- 人工智能与 Python 教程
- 家
- AI 与 Python – 入门概念
- AI 与 Python – 入门
- AI 与 Python – 机器学习
- AI与Python——数据准备
- 监督学习:分类
- 监督学习:回归
- AI与Python——逻辑编程
- 无监督学习:聚类
- 自然语言处理
- AI 与 Python – NLTK 包
- 分析时间序列数据
- AI与Python——语音识别
- AI 与 Python – 启发式搜索
- AI 与 Python – 游戏
- 使用 Python 进行人工智能 – 神经网络
- 强化学习
- AI与Python——遗传算法
- 人工智能与Python——计算机视觉
- AI 与 Python – 深度学习
- 人工智能与 Python 资源
- AI 与 Python – 快速指南
- AI 与 Python – 有用的资源
- AI 与 Python – 讨论
AI 与 Python – 快速指南
AI 与 Python – 入门概念
自从计算机或机器发明以来,它们执行各种任务的能力经历了指数级增长。人类已经在不同的工作领域、不断提高的速度以及随着时间的推移而减小尺寸方面开发了计算机系统的强大功能。
计算机科学的一个分支称为人工智能,致力于创造像人类一样智能的计算机或机器。
人工智能(AI)的基本概念
按照人工智能之父约翰·麦卡锡的说法,它是“制造智能机器,特别是智能计算机程序的科学和工程”。
人工智能是一种让计算机、计算机控制的机器人或软件进行智能思考的方法,就像智能人类的思考方式一样。人工智能是通过研究人脑如何思考以及人类在尝试解决问题时如何学习、决策和工作,然后将研究结果作为开发智能软件和系统的基础来实现的。
在利用计算机系统的力量时,人类的好奇心让他想知道:“机器能否像人类一样思考和Behave?”
因此,人工智能的发展始于在机器中创造出我们在人类身上发现并高度重视的类似智能。
学习人工智能的必要性
众所周知,人工智能追求创造像人类一样智能的机器。我们研究人工智能的原因有很多。原因如下:
人工智能可以通过数据学习
在我们的日常生活中,我们处理大量的数据,而人脑无法跟踪这么多的数据。这就是为什么我们需要自动化。要做自动化,我们需要研究人工智能,因为它可以从数据中学习,可以准确地完成重复性的任务,而且不会感到疲劳。
人工智能可以自学
系统自学是非常有必要的,因为数据本身不断变化,从这些数据中得出的知识也必须不断更新。我们可以使用人工智能来实现这一目的,因为人工智能支持的系统可以自我学习。
AI可实时响应
人工智能在神经网络的帮助下可以更深入地分析数据。由于这种能力,人工智能可以根据情况实时思考并做出反应。
人工智能实现准确性
借助深度神经网络,人工智能可以实现极高的准确性。人工智能有助于医学领域通过患者的核磁共振成像诊断癌症等疾病。
人工智能可以组织数据以充分利用数据
这些数据是使用自学习算法的系统的知识产权。我们需要人工智能以始终提供最佳结果的方式来索引和组织数据。
了解情报
通过人工智能,可以构建智能系统。我们需要理解智能的概念,以便我们的大脑能够构建另一个像它自己一样的智能系统。
什么是情报?
系统计算、推理、感知关系和类比、从经验中学习、从记忆中存储和检索信息、解决问题、理解复杂思想、流利使用自然语言、分类、概括和适应新情况的能力。
智力的类型
正如美国发展心理学家霍华德·加德纳所描述的,智力有多种形式:
| 先生编号 | 情报与描述 | 例子 |
|---|---|---|
| 1 | 语言智能 说话、识别和使用音韵(语音)、句法(语法)和语义(意义)机制的能力。 |
解说员、演说家 |
| 2 | 音乐智力 创造、交流和理解声音意义的能力,理解音高、节奏的能力。 |
音乐家、歌手、作曲家 |
| 3 | 逻辑数学智能 在没有动作或物体的情况下使用和理解关系的能力。它也是理解复杂和抽象思想的能力。 |
数学家、科学家 |
| 4 | 空间智能 感知视觉或空间信息、改变它以及在不参考对象的情况下重新创建视觉图像、构建 3D 图像以及移动和旋转它们的能力。 |
地图阅读器、宇航员、物理学家 |
| 5 | 身体动觉智力 使用整个或部分身体来解决问题或时尚产品、控制精细和粗略运动技能以及操纵物体的能力。 |
选手、舞者 |
| 6 | 个人内部智力 区分自己的感受、意图和动机的能力。 |
释迦牟尼佛 |
| 7 | 人际关系智能 识别并区分他人的感受、信仰和意图的能力。 |
大众传播者、采访者 |
当一台机器或一个系统配备了至少一种或全部智能时,您可以说它是人工智能的。
智力由什么组成?
