- Kibana 教程
- Kibana - 主页
- Kibana - 概述
- Kibana - 环境设置
- Kibana - Elk Stack 简介
- Kibana - 加载示例数据
- Kibana - 管理
- Kibana - 发现
- Kibana - 聚合和指标
- Kibana - 创建可视化
- Kibana - 使用图表
- Kibana - 使用图表
- Kibana - 使用热图
- 使用坐标图
- Kibana - 使用区域地图
- 使用规范和目标
- Kibana - 使用画布
- Kibana - 创建仪表板
- Kibana - 泰美狮
- Kibana - 开发工具
- Kibana - 监控
- 使用 Kibana 创建报告
- Kibana 有用资源
- Kibana - 快速指南
- Kibana - 有用的资源
- Kibana - 讨论
Kibana - 聚合和指标
在学习 Kibana 的过程中经常遇到的两个术语是 Bucket 和 Metrics Aggregation。本章讨论它们在 Kibana 中扮演的角色以及有关它们的更多详细信息。
什么是 Kibana 聚合?
聚合是指从特定搜索查询或过滤器获得的文档或一组文档的集合。聚合构成了在 Kibana 中构建所需可视化的主要概念。
每当执行任何可视化时,您都需要决定标准,这意味着您希望以哪种方式对数据进行分组以对其执行指标。
在本节中,我们将讨论两种类型的聚合 -
- 桶聚合
- 指标聚合
桶聚合
一个Bucket主要由一个Key和一个Document组成。当执行聚合时,文档被放置在各自的存储桶中。所以最后你应该有一个存储桶列表,每个存储桶都有一个文档列表。在 Kibana 中创建可视化时您将看到的存储桶聚合列表如下所示 -
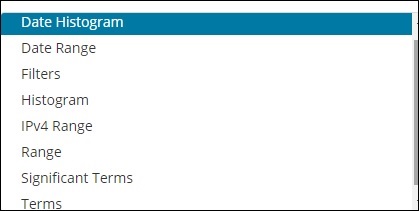
桶聚合有以下列表 -
- 日期直方图
- 日期范围
- 过滤器
- 直方图
- IPv4 范围
- 范围
- 重要条款
- 条款
创建时,您需要选择其中之一进行桶聚合,即对桶内的文档进行分组。
作为示例,为了进行分析,请考虑我们在本教程开始时上传的国家/地区数据。国家索引中可用的字段为国家名称、面积、人口、地区。在国家数据中,我们有国家名称及其人口、地区和面积。
让我们假设我们想要区域明智的数据。然后,每个区域中可用的国家/地区将成为我们的搜索查询,因此在这种情况下,该区域将构成我们的存储桶。下面的框图显示 R1、R2、R3、R4、R5 和 R6 是我们获得的存储桶,而 c1 、 c2 ..c25 是作为存储桶 R1 到 R6 一部分的文档列表。
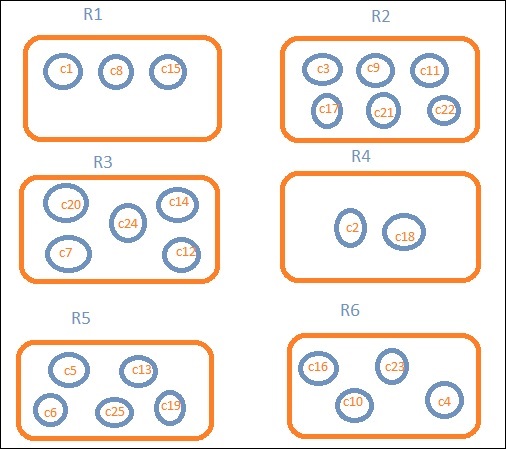
