成的。它使用org.apache.tika.detect.Detector接口进行大多数内容类型检测。
Tika 在内部使用了多种技术,如文件全局、内容类型提示、魔术字节、字符编码和其他几种技术。
解析器接口
org.apache.tika.parser 的解析器接口是 Tika 中解析文档的关键接口。该接口从文档中提取文本和元数据,并为愿意编写解析器插件的外部用户进行总结。
使用特定于各个文档类型的不同具体解析器类,Tika 支持许多文档格式。这些特定于格式的类通过直接实现解析器逻辑或使用外部解析器库来提供对不同文档格式的支持。
蒂卡门面类
使用 Tika 门面类是从 Java 调用 Tika 的最简单、直接的方式,它遵循门面设计模式。您可以在 Tika API 的 org.apache.tika 包中找到 Tika 门面类。
通过实施基本用例,Tika 充当景观经纪人。它抽象了 Tika 库的底层复杂性,如 MIME 检测机制、解析器接口和语言检测机制,并为用户提供了一个简单的使用界面。
蒂卡的特点
统一解析器接口- Tika 将所有第三方解析器库封装在单个解析器接口中。由于此功能,用户摆脱了选择合适的解析器库并根据遇到的文件类型使用它的负担。
低内存使用量- Tika 消耗较少的内存资源,因此它很容易嵌入 Java 应用程序。我们还可以在移动 PDA 等资源较少的平台上运行的应用程序中使用 Tika。
快速处理- 可以预期从应用程序中快速检测和提取内容。
灵活的元数据- Tika 了解用于描述文件的所有元数据模型。
解析器集成- Tika 可以在单个应用程序中使用可用于每种文档类型的各种解析器库。
MIME 类型检测- Tika 可以检测并提取 MIME 标准中包含的所有媒体类型的内容。
语言检测- Tika 包含语言识别功能,因此可以在多语言网站中基于语言类型的文档中使用。
蒂卡的功能
Tika 支持各种功能 -
- 文档类型检测
- 内容提取
- 元数据提取
- 语言检测
文档类型检测
Tika 使用各种检测技术并检测提供给它的文档的类型。

内容提取
Tika 有一个解析器库,可以解析各种文档格式的内容并提取它们。检测到文档的类型后,它从解析器存储库中选择适当的解析器并传递文档。不同类的 Tika 有解析不同文档格式的方法。

元数据提取
除了内容之外,Tika 还使用与内容提取相同的过程来提取文档的元数据。对于某些文档类型,Tika 有用于提取元数据的类。

语言检测
在内部,Tika 遵循n-gram等算法来检测给定文档中内容的语言。Tika 依赖于Languageidentifier和Profiler等类来进行语言识别。

TIKA - 环境
本章将带您完成在 Windows 和 Linux 上设置 Apache Tika 的过程。安装 Apache Tika 时需要进行用户管理。
系统要求
| JDK | Java SE 2 JDK 1.6 或更高版本 |
| 记忆 | 1 GB RAM(推荐) |
| 磁盘空间 | 无最低要求 |
| 操作系统版本 | Windows XP或以上、Linux |
第 1 步:验证 Java 安装
要验证 Java 安装,请打开控制台并执行以下java命令。
| 操作系统 | 任务 | 命令 |
|---|---|---|
| Windows | 打开命令控制台 | \>java –版本 |
| Linux | 打开命令终端 | $java –版本 |
如果 Java 已正确安装在您的系统上,那么您应该获得以下输出之一,具体取决于您正在使用的平台。
| 操作系统 | 输出 |
|---|---|
| Windows | Java版本“1.7.0_60”
Java (TM) SE 运行时环境(内部版本 1.7.0_60-b19) Java Hotspot (TM) 64 位服务器 VM(内部版本 24.60-b09,混合模式) |
| 卢尼克斯 | java版本“1.7.0_25” 打开JDK运行环境(rhel-2.3.10.4.el6_4-x86_64) 打开 JDK 64 位服务器 VM(内部版本 23.7-b01,混合模式) |
我们假设本教程的读者在继续学习本教程之前已在其系统上安装了 Java 1.7.0_60。
如果您没有 Java SDK,请从https://www.oracle.com/technetwork/java/javase/downloads/index.html 下载其当前版本并进行安装。
第二步:设置Java环境
设置 JAVA_HOME 环境变量以指向计算机上安装 Java 的基本目录位置。例如,
| 操作系统 | 输出 |
|---|---|
| Windows | 将环境变量 JAVA_HOME 设置为 C:\ProgramFiles\java\jdk1.7.0_60 |
| Linux | 导出 JAVA_HOME = /usr/local/java-current |
将 Java 编译器位置的完整路径附加到系统路径。
| 操作系统 | 输出 |
|---|---|
| Windows | 追加字符串;C:\Program Files\Java\jdk1.7.0_60\bin 到系统变量 PATH 的末尾。 |
| Linux | 导出路径 = $PATH:$JAVA_HOME/bin/ |
如上所述,从命令提示符验证命令 java-version。