智力是无形的。它由以下部分组成 -
- 推理
- 学习
- 解决问题
- 洞察力
- 语言智能
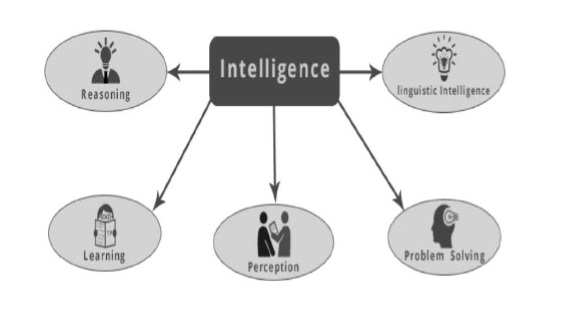
让我们简要介绍一下所有组件 -
推理
它是使我们能够为判断、决策和预测提供基础的一组过程。大致有两种类型 -
| 归纳推理 | 演绎推理 |
|---|---|
| 它进行具体观察以做出广泛的一般性陈述。 | 它从一般性陈述开始,并研究得出具体的、合乎逻辑的结论的可能性。 |
| 即使陈述中的所有前提都为真,归纳推理也允许结论为假。 | 如果某件事对于一类事物来说是普遍的,那么对于该类的所有成员来说也是如此。 |
| 示例- “妮塔是一位老师。妮塔很勤奋。因此,所有老师都很勤奋。” | 示例- “所有 60 岁以上的女性都是祖母。Shalini 65 岁。因此,Shalini 是祖母。” |
学习 - l
人类、特定物种的动物和人工智能系统都具备学习能力。学习分类如下 -
听觉学习
它是通过倾听和聆听来学习。例如,学生听录制的音频讲座。
情景学习
通过记住亲眼目睹或经历过的一系列事件来学习。这是线性且有序的。
运动学习
它通过肌肉的精确运动来学习。例如,拾取物体、书写等。
观察学习
通过观察和模仿他人来学习。例如,孩子试图通过模仿父母来学习。
感性学习
它正在学习识别人们以前见过的刺激。例如,识别对象和情况并对其进行分类。
关系学习
它涉及学习根据关系属性而不是绝对属性来区分各种刺激。例如,上次煮土豆时加“少一点”盐,煮时加一汤匙盐。
空间学习- 它是通过图像、颜色、地图等视觉刺激进行学习。例如,一个人可以在实际沿着道路行驶之前在脑海中创建路线图。
刺激反应学习- 学习在存在某种刺激时执行特定Behave。例如,狗听到门铃时会抬起耳朵。
解决问题
这是一个过程,在这个过程中,一个人感知并试图通过某种被已知或未知的障碍阻碍的路径,从当前的情况中获得期望的解决方案。
解决问题还包括决策,即从多种方案中选择最合适的方案以达到预期目标的过程。
洞察力
它是获取、解释、选择和组织感官信息的过程。
感知以感知为前提。在人类中,感知是由感觉器官帮助的。在人工智能领域,感知机制将传感器获取的数据以有意义的方式组合在一起。
语言智能
它是一个人使用、理解、说和写口头和书面语言的能力。这在人际交往中很重要。
人工智能涉及什么
人工智能是一个广阔的研究领域。该研究领域有助于寻找现实世界问题的解决方案。
现在让我们看看人工智能的不同研究领域 -
机器学习
它是人工智能最热门的领域之一。该领域的基本概念是使机器从数据中学习,就像人类可以从他/她的经验中学习一样。它包含学习模型,在此基础上可以对未知数据进行预测。
逻辑
这是使用数理逻辑来执行计算机程序的另一个重要研究领域。它包含执行模式匹配、语义分析等的规则和事实。
搜寻中
这个研究领域主要用于国际象棋、井字棋等游戏。搜索算法在搜索整个搜索空间后给出最优解决方案。
人工神经网络
这是一个高效计算系统的网络,其中心主题借鉴了生物神经网络的类比。ANN 可用于机器人、语音识别、语音处理等领域。
遗传算法
遗传算法有助于在多个程序的帮助下解决问题。结果将基于选择最适合的人。
知识表示
这是一个研究领域,借助它,我们可以以机器可以理解的方式表示事实。知识的表达效率越高;系统越智能。
人工智能应用
在本节中,我们将看到人工智能支持的不同领域 -
赌博
人工智能在国际象棋、扑克、井字游戏等战略游戏中发挥着至关重要的作用,机器可以根据启发式知识思考大量可能的位置。
自然语言处理
可以与理解人类所说的自然语言的计算机进行交互。
专家系统
有一些应用程序集成了机器、软件和特殊信息来传递推理和建议。他们向用户提供解释和建议。
视觉系统
这些系统理解、解释和理解计算机上的视觉输入。例如,
间谍飞机拍摄照片,用于找出空间信息或该地区的地图。
医生使用临床专家系统来诊断患者。
警方使用计算机软件,可以通过法医艺术家制作的存储肖像来识别罪犯的脸部。
语音识别
一些智能系统能够在人类与之交谈时听到并理解句子及其含义的语言。它可以处理不同的口音、俚语、背景噪音、由于寒冷而引起的人类噪音变化等。
手写识别
手写识别软件读取用笔写在纸上或用手写笔在屏幕上写的文本。它可以识别字母的形状并将其转换为可编辑的文本。
智能机器人
机器人能够执行人类指定的任务。它们拥有传感器来检测现实世界的物理数据,例如光、热、温度、运动、声音、碰撞和压力。它们拥有高效的处理器、多个传感器和巨大的内存,以展现智能。此外,他们能够从错误中吸取教训,能够适应新环境。
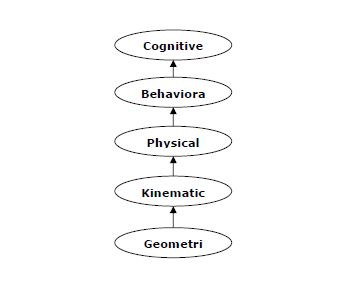
认知建模:模拟人类思维过程
认知建模基本上是计算机科学的研究领域,涉及研究和模拟人类的思维过程。人工智能的主要任务是让机器像人一样思考。人类思维过程最重要的特征就是解决问题。这就是为什么认知模型或多或少地试图理解人类如何解决问题。之后该模型可用于各种人工智能应用,如机器学习、机器人、自然语言处理等。下图是人脑不同思维层次的图 -
代理与环境
在本节中,我们将重点关注代理和环境以及它们如何在人工智能中发挥作用。
代理人
代理是任何可以通过传感器感知其环境并通过效应器对该环境采取行动的东西。
人类代理具有与传感器平行的感觉器官,例如眼睛、耳朵、鼻子、舌头和皮肤,以及其他器官,例如手、腿、嘴,作为效应器。
机器人代理取代了传感器的摄像头和红外测距仪,以及效应器的各种电机和执行器。
软件代理将位串编码为其程序和操作。
环境
有些程序在完全人造的环境中运行,仅限于键盘输入、数据库、计算机文件系统和屏幕上的字符输出。
相比之下,一些软件代理(软件机器人或软机器人)存在于丰富的、无限的软机器人领域中。模拟器有一个非常详细、复杂的环境。软件代理需要从大量的实时操作中进行选择。软机器人旨在扫描客户的在线偏好,并在真实和人工环境中向客户展示有趣的项目。
AI 与 Python – 入门
在本章中,我们将学习如何开始使用Python。我们还将了解 Python 如何帮助人工智能。
为什么Python适合人工智能
人工智能被认为是未来的趋势技术。已经有许多应用程序对此进行了开发。因此,许多公司和研究人员对此产生了兴趣。但这里出现的主要问题是,这些人工智能应用程序可以用哪种编程语言来开发?有多种编程语言,如 Lisp、Prolog、C++、Java 和 Python,可用于开发人工智能应用程序。其中,Python编程语言非常受欢迎,原因如下:
