- Keras 深度学习教程
- 使用 Keras 进行深度学习 - 主页
- 使用 Keras 进行深度学习 - 简介
- 深度学习
- 设置项目
- 导入库
- 创建深度学习模型
- 编译模型
- 准备数据
- 训练模型
- 评估模型性能
- 根据测试数据进行预测
- 节约模型
- 加载预测模型
- 结论
- 使用 Keras 资源进行深度学习
- 使用 Keras 进行深度学习 - 快速指南
- 使用 Keras 进行深度学习 - 有用的资源
- 使用 Keras 进行深度学习 - 讨论
使用 Keras 进行深度学习 - 快速指南
使用 Keras 进行深度学习 - 简介
深度学习近来已成为人工智能(AI)领域的流行词。多年来,我们使用机器学习 (ML) 来向机器传授智能。近年来,深度学习由于其与传统机器学习技术相比在预测方面的优势而变得更加流行。
深度学习本质上意味着用大量数据训练人工神经网络(ANN)。在深度学习中,网络自行学习,因此需要大量数据进行学习。而传统的机器学习本质上是一组解析数据并从中学习的算法。然后他们利用这种学习来做出明智的决策。
现在,Keras 是一个在 TensorFlow(端到端开源机器学习平台)之上运行的高级神经网络 API。使用 Keras,您可以轻松定义复杂的 ANN 架构来对大数据进行实验。Keras 还支持 GPU,这对于处理大量数据和开发机器学习模型至关重要。
在本教程中,您将学习如何使用 Keras 构建深度神经网络。我们将看看教学的实际例子。当前的问题是使用经过深度学习训练的神经网络来识别手写数字。
为了让您对深度学习更加兴奋,下面是谷歌深度学习趋势的屏幕截图 -
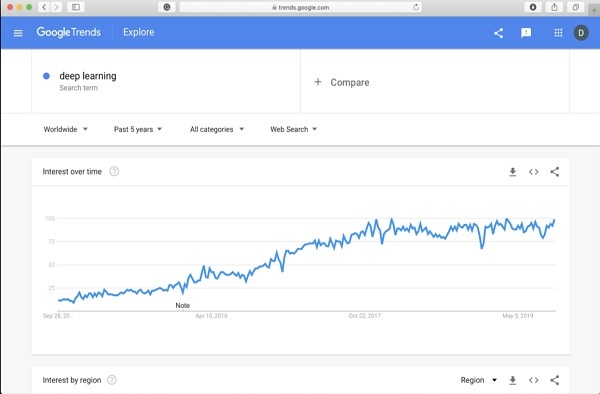
从图中可以看出,过去几年人们对深度学习的兴趣正在稳步增长。深度学习在计算机视觉、自然语言处理、语音识别、生物信息学、药物设计等许多领域都得到了成功的应用。本教程将帮助您快速开始深度学习。
所以继续阅读吧!
使用 Keras 进行深度学习 - 深度学习
正如引言中所说,深度学习是用大量数据训练人工神经网络的过程。经过训练后,网络将能够为我们提供对未见数据的预测。在进一步解释什么是深度学习之前,让我们快速浏览一下训练神经网络时使用的一些术语。
神经网络
人工神经网络的想法源自我们大脑中的神经网络。典型的神经网络由三层组成——输入层、输出层和隐藏层,如下图所示。
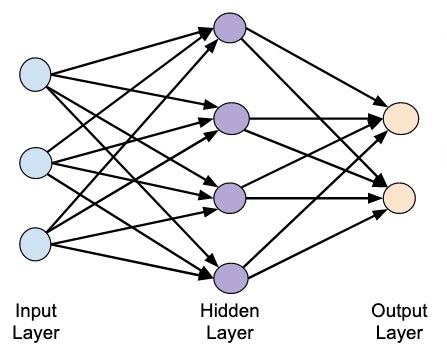
这也称为浅层神经网络,因为它仅包含一个隐藏层。您可以在上述架构中添加更多隐藏层以创建更复杂的架构。
深度网络
下图显示了一个由四个隐藏层、一个输入层和一个输出层组成的深度网络。
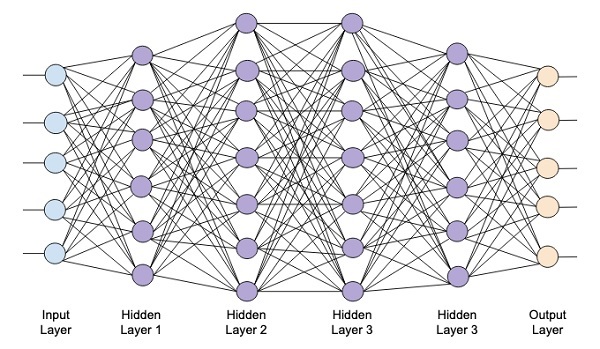
随着网络中隐藏层数量的增加,其训练在所需资源和完全训练网络所需的时间方面变得更加复杂。
网络培训
定义网络架构后,您可以训练它进行某些类型的预测。训练网络是为网络中每个链接找到适当权重的过程。在训练期间,数据通过各个隐藏层从输入层流向输出层。由于数据总是从输入到输出沿一个方向移动,因此我们将该网络称为前馈网络,并将数据传播称为前向传播。
激活函数
在每一层,我们计算输入的加权和并将其输入激活函数。激活函数给网络带来了非线性。它只是一些离散化输出的数学函数。一些最常用的激活函数是 sigmoid、双曲、正切 (tanh)、ReLU 和 Softmax。
反向传播
反向传播是一种监督学习算法。在反向传播中,误差从输出向后传播到输入层。给定一个误差函数,我们计算误差函数相对于每个连接分配的权重的梯度。梯度的计算通过网络向后进行。先计算最后一层权重的梯度,最后计算第一层权重的梯度。