步骤 3:设置 Apache Tika 环境
程序员可以使用以下命令将 Apache Tika 集成到他们的环境中
- 命令行,
- 蒂卡API,
- Tika 的命令行界面 (CLI),
- Tika 的图形用户界面 (GUI),或
- 源代码。
对于任何这些方法,首先,您必须下载 Tika 的源代码。
您可以在 https://Tika.apache.org/download.html 找到 Tika 的源代码,其中您可以找到两个链接 -
apache-tika-1.6-src.zip - 它包含 Tika 的源代码,以及
Tika -app-1.6.jar - 这是一个包含 Tika 应用程序的 jar 文件。
下载这两个文件。Tika官网截图如下所示。

下载文件后,设置 jar 文件tika-app-1.6.jar的类路径。添加jar文件的完整路径,如下表所示。
| 操作系统 | 输出 |
|---|---|
| Windows | 将字符串“C:\jars\Tika-app-1.6.jar”附加到用户环境变量 CLASSPATH |
| Linux | 导出 CLASSPATH = $CLASSPATH - /usr/share/jars/Tika-app-1.6.tar - |
Apache 提供了 Tika 应用程序,这是一个使用 Eclipse 的图形用户界面 (GUI) 应用程序。
Tika-Maven 使用 Eclipse 构建
打开 eclipse 并创建一个新项目。
如果您的 Eclipse 中没有 Maven,请按照给定的步骤进行设置。
打开链接 https://wiki.eclipse.org/M2E_updatesite_and_gittags。在那里您可以找到表格格式的 m2e 插件版本

选择最新版本并将 url 的路径保存在 p2 url 列中。
现在重新访问 eclipse,在菜单栏中单击Help,然后从下拉菜单中选择Install New Software
单击“添加”按钮,输入任何所需的名称(因为它是可选的)。现在将保存的 URL 粘贴到“位置”字段中。
将添加一个新插件,其名称为您在上一步中选择的名称,选中其前面的复选框,然后单击“下一步”。

继续安装。完成后,重新启动 Eclipse。
现在右键单击该项目,然后在配置选项中选择“转换为maven项目”。
将出现一个用于创建新 pom 的新向导。输入 Group Id 为 org.apache.tika,输入最新版本的 Tika,选择打包为jar,然后单击Finish。
Maven项目已成功安装,并且您的项目已转换为Maven。现在您必须配置 pom.xml 文件。
配置 XML 文件
从https://mvnrepository.com/artifact/org.apache.tika获取 Tika maven 依赖项
下图是 Apache Tika 的完整 Maven 依赖关系。
<dependency> <groupId>org.apache.Tika</groupId> <artifactId>Tika-core</artifactId> <version>1.6</version> <groupId>org.apache.Tika</groupId> <artifactId> Tika-parsers</artifactId> <version> 1.6</version> <groupId> org.apache.Tika</groupId> <artifactId>Tika</artifactId> <version>1.6</version> <groupId>org.apache.Tika</groupId> < artifactId>Tika-serialization</artifactId> < version>1.6< /version> < groupId>org.apache.Tika< /groupId> < artifactId>Tika-app< /artifactId> < version>1.6< /version> <groupId>org.apache.Tika</groupId> <artifactId>Tika-bundle</artifactId> <version>1.6</version> </dependency>
TIKA - 参考 API
用户可以使用 Tika 门面类将 Tika 嵌入到他们的应用程序中。它有方法来探索 Tika 的所有功能。由于它是一个外观类,Tika 抽象了其功能背后的复杂性。除此之外,用户还可以在其应用程序中使用 Tika 的各种类。

蒂卡级(立面)
这是Tika库中最突出的类,遵循门面设计模式。因此,它抽象了所有内部实现并提供了访问 Tika 功能的简单方法。下表列出了此类的构造函数及其描述。
包- org.apache.tika
类- 蒂卡
| 先生。 | 构造函数及描述 |
|---|---|
| 1 |
提卡 () 使用默认配置并构造 Tika 类。 |
| 2 |
Tika(探测器探测器) 通过接受检测器实例作为参数来创建 Tika 外观 |
| 3 |
Tika(Detector检测器、Parser解析器) 通过接受检测器和解析器实例作为参数来创建 Tika 外观。 |
| 4 |