简单的语法和更少的编码
与其他可用于开发人工智能应用程序的编程语言相比,Python 涉及的代码非常少,语法也很简单。由于这个特性,测试可以更容易,我们可以更专注于编程。
AI 项目的内置库
使用 Python 进行 AI 的一个主要优势是它带有内置库。Python 拥有几乎所有类型的人工智能项目的库。例如,NumPy、SciPy、matplotlib、nltk、SimpleAI是 Python 的一些重要的内置库。
开源- Python 是一种开源编程语言。这使得它在社会上广泛流行。
可用于广泛的编程- Python 可用于广泛的编程任务,例如小型 shell 脚本到企业 Web 应用程序。这是Python适合AI项目的另一个原因。
Python的特点
Python 是一种高级、解释性、交互式、面向对象的脚本语言。Python 被设计为具有高度可读性。它经常使用英语关键字,而其他语言则使用标点符号,并且它的句法结构比其他语言更少。Python 的功能包括以下内容 -
易于学习- Python 关键字很少、结构简单、语法定义明确。这使得学生能够快速掌握该语言。
易于阅读- Python 代码定义更清晰且肉眼可见。
易于维护- Python 的源代码相当易于维护。
广泛的标准库- Python 的大部分库在 UNIX、Windows 和 Macintosh 上非常可移植且跨平台兼容。
交互模式- Python 支持交互模式,允许对代码片段进行交互测试和调试。
可移植- Python 可以在各种硬件平台上运行,并且在所有平台上具有相同的接口。
可扩展- 我们可以向 Python 解释器添加低级模块。这些模块使程序员能够添加或自定义他们的工具以提高效率。
数据库- Python 提供所有主要商业数据库的接口。
GUI 编程- Python 支持 GUI 应用程序,可以创建这些应用程序并将其移植到许多系统调用、库和 Windows 系统,例如 Windows MFC、Macintosh 和 Unix 的 X Window 系统。
可扩展- Python 为大型程序提供了比 shell 脚本更好的结构和支持。
Python 的重要特性
现在让我们考虑一下 Python 的以下重要特性 -
它支持函数式和结构化编程方法以及 OOP。
它可以用作脚本语言,也可以编译为字节码以构建大型应用程序。
它提供非常高级的动态数据类型并支持动态类型检查。
它支持自动垃圾收集。
它可以轻松地与 C、C++、COM、ActiveX、CORBA 和 Java 集成。
安装Python
Python 发行版可用于大量平台。您只需下载适用于您的平台的二进制代码并安装 Python。
如果您的平台的二进制代码不可用,您需要 C 编译器来手动编译源代码。编译源代码在选择安装中所需的功能方面提供了更大的灵活性。
以下是在各种平台上安装 Python 的快速概述 -
Unix 和 Linux 安装
请按照以下步骤在 Unix/Linux 计算机上安装 Python。
打开 Web 浏览器并访问https://www.python.org/downloads
点击链接下载适用于 Unix/Linux 的压缩源代码。
下载并解压文件。
如果您想自定义某些选项,请编辑模块/安装文件。
运行./configure脚本
制作
进行安装
这会将 Python 安装在标准位置 /usr/local/bin 并将其库安装在/usr/local/lib/pythonXX处,其中 XX 是 Python 的版本。
Windows安装
请按照以下步骤在 Windows 计算机上安装 Python。
打开 Web 浏览器并访问https://www.python.org/downloads
单击 Windows 安装程序python-XYZ .msi 文件的链接,其中 XYZ 是您需要安装的版本。
要使用此安装程序python-XYZ .msi,Windows 系统必须支持 Microsoft Installer 2.0。将安装程序文件保存到本地计算机,然后运行它以查明您的计算机是否支持 MSI。
运行下载的文件。这会弹出 Python 安装向导,非常易于使用。只需接受默认设置并等待安装完成。
Macintosh 安装
如果您使用的是 Mac OS X,建议您使用 Homebrew 安装 Python 3。它是 Mac OS X 的一个很棒的软件包安装程序,而且非常易于使用。如果您没有 Homebrew,可以使用以下命令安装它 -
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
我们可以使用以下命令更新包管理器 -
$ brew update
现在运行以下命令在您的系统上安装 Python3 -
$ brew install python3
设置路径
程序和其他可执行文件可以位于许多目录中,因此操作系统提供了一个搜索路径,其中列出了操作系统搜索可执行文件的目录。
该路径存储在环境变量中,该变量是由操作系统维护的命名字符串。该变量包含命令 shell 和其他程序可用的信息。
路径变量在 Unix 中命名为 PATH,在 Windows 中命名为 Path(Unix 区分大小写;Windows 不区分大小写)。
在 Mac OS 中,安装程序处理路径详细信息。要从任何特定目录调用 Python 解释器,您必须将 Python 目录添加到您的路径中。
在 Unix/Linux 下设置路径
将 Python 目录添加到 Unix 中特定会话的路径 -
在 csh shell 中
输入setenv PATH "$PATH:/usr/local/bin/python"并按Enter。
在 bash shell 中 (Linux)
输入export ATH = "$PATH:/usr/local/bin/python"并按Enter。
在 sh 或 ksh shell 中
输入PATH = "$PATH:/usr/local/bin/python"并按Enter。
注意- /usr/local/bin/python 是 Python 目录的路径。
