- OpenCV Python 教程
- OpenCV Python - 主页
- OpenCV Python - 概述
- OpenCV Python - 环境
- OpenCV Python - 读取图像
- OpenCV Python - 写入图像
- OpenCV Python - 使用 Matplotlib
- OpenCV Python - 图像属性
- OpenCV Python - 位运算
- OpenCV Python - 形状和文本
- OpenCV Python - 鼠标事件
- OpenCV Python - 添加轨迹栏
- OpenCV Python - 调整大小和旋转
- OpenCV Python - 图像阈值
- OpenCV Python - 图像过滤
- OpenCV Python - 边缘检测
- OpenCV Python - 直方图
- OpenCV Python - 颜色空间
- OpenCV Python - 转换
- OpenCV Python - 图像轮廓
- OpenCV Python - 模板匹配
- OpenCV Python - 图像Pyramid
- OpenCV Python - 图像相加
- OpenCV Python - 图像混合
- OpenCV Python - 傅里叶变换
- OpenCV Python - 捕获视频
- OpenCV Python - 播放视频
- OpenCV Python - 视频图像
- OpenCV Python - 来自图像的视频
- OpenCV Python - 人脸检测
- OpenCV Python - Meanshift/Camshift
- OpenCV Python - 特征检测
- OpenCV Python - 特征匹配
- OpenCV Python - 数字识别
- OpenCV Python 资源
- OpenCV Python - 快速指南
- OpenCV Python - 资源
- OpenCV Python - 讨论
OpenCV-Python - 快速指南
OpenCV Python - 概述
OpenCV 代表开源计算机视觉,是一个在实时计算机视觉应用程序编程中有用的函数库。术语计算机视觉用于使用计算机程序对数字图像和视频进行分析的主题。计算机视觉是人工智能、机器学习等现代学科的重要组成部分。
OpenCV 最初由 Intel 开发,是一个用 C++ 编写的跨平台库,但也有 OpenCV 的 C 接口包装器,该包装器已为许多其他编程语言(例如 Java 和 Python)开发。在本教程中,将描述 OpenCV 的 Python 库的功能。
OpenCV-Python
OpenCV-Python是 OpenCV 库的 C++ 实现的 Python 包装器。它利用 NumPy 库进行数值运算,是计算机视觉问题的快速原型设计工具。
OpenCV-Python 是一个跨平台库,可在所有操作系统 (OS) 平台上使用,包括 Windows、Linux、MacOS 和 Android。OpenCV 还支持图形处理单元 (GPU) 加速。
本教程专为希望获得计算机视觉应用领域专业知识的计算机科学学生和专业人士而设计。Python 和 NumPy 库的先验知识对于理解 OpenCV-Python 的功能至关重要。
OpenCV Python - 环境设置
在大多数情况下,使用 pip 应该足以在您的计算机上安装 OpenCV-Python。
用于安装 pip 的命令如下 -
pip install opencv-python
建议在新的虚拟环境中执行此安装。OpenCV-Python的当前版本是4.5.1.48,可以通过以下命令进行验证 -
>>> import cv2 >>> cv2.__version__ '4.5.1'
由于 OpenCV-Python 依赖于 NumPy,因此它也会自动安装。或者,您可以安装 Matplotlib 来渲染某些图形输出。
在 Fedora 上,您可以通过下面提到的命令安装 OpenCV-Python -
$ yum install numpy opencv*
OpenCV-Python 也可以通过从 http://sourceforge.net上提供的源代码进行构建来安装,请遵循同样的安装说明。
OpenCV Python - 读取图像
CV2包(OpenCV-Python 库的名称)提供了imread()函数来读取图像。
读取图像的命令如下 -
img=cv2.imread(filename, flags)
标志参数是以下常量的枚举 -
- cv2.IMREAD_COLOR (1) - 加载彩色图像。
- cv2.IMREAD_GRAYSCALE (0) - 以灰度模式加载图像
- cv2.IMREAD_UNCHANGED (-1) - 加载图像,包括 Alpha 通道
该函数将返回一个图像对象,可以使用 imshow() 函数渲染该图像对象。使用 imshow() 函数的命令如下 -
cv2.imshow(window-name, image)
图像显示在命名窗口中。将创建一个设置了 AUTOSIZE 标志的新窗口。WaitKey ()是一个键盘绑定函数。它的参数是以毫秒为单位的时间。
该函数等待指定的毫秒并保持窗口显示,直到按下某个键。最后,我们可以销毁所有由此创建的窗口。
该函数等待指定的毫秒并保持窗口显示,直到按下某个键。最后,我们可以销毁所有由此创建的窗口。
显示 OpenCV 徽标的程序如下 -
import numpy as np
import cv2
# Load a color image in grayscale
img = cv2.imread('OpenCV_Logo.png',1)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
上述程序显示 OpenCV 徽标如下 -
OpenCV Python - 写入图像
CV2 包有imwrite()函数,可将图像对象保存到指定文件中。
借助 imwrite() 函数保存图像的命令如下 -
cv2.imwrite(filename, img)
图像格式由 OpenCV 根据文件扩展名自动决定。OpenCV 支持 *.bmp、*.dib 、*.jpeg、*.jpg、*.png、*.webp、*.sr、*.tiff、\*.tif 等图像文件类型。
例子
以下程序加载 OpenCV 徽标图像并在按下“s”键时保存其灰度版本 -
import numpy as np
import cv2
# Load an color image in grayscale
img = cv2.imread('OpenCV_Logo.png',0)
cv2.imshow('image',img)
key=cv2.waitKey(0)
if key==ord('s'):
cv2.imwrite("opencv_logo_GS.png", img)
cv2.destroyAllWindows()
输出
OpenCV Python - 使用 Matplotlib
Python 的 Matplotlib 是一个功能强大的绘图库,拥有大量适用于各种绘图类型的绘图函数。它还具有 imshow() 函数来渲染图像。它提供了附加功能,例如缩放、保存等。
例子
在运行以下程序之前,请确保当前工作环境中已安装 Matplotlib。
import numpy as np
import cv2
import matplotlib.pyplot as plt
# Load an color image in grayscale
img = cv2.imread('OpenCV_Logo.png',0)
plt.imshow(img)
plt.show()
输出
OpenCV Python - 图像属性
OpenCV 读取 NumPy 数组中的图像数据。该 ndarray 对象的shape ()方法显示图像属性,例如尺寸和通道。
使用 shape() 方法的命令如下 -
>>> img = cv.imread("OpenCV_Logo.png", 1)
>>> img.shape
(222, 180, 3)
在上面的命令中 -
- 前两项 shape[0] 和 shape[1] 表示图像的宽度和高度。
- Shape[2]代表通道数。
- 3 表示图像具有红绿蓝 (RGB) 通道。
类似地,size 属性返回图像的大小。图像大小的命令如下 -
>>> img.size 119880
ndarray 中的每个元素代表一个图像像素。
借助下面提到的命令,我们可以访问和操作任何像素的值。
>>> p=img[50,50] >>> p array([ 1, 1, 255], dtype=uint8)
例子
以下代码将前 100X100 像素的颜色值更改为黑色。imshow ()函数可以验证结果。
>>> for i in range(100):
for j in range(100):
img[i,j]=[0,0,0]
输出