在每一层,梯度的部分计算在前一层的梯度计算中被重用。这称为梯度下降。
在这个基于项目的教程中,您将定义一个前馈深度神经网络,并使用反向传播和梯度下降技术对其进行训练。幸运的是,Keras 为我们提供了所有高级 API,用于定义网络架构并使用梯度下降对其进行训练。接下来,您将学习如何在 Keras 中执行此操作。
手写数字识别系统
在此小型项目中,您将应用前面描述的技术。您将创建一个深度学习神经网络,该网络将接受训练以识别手写数字。在任何机器学习项目中,第一个挑战是收集数据。特别是对于深度学习网络,您需要大量数据。幸运的是,对于我们正在尝试解决的问题,有人已经创建了一个用于训练的数据集。这称为 mnist,它作为 Keras 库的一部分提供。该数据集由多个 28x28 像素的手写数字图像组成。您将在此数据集的主要部分上训练您的模型,其余数据将用于验证您训练的模型。
项目介绍
mnist数据集由 70000 张手写数字图像组成。这里复制了一些示例图像供您参考

每个图像的大小为 28 x 28 像素,总共有 768 个不同灰度级别的像素。大多数像素趋向于黑色阴影,而只有少数像素趋于白色。我们将把这些像素的分布放在一个数组或一个向量中。例如,数字4和5的典型图像的像素分布如下图所示。
每个图像的大小为 28 x 28 像素,总共有 768 个不同灰度级别的像素。大多数像素趋向于黑色阴影,而只有少数像素趋于白色。我们将把这些像素的分布放在一个数组或一个向量中。例如,数字4和5的典型图像的像素分布如下图所示。
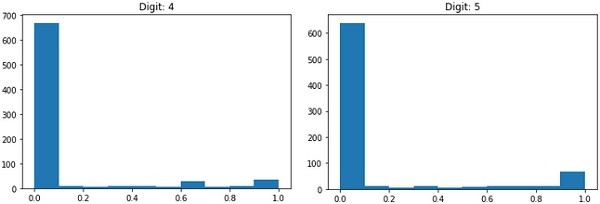
显然,您可以看到像素的分布(尤其是那些趋于白色调的像素)不同,这可以区分它们代表的数字。我们会将这个 784 像素的分布提供给我们的网络作为其输入。网络的输出将包含 10 个类别,代表 0 到 9 之间的数字。
我们的网络将由 4 层组成——一个输入层、一个输出层和两个隐藏层。每个隐藏层将包含 512 个节点。每一层都完全连接到下一层。当我们训练网络时,我们将计算每个连接的权重。我们通过应用前面讨论的反向传播和梯度下降来训练网络。
使用 Keras 进行深度学习 - 设置项目
有了这个背景,现在让我们开始创建项目。
设置项目
我们将通过Anaconda导航器在我们的项目中使用Jupyter。由于我们的项目使用 TensorFlow 和 Keras,因此您需要在 Anaconda 设置中安装它们。要安装 Tensorflow,请在控制台窗口中运行以下命令:
>conda install -c anaconda tensorflow
要安装 Keras,请使用以下命令 -
>conda install -c anaconda keras
您现在已准备好启动 Jupyter。
启动 Jupyter
当您启动 Anaconda 导航器时,您将看到以下打开屏幕。
单击“Jupyter”启动它。屏幕将显示驱动器上的现有项目(如果有)。
开始一个新项目
通过选择以下菜单选项在 Anaconda 中启动一个新的 Python 3 项目 -
File | New Notebook | Python 3
显示菜单选择的屏幕截图供您快速参考 -
一个新的空白项目将显示在您的屏幕上,如下所示 -
通过单击并编辑默认名称“UntitledXX”,将项目名称更改为DeepLearningDigitRecognition。
使用 Keras 进行深度学习 - 导入库
我们首先导入我们项目中代码所需的各种库。
