- Keras 深度学习教程
- 使用 Keras 进行深度学习 - 主页
- 使用 Keras 进行深度学习 - 简介
- 深度学习
- 设置项目
- 导入库
- 创建深度学习模型
- 编译模型
- 准备数据
- 训练模型
- 评估模型性能
- 根据测试数据进行预测
- 节约模型
- 加载预测模型
- 结论
- 使用 Keras 资源进行深度学习
- 使用 Keras 进行深度学习 - 快速指南
- 使用 Keras 进行深度学习 - 有用的资源
- 使用 Keras 进行深度学习 - 讨论
评估模型性能
为了评估模型性能,我们调用评估方法如下 -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
为了评估模型性能,我们调用评估方法如下 -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
我们将使用以下两个语句打印损失和准确性 -
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])
当您运行上述语句时,您将看到以下输出 -
Test Loss 0.08041584826191042 Test Accuracy 0.9837
这表明测试准确率为 98%,这应该是我们可以接受的。在 2% 的情况下,手写数字无法被正确分类,这对我们意味着什么。我们还将绘制准确性和损失指标,以了解模型在测试数据上的表现。
绘制准确度指标
我们在训练期间使用记录的历史来获取准确度指标图。以下代码将绘制每个时期的准确性。我们选取训练数据准确性(“acc”)和验证数据准确性(“val_acc”)进行绘图。
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')
输出图如下所示 -
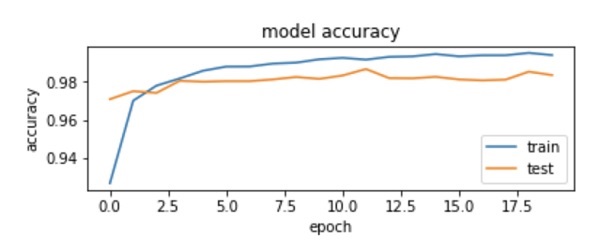
如图所示,前两个 epoch 的准确率迅速提高,表明网络学习速度很快。之后,曲线变平,表明不需要太多的时期来进一步训练模型。一般来说,如果训练数据准确性(“acc”)不断提高,而验证数据准确性(“val_acc”)变得更差,则您会遇到过度拟合。这表明模型开始记忆数据。
我们还将绘制损失指标来检查模型的性能。
绘制损失指标
我们再次在训练(“loss”)和测试(“val_loss”)数据上绘制损失。这是使用以下代码完成的 -
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')
该代码的输出如下所示 -
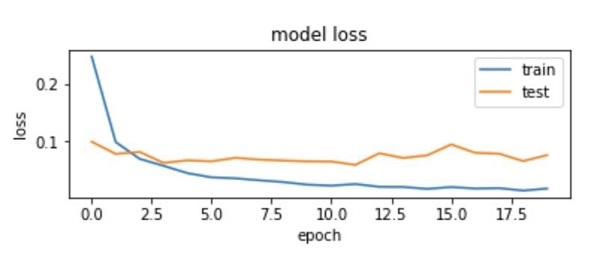
正如您在图中所看到的,前两个时期训练集上的损失迅速下降。对于测试集,损失不会以与训练集相同的速度下降,但在多个时期内几乎保持平坦。这意味着我们的模型可以很好地推广到未见过的数据。
现在,我们将使用经过训练的模型来预测测试数据中的数字。