可以使用split()函数将图像通道分割为单独的平面。可以使用merge()函数合并通道。
split() 函数返回一个多通道数组。
我们可以使用以下命令来分割图像通道 -
>>> img = cv.imread("OpenCV_Logo.png", 1)
>>> b,g,r = cv.split(img)
您现在可以在每个平面上执行操作。
假设我们将蓝色通道中的所有像素设置为 0,代码如下 -
>>> img[:, :, 0]=0
>>> cv.imshow("image", img)
结果图像如下所示 -

OpenCV Python - 位运算
位运算用于图像处理和提取图像中的基本部分。
OpenCV 中实现了以下运算符 -
- 按位与
- 按位或
- 按位异或
- 按位非
实施例1
为了演示这些运算符的使用,我们拍摄了两张带有实心圆和空心圆的图像。
以下程序演示了 OpenCV-Python 中按位运算符的使用 -
import cv2
import numpy as np
img1 = cv2.imread('a.png')
img2 = cv2.imread('b.png')
dest1 = cv2.bitwise_and(img2, img1, mask = None)
dest2 = cv2.bitwise_or(img2, img1, mask = None)
dest3 = cv2.bitwise_xor(img1, img2, mask = None)
cv2.imshow('A', img1)
cv2.imshow('B', img2)
cv2.imshow('AND', dest1)
cv2.imshow('OR', dest2)
cv2.imshow('XOR', dest3)
cv2.imshow('NOT A', cv2.bitwise_not(img1))
cv2.imshow('NOT B', cv2.bitwise_not(img2))
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()
输出



实施例2
在另一个涉及按位运算的示例中,opencv 徽标叠加在另一张图像上。在这里,我们通过对徽标调用threshold()函数获得一个掩码数组,并在它们之间进行AND运算。
类似地,通过 NOT 运算,我们得到一个反掩码。另外,我们得到与背景图像的“与”。
以下是确定按位运算的使用的程序 -
import cv2 as cv
import numpy as np
img1 = cv.imread('lena.jpg')
img2 = cv.imread('whitelogo.png')
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols]
img2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)
ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)
mask_inv = cv.bitwise_not(mask)
# Now black-out the area of logo
img1_bg = cv.bitwise_and(roi,roi,mask = mask_inv)
# Take only region of logo from logo image.
img2_fg = cv.bitwise_and(img2,img2,mask = mask)
# Put logo in ROI
dst = cv.add(img2_fg, img1_bg)
img1[0:rows, 0:cols ] = dst
cv.imshow(Result,img1)
cv.waitKey(0)
cv.destroyAllWindows()
输出
蒙版图像给出以下结果 -

OpenCV Python - 绘制形状和文本
在本章中,我们将学习如何借助 OpenCV-Python 在图像上绘制形状和文本。让我们首先了解如何在图像上绘制形状。
在图像上绘制形状
我们需要了解 OpenCV-Python 中所需的函数,这有助于我们在图像上绘制形状。
功能
OpenCV-Python 包(称为 cv2)包含以下用于绘制相应形状的函数。
| 功能 | 描述 | 命令 |
|---|---|---|
| CV2.line() | 绘制连接两点的线段。 | cv2.line(img, pt1, pt2, 颜色, 粗细) |
| cv2.circle() | 以给定点为圆心绘制给定半径的圆 | cv2.circle(img,中心,半径,颜色,厚度) |
| cv2.矩形 | 以给定点作为左上角和右下角绘制一个矩形。 | cv2.rectangle(img, pt1, pt2, 颜色, 厚度) |
| cv2.椭圆() | 绘制简单或粗的椭圆弧或填充椭圆扇形。 | cv2.ellipse(img, 中心, 轴, 角度, startAngle, endAngle, 颜色, 厚度) |
参数
上述函数的通用参数如下 -
| 先生。 | 功能说明 |
|---|---|
| 1 | 图像 您要在其中绘制形状的图像 |
| 2 | 颜色 形状的颜色。对于 BGR,将其作为元组传递。对于灰度,只需传递标量值。 |
| 3 | 厚度 直线或圆等的粗细。如果对于圆形等封闭图形传递-1,它将填充形状。 |
| 4 | 线型 线路类型,是否8连线、抗锯齿线等。 |
例子
以下示例显示了如何在图像顶部绘制形状。下面给出了相同的程序 -
import numpy as np
import cv2
img = cv2.imread('LENA.JPG',1)
cv2.line(img,(20,400),(400,20),(255,255,255),3)
cv2.rectangle(img,(200,100),(400,400),(0,255,0),5)
cv2.circle(img,(80,80), 55, (255,255,0), -1)
cv2.ellipse(img, (300,425), (80, 20), 5, 0, 360, (0,0,255), -1)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出

绘制文字
提供cv2.putText ()函数来在图像上写入文本。其命令如下 -
img, text, org, fontFace, fontScale, color, thickness)
字体
OpenCV 支持以下字体 -
| 字体名称 | 字体大小 |
|---|---|
| FONT_HERSHEY_SIMPLEX | 0 |
| FONT_HERSHEY_PLAIN | 1 |
| FONT_HERSHEY_DUPLEX | 2 |
| FONT_HERSHEY_COMPLEX | 3 |
| FONT_HERSHEY_TRIPLEX | 4 |
| FONT_HERSHEY_COMPLEX_SMALL | 5 |
| FONT_HERSHEY_SCRIPT_SIMPLEX | 6 |
| FONT_HERSHEY_SCRIPT_COMPLEX | 7 |
| 斜体字体 | 16 |
例子
以下程序为著名足球运动员莱昂内尔·梅西的照片添加了文字说明。
import numpy as np
import cv2
img = cv2.imread('messi.JPG',1)
txt="Lionel Messi"
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,txt,(10,100), font, 2,(255,255,255),2,cv2.LINE_AA)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出

