- 数据结构与算法
- DSA - 主页
- DSA - 概述
- DSA - 环境设置
- 数据结构
- DSA - 数据结构基础知识
- DSA - 数据结构和类型
- DSA - 数组数据结构
- 链表
- DSA - 链表基础知识
- DSA - 双向链表
- DSA - 循环链表
- 堆栈和队列
- DSA - 堆栈
- DSA - 表达式解析
- DSA-队列
- 图数据结构
- DSA - 图数据结构
- DSA-深度优先遍历
- DSA-广度优先遍历
- DSA——生成树
- 树数据结构
- DSA - 树数据结构
- DSA - 树遍历
- DSA - 二叉搜索树
- DSA - AVL 树
- DSA - 红黑树
- DSA - B 树
- DSA - B+ 树
- DSA - 八字树
- DSA - 尝试
- DSA-堆
- 递归
- DSA - 递归基础知识
- DSA - 河内塔
- DSA - 斐波那契数列
- DSA 有用资源
- DSA - 问题与解答
- DSA - 快速指南
- DSA - 有用的资源
- DSA - 讨论
数据结构和算法-树
树是一种具有基于层次结构的非线性抽象数据类型。它由通过链接连接的节点(存储数据的位置)组成。树数据结构源于称为根节点的单个节点,并具有连接到根的子树。
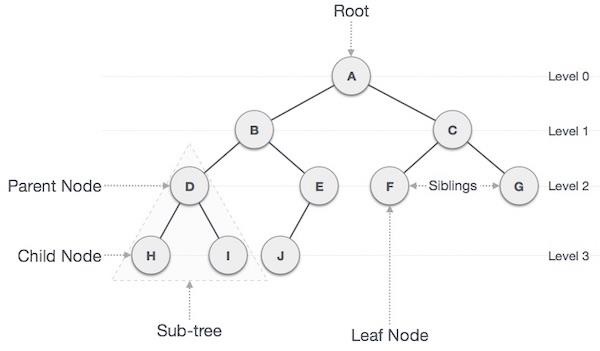
重要条款
以下是与树有关的重要术语。
路径- 路径是指沿树边缘的节点序列。
根- 树顶部的节点称为根。每棵树只有一个根,并且从根节点到任意节点都有一条路径。
父节点- 除根节点外的任何节点都有一条向上的边指向称为父节点的节点。
子节点- 给定节点下方通过其边缘向下连接的节点称为其子节点。
叶- 没有任何子节点的节点称为叶节点。
子树- 子树代表节点的后代。
访问- 访问是指当控制在节点上时检查节点的值。
遍历- 遍历意味着按特定顺序穿过节点。
Levels - 节点的级别代表节点的生成。如果根节点位于级别 0,则其下一个子节点位于级别 1,其孙节点位于级别 2,依此类推。
键- 键表示节点的值,基于该值对节点执行搜索操作。
树木的类型
有三种类型的树 -
一般树木
二叉树
二叉搜索树
