- Selenium Webdriver 教程
- 家
- 介绍
- 安装
- 浏览器导航
- 识别单个元素
- 识别多个元素
- 显式等待和隐式等待
- 弹出窗口
- 向后和向前导航
- cookie
- 例外情况
- 动作类
- 创建基本测试
- 形式
- 拖放
- 视窗
- 警报
- 处理链接
- 处理编辑框
- 颜色支持
- 在 Python 中生成 HTML 测试报告
- 从 Excel 读取/写入数据
- 处理复选框
- 在多个浏览器中执行测试
- 无头执行
- 等待支持
- 选择支持
- JavaScript 执行器
- Chrome WebDriver 选项
- 滚动操作
- 捕获屏幕截图
- 右键点击
- 双击
- Selenium Webdriver 有用资源
- Selenium WebDriver - 快速指南
- Selenium WebDriver - 有用的资源
- Selenium WebDriver - 讨论
Selenium Webdriver - 识别多个元素
在本章中,我们将学习如何通过各种选项来识别多个元素。让我们首先了解通过 Id 识别多个元素。
按 ID
不建议通过定位器 id 来标识多个元素,因为 id 属性的值对于元素来说是唯一的,并且适用于页面上的单个元素。
按类名
导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。我们可以使用元素的类属性来识别它们,并使用 find_elements_by_class_name 方法。这样,所有与该属性类的值匹配的元素都会以列表的形式返回。
如果没有与 class 属性值匹配的元素,则应返回空列表。
通过类名标识多个元素的语法如下-
driver.find_elements_by_class_name("value of class attribute")
让我们看看具有 class 属性的 webelements 的 html 代码,如下所示 -

上图中突出显示的 class 属性的值是 toc Chapters。让我们尝试计算此类网络元素的数量。
代码实现
通过类名识别多个元素的代码实现如下 -
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/about/about_careers.htm")
#identify elements with class attribute
l = driver.find_elements_by_class_name("chapters")
#count elements
s = len(l)
print('Count is:')
print(s)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,具有类属性值 Chapters(从 len 方法获得)的 Web 元素的总数 - 2 会打印在控制台中。
按标记名
导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。我们可以使用元素的标记名来识别它们,并使用 find_elements_by_tag_name 方法。这样,所有与标记名匹配的元素都会以列表的形式返回。
如果没有与标记名的值匹配的元素,则应返回空列表。
通过标记名标识多个元素的语法如下-
driver.find_elements_by_tag_name("value of tagname")
让我们看一下 webelement 的 html 代码,如下 -

上图中突出显示的标记名的值为 h4。让我们尝试计算标记名为 h4 的 Web 元素的数量。
代码实现
通过标记名识别多个元素的代码实现如下 -
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/index.htm")
#identify elements with tagname
l = driver.find_elements_by_tag_name("h4")
#count elements
s = len(l)
print('Count is:')
print(s)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,标签名为 h4(从 len 方法获得)的 webelement 的总数 - 1 会打印在控制台中。
通过部分链接文本
一旦我们导航到网页,我们可能必须通过单击链接来与网络元素进行交互以完成我们的自动化测试用例。部分链接文本用于具有锚标记的元素。
为此,我们的首要工作是识别元素。我们可以使用元素的部分链接文本属性来进行识别,并使用 find_elements_by_partial_link_text 方法。这样,具有给定部分链接文本的匹配值的所有元素都会以列表的形式返回。
如果没有与部分链接文本的匹配值的元素,则应返回空列表。
通过部分链接文本识别多个元素的语法如下-
driver.find_elements_by_partial_link_text("value of partial link text")
让我们看看链接的html代码,如下 -