数组处理和绘图
通常,我们使用numpy进行数组处理,使用matplotlib进行绘图。使用以下导入语句将这些库导入到我们的项目中
import numpy as np import matplotlib import matplotlib.pyplot as plot
抑制警告
由于 Tensorflow 和 Keras 都在不断修改,如果您没有在项目中同步它们的适当版本,在运行时您会看到大量警告错误。由于它们会分散您学习的注意力,因此我们将取消该项目中的所有警告。这是通过以下代码行完成的 -
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = False
喀拉斯
我们使用 Keras 库导入数据集。我们将使用mnist数据集来处理手写数字。我们使用以下语句导入所需的包
from keras.datasets import mnist
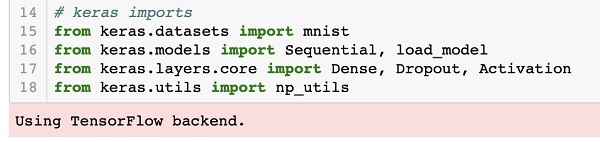
我们将使用 Keras 包定义深度学习神经网络。我们导入Sequential、Dense、Dropout和Activation包来定义网络架构。我们使用load_model包来保存和检索我们的模型。我们还使用np_utils来实现项目中需要的一些实用程序。这些导入是通过以下程序语句完成的 -
from keras.models import Sequential, load_model from keras.layers.core import Dense, Dropout, Activation from keras.utils import np_utils
当您运行此代码时,您将在控制台上看到一条消息,指出 Keras 在后端使用 TensorFlow。此阶段的屏幕截图如下所示 -
现在,由于我们拥有项目所需的所有导入,我们将继续定义深度学习网络的架构。
创建深度学习模型
我们的神经网络模型将由线性堆栈组成。为了定义这样的模型,我们调用Sequential函数 -
model = Sequential()
输入层
我们使用以下程序语句定义输入层,这是我们网络中的第一层 -
model.add(Dense(512, input_shape=(784,)))
这将创建一个包含 512 个节点(神经元)和 784 个输入节点的层。如下图所示 -
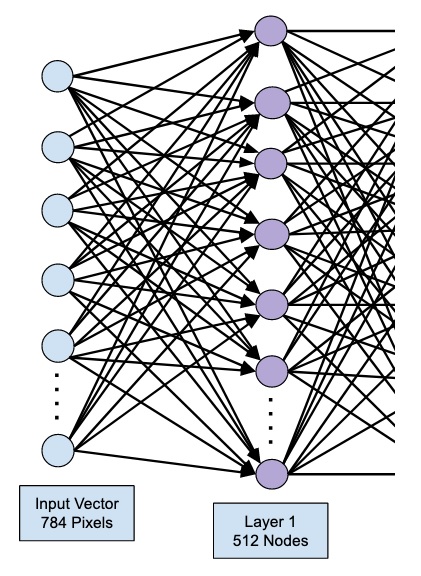
请注意,所有输入节点都完全连接到第 1 层,即每个输入节点都连接到第 1 层的所有 512 个节点。
接下来,我们需要为第 1 层的输出添加激活函数。我们将使用 ReLU 作为激活函数。使用以下程序语句添加激活函数 -
model.add(Activation('relu'))
接下来,我们使用以下语句添加 20% 的 Dropout。Dropout 是一种用于防止模型过度拟合的技术。
model.add(Dropout(0.2))
至此,我们的输入层已完全定义。接下来,我们将添加一个隐藏层。
隐藏层
我们的隐藏层将由 512 个节点组成。隐藏层的输入来自我们之前定义的输入层。所有节点都像之前的情况一样完全连接。隐藏层的输出将进入网络中的下一层,这将是我们的最终层和输出层。我们将使用与前一层相同的 ReLU 激活和 20% 的 dropout。添加该层的代码如下 -
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
此阶段的网络可以可视化如下 -
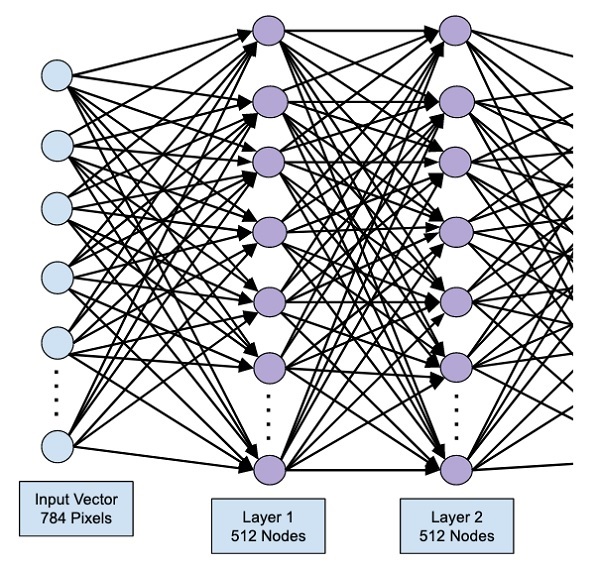