在 Windows 下设置路径
将 Python 目录添加到 Windows 中特定会话的路径 -
在命令提示符处- 输入路径 %path%;C:\Python并按Enter。
注意- C:\Python 是 Python 目录的路径。
运行Python
现在让我们看看运行 Python 的不同方法。方法如下所述 -
互动口译员
我们可以从 Unix、DOS 或任何其他提供命令行解释器或 shell 窗口的系统启动 Python。
在命令行中输入python 。
立即在交互式解释器中开始编码。
$python # Unix/Linux
或者
python% # Unix/Linux
或者
C:> python # Windows/DOS
以下是所有可用命令行选项的列表 -
| 编号 | 选项和说明 |
|---|---|
| 1 | -d 它提供调试输出。 |
| 2 | -o 它生成优化的字节码(生成 .pyo 文件)。 |
| 3 | -S 不要在启动时运行 import site 来查找 Python 路径。 |
| 4 | -v 详细输出(导入语句的详细跟踪)。 |
| 5 | -X 禁用基于类的内置异常(仅使用字符串);从版本 1.6 开始已过时。 |
| 6 | -c命令 运行作为 cmd 字符串发送的 Python 脚本。 |
| 7 | 文件 从给定文件运行 Python 脚本。 |
来自命令行的脚本
可以通过调用应用程序上的解释器来在命令行执行 Python 脚本,如下所示 -
$python script.py # Unix/Linux
或者,
python% script.py # Unix/Linux
或者,
C:> python script.py # Windows/DOS
注意- 确保文件权限模式允许执行。
集成开发环境
如果您的系统上有支持 Python 的 GUI 应用程序,您也可以从图形用户界面 (GUI) 环境运行 Python。
Unix - IDLE 是第一个用于 Python 的 Unix IDE。
Windows - PythonWin 是第一个 Python 的 Windows 界面,是一个带有 GUI 的 IDE。
Macintosh - Macintosh 版本的 Python 以及 IDLE IDE 可从主网站获取,可作为 MacBinary 或 BinHex 文件下载。
如果您无法正确设置环境,那么您可以向系统管理员寻求帮助。确保 Python 环境已正确设置并且工作正常。
我们还可以使用另一个名为 Anaconda 的 Python 平台。它包括数百个流行的数据科学软件包以及适用于 Windows、Linux 和 MacOS 的 conda 软件包和虚拟环境管理器。您可以根据您的操作系统从链接https://www.anaconda.com/download/下载它。
在本教程中,我们使用 MS Windows 上的 Python 3.6.3 版本。
AI 与 Python – 机器学习
学习是指通过学习或经验获得知识或技能。基于此,我们可以将机器学习(ML)定义如下 -
它可以被定义为计算机科学领域,更具体地说是人工智能的应用,它为计算机系统提供了利用数据学习并从经验中改进的能力,而无需明确编程。
基本上,机器学习的主要焦点是让计算机自动学习而无需人工干预。现在的问题是如何开始和完成这样的学习?可以从数据观察开始。数据也可以是一些例子、指导或一些直接经验。然后,根据此输入,机器通过寻找数据中的某些模式来做出更好的决策。
机器学习 (ML) 的类型
机器学习算法可以帮助计算机系统无需显式编程即可学习。这些算法分为监督算法和无监督算法。现在让我们看一些算法 -
监督机器学习算法
这是最常用的机器学习算法。之所以称为监督式,是因为算法从训练数据集学习的过程可以被视为监督学习过程的老师。在这种机器学习算法中,可能的结果是已知的,并且训练数据也标有正确答案。可以理解如下 -
假设我们有输入变量x和输出变量y,并且我们应用算法来学习从输入到输出的映射函数,例如 -
Y = f(x)
现在,主要目标是很好地近似映射函数,以便当我们有新的输入数据 (x) 时,我们可以预测该数据的输出变量 (Y)。
主要监督学习问题可以分为以下两类问题 -
分类- 当我们有“黑色”、“教学”、“非教学”等分类输出时,问题称为分类问题。
回归- 当我们有实际值输出(例如“距离”、“千克”等)时,问题称为回归问题。
决策树、随机森林、knn、逻辑回归是监督机器学习算法的例子。
无监督机器学习算法
顾名思义,这类机器学习算法没有任何监督者提供任何形式的指导。这就是为什么无监督机器学习算法与一些人所说的真正的人工智能密切相关。可以理解如下 -
假设我们有输入变量 x,那么就不会像监督学习算法那样有相应的输出变量。
简单来说,我们可以说,在无监督学习中,不会有正确答案,也不会有老师指导。算法有助于发现数据中有趣的模式。
无监督学习问题可以分为以下两类问题 -
聚类- 在聚类问题中,我们需要发现数据中固有的分组。例如,根据客户的购买Behave对客户进行分组。
关联- 问题称为关联问题,因为此类问题需要发现描述大部分数据的规则。例如,查找同时购买x和y的客户。
用于聚类的 K 均值、用于关联的 Apriori 算法是无监督机器学习算法的示例。
强化机器学习算法
这类机器学习算法的使用非常少。这些算法训练系统做出具体决策。基本上,机器暴露在一个使用试错法不断自我训练的环境中。这些算法从过去的经验中学习,并尝试捕获最佳的知识以做出准确的决策。马尔可夫决策过程是强化机器学习算法的一个例子。
最常见的机器学习算法
在本节中,我们将了解最常见的机器学习算法。算法描述如下 -
线性回归
它是统计学和机器学习领域最著名的算法之一。
基本概念 - 主要线性回归是一种线性模型,假设输入变量 x 和单个输出变量 y 之间存在线性关系。换句话说,我们可以说 y 可以通过输入变量 x 的线性组合来计算。变量之间的关系可以通过拟合最佳线来建立。
线性回归的类型
线性回归有以下两种类型 -
简单线性回归- 如果线性回归算法只有一个自变量,则称为简单线性回归。
多元线性回归- 如果线性回归算法具有多个自变量,则称为多元线性回归。
线性回归主要用于基于连续变量估计真实值。例如,基于实际值,可以通过线性回归来估计商店一天的总销售额。