上图中突出显示的链接 - 使用条款具有标记名 - a 和部分链接文本 - 条款。让我们在识别完文本后尝试对其进行识别。
代码实现
通过部分链接文本识别多个元素的代码实现如下 -
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/about/about_careers.htm")
#identify elements with partial link text
l = driver.find_elements_by_partial_link_text('Terms')
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.text
print('Text is: ' + t)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,使用部分链接文本定位器(从文本方法获得)标识的链接文本 - 使用条款将打印在控制台中。
通过链接文本
一旦我们导航到网页,我们可能必须通过单击链接来与网络元素进行交互以完成我们的自动化测试用例。链接文本用于具有锚标记的元素。
为此,我们的首要工作是识别元素。我们可以使用元素的链接文本属性来识别它们,并利用 find_elements_by_link_text 方法。这样,具有给定链接文本的匹配值的所有元素都会以列表的形式返回。
如果没有与链接文本的值匹配的元素,则应返回空列表。
通过链接文本识别多个元素的语法如下-
driver.find_elements_by_link_text("value of link text")
让我们看看链接的html代码,如下 -

上图中突出显示的链接 - Cookies 政策具有标记名 - a 和链接文本 - Cookies 政策。让我们在识别完文本后尝试对其进行识别。
代码实现
通过链接文本识别多个元素的代码实现如下 -
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/about/about_careers.htm")
#identify elements with link text
l = driver.find_elements_by_link_text('Cookies Policy')
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.text
print('Text is: ' + t)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,用链接文本定位器(从文本方法获得)标识的链接文本 - Cookies 策略会打印在控制台中。
按名字
导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。我们可以使用元素的名称属性来识别它们,并使用 find_elements_by_name 方法。这样,属性名称匹配值的元素就会以列表的形式返回。
如果没有与 name 属性值匹配的元素,则应返回空列表。
通过名称识别多个元素的语法如下-
driver.find_elements_by_name("value of name attribute")
让我们看一下 webelement 的 html 代码,如下 -

上图中突出显示的编辑框具有带有值搜索的名称属性。让我们在识别后尝试在这个编辑框中输入一些文本。
代码实现
通过名称识别多个元素的代码实现如下 -
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/index.htm")
#identify elements with name attribute
l = driver.find_elements_by_name('search')
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.send_keys('Selenium Python')
v = i.get_attribute('value')
print('Value entered is: ' + v)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,在编辑框中输入的值(从 get_attribute 方法获得) - Selenium Python 会打印在控制台中。
通过 CSS 选择器
导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。我们可以创建一个 css 选择器来识别它们,并使用 find_elements_by_css_selector 方法。这样,与给定 css 的匹配值的元素就会以列表的形式返回。
如果没有与 css 值匹配的元素,则应返回空列表。
CSS 选择器识别多个元素的语法如下-
driver.find_elements_by_css_selector("value of css")
CSS 表达规则
下面讨论创建 CSS 表达式的规则 -
要使用 css 来标识元素,表达式应为 tagname[attribute='value']。我们还可以专门使用 id 属性来创建 css 表达式。
对于id,css表达式的格式应该是tagname#id。例如,input#txt [这里input是标记名,txt是id属性的值]。
对于 class,css 表达式的格式应该是 tagname.class 。例如,input.cls-txt [此处输入是标记名,cls-txt 是类属性的值]。
如果父元素有 n 个子元素,并且我们想要识别第 n 个子元素,则 css 表达式应该具有 nth-of –type(n)。

在上面的代码中,如果我们要识别 ul[问答] 的第四个 li 子级,则 css 表达式应该为 ul.reading li:nth-of-type(4)。同样,要识别最后一个子节点,CSS 表达式应为 ul.reading li:last-child。
对于值动态变化的属性,我们可以使用^=来定位属性值以特定文本开头的元素。例如,input[name^='qa'][这里input是标记名,name属性的值以qa开头]。
对于值动态变化的属性,我们可以使用 $= 来定位属性值以特定文本结尾的元素。例如, input[class$='txt'] 这里,input 是标记名,class 属性的值以 txt 结尾。
对于值动态变化的属性,我们可以使用*=来定位属性值包含特定子文本的元素。例如,input[name*='nam'] 这里,input 是标记名,name 属性的值包含子文本 nam。
让我们看看 webelement 的 html 代码 -