Tika(Detector检测器、Parser解析器、Translator翻译器) 通过接受检测器、解析器和翻译器实例作为参数来创建 Tika 外观。 |
| 5 |
蒂卡(TikaConfig 配置) 通过接受 TikaConfig 类的对象作为参数来创建 Tika 外观。 |
方法和说明
以下是 Tika 门面类的重要方法 -
| 先生。 | 方法与说明 |
|---|---|
| 1 |
解析ToString(文件文件) 此方法及其所有变体解析作为参数传递的文件,并以字符串格式返回提取的文本内容。默认情况下,该字符串参数的长度是有限的。 |
| 2 |
int getMaxStringLength () 返回 parseToString 方法返回的字符串的最大长度。 |
| 3 |
无效setMaxStringLength(int maxStringLength) 设置 parseToString 方法返回的字符串的最大长度。 |
| 4 |
读者解析(文件文件) 此方法及其所有变体解析作为参数传递的文件,并以 java.io.reader 对象的形式返回提取的文本内容。 |
| 5 |
字符串检测(InputStream流、Metadata元数据) 此方法及其所有变体接受 InputStream 对象和 Metadata 对象作为参数,检测给定文档的类型,并将文档类型名称作为 String 对象返回。该方法抽象了 Tika 使用的检测机制。 |
| 6 |
字符串翻译(输入流文本,字符串目标语言) 此方法及其所有变体接受 InputStream 对象和一个表示我们希望翻译文本的语言的字符串,并将给定的文本翻译为所需的语言,尝试自动检测源语言。 |
解析器接口
这是 Tika 包的所有解析器类实现的接口。
包- org.apache.tika.parser
接口- 解析器
方法和说明
以下是 Tika Parser 接口的重要方法 -
| 先生。 | 方法与说明 |
|---|---|
| 1 |
解析(InputStream 流、ContentHandler 处理程序、Metadata 元数据、ParseContext 上下文) 该方法将给定文档解析为一系列 XHTML 和 SAX 事件。解析后,它将提取的文档内容放置在ContentHandler类的对象中,将元数据放置在Metadata类的对象中。 |
元数据类
该类实现了各种接口,例如 CreativeCommons、Geographic、HttpHeaders、Message、MSOffice、ClimateForcast、TIFF、TikaMetadataKeys、TikaMimeKeys、Serializable,以支持各种数据模型。下表列出了此类的构造函数和方法及其说明。
包- org.apache.tika.metadata
类- 元数据
| 先生。 | 构造函数及描述 |
|---|---|
| 1 |
元数据() 构造一个新的空元数据。 |
| 先生。 | 方法与说明 |
|---|---|
| 1 |
添加(属性属性,字符串值) 将元数据属性/值映射添加到给定文档。使用此函数,我们可以将值设置为属性。 |
| 2 |
添加(字符串名称,字符串值) 将元数据属性/值映射添加到给定文档。使用此方法,我们可以为文档的现有元数据设置新的名称值。 |
| 3 |
字符串获取(属性属性) 返回给定元数据属性的值(如果有)。 |
| 4 |
字符串获取(字符串名称) 返回给定元数据名称的值(如果有)。 |
| 5 |
日期 getDate(属性属性) 返回日期元数据属性的值。 |
| 6 |
String[] getValues(属性属性) 返回元数据属性的所有值。 |
| 7 |
String[] getValues(字符串名称) 返回给定元数据名称的所有值。 |
| 8 |
字符串[]名称() 返回元数据对象中所有元数据元素的名称。 |
| 9 |
设置(属性属性,日期日期) 设置给定元数据属性的日期值 |
| 10 |
set(属性属性, String[] 值) 为元数据属性设置多个值。 |
语言标识符类
此类标识给定内容的语言。下表列出了此类的构造函数及其描述。
包- org.apache.tika.language
类- 语言标识符
| 先生。 | 构造函数及描述 |
|---|---|
| 1 |
LanguageIdentifier(LanguageProfile配置文件) 实例化语言标识符。在这里您必须传递一个 LanguageProfile 对象作为参数。 |
| 2 |
语言标识符(字符串内容) 此构造函数可以通过传递文本内容中的字符串来实例化语言标识符。 |
| 先生。 | 方法与说明 |
|---|---|
| 1 |
字符串获取语言() 返回指定给当前 LanguageIdentifier 对象的语言。 |
TIKA - 文件格式
Tika 支持的文件格式
下表显示了 Tika 支持的文件格式。
| 文件格式 | 封装库 | 蒂卡课堂 |
|---|---|---|
| XML | org.apache.tika.parser.xml | XML解析器 |
| 超文本标记语言 | org.apache.tika.parser.html 它使用Tagsoup库 | Html解析器 |