逻辑回归
它是一种分类算法,也称为Logit回归。
逻辑回归主要是一种分类算法,用于根据给定的一组自变量来估计离散值,如 0 或 1、真或假、是或否。基本上,它预测概率,因此其输出介于 0 和 1 之间。
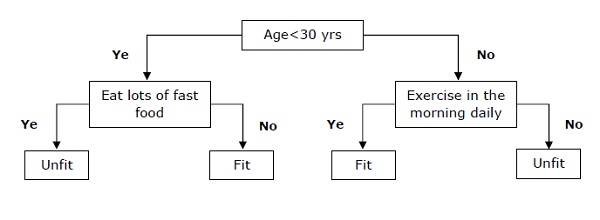
决策树
决策树是一种监督学习算法,主要用于分类问题。
基本上它是一个分类器,表示为基于自变量的递归划分。决策树具有形成有根树的节点。有根树是一种有向树,其节点称为“根”。根节点没有任何传入边,所有其他节点都有一个传入边。这些节点称为叶子节点或决策节点。例如,考虑以下决策树来查看一个人是否适合。
支持向量机(SVM)
它用于分类和回归问题。但主要用于分类问题。SVM的主要概念是将每个数据项绘制为n维空间中的一个点,每个特征的值是特定坐标的值。这里 n 是我们将拥有的特征。以下是理解 SVM 概念的简单图形表示 -
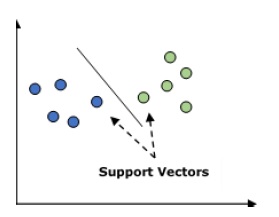
在上图中,我们有两个特征,因此我们首先需要在二维空间中绘制这两个变量,其中每个点都有两个坐标,称为支持向量。该线将数据分为两个不同的分类组。这条线就是分类器。
朴素贝叶斯
这也是一种分类技术。这种分类技术背后的逻辑是使用贝叶斯定理来构建分类器。假设预测变量是独立的。简而言之,它假设类中特定功能的存在与任何其他功能的存在无关。以下是贝叶斯定理的方程 -
$$P\left ( \frac{A}{B} \right ) = \frac{P\left ( \frac{B}{A} \right )P\left ( A \right )}{P\left ( B \右)}$$
朴素贝叶斯模型易于构建,对于大型数据集特别有用。
K 最近邻 (KNN)
它用于问题的分类和回归。它被广泛用于解决分类问题。该算法的主要概念是它用于存储所有可用的案例,并通过其 k 个邻居的多数票对新案例进行分类。然后将该案例分配给通过距离函数测量的 K 最近邻中最常见的类。距离函数可以是欧氏距离、闵可夫斯基距离和汉明距离。使用 KNN 时请考虑以下因素 -
KNN 的计算成本比用于分类问题的其他算法昂贵。
需要对变量进行标准化,否则较高范围的变量可能会产生偏差。
在KNN中,我们需要进行预处理阶段,例如噪声去除。
K 均值聚类
顾名思义,它是用来解决聚类问题的。它基本上是一种无监督学习。K-Means聚类算法的主要逻辑是通过多个聚类对数据集进行分类。按照以下步骤通过 K-means 形成簇 -
K 均值为每个簇选取 k 个点(称为质心)。
现在每个数据点形成一个具有最近质心的簇,即k个簇。
现在,它将根据现有的集群成员找到每个集群的质心。
我们需要重复这些步骤直到收敛。
随机森林
它是一种监督分类算法。随机森林算法的优点是它可以用于分类和回归类型的问题。基本上它是决策树(即森林)的集合,或者你可以说决策树的集合。随机森林的基本概念是每棵树给出一个分类,森林从中选择最好的分类。以下是随机森林算法的优点 -
随机森林分类器可用于分类和回归任务。
他们可以处理缺失值。
即使森林中有更多的树木,它也不会过度拟合模型。
AI与Python——数据准备
我们已经研究了有监督和无监督的机器学习算法。这些算法需要格式化数据才能开始训练过程。我们必须以某种方式准备或格式化数据,以便将其作为机器学习算法的输入。
本章重点介绍机器学习算法的数据准备。
预处理数据
在我们的日常生活中,我们处理大量数据,但这些数据都是原始形式的。为了提供数据作为机器学习算法的输入,我们需要将其转换为有意义的数据。这就是数据预处理的用武之地。换句话说,我们可以说,在将数据提供给机器学习算法之前,我们需要对数据进行预处理。
数据预处理步骤
按照以下步骤在 Python 中预处理数据 -
步骤 1 - 导入有用的包- 如果我们使用 Python,那么这将是将数据转换为某种格式的第一步,即预处理。可以按如下方式完成 -
import numpy as np import sklearn.preprocessing
这里我们使用了以下两个包 -
NumPy - 基本上,NumPy 是一个通用数组处理包,旨在有效地操作任意记录的大型多维数组,而不会为小型多维数组牺牲太多速度。
Sklearn.preprocessing - 该包提供了许多常见的实用函数和转换器类,可将原始特征向量更改为更适合机器学习算法的表示形式。
步骤 2 - 定义示例数据- 导入包后,我们需要定义一些示例数据,以便我们可以对该数据应用预处理技术。我们现在将定义以下示例数据 -
input_data = np.array([2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8])
步骤3 - 应用预处理技术- 在这一步中,我们需要应用任何预处理技术。
以下部分介绍数据预处理技术。
数据预处理技术
数据预处理技术如下所述 -
二值化
这是当我们需要将数值转换为布尔值时使用的预处理技术。我们可以使用内置方法对输入数据进行二值化,例如使用 0.5 作为阈值,如下所示 -
data_binarized = preprocessing.Binarizer(threshold = 0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)
现在,运行上述代码后,我们将得到以下输出,所有高于 0.5(阈值)的值将转换为 1,所有低于 0.5 的值将转换为 0。
二值化数据
[[ 1. 0. 1.] [ 0. 1. 1.] [ 0. 0. 1.] [ 1. 1. 0.]]
均值去除
这是机器学习中使用的另一种非常常见的预处理技术。基本上它用于消除特征向量的均值,以便每个特征都以零为中心。我们还可以消除特征向量中特征的偏差。为了对样本数据应用均值去除预处理技术,我们可以编写如下所示的Python代码。该代码将显示输入数据的平均值和标准偏差 -
print("Mean = ", input_data.mean(axis = 0))
print("Std deviation = ", input_data.std(axis = 0))
运行上述代码行后,我们将得到以下输出 -
