- Kibana 教程
- Kibana - 主页
- Kibana - 概述
- Kibana - 环境设置
- Kibana - Elk Stack 简介
- Kibana - 加载示例数据
- Kibana - 管理
- Kibana - 发现
- Kibana - 聚合和指标
- Kibana - 创建可视化
- Kibana - 使用图表
- Kibana - 使用图表
- Kibana - 使用热图
- 使用坐标图
- Kibana - 使用区域地图
- 使用规范和目标
- Kibana - 使用画布
- Kibana - 创建仪表板
- Kibana - 泰美狮
- Kibana - 开发工具
- Kibana - 监控
- 使用 Kibana 创建报告
- Kibana 有用资源
- Kibana - 快速指南
- Kibana - 有用的资源
- Kibana - 讨论
Kibana - Elk Stack 简介
Kibana 是一个开源可视化工具,主要用于分析折线图、条形图、饼图、热图等形式的大量日志。Kibana 与 Elasticsearch 和 Logstash 同步工作,共同构成所谓的 ELK堆栈。
ELK代表 Elasticsearch、Logstash 和 Kibana。ELK是全球范围内用于日志分析的流行日志管理平台之一。
在 ELK 堆栈中 -
Logstash从不同的输入源提取日志数据或其他事件。它处理事件,然后将其存储在 Elasticsearch 中。
Kibana是一个可视化工具,它访问 Elasticsearch 的日志,并能够以折线图、条形图、饼图等形式显示给用户。
在本教程中,我们将与 Kibana 和 Elasticsearch 密切合作,并以不同的形式可视化数据。
在本章中,让我们了解如何一起使用 ELK 堆栈。此外,您还将看到如何 -
- 将 CSV 数据从 Logstash 加载到 Elasticsearch。
- 在 Kibana 中使用 Elasticsearch 的索引。
将 CSV 数据从 Logstash 加载到 Elasticsearch
我们将使用 CSV 数据通过 Logstash 将数据上传到 Elasticsearch。为了进行数据分析,我们可以从kaggle.com网站获取数据。Kaggle.com网站上传了所有类型的数据,用户可以使用它来进行数据分析。
我们从这里获取了country.csv数据: https: //www.kaggle.com/fernandol/countries-of-the-world。您可以下载 csv 文件并使用它。
我们要使用的 csv 文件包含以下详细信息。
文件名 -countriesdata.csv
列 - “国家”、“地区”、“人口”、“面积”
您还可以创建一个虚拟 csv 文件并使用它。我们将使用logstash 将这些数据从countriesdata.csv转储到elasticsearch。
在终端中启动 elasticsearch 和 Kibana 并保持其运行。我们必须为logstash创建配置文件,其中包含有关CSV文件的列的详细信息以及其他详细信息,如下面给出的logstash配置文件所示 -
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}