| MS-Office 复合文档 Ole2 至 2007 ooxml 2007 及以后 | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml 它使用 Apache Poi 库 |
Office解析器(ole2) OOXML 解析器 (ooxml) |
| OpenDocument 格式 openoffice | org.apache.tika.parser.odf | OpenOffice解析器 |
| 便携式文档格式(PDF) | org.apache.tika.parser.pdf 并且此包使用 Apache PdfBox 库 | PDF解析器 |
| 电子出版物格式(数字图书) | org.apache.tika.parser.epub | Epub解析器 |
| 富文本格式 | org.apache.tika.parser.rtf | RTF解析器 |
| 压缩和打包格式 | org.apache.tika.parser.pkg,该包使用通用压缩库 | PackageParser 和 CompressorParser 及其子类 |
| 文本格式 | org.apache.tika.parser.txt | TXT解析器 |
| Feed 和聚合格式 | org.apache.tika.parser.feed | Feed解析器 |
| 音频格式 | org.apache.tika.parser.audio 和 org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- 用于 mp3parser |
| 图像解析器 | org.apache.tika.parser.jpeg | JpegParser-用于 jpeg 图像 |
| 视频格式 | org.apache.tika.parser.mp4 和 org.apache.tika.parser.video 该解析器内部使用简单算法来解析 flash 视频格式 | Mp4parser FlvParser |
| java 类文件和 jar 文件 | org.apache.tika.parser.asm | 类解析器 压缩器解析器 |
| Mobx格式(电子邮件) | org.apache.tika.parser.mbox | MobX解析器 |
| CAD 格式 | org.apache.tika.parser.dwg | DWG解析器 |
| 字体格式 | org.apache.tika.parser.font | TrueType解析器 |
| 可执行程序和库 | org.apache.tika.parser.executable | 可执行解析器 |
TIKA - 文档类型检测
MIME 标准
多用途 Internet 邮件扩展 (MIME) 标准是识别文档类型的最佳可用标准。了解这些标准可以帮助浏览器进行内部交互。
每当浏览器遇到媒体文件时,它都会选择可用的兼容软件来显示其内容。如果没有任何合适的应用程序来运行特定媒体文件,它建议用户为其获取合适的插件软件。
Tika 中的类型检测
Tika 支持 MIME 中提供的所有互联网媒体文档类型。每当文件通过 Tika 时,它都会检测该文件及其文档类型。为了检测媒体类型,Tika 在内部使用以下机制。
文件扩展名
检查文件扩展名是检测文件格式最简单且最广泛使用的方法。许多应用程序和操作系统都提供对这些扩展的支持。下面显示的是一些已知文件类型的扩展名。
| 文件名 | 延伸 |
|---|---|
| 图像 | .jpg |
| 声音的 | .mp3 |
| java归档文件 | 。罐 |
| java类文件 | 。班级 |
内容类型提示
每当您从数据库检索文件或将其附加到另一个文档时,您可能会丢失文件的名称或扩展名。在这种情况下,随文件提供的元数据用于检测文件扩展名。
魔字节
观察文件的原始字节,您可以找到每个文件的一些独特的字符模式。有些文件具有特殊的字节前缀,称为魔术字节,它们是专门制作并包含在文件中的,用于识别文件类型
例如,您可以在 java 文件中找到 CA FE BA BE(十六进制格式),在 pdf 文件中找到 %PDF(ASCII 格式)。Tika 使用此信息来识别文件的媒体类型。
字符编码
纯文本文件使用不同类型的字符编码进行编码。这里的主要挑战是识别文件中使用的字符编码类型。Tika 遵循Bom 标记和字节频率等字符编码技术来识别纯文本内容使用的编码系统。
XML 根字符
为了检测 XML 文档,Tika 解析 xml 文档并提取信息,例如根元素、命名空间和引用模式,从中可以找到文件的真实媒体类型。
使用 Facade 类进行类型检测
Facade 类的detector ()方法用于检测文档类型。此方法接受文件作为输入。下面显示的是使用 Tika Facade 类进行文档类型检测的示例程序。
import java.io.File;
import org.apache.tika.Tika;
public class Typedetection {
public static void main(String[] args) throws Exception {
//assume example.mp3 is in your current directory
File file = new File("example.mp3");//