Mean = [ 1.75 -1.275 2.2] Std deviation = [ 2.71431391 4.20022321 4.69414529]
现在,下面的代码将删除输入数据的平均值和标准差 -
data_scaled = preprocessing.scale(input_data)
print("Mean =", data_scaled.mean(axis=0))
print("Std deviation =", data_scaled.std(axis = 0))
运行上述代码行后,我们将得到以下输出 -
Mean = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00] Std deviation = [ 1. 1. 1.]
缩放
这是另一种用于缩放特征向量的数据预处理技术。需要对特征向量进行缩放,因为每个特征的值可能在许多随机值之间变化。换句话说,我们可以说缩放很重要,因为我们不希望任何特征综合地变大或变小。借助以下 Python 代码,我们可以对输入数据(即特征向量)进行缩放 -
# 最小最大缩放
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)
运行上述代码行后,我们将得到以下输出 -
最小最大缩放数据
[ [ 0.48648649 0.58252427 0.99122807] [ 0. 1. 0.81578947] [ 0.27027027 0. 1. ] [ 1. 0. 99029126 0. ]]
正常化
这是另一种用于修改特征向量的数据预处理技术。这种修改对于在通用尺度上测量特征向量是必要的。以下是可用于机器学习的两种类型的标准化 -
L1 归一化
它也称为最小绝对偏差。这种归一化会修改值,以便每行中的绝对值之和始终最大为 1。它可以借助以下 Python 代码在输入数据上实现 -
# Normalize data
data_normalized_l1 = preprocessing.normalize(input_data, norm = 'l1')
print("\nL1 normalized data:\n", data_normalized_l1)
上面的代码行生成以下输出 &miuns;
L1 normalized data: [[ 0.22105263 -0.2 0.57894737] [ -0.2027027 0.32432432 0.47297297] [ 0.03571429 -0.56428571 0.4 ] [ 0.42142857 0.16428571 -0.41428571]]
L2 归一化
它也称为最小二乘法。这种归一化会修改值,以便每行的平方和始终最大为 1。它可以借助以下 Python 代码在输入数据上实现 -
# Normalize data
data_normalized_l2 = preprocessing.normalize(input_data, norm = 'l2')
print("\nL2 normalized data:\n", data_normalized_l2)
上面的代码行将生成以下输出 -
L2 normalized data: [[ 0.33946114 -0.30713151 0.88906489] [ -0.33325106 0.53320169 0.7775858 ] [ 0.05156558 -0.81473612 0.57753446] [ 0.68706914 0.26784051 -0.6754239 ]]
标记数据
我们已经知道,机器学习算法需要某种格式的数据。另一个重要要求是,在将数据作为机器学习算法的输入发送之前,必须对其进行正确标记。例如,如果我们谈论分类,数据上有很多标签。这些标签的形式是单词、数字等。sklearn中与机器学习相关的功能期望数据必须具有数字标签。因此,如果数据是其他形式,则必须将其转换为数字。将单词标签转换为数字形式的过程称为标签编码。
标签编码步骤
按照以下步骤在 Python 中对数据标签进行编码 -
Step1 - 导入有用的包
如果我们使用Python,那么这将是将数据转换为某种格式的第一步,即预处理。可以按如下方式完成 -
import numpy as np from sklearn import preprocessing
步骤 2 - 定义示例标签
导入包后,我们需要定义一些示例标签,以便我们可以创建和训练标签编码器。我们现在将定义以下示例标签 -
# Sample input labels input_labels = ['red','black','red','green','black','yellow','white']
步骤 3 - 创建和训练标签编码器对象
在这一步中,我们需要创建标签编码器并训练它。以下 Python 代码将有助于做到这一点 -
# Creating the label encoder encoder = preprocessing.LabelEncoder() encoder.fit(input_labels)
以下是运行上述 Python 代码后的输出 -
LabelEncoder()
Step4 - 通过编码随机有序列表来检查性能
此步骤可用于通过对随机排序列表进行编码来检查性能。可以编写以下 Python 代码来执行相同的操作 -
# encoding a set of labels
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)
标签将打印如下 -
Labels = ['green', 'red', 'black']
现在,我们可以获得编码值列表,即转换为数字的单词标签,如下所示 -
print("Encoded values =", list(encoded_values))
编码值将打印如下 -
Encoded values = [1, 2, 0]
步骤 5 - 通过解码一组随机数字来检查性能 -
此步骤可用于通过解码随机数字集来检查性能。可以编写以下 Python 代码来执行相同的操作 -
# decoding a set of values
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)