接下来,我们将最后一层添加到网络中,即输出层。请注意,您可以使用与此处使用的代码类似的代码添加任意数量的隐藏层。添加更多层会使网络训练变得复杂;然而,在许多情况下(但不是全部),提供更好结果的明确优势。
输出层
输出层仅包含 10 个节点,因为我们希望将给定图像分类为 10 个不同的数字。我们使用以下语句添加这一层 -
model.add(Dense(10))
由于我们想要将输出分类为 10 个不同的单元,因此我们使用 softmax 激活。对于 ReLU,输出是二进制的。我们使用以下语句添加激活 -
model.add(Activation('softmax'))
此时,我们的网络可以如下图所示可视化 -
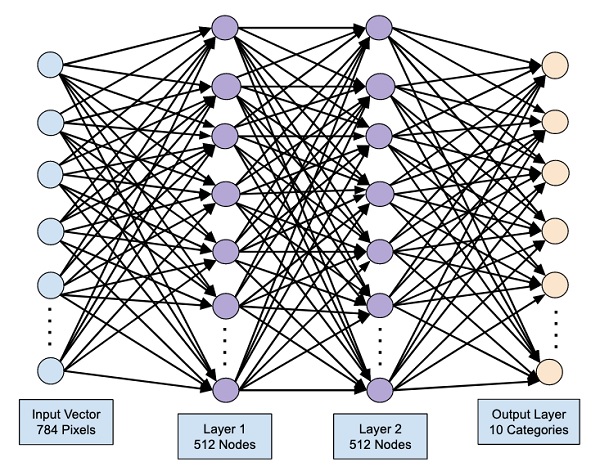
至此,我们的网络模型已在软件中完全定义。运行代码单元,如果没有错误,您将在屏幕上收到一条确认消息,如下面的屏幕截图所示 -

接下来,我们需要编译模型。
使用 Keras 进行深度学习 - 编译模型
编译是使用一个名为compile的方法调用来执行的。
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
编译方法需要几个参数。损失参数被指定为类型'categorical_crossentropy'。指标参数设置为“准确度”,最后我们使用adam优化器来训练网络。此阶段的输出如下所示 -

现在,我们准备将数据输入到我们的网络中。
加载数据中
如前所述,我们将使用Keras 提供的mnist数据集。当我们将数据加载到系统中时,我们会将其分为训练数据和测试数据。通过调用load_data方法加载数据,如下所示 -
(X_train, y_train), (X_test, y_test) = mnist.load_data()
此阶段的输出如下所示 -

现在,我们将了解加载的数据集的结构。
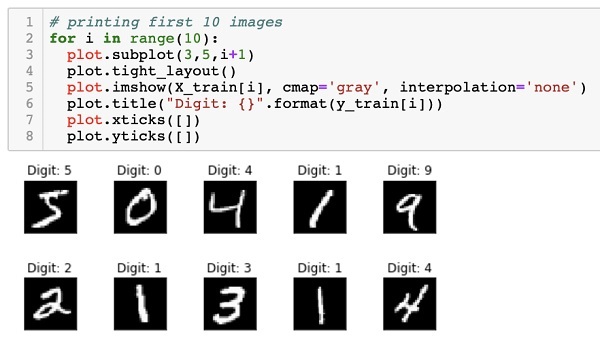
提供给我们的数据是大小为 28 x 28 像素的图形图像,每个图像包含 0 到 9 之间的单个数字。我们将在控制台上显示前十个图像。这样做的代码如下 -
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])
在 10 次计数的迭代循环中,我们在每次迭代时创建一个子图,并在其中显示来自X_train向量的图像。我们从相应的y_train向量中为每个图像添加标题。请注意,y_train向量包含X_train向量中对应图像的实际值。我们通过使用 null 参数调用xticks和yticks两个方法来删除 x 和 y 轴标记。当您运行代码时,您将看到以下输出 -
接下来,我们将准备数据以将其输入到我们的网络中。
使用 Keras 进行深度学习 - 准备数据
在我们将数据输入网络之前,必须将其转换为网络所需的格式。这称为为网络准备数据。它通常包括将多维输入转换为一维向量并对数据点进行归一化。
重塑输入向量
我们数据集中的图像由 28 x 28 像素组成。必须将其转换为大小为 28 * 28 = 784 的单维向量,才能将其输入到我们的网络中。我们通过调用向量的reshape方法来实现这一点。
X_train = X_train.reshape(60000, 784) X_test = X_test.reshape(10000, 784)
现在,我们的训练向量将由 60000 个数据点组成,每个数据点由大小为 784 的单维向量组成。同样,我们的测试向量将由大小为 784 的单维向量的 10000 个数据点组成。