//Instantiating tika facade class
Tika tika = new Tika();
//detecting the file type using detect method
String filetype = tika.detect(file);
System.out.println(filetype);
}
}
将上述代码保存为 TypeDetection.java 并使用以下命令从命令提示符运行它 -
javac TypeDetection.java java TypeDetection audio/mpeg
TIKA - 内容提取
Tika 使用各种解析器库从给定的解析器中提取内容。它选择正确的解析器来提取给定的文档类型。
对于解析文档,通常使用 Tika Facade 类的 parseToString() 方法。下面显示的是解析过程中涉及的步骤,这些步骤由 Tika ParsertoString() 方法抽象。

抽象解析过程 -
最初,当我们将文档传递给 Tika 时,它会使用可用的合适类型检测机制并检测文档类型。
一旦知道文档类型,它就会从解析器存储库中选择合适的解析器。解析器存储库包含使用外部库的类。
然后传递文档以选择解析器,该解析器将解析内容、提取文本,并针对不可读的格式抛出异常。
使用 Tika 进行内容提取
下面给出的是使用 Tika 外观类从文件中提取文本的程序 -
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}
将上述代码保存为 TikaExtraction.java 并从命令提示符运行它 -
javac TikaExtraction.java java TikaExtraction
下面给出的是sample.txt的内容。
Hi students welcome to tutorialspoint
它为您提供以下输出 -
Extracted Content: Hi students welcome to tutorialspoint
使用解析器接口进行内容提取
Tika 的解析器包提供了几个接口和类,我们可以使用它们解析文本文档。下面给出的是org.apache.tika.parser包的框图。

有几个可用的解析器类,例如pdf解析器、Mp3Passer、OfficeParser等,可以单独解析各个文档。所有这些类都实现了解析器接口。
复合解析器
给定的图表显示了 Tika 的通用解析器类:CompositeParser和AutoDetectParser。由于 CompositeParser 类遵循复合设计模式,因此您可以将一组解析器实例用作单个解析器。CompositeParser 类还允许访问所有实现解析器接口的类。
自动检测解析器
这是 CompositeParser 的子类,它提供自动类型检测。使用此功能,AutoDetectParser 使用复合方法自动将传入文档发送到适当的解析器类。
解析()方法
除了 parseToString() 之外,您还可以使用解析器接口的 parse() 方法。该方法的原型如下所示。
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)
下表列出了它接受作为参数的四个对象。
| 先生。 | 对象及描述 |
|---|---|
| 1 |
输入流流 包含文件内容的任何 Inputstream 对象 |
| 2 |
ContentHandler处理程序 Tika 将文档作为 XHTML 内容传递给此处理程序,然后使用 SAX API 处理该文档。它提供了文档内容的高效后处理。 |
| 3 |
元数据元数据 元数据对象既用作文档元数据的源又用作目标。 |
| 4 |
ParseContext 上下文 该对象用于客户端应用程序想要自定义解析过程的情况。 |
例子
下面给出的示例显示了如何使用 parse() 方法。
步骤 1 -
要使用解析器接口的 parse() 方法,请实例化提供此接口实现的任何类。
有单独的解析器类,例如 PDFParser、OfficeParser、XMLParser 等。您可以使用这些单独的文档解析器中的任何一个。或者,您可以使用 CompositeParser 或 AutoDetectParser,它们在内部使用所有解析器类并使用合适的解析器提取文档的内容。
Parser parser = new AutoDetectParser(); (or) Parser parser = new CompositeParser(); (or) object of any individual parsers given in Tika Library
步骤 2 -
创建一个处理程序类对象。下面给出了三个内容处理程序 -
| 先生。 | 类别和描述 |
|---|---|
| 1 |
正文内容处理程序 此类选择 XHTML 输出的主体部分并将该内容写入输出写入器或输出流。然后它将 XHTML 内容重定向到另一个内容处理程序实例。 |
| 2 |
链接内容处理程序 此类检测并选取 XHTML 文档的所有 H-Ref 标签,并将这些标签转发给网络爬虫等工具使用。 |
| 3 |
TeeContentHandler 此类有助于同时使用多个工具。 |
由于我们的目标是从文档中提取文本内容,因此实例化 BodyContentHandler 如下所示 -