现在,编码值将打印如下 -
Encoded values = [3, 0, 4, 1]
print("\nDecoded labels =", list(decoded_list))
现在,解码后的值将打印如下 -
Decoded labels = ['white', 'black', 'yellow', 'green']
标记数据与未标记数据
未标记数据主要包括可以从世界中轻松获得的自然或人造物体的样本。它们包括音频、视频、照片、新闻文章等。
另一方面,标记数据采用一组未标记数据,并使用一些有意义的标签或标签或类来扩充每条未标记数据。例如,如果我们有一张照片,那么可以根据照片的内容来放置标签,即,它是男孩或女孩或动物或其他任何东西的照片。标记数据需要人类的专业知识或对给定的未标记数据的判断。
在许多场景中,未标记数据丰富且易于获取,但标记数据通常需要人工/专家进行注释。半监督学习尝试结合标记和未标记数据来构建更好的模型。
AI with Python – 监督学习:分类
在本章中,我们将重点关注监督学习的实现——分类。
分类技术或模型试图从观察值中得出一些结论。在分类问题中,我们有分类输出,例如“黑色”或“白色”或“教学”和“非教学”。在构建分类模型时,我们需要包含数据点和相应标签的训练数据集。例如,如果我们想检查图像是否是汽车。为了检查这一点,我们将构建一个训练数据集,其中包含与“汽车”和“无汽车”相关的两个类别。然后我们需要使用训练样本来训练模型。分类模型主要应用于人脸识别、垃圾邮件识别等。
在 Python 中构建分类器的步骤
为了用 Python 构建分类器,我们将使用 Python 3 和 Scikit-learn(一种机器学习工具)。按照以下步骤在 Python 中构建分类器 -
第 1 步 - 导入 Scikit-learn
这将是用 Python 构建分类器的第一步。在此步骤中,我们将安装一个名为 Scikit-learn 的 Python 包,它是 Python 中最好的机器学习模块之一。以下命令将帮助我们导入包 -
Import Sklearn
步骤 2 - 导入 Scikit-learn 的数据集
在此步骤中,我们可以开始使用机器学习模型的数据集。在这里,我们将使用威斯康星州乳腺癌诊断数据库。该数据集包括有关乳腺癌肿瘤的各种信息,以及恶性或良性的分类标签。该数据集包含 569 个肿瘤的 569 个实例或数据,包括 30 个属性或特征的信息,例如肿瘤的半径、纹理、平滑度和面积。借助以下命令,我们可以导入 Scikit-learn 的乳腺癌数据集 -
from sklearn.datasets import load_breast_cancer
现在,以下命令将加载数据集。
data = load_breast_cancer()
以下是重要字典键的列表 -
- 分类标签名称(target_names)
- 实际标签(目标)
- 属性/特征名称(feature_names)
- 属性(数据)
现在,借助以下命令,我们可以为每组重要的信息创建新变量并分配数据。换句话说,我们可以使用以下命令组织数据 -
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']
现在,为了更清楚,我们可以借助以下命令打印类标签、第一个数据实例的标签、特征名称和特征值 -
print(label_names)
上面的命令将分别打印恶性和良性的类名称。其输出如下所示 -
['malignant' 'benign']
现在,下面的命令将显示它们映射到二进制值 0 和 1。这里 0 代表恶性癌症,1 代表良性癌症。您将收到以下输出 -
print(labels[0]) 0
下面给出的两个命令将生成特征名称和特征值。
print(feature_names[0]) mean radius print(features[0]) [ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03 1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01 2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01 8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02 5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03 2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03 1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01 4.60100000e-01 1.18900000e-01]
从上面的输出中,我们可以看到第一个数据实例是一个半径为1.7990000e+01的恶性肿瘤。
步骤 3 - 将数据组织成集合
在这一步中,我们将把数据分为两部分,即训练集和测试集。将数据分成这些组非常重要,因为我们必须在看不见的数据上测试我们的模型。为了将数据分成集合,sklearn 有一个名为train_test_split()函数的函数。借助以下命令,我们可以分割这些集合中的数据 -
from sklearn.model_selection import train_test_split
上面的命令将从 sklearn 导入train_test_split函数,下面的命令将数据拆分为训练数据和测试数据。在下面给出的示例中,我们使用 40% 的数据进行测试,其余数据将用于训练模型。
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
第 4 步 - 构建模型
在这一步中,我们将构建我们的模型。我们将使用朴素贝叶斯算法来构建模型。以下命令可用于构建模型 -
from sklearn.naive_bayes import GaussianNB
上面的命令将导入 GaussianNB 模块。现在,以下命令将帮助您初始化模型。
gnb = GaussianNB()