标准化数据
输入向量包含的数据当前具有 0 到 255 之间的离散值(灰度级)。将这些像素值标准化在 0 到 1 之间有助于加快训练速度。由于我们将使用随机梯度下降,标准化数据也将有助于减少陷入局部最优的机会。
为了标准化数据,我们将其表示为 float 类型并将其除以 255,如以下代码片段所示 -
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
现在让我们看看标准化数据是什么样子的。
检查标准化数据
要查看标准化数据,我们将调用直方图函数,如下所示 -
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))
在这里,我们绘制X_train向量第一个元素的直方图。我们还打印该数据点代表的数字。运行上述代码的输出如下所示 -
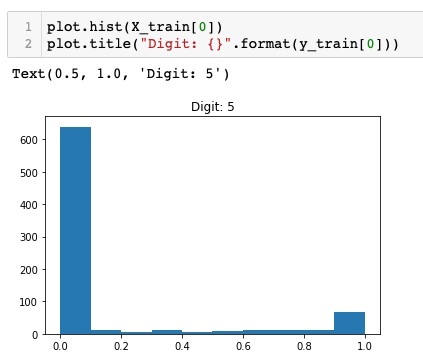
您会注意到值接近于零的点的密集密度。这些是图像中的黑点,显然是图像的主要部分。其余接近白色的灰度点代表数字。您可以检查另一个数字的像素分布。下面的代码打印训练数据集中索引为 2 处的数字的直方图。
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])
运行上述代码的输出如下所示 -
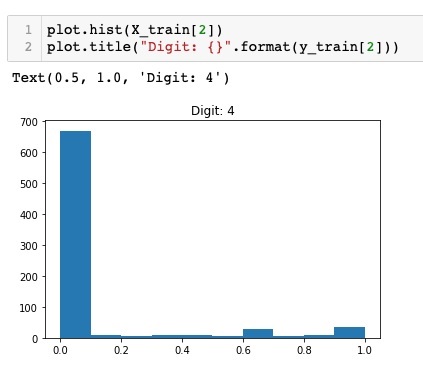
比较上面两张图,你会发现两张图片中白色像素的分布不同,这表明上面两张图片中的“5”和“4”代表了不同的数字。
接下来,我们将检查完整训练数据集中的数据分布。
检查数据分布
在我们在数据集上训练机器学习模型之前,我们应该知道数据集中唯一数字的分布。我们的图像代表 10 个不同的数字,范围从 0 到 9。我们想知道数据集中数字 0、1 等的数量。我们可以使用Numpy独特的方法来获取这些信息。
使用以下命令打印唯一值的数量以及每个值出现的次数
print(np.unique(y_train, return_counts=True))
当您运行上述命令时,您将看到以下输出 -
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))
它显示有 10 个不同的值 - 0 到 9。数字 0 出现 5923 次,数字 1 出现 6742 次,依此类推。输出的屏幕截图如下所示 -

作为数据准备的最后一步,我们需要对数据进行编码。
编码数据
我们的数据集中有十个类别。因此,我们将使用 one-hot 编码将我们的输出编码为这十个类别。我们使用 Numpy 实用程序的 to_categorial 方法来执行编码。输出数据编码后,每个数据点将转换为大小为 10 的单维向量。例如,数字 5 现在将表示为 [0,0,0,0,0,1,0,0,0 ,0]。
使用以下代码对数据进行编码 -
n_classes = 10 Y_train = np_utils.to_categorical(y_train, n_classes)
您可以通过打印分类 Y_train 向量的前 5 个元素来检查编码结果。
使用以下代码打印前 5 个向量 -
for i in range(5): print (Y_train[i])
您将看到以下输出 -
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
第一个元素代表数字 5,第二个元素代表数字 0,依此类推。
最后,您还必须对测试数据进行分类,这是使用以下语句完成的 -