OpenCV Python - 处理鼠标事件
OpenCV 能够使用回调函数注册各种与鼠标相关的事件。这样做是为了根据鼠标事件的类型启动某个用户定义的操作。
| 先生编号 | 鼠标事件及描述 |
|---|---|
| 1 | CV.EVENT_MOUSEMOVE 当鼠标指针移到窗口上时。 |
| 2 | CV.EVENT_LBUTTONDOWN 表示按下了鼠标左键。 |
| 3 | CV.EVENT_RBUTTONDOWN 按下鼠标右键的事件。 |
| 4 | CV.EVENT_MBUTTONDOWN 表示鼠标中键被按下。 |
| 5 | CV.EVENT_LBUTTONUP 当释放鼠标左键时。 |
| 6 | CV.EVENT_RBUTTONUP 当释放鼠标右键时。 |
| 7 | CV.EVENT_MBUTTONUP 表示鼠标中键已释放。 |
| 8 | CV.EVENT_LBUTTONDBLCLK 当双击鼠标左键时会发生此事件。 |
| 9 | CV.EVENT_RBUTTONDBLCLK 表示双击鼠标右键。 |
| 10 | CV.EVENT_MBUTTONDBLCLK 表示双击鼠标中键。 |
| 11 | CV.EVENT_MOUSEWHEEL 向前滚动为正,向后滚动为负。 |
要在鼠标事件上触发函数,必须在setMouseCallback()函数的帮助下注册它。其命令如下 -
cv2.setMouseCallback(window, callbak_function)
该函数将事件的类型和位置传递给回调函数以进行进一步处理。
实施例1
每当在显示图像作为背景的窗口上发生左键双击事件时,以下代码就会绘制一个圆圈 -
import numpy as np
import cv2 as cv
# mouse callback function
def drawfunction(event,x,y,flags,param):
if event == cv.EVENT_LBUTTONDBLCLK:
cv.circle(img,(x,y),20,(255,255,255),-1)
img = cv.imread('lena.jpg')
cv.namedWindow('image')
cv.setMouseCallback('image',drawfunction)
while(1):
cv.imshow('image',img)
key=cv.waitKey(1)
if key == 27:
break
cv.destroyAllWindows()
输出
运行上述程序并在随机位置双击。将出现类似的输出 -

实施例2
以下程序根据用户输入(1,2 或 3)以交互方式绘制矩形、直线或圆形 -
import numpy as np
import cv2 as cv
# mouse callback function
drawing=True
shape='r'
def draw_circle(event,x,y,flags,param):
global x1,x2
if event == cv.EVENT_LBUTTONDOWN:
drawing = True
x1,x2 = x,y
elif event == cv.EVENT_LBUTTONUP:
drawing = False
if shape == 'r':
cv.rectangle(img,(x1,x2),(x,y),(0,255,0),-1)
if shape == 'l':
cv.line(img,(x1,x2),(x,y),(255,255,255),3)
if shape=='c':
cv.circle(img,(x,y), 10, (255,255,0), -1)
img = cv.imread('lena.jpg')
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
key=cv.waitKey(1)
if key==ord('1'):
shape='r'
if key==ord('2'):
shape='l'
if key==ord('3'):
shape='c'
#print (shape)
if key == 27:
break
cv.destroyAllWindows()
在窗口表面上,如果按下“1”,则在鼠标左键向下和向上的坐标之间绘制一个矩形。
如果用户选择为 2,则使用坐标作为端点绘制一条线。
当为圆选择 3 时,它会在鼠标松开事件的坐标处绘制。
下图是上述程序成功执行后的输出 -

OpenCV Python - 添加轨迹栏
OpenCV 中的 Trackbar 是一个滑块控件,通过手动在滑块上滑动选项卡,可以帮助从连续范围中选取变量的值。选项卡的位置与值同步。
createTrackbar() 函数使用以下命令创建一个 Trackbar 对象 -
cv2.createTrackbar(trackbarname, winname, value, count, TrackbarCallback)
在下面的示例中,提供了三个轨迹条供用户在灰度范围 0 到 255 之间设置 R、G 和 B 的值。
使用轨迹栏位置值绘制一个矩形,其填充颜色对应于 RGB 颜色值。
例子
以下程序用于添加轨迹栏 -
import numpy as np
import cv2 as cv
img = np.zeros((300,400,3), np.uint8)
cv.namedWindow('image')
def nothing(x):
pass
# create trackbars for color change
cv.createTrackbar('R','image',0,255,nothing)
cv.createTrackbar('G','image',0,255,nothing)
cv.createTrackbar('B','image',0,255,nothing)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == 27:
break
# get current positions of four trackbars
r = cv.getTrackbarPos('R','image')
g = cv.getTrackbarPos('G','image')
b = cv.getTrackbarPos('B','image')
#s = cv.getTrackbarPos(switch,'image')
#img[:] = [b,g,r]
cv.rectangle(img, (100,100),(200,200), (b,g,r),-1)
cv.destroyAllWindows()
输出

OpenCV Python - 调整图像大小和旋转图像
在本章中,我们将学习如何借助 OpenCVPython 调整图像大小和旋转图像。
调整图像大小
可以使用 cv2.resize() 函数放大或缩小图像。
resize ()函数的用法如下 -
resize(src, dsize, dst, fx, fy, interpolation)
一般来说,插值是估计已知数据点之间的值的过程。
当图形数据包含间隙,但间隙两侧或间隙内的几个特定点有可用数据时。插值允许我们估计间隙内的值。
在上面的 resize() 函数中,插值标志确定用于计算目标图像大小的插值类型。
插值类型
插值的类型如下 -
INTER_NEAREST - 最近邻插值。
INTER_LINEAR - 双线性插值(默认使用)
INTER_AREA - 使用像素区域关系重新采样。它是图像抽取的首选方法,但当图像缩放时,它类似于 INTER_NEAREST 方法。
INTER_CUBIC - 4x4 像素邻域的双三次插值
INTER_LANCZOS4 - 8x8 像素邻域的 Lanczos 插值
首选插值方法是用于缩小的 cv2.INTER_AREA 和用于缩放的 cv2.INTER_CUBIC(慢)和 cv2.INTER_LINEAR。
例子
以下代码将“messi.jpg”图像的大小调整为其原始高度和宽度的一半。
import numpy as np
import cv2
img = cv2.imread('messi.JPG',1)
height, width = img.shape[:2]
res = cv2.resize(img,(int(width/2), int(height/2)), interpolation =
cv2.INTER_AREA)
cv2.imshow('image',res)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出