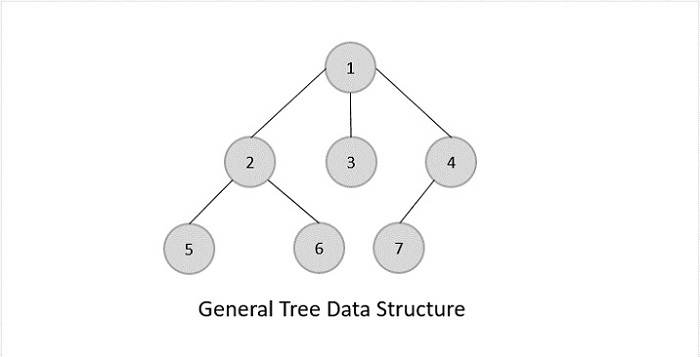
一般树木
一般树是无序树数据结构,其中根节点具有最少 0 个或最多“n”个子树。
通用树对其层次结构没有任何限制。因此,根节点的作用就像所有其他子树的超集。
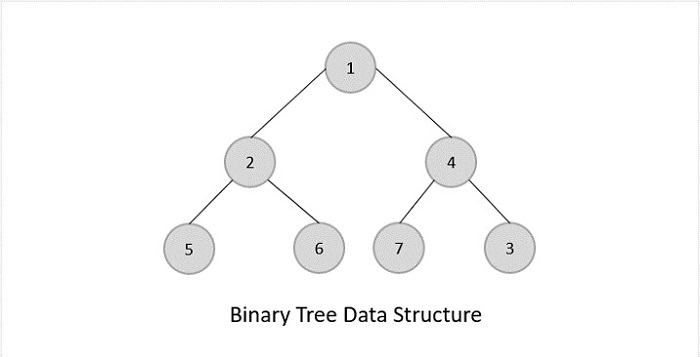
二叉树
二叉树是一般树,根节点最多只能容纳 2 个子树:左子树和右子树。根据子节点的数量,二叉树分为三种类型。
满二叉树
满二叉树是一种二叉树类型,其中每个节点都有 0 或 2 个子节点。
完全二叉树
完全二叉树是所有叶节点必须位于同一级别的二叉树类型。然而,完全二叉树中的根节点和内部节点可以有 0、1 或 2 个子节点。
完美二叉树
完美二叉树是一种二叉树类型,其中所有叶节点都位于同一级别,并且除叶节点外的每个节点都有 2 个子节点。
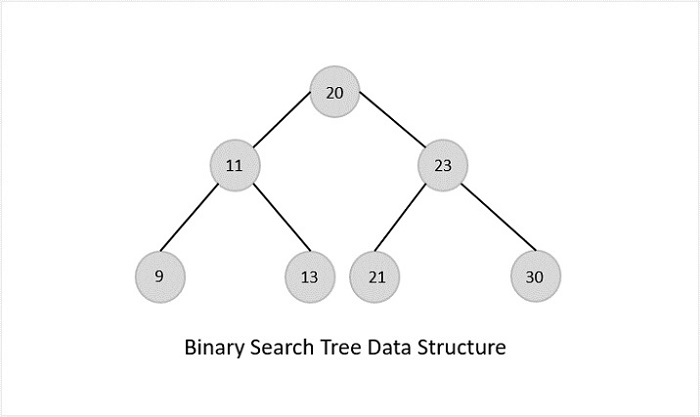
二叉搜索树
二叉搜索树拥有二叉树的所有属性,包括它们自己的一些额外属性,基于一些约束,使得它们比二叉树更有效。
二叉搜索树 (BST) 中的数据始终以这样的方式存储:左子树中的值始终小于根节点中的值,右子树中的值始终大于根节点中的值节点,即左子树 < 根节点 ≤ 右子树。
贝斯特技术的优势
二叉搜索树比二叉树更有效,因为执行各种操作的时间复杂度降低了。
由于键的顺序仅基于父节点,因此搜索操作变得更简单。
BST 的对齐也有利于范围查询,执行范围查询是为了查找两个键之间存在的值。这有助于数据库管理系统。
BST的缺点
二叉搜索树的主要缺点是,如果节点中的所有元素都大于或小于根节点,则树会倾斜。简而言之,树完全向一侧倾斜。
这种偏度将使树成为链表而不是 BST,因为搜索操作的最坏情况时间复杂度变为 O(n)。
为了克服二叉搜索树的偏斜问题,引入了平衡二叉搜索树的概念。
平衡二叉搜索树
考虑二叉搜索树,其中“m”作为左子树的高度,“n”作为右子树的高度。如果 (mn) 的值等于 0,1 或 -1,则该树被称为平衡二叉搜索树。
这些树的设计方式是,一旦高度差超过 1,它们就会自动平衡。二叉搜索树使用旋转作为自平衡算法。有四种不同类型的旋转:左左、右右、左右、右左。
有各种类型的自平衡二叉搜索树 -
AVL树
红黑树
B树
B+树
八字树
优先搜索树