我们将使用 gnb.fit() 将模型拟合到数据来训练模型。
model = gnb.fit(train, train_labels)
步骤 5 - 评估模型及其准确性
在此步骤中,我们将通过对测试数据进行预测来评估模型。然后我们也会发现它的准确性。为了进行预测,我们将使用 Predict() 函数。以下命令将帮助您执行此操作 -
preds = gnb.predict(test) print(preds) [1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述 0 和 1 系列是肿瘤类别(恶性和良性)的预测值。
现在,通过比较两个数组,即test_labels和preds,我们可以找出模型的准确性。我们将使用precision_score()函数来确定准确性。为此考虑以下命令 -
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965
结果表明,NaïveBayes 分类器的准确率为 95.17%。
这样,借助上述步骤,我们就可以用 Python 构建我们的分类器了。
用 Python 构建分类器
在本节中,我们将学习如何用 Python 构建分类器。
朴素贝叶斯分类器
朴素贝叶斯是一种分类技术,用于使用贝叶斯定理构建分类器。假设预测变量是独立的。简而言之,它假设类中特定功能的存在与任何其他功能的存在无关。为了构建朴素贝叶斯分类器,我们需要使用名为 scikit learn 的 python 库。scikit learn 包下有三种类型的朴素贝叶斯模型:高斯模型、多项式模型和伯努利模型。
要构建朴素贝叶斯机器学习分类器模型,我们需要以下 &minus
数据集
我们将使用名为威斯康星州乳腺癌诊断数据库的数据集。该数据集包括有关乳腺癌肿瘤的各种信息,以及恶性或良性的分类标签。该数据集包含 569 个肿瘤的 569 个实例或数据,包括 30 个属性或特征的信息,例如肿瘤的半径、纹理、平滑度和面积。我们可以从 sklearn 包导入这个数据集。
朴素贝叶斯模型
为了构建朴素贝叶斯分类器,我们需要一个朴素贝叶斯模型。如前所述,scikit learn 包下有三种类型的朴素贝叶斯模型,分别为高斯模型、多项式模型和伯努利模型。在下面的示例中,我们将使用高斯朴素贝叶斯模型。
通过以上内容,我们将建立一个朴素贝叶斯机器学习模型,利用肿瘤信息来预测肿瘤是恶性还是良性。
首先,我们需要安装 sklearn 模块。可以借助以下命令来完成 -
Import Sklearn
现在,我们需要导入名为“乳腺癌威斯康星州诊断数据库”的数据集。
from sklearn.datasets import load_breast_cancer
现在,以下命令将加载数据集。
data = load_breast_cancer()
数据可以组织如下 -
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']
现在,为了更清楚,我们可以借助以下命令打印类标签、第一个数据实例的标签、特征名称和特征值 -
print(label_names)
上面的命令将分别打印恶性和良性的类名称。其输出如下所示 -
['malignant' 'benign']
现在,下面给出的命令将显示它们映射到二进制值 0 和 1。这里 0 代表恶性癌症,1 代表良性癌症。其输出如下所示 -
print(labels[0]) 0
以下两个命令将生成特征名称和特征值。
print(feature_names[0]) mean radius print(features[0]) [ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03 1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01 2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01 8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02 5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03 2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03 1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01 4.60100000e-01 1.18900000e-01]
从上面的输出中,我们可以看到第一个数据实例是一个恶性肿瘤,其主半径为1.7990000e+01。
为了在看不见的数据上测试我们的模型,我们需要将数据分为训练数据和测试数据。可以借助以下代码来完成 -
from sklearn.model_selection import train_test_split
上面的命令将从 sklearn 导入train_test_split函数,下面的命令将数据拆分为训练数据和测试数据。在下面的示例中,我们使用 40% 的数据进行测试,重新挖掘的数据将用于训练模型。
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
现在,我们使用以下命令构建模型 -
from sklearn.naive_bayes import GaussianNB
上面的命令将导入GaussianNB模块。现在,使用下面给出的命令,我们需要初始化模型。
gnb = GaussianNB()
我们将使用gnb.fit()将模型拟合到数据来训练模型。
model = gnb.fit(train, train_labels)
现在,通过对测试数据进行预测来评估模型,可以按如下方式完成 -
preds = gnb.predict(test) print(preds) [1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述 0 和 1 系列是肿瘤类别(即恶性和良性)的预测值。
现在,通过比较两个数组test_labels和preds,我们可以找出