旋转图像
OpenCV 使用仿射变换函数对图像进行平移和旋转等操作。仿射变换是一种可以用矩阵乘法(线性变换)和向量加法(平移)的形式表示的变换。
cv2 模块提供了两个函数cv2.warpAffine和cv2.warpPerspective,您可以使用它们进行各种转换。cv2.warpAffine 采用 2x3 变换矩阵,而 cv2.warpPerspective 采用 3x3 变换矩阵作为输入。
为了找到用于旋转的变换矩阵,OpenCV 提供了一个函数cv2.getRotationMatrix2D,如下所示 -
getRotationMatrix2D(center, angle, scale)
然后,我们将warpAffine函数应用于 getRotationMatrix2D() 函数返回的矩阵以获得旋转图像。
以下程序将原始图像旋转 90 度而不改变尺寸 -
例子
import numpy as np
import cv2
img = cv2.imread('OpenCV_Logo.png',1)
h, w = img.shape[:2]
center = (w / 2, h / 2)
mat = cv2.getRotationMatrix2D(center, 90, 1)
rotimg = cv2.warpAffine(img, mat, (h, w))
cv2.imshow('original',img)
cv2.imshow('rotated', rotimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出
原始图像

旋转图像

OpenCV Python - 图像阈值
在数字图像处理中,阈值处理是基于像素强度阈值创建二值图像的过程。阈值处理将前景像素与背景像素分开。
OpenCV 提供了执行简单、自适应和Otsu阈值的函数。
在简单阈值处理中,所有值小于阈值的像素都设置为零,其余为最大像素值。这是最简单的阈值形式。
cv2.threshold ()函数具有以下定义。
cv2.threshold((src, thresh, maxval, type, dst)
参数
图像阈值处理的参数如下 -
- Src:输入数组。
- Dst:相同大小的输出数组。
- 阈值:阈值。
- Maxval:最大值。
- 类型:阈值类型。
阈值类型
其他类型的阈值列举如下 -
| 先生编号 | 类型与功能 |
|---|---|
| 1 | CV.THRESH_BINARY dst(x,y) = maxval 如果 src(x,y)>thresh 0 否则 |
| 2 | CV.THRESH_BINARY_INV dst(x,y)=0 如果 src(x,y)>thresh maxval 否则 |
| 3 | CV.THRESH_TRUNC dst(x,y)=阈值 如果 src(x,y)>阈值 src(x,y) 否则 |
| 4 | CV.THRESH_TOZERO dst(x,y)=src(x,y) 如果 src(x,y)>thresh 0 否则 |
| 5 | CV.THRESH_TOZERO_INV dst(x,y)=0 如果 src(x,y)> 阈值 src(x,y) 否则 |
这些阈值类型根据下图对输入图像进行操作 -

Threshold() 函数返回使用的阈值和阈值图像。
以下程序通过将阈值设置为 127,从原始图像生成灰度值从 255 到 0 的梯度的二值图像。
例子
使用 Matplotlib 库并排绘制原始阈值二值图像和生成的阈值二值图像。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('gradient.png',0)
ret,img1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
plt.subplot(2,3,1),plt.imshow(img,'gray',vmin=0,vmax=255)
plt.title('Original')
plt.subplot(2,3,2),plt.imshow(img1,'gray',vmin=0,vmax=255)
plt.title('Binary')
plt.show()
输出

自适应阈值根据像素周围的小区域确定像素的阈值。因此,同一图像的不同区域获得不同的阈值。这可以为具有不同照明的图像提供更好的结果。
cv2.adaptiveThreshold() 方法采用以下输入参数 -
cv.adaptiveThreshold( src, maxValue, adaptiveMethod, thresholdType, blockSize, C[, dst] )
AdaptiveMethod 有以下枚举值 -
cv.ADAPTIVE_THRESH_MEAN_C - 阈值是邻域区域的平均值减去常数 C。
cv.ADAPTIVE_THRESH_GAUSSIAN_C - 阈值是邻域值的高斯加权和减去常数 C。
例子
在下面的示例中,原始图像(messi.jpg)应用了均值和高斯自适应阈值。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('messi.jpg',0)
img = cv.medianBlur(img,5)
th1 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\
cv.THRESH_BINARY,11,2)
th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv.THRESH_BINARY,11,2)
titles = ['Original', 'Mean Thresholding', 'Gaussian Thresholding']
images = [img, th1, th2]
for i in range(3):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
输出
使用 matplotlib 绘制原始和自适应阈值二进制图像,如下所示 -

例子
OTSU 算法根据图像直方图自动确定阈值。除了 THRESH-BINARY 标志之外,我们还需要传递 cv.THRES_OTSU 标志。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('messi.jpg',0)
# global thresholding
ret1,img1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu's thresholding
ret2,img2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
plt.subplot(2,2,1),plt.imshow(img,'gray',vmin=0,vmax=255)
plt.title('Original')
plt.subplot(2,2,2),plt.imshow(img1,'gray')
plt.title('Binary')
plt.subplot(2,2,3),plt.imshow(img2,'gray')
plt.title('OTSU')
plt.show()
输出
matplotlib 的绘图结果如下 -

