回归技术
回归是一种统计技术,有助于确定相关经济变量之间的关系。第一步涉及估计自变量的系数,然后测量估计系数的可靠性。这需要制定一个假设,基于假设,我们可以创建一个函数。
如果经理想要确定公司的广告支出与其销售收入之间的关系,他将接受假设检验。假设较高的广告支出会导致公司的销售额增加。经理收集特定时间段内的广告支出和销售收入数据。这个假设可以转化为数学函数,它导致 -
Y = A + Bx
其中Y是销售额,x是广告支出,A和B是常数。
将假设转化为函数后,其基础是找到因变量和自变量之间的关系。因变量的值对于研究人员来说是最重要的,并且取决于其他变量的值。自变量用于解释因变量的变化。它可以分为两种类型 -
简单回归- 一个自变量
多元回归- 几个自变量
简单回归
以下是建立回归分析的步骤 -
- 指定回归模型
- 获取变量数据
- 估计数量关系
- 测试结果的统计显着性
- 结果在决策中的应用
简单回归的公式是 -
Y = a + bX + u
Y = 因变量
X = 自变量
a = 截距
b = 斜率
u = 随机因子
横截面数据提供给定时间的一组实体的信息,而时间序列数据提供一个实体随时间变化的信息。当我们估计回归方程时,它涉及找出因变量和自变量之间的最佳线性关系的过程。
普通最小二乘法 (OLS)
普通最小二乘法旨在通过分散的点来拟合直线,从而使点与直线的偏差平方和最小化。它是一种统计方法。通常软件包执行 OLS 估计。
Y = a + bX
决定系数 (R 2 )
决定系数是一种衡量标准,表明因变量的变化由自变量的变化引起的百分比。R 2是拟合模型优度的度量。以下是方法 -
平方和 (TSS)
Y 样本值与 Y 平均值的偏差平方和。
TSS = SUM ( Y i − Y ) 2
Y i = 因变量
Y = 因变量的平均值
i = 观察次数
回归平方和 (RSS)
Y 的估计值与 Y 平均值的平方偏差之和。
RSS = SUM (Ỷ i − uY) 2
Ỷ i = Y 的估计值
Y = 因变量的平均值
i = 变化数
误差平方和 (ESS)
Y 的样本值与 Y 的估计值的平方偏差之和。
ESS = SUM ( Y i − Ỷ i ) 2
Ỷ i = Y 的估计值
Y i = 因变量
i = 观察次数
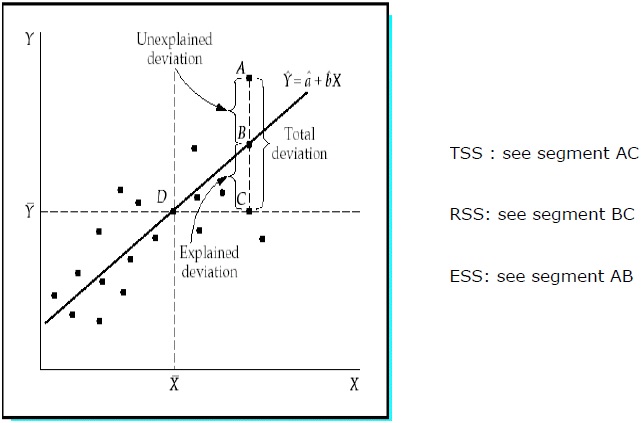
R 2测量 Y 与其均值的总偏差的比例,该偏差由回归模型解释。R 2越接近1,回归方程的解释力就越大。R 2接近 0 表明回归方程的解释力很小。

为了评估回归系数,使用总体样本而不是整个总体。根据样本对总体做出假设并判断这些假设的好坏非常重要。
评估回归系数
总体中的每个样本都会生成自己的截距。要计算统计差异,可以使用以下方法 -
双尾测试 -
原假设:H 0 : b = 0
替代假设:H a : b ≠ 0
一尾测试 -
原假设:H 0 : b > 0(或 b < 0)
替代假设:H a : b < 0(或 b > 0)
统计测试 -
b = 估计系数
E (b) = b = 0(原假设)
SE b = 系数的标准误差
。t的值取决于自由度、一两次失败的检验以及显着性水平。为了确定t的临界值,可以使用 t 表。然后是 t 值与临界值的比较。如果统计检验的绝对值大于或等于临界 t 值,则需要拒绝原假设。不要拒绝原假设,统计检验的绝对值小于临界 t 值。
多元回归分析
与多元回归分析中的简单回归不同,假设其他变量的值恒定,系数表示因变量的变化。
统计显着性检验称为F 检验。F 检验很有用,因为它衡量整个回归方程的统计显着性,而不仅仅是单个回归方程的统计显着性。这里,在原假设中,总体的因变量和自变量之间不存在关系。
公式为 - H 0 : b1 = b2 = b3 = …。= 背景 = 0
总体的因变量和k 个自变量之间不存在关系。
F 静态测试 -
$$F \: =\: \frac{ \left ( \frac{R^2}{K} \right )}{\frac{(1-R^2)}{(nk-1)}}$$
F的临界值取决于分子和分母的自由度和显着性水平。F 表可用于确定临界 F 值。与 F 值与临界值 (F*) 相比 -
如果 F > F*,我们需要拒绝原假设。
如果 F < F*,则不要拒绝原假设,因为因变量与所有自变量之间不存在显着关系。