BodyContentHandler handler = new BodyContentHandler( );
步骤 3 -
创建元数据对象,如下所示 -
Metadata metadata = new Metadata();
步骤 4 -
创建任何输入流对象,并将应提取的文件传递给它。
文件输入流
通过将文件路径作为参数传递来实例化文件对象,并将该对象传递给 FileInputStream 类构造函数。
注意- 传递给文件对象的路径不应包含空格。
这些输入流类的问题是它们不支持随机访问读取,而这是有效处理某些文件格式所必需的。为了解决这个问题,Tika 提供了 TikaInputStream。
File file = new File(filepath) FileInputStream inputstream = new FileInputStream(file); (or) InputStream stream = TikaInputStream.get(new File(filename));
步骤 5 -
创建一个解析上下文对象,如下所示 -
ParseContext context =new ParseContext();
步骤 6 -
实例化解析器对象,调用解析方法,并传递所需的所有对象,如下面的原型所示 -
parser.parse(inputstream, handler, metadata, context);
下面给出的是使用解析器接口进行内容提取的程序 -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}
将上述代码保存为 ParserExtraction.java 并从命令提示符运行它 -
javac ParserExtraction.java java ParserExtraction
下面给出的是sample.txt的内容
Hi students welcome to tutorialspoint
如果执行上面的程序,它将给出以下输出 -
File content : Hi students welcome to tutorialspoint
TIKA - 元数据提取
除了内容之外,Tika 还从文件中提取元数据。元数据只不过是文件提供的附加信息。如果我们考虑音频文件,艺术家姓名、专辑名称、标题都属于元数据。
XMP标准
可扩展元数据平台 (XMP) 是用于处理和存储与文件内容相关的信息的标准。它是由Adobe Systems Inc.创建的。XMP 提供了定义、创建和处理元数据的标准。您可以将此标准嵌入到多种文件格式中,例如PDF、JPEG、JPEG、GIF、jpg、HTML等。
财产类别
Tika 使用 Property 类来遵循 XMP 属性定义。它提供PropertyType和ValueType枚举来捕获元数据的名称和值。
元数据类
该类实现了各种接口,例如ClimateForcast、 CativeCommons 、Geographic、 TIFF 等,以提供对各种元数据模型的支持。此外,此类还提供了各种从文件中提取内容的方法。
元数据名称
我们可以使用方法名称()从文件的元数据对象中提取文件的所有元数据名称的列表。它将所有名称作为字符串数组返回。使用元数据的名称,我们可以使用get()方法获取值。它采用元数据名称并返回与其关联的值。
String[] metadaNames = metadata.names(); String value = metadata.get(name);
使用 Parse 方法提取元数据
每当我们使用 parse() 解析文件时,我们都会传递一个空的元数据对象作为参数之一。此方法提取给定文件的元数据(如果该文件包含任何元数据),并将它们放入元数据对象中。因此,在使用 parse() 解析文件后,我们可以从该对象中提取元数据。
Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); //empty metadata object FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); parser.parse(inputstream, handler, metadata, context); // now this metadata object contains the extracted metadata of the given file. metadata.metadata.names();
下面给出的是从文本文件中提取元数据的完整程序。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
将上述代码保存为 GetMetadata.java 并使用以下命令从命令提示符运行它 -
javac GetMetadata .java java GetMetadata
下面给出的是 boy.jpg 的快照

如果执行上面的程序,它将给出以下输出 -