OpenCV Python - 图像过滤
图像基本上是由对应于灰度值的 0 到 255 之间的二进制值表示的像素矩阵。彩色图像是一个三维矩阵,具有多个与 RGB 相对应的通道。
图像过滤是对像素值进行平均以改变原始图像的阴影、亮度、对比度等的过程。
通过应用低通滤波器,我们可以消除图像中的任何噪声。高通滤波器有助于检测边缘。
OpenCV库提供了cv2.filter2D()函数。它通过大小为 3X3 或 5X5 等的方阵的核对原始图像进行卷积。
卷积使核矩阵在图像矩阵上水平和垂直滑动。对于每个位置,添加内核下的所有像素,取内核下像素的平均值,并用平均值替换中心像素。
对所有像素执行此操作即可获得输出图像像素矩阵。请参阅下面给出的图表 -
cv2.filter2D() 函数需要输入数组、核矩阵和输出数组参数。
例子
下图使用该函数获得二维卷积结果的平均图像。其程序如下 -
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('opencv_logo_gs.png')
kernel = np.ones((3,3),np.float32)/9
dst = cv.filter2D(img,-1,kernel)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Convolved')
plt.xticks([]), plt.yticks([])
plt.show()
输出
过滤功能的类型
OpenCV 中其他类型的过滤功能包括 -
BioralFilter - 减少不需要的噪音,保持边缘完整。
BoxFilter - 这是一个平均模糊操作。
GaussianBlur - 消除高频内容,例如噪声和边缘。
MedianBlur - 它不是平均值,而是取内核下所有像素的中值并替换中心值。
OpenCV Python - 边缘检测
这里的边缘是指图像中物体的边界。OpenCV 有一个cv2.Canny()函数,通过实现 Canny 算法来识别图像中各种对象的边缘。
Canny 边缘检测算法由 John Canny 开发。据此,对象的边缘是通过执行以下步骤来确定的 -
第一步是减少图像中的噪声像素。这是通过应用 5X5 高斯滤波器来完成的。
第二步涉及找到图像的强度梯度。第一阶段的平滑图像通过应用Sobel算子进行滤波以获得水平和垂直方向的一阶导数(G x和G y)。
均方根值给出边缘梯度,导数的 tan 反比给出边缘方向。
$$\mathrm{边缘梯度\:G\:=\:\sqrt{G_x^2+G_y^2}}$$
$$\mathrm{角度\:\theta\:=\:\tan^{-1}(\frac{G_{y}}{G_{x}})}$$
获得梯度大小和方向后,对图像进行全面扫描,以删除可能不构成边缘的任何不需要的像素。
下一步是使用 minval 和 maxval 阈值执行滞后阈值。小于 minval 和 maxval 的强度梯度是非边缘,因此被丢弃。介于两者之间的点根据其连通性被视为边缘点或非边缘。
所有这些步骤都是由 OpenCV 的 cv2.Canny() 函数执行,该函数需要输入图像数组以及 minval 和 maxval 参数。
例子
这是精明边缘检测的示例。其程序如下 -
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('lena.jpg', 0)
edges = cv.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edges of original Image'), plt.xticks([]), plt.yticks([])
plt.show()
输出

OpenCV Python - 直方图
直方图显示图像中的强度分布。它在 X 轴上绘制像素值(0 到 255),在 Y 轴上绘制像素数。
通过使用直方图,可以了解指定图像的对比度、亮度和强度分布。直方图中的 bin 表示 X 轴上值的增量部分。
在我们的例子中,它是像素值,默认的 bin 大小是 1。
在 OpenCV 库中,函数cv2.calcHist()函数根据输入图像计算直方图。该功能的命令如下 -
cv.calcHist(images, channels, mask, histSize, ranges)
参数
cv2.calcHist ()函数的参数如下 -
images - 它是 uint8 或 float32 类型的源图像,位于方括号中,即“[img]”。
Channels - 它是我们计算直方图的通道的索引。对于灰度图像,其值为[0]。对于BGR图像,可以通过[0]、[1]或[2]来计算每个通道的直方图。
mask - 对于完整图像,掩模图像被指定为“无”。对于图像的特定区域,您必须为其创建蒙版图像并将其作为蒙版。
histSize - 这代表我们的 BIN 计数。
范围- 通常为 [0,256]。
使用 Matplotlib 绘制直方图
可以借助 Matplotlib 的pyplot.plot()函数或调用OpenCV 库中的Polylines()函数来获得直方图。
例子
以下程序计算图像(lena.jpg)中每个通道的直方图并绘制每个通道的强度分布 -
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('lena.jpg')
color = ('b','g','r')
for i,col in enumerate(color):
hist = cv.calcHist([img],[i],None,[256],[0,256])
plt.plot(hist, color = col)
plt.xlim([0,256])
plt.show()
输出

OpenCV Python - 颜色空间
颜色空间是描述如何表示颜色的数学模型。它以特定的、可测量的和固定的可能颜色和亮度值范围来描述。
OpenCV 支持以下众所周知的颜色空间 -
RGB 颜色空间- 它是一个加法颜色空间。颜色值是通过红、绿、蓝颜色值的组合获得的。每个都由 0 到 255 之间的数字表示。
HSV 色彩空间- H、S 和 V 代表色调、饱和度和值。这是 RGB 的替代颜色模型。该模型应该更接近人眼感知颜色的方式。色调值在 0 到 179 之间,而 S 和 V 值在 0 到 255 之间。
CMYK 颜色空间- 与 RGB 不同,CMYK 是减色模型。字母代表青色、洋红色、黄色和黑色。白光减去红色,叶子变成青色,白色减去绿色,叶子变成洋红色,白色减去蓝色,叶子变成黄色。所有值均以 0 至 100% 的范围表示。
CIELAB 色彩空间- LAB 色彩空间具有三个分量,L 表示亮度,A 颜色分量范围从绿色到洋红色,B 表示从蓝色到黄色的分量。
YCrCb 颜色空间- 这里,Cr 代表 RY,Cb 代表 BY。这有助于将亮度和色度分离到不同的通道中。
OpenCV 借助cv2.cvtColor()函数支持颜色空间之间的图像转换。
cv2.cvtColor() 函数的命令如下 -
cv.cvtColor(src, code, dst)
转换代码
转换由以下预定义的转换代码控制。
| 先生。 | 转换代码及功能 |
|---|---|
| 1 | CV.COLOR_BGR2BGRA 将 Alpha 通道添加到 RGB 或 BGR 图像。 |
| 2 | CV.COLOR_BGRA2BGR 从 RGB 或 BGR 图像中删除 Alpha 通道。 |
| 3 | CV.COLOR_BGR2GRAY RGB/BGR 和灰度之间进行转换。 |
| 4 | CV.COLOR_BGR2YCrCb 将 RGB/BGR 转换为亮度-色度 |
| 5 | 变种COLOR_BGR2HSV 将 RGB/BGR 转换为 HSV |
| 6 | CV.COLOR_BGR2Lab 将 RGB/BGR 转换为 CIE Lab |
| 7 | 变种COLOR_HSV2BGR HSV 向后转换为 RGB/BGR |
例子
以下程序显示了将 RGB 颜色空间的原始图像转换为 HSV 和灰度方案 -
import cv2
img = cv2.imread('messi.jpg')
img1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY )
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# Displaying the image
cv2.imshow('original', img)
cv2.imshow('Gray', img1)
cv2.imshow('HSV', img2)
输出