我们可以看到每个桶里都有一些圆圈。它们是基于搜索条件的文档集,并被认为属于每个桶中。在桶 R1 中,我们有文档 c1、c8 和 c15。这些文件是属于该地区的国家,其他国家也是如此。因此,如果我们计算桶 R1 中的国家/地区,则为 3、R2 为 6、R3 为 6、R4 为 2、R5 为 5、R6 为 4。
因此,通过桶聚合,我们可以将文档聚合到桶中,并得到这些桶中的文档列表,如上所示。
到目前为止,我们拥有的桶聚合列表是 -
- 日期直方图
- 日期范围
- 过滤器
- 直方图
- IPv4 范围
- 范围
- 重要条款
- 条款
现在让我们详细讨论如何一一详细地形成这些桶。
日期直方图
日期直方图聚合用于日期字段。因此,您用于可视化的索引,如果该索引中有日期字段,则只能使用此聚合类型。这是一种多存储桶聚合,这意味着您可以将某些文档作为多个存储桶的一部分。此聚合有一个间隔,详细信息如下所示 -
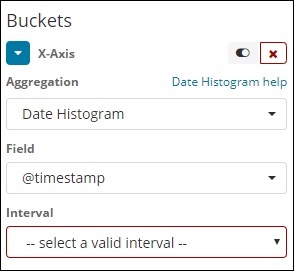
当您选择存储桶聚合作为日期直方图时,它将显示“字段”选项,该选项仅提供与日期相关的字段。选择字段后,您需要选择具有以下详细信息的间隔 -
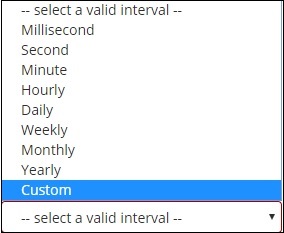
因此,来自所选索引并基于所选字段和间隔的文档将对存储桶中的文档进行分类。例如,如果您选择的时间间隔为每月,则基于日期的文档将被转换为存储桶,并且基于月份(即一月至十二月)的文档将被放入存储桶中。这里一月、二月、..十二月将是桶。
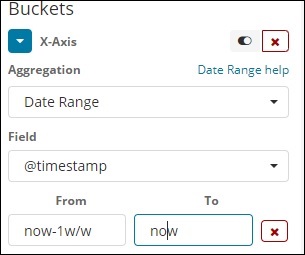
日期范围
您需要一个日期字段才能使用此聚合类型。这里我们将有一个日期范围,即要给出的起始日期和截止日期。这些存储桶将根据给定的表格和日期提供其文件。
过滤器
通过过滤器类型聚合,将根据过滤器形成存储桶。在这里,您将获得一个根据一个文档可以存在于一个或多个存储桶中的过滤条件形成的多存储桶。
使用过滤器,用户可以在过滤器选项中编写查询,如下所示 -
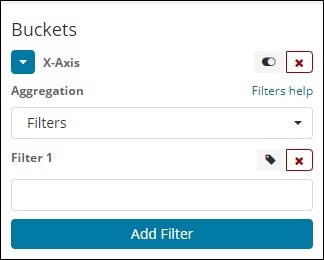
您可以使用“添加过滤器”按钮添加您选择的多个过滤器。
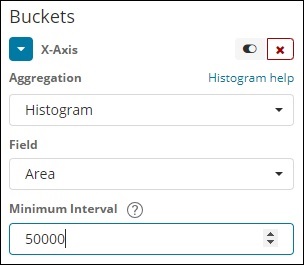
直方图
这种类型的聚合应用于数字字段,它将根据应用的间隔将文档分组到存储桶中。例如0-50,50-100,100-150等。
IPv4 范围
这种类型的聚合主要用于 IP 地址。
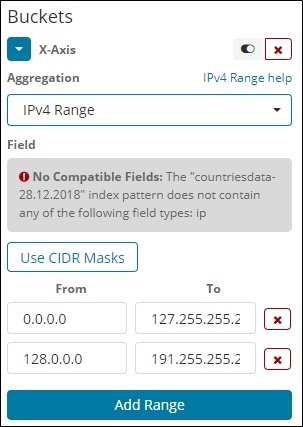
我们拥有的索引 contriesdata-28.12.2018 没有 IP 类型的字段,因此它显示一条消息,如上所示。如果您碰巧有 IP 字段,则可以在其中指定 From 和 To 值,如上所示。
范围
这种类型的聚合需要字段为数字类型。您需要指定范围,文档将列在属于该范围的存储桶中。
如果需要,您可以通过单击“添加范围”按钮添加更多范围。