X-Parsed-By: org.apache.tika.parser.DefaultParser Resolution Units: inch Compression Type: Baseline Data Precision: 8 bits Number of Components: 3 tiff:ImageLength: 3000 Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert Image Height: 3000 pixels X Resolution: 300 dots Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1 Image Width: 4000 pixels IPTC-NAA record: 92 bytes binary data Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert tiff:BitsPerSample: 8 Application Record Version: 4 tiff:ImageWidth: 4000 Content-Type: image/jpeg Y Resolution: 300 dots
我们还可以获得我们想要的元数据值。
添加新的元数据值
我们可以使用元数据类的 add() 方法添加新的元数据值。下面给出了该方法的语法。在这里我们添加作者姓名。
metadata.add(“author”,”Tutorials point”);
Metadata 类具有预定义的属性,包括从ClimateForcast、 CativeCommons 、Geographic等类继承的属性,以支持各种数据模型。下面显示的是从 Tika 实现的 TIFF 接口继承的 SOFTWARE 数据类型的用法,以遵循 TIFF 图像格式的 XMP 元数据标准。
metadata.add(Metadata.SOFTWARE,"ms paint");
下面给出的是完整的程序,演示如何将元数据值添加到给定文件。这里,元数据元素的列表显示在输出中,以便您可以观察添加新值后列表中的变化。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}
将上述代码保存为 AddMetadata.java 类并从命令提示符运行它 -
javac AddMetadata .java java AddMetadata
下面给出的是Example.txt的内容
Hi students welcome to tutorialspoint
如果执行上面的程序,它将给出以下输出 -
metadata elements of the given file : [Content-Encoding, Content-Type] enter the number of metadata name value pairs to be added 1 enter metadata1name: Author enter metadata1value: Tutorials point metadata name value pair is successfully added Here is the list of all the metadata elements after adding new elements [Content-Encoding, Author, Content-Type]
为现有元数据元素设置值
您可以使用 set() 方法为现有元数据元素设置值。使用 set() 方法设置日期属性的语法如下 -
metadata.set(Metadata.DATE, new Date());
您还可以使用 set() 方法为属性设置多个值。使用 set() 方法为 Author 属性设置多个值的语法如下 -
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
下面给出的是演示 set() 方法的完整程序。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
将上述代码保存为 SetMetadata.java 并从命令提示符运行它 -
javac SetMetadata.java java SetMetadata
下面给出的是 example.txt 的内容。
Hi students welcome to tutorialspoint
如果执行上面的程序,它将给出以下输出。在输出中,您可以观察新添加的元数据元素。
metadata elements and values of the given file : Content-Encoding: ISO-8859-1 Content-Type: text/plain; charset = ISO-8859-1 Here is the list of all the metadata elements after adding new elements date: 2014-09-24T07:01:32Z Content-Encoding: ISO-8859-1 Author: ram, raheem, robin Content-Type: text/plain; charset = ISO-8859-1
TIKA - 语言检测
需要语言检测
为了根据多语言网站中编写的语言对文档进行分类,需要语言检测工具。该工具应该接受没有语言注释(元数据)的文档,并通过检测语言将该信息添加到文档的元数据中。
分析语料库的算法
什么是语料库?