OpenCV Python - 形态转换
基于图像形状对图像进行的简单操作称为形态变换。两种最常见的变换是腐蚀和膨胀。
侵蚀
侵蚀消除了前景对象的边界。与 2D 卷积类似,核在图像 A 上滑动。如果核下的所有像素均为 1,则保留原始图像中的像素。
否则,它被设为 0,从而导致腐蚀。边界附近的所有像素都被丢弃。此过程对于消除白噪声很有用。
OpenCV 中erode()函数的命令如下 -
cv.erode(src, kernel, dst, anchor, iterations)
参数
OpenCV 中的 erode() 函数使用以下参数-
src 和 dst 参数是相同大小的输入和输出图像数组。内核是用于侵蚀的结构元素的矩阵。例如,3X3 或 5X5。
锚点参数默认为-1,这意味着锚点元素位于中心。迭代是指应用侵蚀的次数。
扩张
它与侵蚀正好相反。这里,如果内核下至少有一个像素为 1,则像素元素为 1。因此,它增加了图像中的白色区域。
dilate() 函数的命令如下 -
cv.dilate(src, kernel, dst, anchor, iterations)
参数
dilate ()函数具有与 erode() 函数相同的参数。这两个函数都可以有额外的可选参数,如 BorderType 和 borderValue。
BorderType 是图像边界的枚举类型(CONSTANT、REPLICATE、TRANSPERANT 等)
borderValue 用于边界恒定的情况。默认情况下,它是 0。
例子
下面给出了一个示例程序,显示了 erode() 和 dilate() 函数的使用 -
import cv2 as cv
import numpy as np
img = cv.imread('LinuxLogo.jpg',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv.erode(img,kernel,iterations = 1)
dilation = cv.dilate(img,kernel,iterations = 1)
cv.imshow('Original', img)
cv.imshow('Erosion', erosion)
cv.imshow('Dialation', dilation)
输出
原始图像
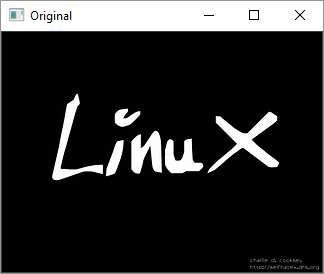
侵蚀
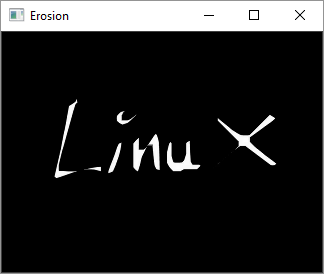
扩张
OpenCV Python - 图像轮廓
轮廓是沿着边界连接具有相同颜色或强度的所有连续点的曲线。轮廓对于形状分析和物体检测非常有用。
寻找轮廓
在找到轮廓之前,我们应该应用阈值或精明的边缘检测。然后,通过使用findContours()方法,我们可以找到二值图像中的轮廓。
findContours()函数的使用命令如下 -
cv.findContours(image, mode, method, contours)
参数
findContours()函数的参数如下 -
- image - 源,8 位单通道图像。
- mode - 轮廓检索模式。
- method - 轮廓近似法。
模式参数的值枚举如下 -
cv.RETR_EXTERNAL - 仅检索最外轮廓。
cv.RETR_LIST - 检索所有轮廓而不建立任何层次关系。
cv.RETR_CCOMP - 检索所有轮廓并将它们组织成两级层次结构。
cv.RETR_TREE - 检索所有轮廓并重建嵌套轮廓的完整层次结构。
另一方面,近似方法可以是以下之一 -
cv.CHAIN_APPROX_NONE - 绝对存储所有轮廓点。
cv.CHAIN_APPROX_SIMPLE - 压缩水平、垂直和对角线段并仅保留其端点。
绘制轮廓
检测到轮廓向量后,使用cv.drawContours()函数在原始图像上绘制轮廓。
cv.drawContours() 函数的命令如下 -
cv.drawContours(image, contours, contourIdx, color)
参数
drawContours()函数的参数如下 -
- 图像 - 目标图像。
- 轮廓 - 所有输入轮廓。每个轮廓都存储为点向量。
- contourIdx - 指示要绘制的轮廓的参数。如果为负,则绘制所有轮廓。
- color - 轮廓的颜色。
例子
以下代码是在输入图像上绘制轮廓的示例,该输入图像具有三个填充黑色的形状。
第一步,我们获得灰度图像,然后进行canny边缘检测。
在生成的图像上,我们调用 findContours() 函数。其结果是一个点向量。然后我们调用drawContours()函数。
完整代码如下 -
import cv2
import numpy as np
img = cv2.imread('shapes.png')
cv2.imshow('Original', img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
canny = cv2.Canny(gray, 30, 200)
contours, hierarchy = cv2.findContours(canny,
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
print("Number of Contours = " ,len(contours))
cv2.imshow('Canny Edges', canny)
cv2.drawContours(img, contours, -1, (0, 255, 0), 3)
cv2.imshow('Contours', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出
经过精明的边缘检测和绘制轮廓的原始图像将显示在单独的窗口中,如下所示 -