在配置文件中,我们创建了 3 个组件 -
输入
我们需要指定输入文件的路径,在我们的例子中是 csv 文件。存储 csv 文件的路径被赋予路径字段。
筛选
将使用带有分隔符的 csv 组件(在我们的示例中为逗号),以及可用于 csv 文件的列。由于logstash将所有数据视为字符串,因此如果我们希望将任何列用作整数,则必须使用上面所示的mutate指定浮点数。
输出
对于输出,我们需要指定需要放置数据的位置。在我们的例子中,我们使用的是elasticsearch。需要提供给elasticsearch的数据是它运行的主机,我们将其称为localhost。下一个字段是索引,我们将其命名为“国家/地区-currentdate”。一旦 Elasticsearch 中的数据更新,我们就必须在 Kibana 中使用相同的索引。
将上述配置文件保存为logstash_countries.config。请注意,我们需要在下一步中将此配置的路径提供给logstash命令。
要将数据从 csv 文件加载到elasticsearch,我们需要启动elasticsearch 服务器 -
现在,在浏览器中运行http://localhost:9200来确认elasticsearch是否运行成功。
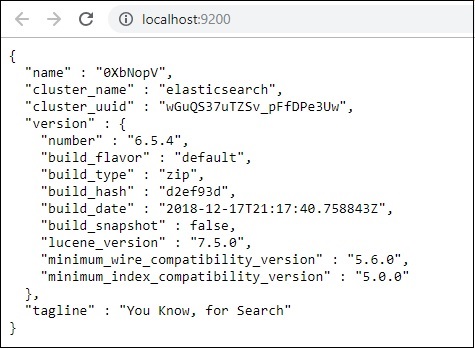
我们正在运行elasticsearch。现在进入logstash安装路径并运行以下命令将数据上传到elasticsearch。
> logstash -f logstash_countries.conf
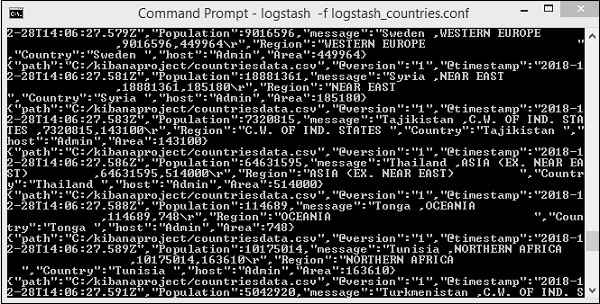
上面的屏幕显示了从 CSV 文件加载到 Elasticsearch 的数据。要知道我们是否在 Elasticsearch 中创建了索引,我们可以按如下方式检查 -
我们可以看到创建的countriesdata-28.12.2018索引如上所示。

该指数的详细信息 -countries-28.12.2018 如下 -
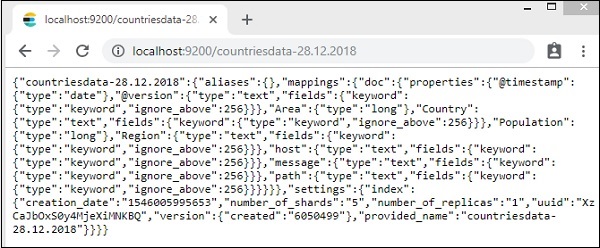
请注意,当数据从logstash上传到elasticsearch时,会创建带有属性的映射详细信息。
在 Kibana 中使用来自 Elasticsearch 的数据
目前,我们在 localhost 上运行 Kibana,端口 5601 - http://localhost:5601。Kibana 的 UI 如下所示 -
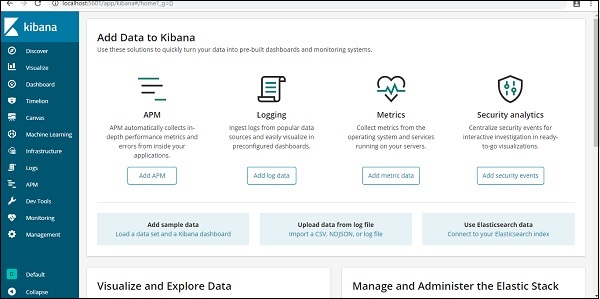
请注意,我们已经将 Kibana 连接到 Elasticsearch,并且我们应该能够在 Kibana 中看到 索引:countries-28.12.2018。
在 Kibana UI 中,单击左侧的“管理菜单”选项 -
现在,单击索引管理 -
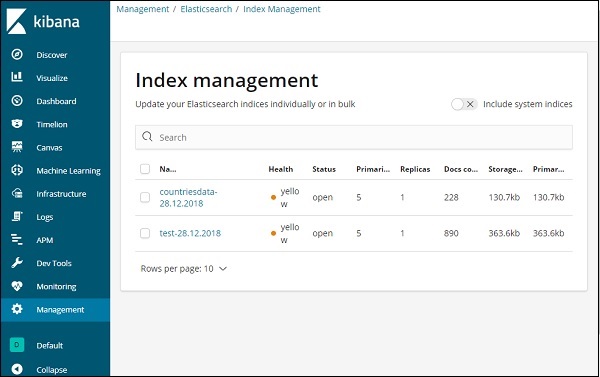
Elasticsearch 中存在的索引显示在索引管理中。我们将在 Kibana 中使用的索引是countriesdata-28.12.2018。
因此,由于我们在 Kibana 中已经有了 Elasticsearch 索引,接下来将了解如何使用 Kibana 中的索引以饼图、条形图、折线图等形式可视化数据。