上图中突出显示的编辑框有一个带有值搜索的 name 属性,css 表达式应为 input[name='search']。让我们在识别后尝试在这个编辑框中输入一些文本。
代码实现
CSS选择器识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/index.htm")
#identify elements with css
l = driver.find_elements_by_css_selector("input[name='search']")
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.send_keys('Tutorialspoint')
v = i.get_attribute('value')
print('Value entered is: ' + v)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,在编辑框中输入的值(从 get_attribute 方法获得)-Tutorialspoint 会打印在控制台中。
通过 Xpath
导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。我们可以创建一个 xpath 来识别它们,并使用 find_elements_by_xpath 方法。这样,与给定 xpath 的匹配值的元素就会以列表的形式返回。
如果没有与 xpath 的值匹配的元素,则应返回空列表。
Xpath识别多个元素的语法如下:
driver.find_elements_by_xpath("value of xpath")
Xpath 表达式的规则
下面讨论创建 xpath 表达式的规则 -
要使用 xpath 标识元素,表达式应为 //tagname[@attribute='value']。xpath 可以有两种类型——相对路径和绝对路径。绝对xpath以/符号开头,从根节点开始直到我们想要识别的元素。
例如,
/html/body/div[1]/div/div[1]/a
相对xpath以//符号开始,并不从根节点开始。
例如,
//img[@alt='tutorialspoint']
让我们看看突出显示的链接 - Home 从根开始的 html 代码。
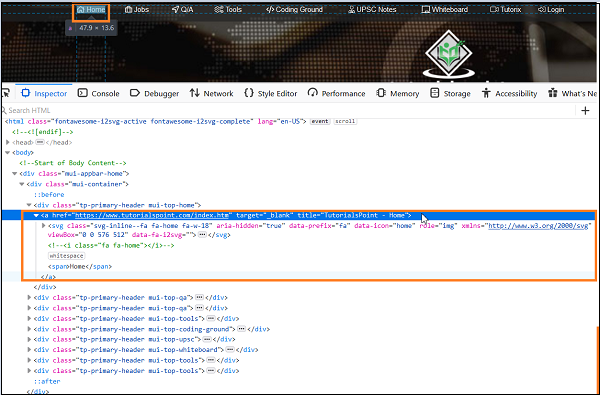
元素 Home 的绝对 xpath 可以如下 -
/html/body/div[1]/div/div[1]/a.
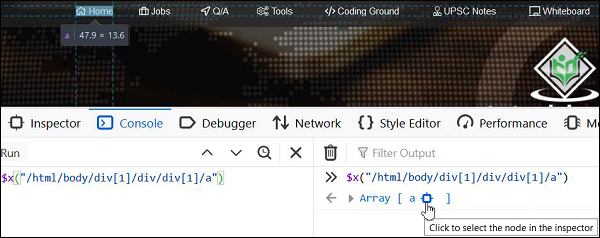
元素 Home 的相对 xpath 可以如下 -
//a[@title='TutorialsPoint - Home'].

功能
还有一些可用的函数可以帮助构建相对的 xpath 表达式 -
文本()
它用于借助页面上的可见文本来识别元素。xpath 表达式如下 -
//*[text()='Home'].

以。。开始
它用于标识属性值以特定文本开头的元素。此函数通常用于其值在每次页面加载时发生变化的属性。
让我们看看元素 Q/A 的 html -

xpath 表达式应如下所示 -
//a[starts-with(@title, 'Questions &')].

包含()
它标识其属性值包含子文本的元素。此函数通常用于其值在每次页面加载时发生变化的属性。
xpath 表达式如下 -
//a[contains(@title, 'Questions & Answers')].

让我们看看 webelement 的 html 代码 -

上图中突出显示的编辑框有一个带有值搜索的 name 属性,xpath 表达式应为 //input[@name='search']。让我们在识别后尝试在这个编辑框中输入一些文本。
代码实现
通过 Xpath 识别多个元素的代码实现如下 -
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://www.tutorialspoint.com/index.htm")
#identify elements with xpath
l = driver.find_elements_by_xpath("//input[@name='search']")
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.send_keys('Tutorialspoint - Selenium')
v = i.get_attribute('value')
print('Value entered is: ' + v)
#driver quit
driver.quit()
输出

输出显示消息 - Process with exit code 0 表示上述 Python 代码执行成功。此外,在编辑框中输入的值(从 get_attribute 方法获得) - Tutorialspoint - Selenium 会打印在控制台中。