经过精明的边缘检测后,图像将如下 -

绘制轮廓后,图像如下 -

OpenCV Python - 模板匹配
模板匹配技术用于检测图像中与样本或模板图像匹配的一个或多个区域。
OpenCV 中的Cv.matchTemplate()函数就是为此目的而定义的,其命令如下:
cv.matchTemplate(image, templ, method)
其中 image 是 templ(模板)图案所在的输入图像。方法参数采用以下值之一 -
- CV.TM_CCOEFF,
- CV.TM_CCOEFF_NORMED、CV.TM_CCORR、
- CV.TM_CCORR_NORMED,
- CV.TM_SQDIFF,
- CV.TM_SQDIFF_NORMED
此方法将模板图像滑动到输入图像上。这是与卷积类似的过程,比较模板图像和模板图像下的输入图像的块。
它返回一个灰度图像,其每个像素表示它与模板的匹配程度。如果输入图像的尺寸为 (WxH),模板图像的尺寸为 (wxh),则输出图像的尺寸将为 (W-w+1, H-h+1)。因此,该矩形就是您的模板区域。
例子
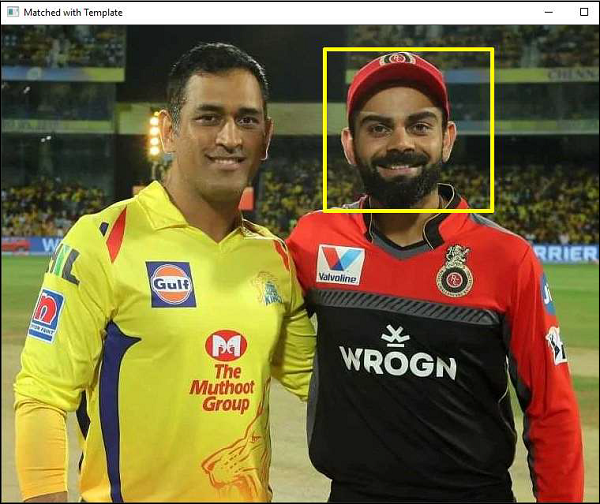
在下面的示例中,具有印度板球运动员 Virat Kohli 脸部的图像被用作模板,以与描绘他与另一位印度板球运动员 MSDhoni 的照片的另一张图像进行匹配。
以下程序使用 80% 的阈值并在匹配的脸部周围绘制一个矩形 -
import cv2
import numpy as np
img = cv2.imread('Dhoni-and-Virat.jpg',1)
cv2.imshow('Original',img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
template = cv2.imread('virat.jpg',0)
cv2.imshow('Template',template)
w,h = template.shape[0], template.shape[1]
matched = cv2.matchTemplate(gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( matched >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img, pt, (pt[0] + w, pt[1] + h), (0,255,255), 2)
cv2.imshow('Matched with Template',img)
输出
原始图像、模板和结果的匹配图像如下 -
原图

模板如下-

与模板匹配时的图像如下 -
OpenCV Python - 图像Pyramid
有时,我们可能需要将图像转换为与其原始尺寸不同的尺寸。为此,您可以放大图像(放大)或缩小图像(缩小)。
图像Pyramid是连续下采样指定次数的图像集合(由单个原始图像构建)。
高斯Pyramid用于对图像进行下采样,而拉普拉斯Pyramid则从Pyramid中较低分辨率的图像重建上采样图像。
将Pyramid视为一组层。图像如下所示 -

Pyramid较高层的图像尺寸较小。为了在高斯Pyramid的下一层生成图像,我们将较低级别的图像与高斯核进行卷积。
$$\frac{1}{16}\begin{bmatrix}1 & 4 & 6 & 4 & 1 \\4 & 16 & 24 & 16 & 4 \\6 & 24 & 36 & 24 & 6 \\4 & 16 & 24 & 16 & 4 \\1 & 4 & 6 & 4 & 1\end{bmatrix}$$
现在删除所有偶数行和列。生成的图像将是其前一个图像面积的 1/4。在原始图像上迭代此过程会生成整个Pyramid。
为了使图像更大,列中填充了零。首先,使用新的偶数行扩大图像的大小,使其在每个维度上都是原始图像的两倍,然后与内核执行卷积以近似丢失像素的值。
cv.pyrUp ()函数将原始大小加倍,而cv.pyrDown()函数将其减小到一半。
例子
以下程序分别根据用户输入“I”或“o”调用pyrUp() 和pyrDown() 函数。
请注意,当我们缩小图像的大小时,图像的信息就会丢失。有一次,我们缩小尺寸,如果将其重新缩放到原始尺寸,我们会丢失一些信息,并且新图像的分辨率比原始图像低得多。
import sys
import cv2 as cv
filename = 'chicky_512.png'
src = cv.imread(filename)
while 1:
print ("press 'i' for zoom in 'o' for zoom out esc to stop")
rows, cols, _channels = map(int, src.shape)
cv.imshow('Pyramids', src)
k = cv.waitKey(0)
if k == 27:
break
elif chr(k) == 'i':
src = cv.pyrUp(src, dstsize=(2 * cols, 2 * rows))
elif chr(k) == 'o':
src = cv.pyrDown(src, dstsize=(cols // 2, rows // 2))
cv.destroyAllWindows()
输出



OpenCV Python - 图像相加
当通过 imread() 函数读取图像时,生成的图像对象实际上是二维或三维矩阵,具体取决于图像是灰度图像还是 RGB 图像。
因此,cv2.add()函数将两个图像矩阵相加并返回另一个图像矩阵。
例子
以下代码读取两个图像并执行它们的二进制加法 -
kalam = cv2.imread('kalam.jpg')
einst = cv2.imread('einstein.jpg')
img = cv2.add(kalam, einst)
cv2.imshow('addition', img)
结果

OpenCV 有一个addWeighted()函数,而不是线性二进制加法,它执行两个数组的加权和。其命令如下
Cv2.addWeighted(src1, alpha, src2, beta, gamma)
参数
addWeighted()函数的参数如下 -
- src1 - 第一个输入数组。
- alpha - 第一个数组元素的权重。
- src2 - 第二个输入数组的大小和通道数与第一个相同
- beta - 第二个数组元素的权重。
- gamma - 添加到每个总和的标量。
该函数按照以下等式添加图像 -
$$\mathrm{g(x)=(1-\alpha)f_{0}(x)+\alpha f_{1}(x)}$$
利用上例得到的图像矩阵进行加权求和。
通过改变 a 从 0 -> 1,可以从一幅图像平滑过渡到另一幅图像,从而使它们混合在一起。
第一个图像的权重为 0.3,第二个图像的权重为 0.7。伽玛因子取0。
addWeighted()函数的命令如下 -
img = cv2.addWeighted(kalam, 0.3, einst, 0.7, 0)
可以看出,图像相加相比二值相加更加平滑。