为了检测文档的语言,构建语言配置文件并将其与已知语言的配置文件进行比较。这些已知语言的文本集称为语料库。
语料库是书面语言文本的集合,解释该语言在实际情况中的使用方式。
该语料库是根据书籍、成绩单和互联网等其他数据资源开发的。语料库的准确性取决于我们用来构建语料库的分析算法。
什么是分析算法?
检测语言的常见方法是使用字典。给定文本片段中使用的单词将与词典中的单词相匹配。
一种语言中使用的常用单词列表将是用于检测特定语言的最简单且有效的语料库,例如英语中的文章a、an、the 。
使用单词集作为语料库
使用单词集,构建一个简单的算法来查找两个语料库之间的距离,该距离等于匹配单词的频率之间的差异之和。
此类算法存在以下问题 -
由于匹配单词的频率非常低,因此该算法无法有效地处理句子较少的小文本。它需要大量文本才能准确匹配。
它无法检测具有复合句子的语言以及没有空格或标点符号等单词分隔符的语言的单词边界。
由于使用单词集作为语料库存在这些困难,因此需要考虑单个字符或字符组。
使用字符集作为语料库
由于语言中常用的字符数量有限,因此很容易应用基于词频而不是字符的算法。在一种或极少数语言使用某些字符集的情况下,该算法效果更好。
该算法存在以下缺点 -
区分具有相似字符频率的两种语言是很困难的。
没有特定的工具或算法可以借助(作为语料库)多种语言使用的字符集来专门识别一种语言。
N-gram算法
上述缺点催生了一种使用给定长度的字符序列来分析语料库的新方法。这种字符序列一般称为N-gram,其中N表示字符序列的长度。
N-gram 算法是一种有效的语言检测方法,特别是对于英语等欧洲语言。
该算法对于短文本效果很好。
尽管有先进的语言分析算法可以检测多语言文档中的多种语言,这些算法具有更有吸引力的功能,但 Tika 使用 3-grams 算法,因为它适合大多数实际情况。
Tika 中的语言检测
在 ISO 639-1 标准化的所有 184 种标准语言中,Tika 可以检测 18 种语言。Tika 中的语言检测是使用LanguageIdentifier类的getLanguage()方法完成的。此方法以字符串格式返回语言的代码名称。下面给出的是 Tika 检测到的 18 个语言代码对的列表 -
| da——丹麦语 | de—德语 | et—爱沙尼亚语 | el——希腊语 |
| en—英语 | es—西班牙语 | fi—芬兰语 | fr—法语 |
| hu—匈牙利语 | 是——冰岛语 | 它——意大利语 | nl—荷兰语 |
| 不——挪威语 | pl—波兰语 | pt—葡萄牙语 | ru—俄语 |
| sv—瑞典语 | th—泰语 |
在实例化LanguageIdentifier类时,您应该传递要提取的内容的String格式,或者LanguageProfile类对象。
LanguageIdentifier object = new LanguageIdentifier(“this is english”);
下面给出的是 Tika 中语言检测的示例程序。
import java.io.IOException; import org.apache.tika.exception.TikaException; import org.apache.tika.language.LanguageIdentifier; import org.xml.sax.S