Y_test = np_utils.to_categorical(y_test, n_classes)
在此阶段,您的数据已完全准备好输入网络。
接下来是最重要的部分,那就是训练我们的网络模型。
使用 Keras 进行深度学习 - 训练模型
模型训练是在一个名为 fit 的方法调用中完成的,该方法需要很少的参数,如下面的代码所示 -
history = model.fit(X_train, Y_train, batch_size=128, epochs=20, verbose=2, validation_data=(X_test, Y_test)))
fit 方法的前两个参数指定训练数据集的特征和输出。
epochs设置为 20 ;我们假设训练将在最多 20 个 epoch(迭代)内收敛。训练后的模型根据最后一个参数中指定的测试数据进行验证。
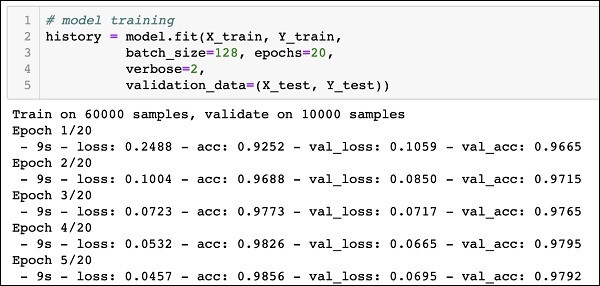
运行上述命令的部分输出如下所示 -
Train on 60000 samples, validate on 10000 samples Epoch 1/20 - 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665 Epoch 2/20 - 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715 Epoch 3/20 - 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765 Epoch 4/20 - 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795 Epoch 5/20 - 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792
下面给出了输出的屏幕截图,供您快速参考 -
现在,当模型根据我们的训练数据进行训练时,我们将评估其性能。
评估模型性能
为了评估模型性能,我们调用评估方法如下 -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
为了评估模型性能,我们调用评估方法如下 -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
我们将使用以下两个语句打印损失和准确性 -
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])
当您运行上述语句时,您将看到以下输出 -
Test Loss 0.08041584826191042 Test Accuracy 0.9837
这表明测试准确率为 98%,这应该是我们可以接受的。在 2% 的情况下,手写数字无法被正确分类,这对我们意味着什么。我们还将绘制准确性和损失指标,以了解模型在测试数据上的表现。
绘制准确度指标
我们在训练期间使用记录的历史来获取准确度指标图。以下代码将绘制每个时期的准确性。我们选取训练数据准确性(“acc”)和验证数据准确性(“val_acc”)进行绘图。
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')
输出图如下所示 -
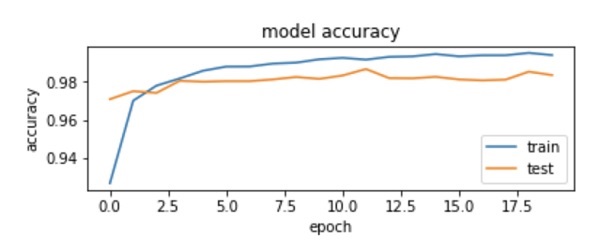
如图所示,前两个 epoch 的准确率迅速提高,表明网络学习速度很快。之后,曲线变平,表明不需要太多的时期来进一步训练模型。一般来说,如果训练数据准确性(“acc”)不断提高,而验证数据准确性(“val_acc”)变得更差,则您会遇到过度拟合。这表明模型开始记忆数据。