重要条款
这种类型的聚合主要用于字符串字段。
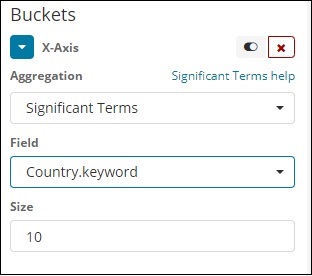
条款
这种类型的聚合用于所有可用字段,即数字、字符串、日期、布尔值、IP 地址、时间戳等。请注意,这是我们将在本节中处理的所有可视化中使用的聚合。教程。
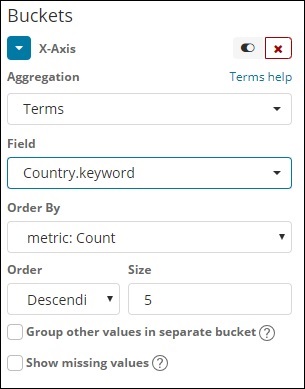
我们有一个选项顺序,我们将根据该选项顺序根据我们选择的指标对数据进行分组。大小是指您想要在可视化中显示的存储桶的数量。
接下来,让我们谈谈指标聚合。
指标聚合
指标聚合主要是指对存储桶中存在的文档进行数学计算。例如,如果您选择数字字段,则可以对其执行的度量计算为 COUNT、SUM、MIN、MAX、AVERAGE 等。
这里给出了我们将讨论的度量聚合列表 -
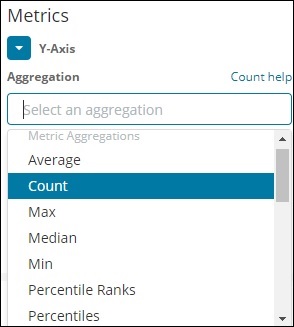
在本节中,让我们讨论我们将经常使用的重要内容 -
- 平均的
- 数数
- 最大限度
- 最小
- 和
该指标将应用于我们上面已经讨论过的单个存储桶聚合。
接下来,让我们在这里讨论指标聚合列表 -
平均的
这将给出存储桶中存在的文档值的平均值。例如 -
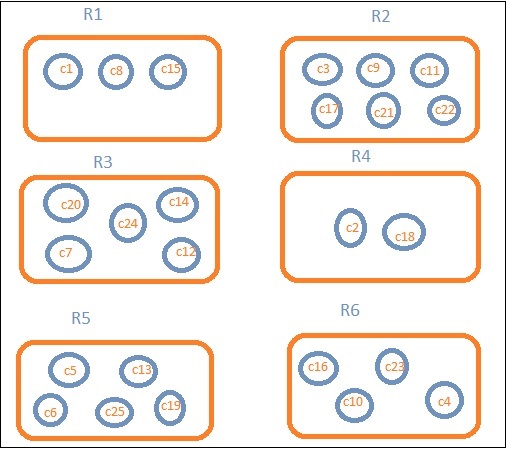
R1到R6是桶。在 R1 中,我们有 c1、c8 和 c15。假设c1的值为300,c8为500,c15为700。现在获取R1桶的平均值
R1 = c1 的值 + c8 的值 + c15 的值 / 3 = 300 + 500 + 700 / 3 = 500。
存储桶 R1 的平均值为 500。这里文档的值可以是任何东西,如果您考虑国家/地区数据,它可能是该地区国家/地区的面积。
数数
这将给出存储桶中存在的文档的计数。假设您想要该区域中存在的国家/地区的计数,它将是存储桶中存在的文档总数。例如,R1 将为 3、R2 = 6、R3 = 5、R4 = 2、R5 = 5 和 R6 = 4。
最大限度
这将给出存储桶中存在的文档的最大值。考虑上面的例子,如果我们在区域桶中有区域明智的国家数据。每个地区的最大值将是面积最大的国家/地区。因此每个地区都有一个国家,即 R1 到 R6。
在
这将给出存储桶中存在的文档的最小值。考虑上面的示例,如果我们在区域存储桶中有区域明智的国家/地区数据。每个地区的最小值将是面积最小的国家。因此每个地区都有一个国家,即 R1 到 R6。
和
这将给出存储桶中存在的文档值的总和。例如,如果您考虑上面的示例,如果我们想要该地区的总面积或国家/地区,那么它将是该地区存在的文档的总和。
例如,要知道 R1 区域的国家总数为 3、R2 = 6、R3 = 5、R4 = 2、R5 = 5 和 R6 = 4。
如果我们有包含该地区面积的文档,则 R1 到 R6 将为该地区汇总国家/地区的面积。