- Keras 深度学习教程
- 使用 Keras 进行深度学习 - 主页
- 使用 Keras 进行深度学习 - 简介
- 深度学习
- 设置项目
- 导入库
- 创建深度学习模型
- 编译模型
- 准备数据
- 训练模型
- 评估模型性能
- 根据测试数据进行预测
- 节约模型
- 加载预测模型
- 结论
- 使用 Keras 资源进行深度学习
- 使用 Keras 进行深度学习 - 快速指南
- 使用 Keras 进行深度学习 - 有用的资源
- 使用 Keras 进行深度学习 - 讨论
使用 Keras 进行深度学习 - 准备数据
在我们将数据输入网络之前,必须将其转换为网络所需的格式。这称为为网络准备数据。它通常包括将多维输入转换为一维向量并对数据点进行归一化。
重塑输入向量
我们数据集中的图像由 28 x 28 像素组成。必须将其转换为大小为 28 * 28 = 784 的单维向量,才能将其输入到我们的网络中。我们通过调用向量的reshape方法来实现这一点。
X_train = X_train.reshape(60000, 784) X_test = X_test.reshape(10000, 784)
现在,我们的训练向量将由 60000 个数据点组成,每个数据点由大小为 784 的单维向量组成。同样,我们的测试向量将由大小为 784 的单维向量的 10000 个数据点组成。
标准化数据
输入向量包含的数据当前具有 0 到 255 之间的离散值(灰度级)。将这些像素值标准化在 0 到 1 之间有助于加快训练速度。由于我们将使用随机梯度下降,标准化数据也将有助于减少陷入局部最优的机会。
为了标准化数据,我们将其表示为 float 类型并将其除以 255,如以下代码片段所示 -
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
现在让我们看看标准化数据是什么样子的。
检查标准化数据
要查看标准化数据,我们将调用直方图函数,如下所示 -
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))
在这里,我们绘制X_train向量第一个元素的直方图。我们还打印该数据点代表的数字。运行上述代码的输出如下所示 -
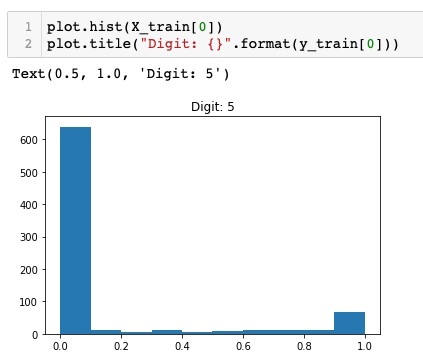
您会注意到值接近于零的点的密集密度。这些是图像中的黑点,显然是图像的主要部分。其余接近白色的灰度点代表数字。您可以检查另一个数字的像素分布。下面的代码打印训练数据集中索引为 2 处的数字的直方图。
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])
运行上述代码的输出如下所示 -
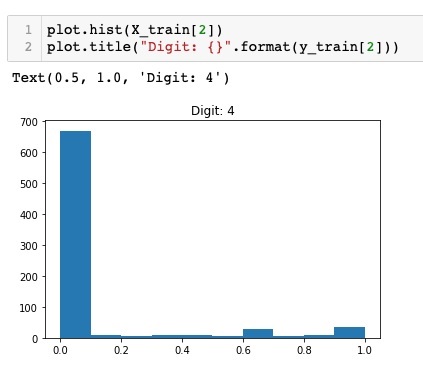
比较上面两张图,你会发现两张图片中白色像素的分布不同,这表明上面两张图片中的“5”和“4”代表了不同的数字。
接下来,我们将检查完整训练数据集中的数据分布。
检查数据分布
在我们在数据集上训练机器学习模型之前,我们应该知道数据集中唯一数字的分布。我们的图像代表 10 个不同的数字,范围从 0 到 9。我们想知道数据集中数字 0、1 等的数量。我们可以使用Numpy独特的方法来获取这些信息。
使用以下命令打印唯一值的数量以及每个值出现的次数
print(np.unique(y_train, return_counts=True))
当您运行上述命令时,您将看到以下输出 -
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))
它显示有 10 个不同的值 - 0 到 9。数字 0 出现 5923 次,数字 1 出现 6742 次,依此类推。输出的屏幕截图如下所示 -

作为数据准备的最后一步,我们需要对数据进行编码。
编码数据
我们的数据集中有十个类别。因此,我们将使用 one-hot 编码将我们的输出编码为这十个类别。我们使用 Numpy 实用程序的 to_categorial 方法来执行编码。输出数据编码后,每个数据点将转换为大小为 10 的单维向量。例如,数字 5 现在将表示为 [0,0,0,0,0,1,0,0,0 ,0]。
使用以下代码对数据进行编码 -
n_classes = 10 Y_train = np_utils.to_categorical(y_train, n_classes)
您可以通过打印分类 Y_train 向量的前 5 个元素来检查编码结果。
使用以下代码打印前 5 个向量 -
for i in range(5): print (Y_train[i])
您将看到以下输出 -
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
第一个元素代表数字 5,第二个元素代表数字 0,依此类推。
最后,您还必须对测试数据进行分类,这是使用以下语句完成的 -
Y_test = np_utils.to_categorical(y_test, n_classes)
在此阶段,您的数据已完全准备好输入网络。
接下来是最重要的部分,那就是训练我们的网络模型。