我们还将绘制损失指标来检查模型的性能。
绘制损失指标
我们再次在训练(“loss”)和测试(“val_loss”)数据上绘制损失。这是使用以下代码完成的 -
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')
该代码的输出如下所示 -
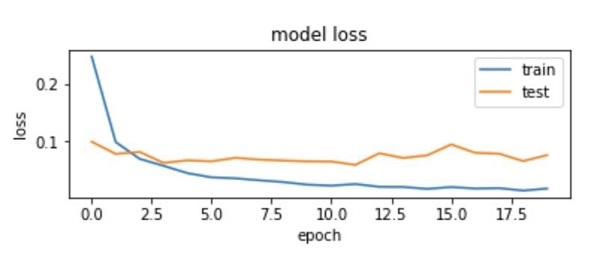
正如您在图中所看到的,前两个时期训练集上的损失迅速下降。对于测试集,损失不会以与训练集相同的速度下降,但在多个时期内几乎保持平坦。这意味着我们的模型可以很好地推广到未见过的数据。
现在,我们将使用经过训练的模型来预测测试数据中的数字。
根据测试数据进行预测
预测看不见的数据中的数字非常容易。您只需将模型传递给由未知数据点组成的向量来调用模型的Predict_classes方法即可。
predictions = model.predict_classes(X_test)
该方法调用返回向量中的预测,可以根据实际值测试 0 和 1。这是使用以下两个语句完成的 -
correct_predictions = np.nonzero(predictions == y_test)[0] incorrect_predictions = np.nonzero(predictions != y_test)[0]
最后,我们将使用以下两个程序语句打印正确和错误预测的计数 -
print(len(correct_predictions)," classified correctly") print(len(incorrect_predictions)," classified incorrectly")
当您运行代码时,您将得到以下输出 -
9837 classified correctly 163 classified incorrectly
现在,由于您已经满意地训练了模型,我们将保存它以供将来使用。
使用 Keras 进行深度学习 - 保存模型
我们将训练后的模型保存在本地驱动器中当前工作目录的 models 文件夹中。要保存模型,请运行以下代码 -
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)
运行代码后的输出如下所示 -

现在,由于您已经保存了经过训练的模型,因此您可以稍后使用它来处理未知数据。
加载预测模型
要预测看不见的数据,首先需要将训练好的模型加载到内存中。这是使用以下命令完成的 -
model = load_model ('./models/handwrittendigitrecognition.h5')
请注意,我们只是将 .h5 文件加载到内存中。这会在内存中设置整个神经网络以及分配给每一层的权重。
现在,要对看不见的数据进行预测,请将数据(将其作为一项或多项)加载到内存中。预处理数据以满足我们模型的输入要求,就像您对上面的训练和测试数据所做的那样。预处理后,将其馈送到您的网络。该模型将输出其预测。
使用 Keras 进行深度学习 - 结论
Keras 提供了用于创建深度神经网络的高级 API。在本教程中,您学习了如何创建一个深度神经网络,该网络经过训练以查找手写文本中的数字。为此目的创建了多层网络。Keras 允许您在每一层定义您选择的激活函数。使用梯度下降,根据训练数据对网络进行训练。在测试数据上测试了训练后的网络预测未见数据的准确性。您学会了绘制准确性和错误指标。网络完全训练完毕后,您保存网络模型以供将来使用。