OpenCV Python - 使用Pyramid进行图像混合
通过使用图像Pyramid可以最小化图像的不连续性。这会产生无缝混合图像。
采取以下步骤来实现最终结果 -
首先加载图像并找到两者的高斯Pyramid。其程序如下 -
import cv2
import numpy as np,sys
kalam = cv2.imread('kalam.jpg')
einst = cv2.imread('einstein.jpg')
### generate Gaussian pyramid for first
G = kalam.copy()
gpk = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpk.append(G)
# generate Gaussian pyramid for second
G = einst.copy()
gpe = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpe.append(G)
从高斯Pyramid中,获得相应的拉普拉斯Pyramid。其程序如下 -
# generate Laplacian Pyramid for first lpk = [gpk[5]] for i in range(5,0,-1): GE = cv2.pyrUp(gpk[i]) L = cv2.subtract(gpk[i-1],GE) lpk.append(L) # generate Laplacian Pyramid for second lpe = [gpe[5]] for i in range(5,0,-1): GE = cv2.pyrUp(gpe[i]) L = cv2.subtract(gpe[i-1],GE) lpe.append(L)
然后,在每一层Pyramid中将第一张图像的左半部分与第二张图像的右半部分连接起来。其程序如下 -
# Now add left and right halves of images in each level LS = [] for la,lb in zip(lpk,lpe): rows,cols,dpt = la.shape ls = np.hstack((la[:,0:int(cols/2)], lb[:,int(cols/2):])) LS.append(ls)
最后,从这个联合Pyramid重建图像。下面给出了相同的程序 -
ls_ = LS[0]
for i in range(1,6):
ls_ = cv2.pyrUp(ls_)
ls_ = cv2.add(ls_, LS[i])
cv2.imshow('RESULT',ls_)
输出
混合结果应如下 -

OpenCV Python - 傅里叶变换
傅里叶变换用于通过将图像分解为正弦和余弦分量来将图像从空间域变换到频域。
在数字图像的情况下,基本灰度图像值通常在0和255之间。因此,傅里叶变换也需要是离散傅里叶变换(DFT)。它用于查找频域。
在数学上,二维图像的傅里叶变换表示如下 -
$$\mathrm{F(k,l)=\displaystyle\sum\limits_{i=0}^{N-1}\: \displaystyle\sum\limits_{j=0}^{N-1} f( i,j)\:e^{-i2\pi (\frac{ki}{N},\frac{lj}{N})}}$$
如果幅度在短时间内变化如此之快,则可以说它是高频信号。如果变化缓慢,则为低频信号。
对于图像,幅度在边缘点或噪声处变化很大。因此,边缘和噪声是图像中的高频内容。如果幅度没有太大变化,则它是低频分量。
为此,OpenCV 提供了函数cv.dft()和cv.idft() 。
cv.dft() 对 1D 或 2D 浮点数组执行离散傅里叶变换。其命令如下 -
cv.dft(src, dst, flags)
这里,
- src - 输入数组可以是实数或复数。
- dst - 输出数组,其大小和类型取决于标志。
- flags - 转换标志,表示 DftFlags 的组合。
cv.idft() 计算一维或二维数组的逆离散傅立叶变换。其命令如下 -
cv.idft(src, dst, flags)
为了获得离散傅里叶变换,输入图像被转换为 np.float32 数据类型。然后使用获得的变换将零频率分量移动到频谱的中心,从中计算幅度谱。
例子
下面给出的是使用 Matplotlib 的程序,我们绘制原始图像和幅度谱 -
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('lena.jpg',0)
dft = cv.dft(np.float32(img),flags = cv.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20*np.log(cv.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
输出

OpenCV Python - 从相机捕获视频
通过使用OpenCV 库中的VideoCapture()函数,可以非常轻松地在 OpenCV 窗口上从摄像机捕获实时流。
该函数需要一个设备索引作为参数。您的计算机可能连接了多个摄像头。对于内置网络摄像头,它们通过从 0 开始的索引进行枚举。该函数返回一个VideoCapture对象
cam = cv.VideoCapture(0)
打开相机后,我们可以借助read()函数从中读取连续的帧
ret,frame = cam.read()
read() 函数读取下一个可用帧和返回值(True/False)。现在使用cvtColor()函数在所需的颜色空间中渲染该帧并显示在 OpenCV 窗口上。
img = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
# Display the resulting frame
cv.imshow('frame', img)
要将当前帧捕获到图像文件,可以使用imwrite()函数。
cv2.imwrite(“capture.png”, img)
为了将来自摄像机的实时流保存到视频文件,OpenCV 提供了 VideoWriter() 函数。
cv.VideoWriter( filename, fourcc, fps, frameSize)
fourcc 参数是视频编解码器的标准化代码。OpenCV 支持各种编解码器,例如 DIVX、XVID、MJPG、X264 等。 fps 和帧大小参数取决于视频捕获设备。
VideoWriter() 函数返回一个 VideoWrite 流对象,在循环中将抓取的帧连续写入该对象。最后,释放frame和VideoWriter对象,完成视频的创建。
例子
以下示例从内置网络摄像头读取实时源并将其保存到 ouput.avi 文件。
import cv2 as cv
cam = cv.VideoCapture(0)
cc = cv.VideoWriter_fourcc(*'XVID')
file = cv.VideoWriter('output.avi', cc, 15.0, (640, 480))
if not cam.isOpened():
print("error opening camera")
exit()
while True:
# Capture frame-by-frame
ret, frame = cam.read()
# if frame is read correctly ret is True
if not ret:
print("error in retrieving frame")
break
img = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
cv.imshow('frame', img)
file.write(img)
if cv.waitKey(1) == ord('q'):
break
cam.release()
file.release()
cv.destroyAllWindows()
OpenCV Python - 从文件播放视频
VideoCapture ()函数还可以从视频文件而不是摄像机中检索帧。因此,我们仅将摄像机索引替换为要在 OpenCV 窗口上播放的视频文件的名称。
video=cv2.VideoCapture(file)
虽然这应该足以开始渲染视频文件,如果它伴随着声音。声音不会一起播放。为此,您需要安装 ffpyplayer 模块。
FFPy播放器
FFPyPlayer是 FFmpeg 库的 python 绑定,用于播放和写入媒体文件。要安装,请使用以下命令使用 pip installer 实用程序。
pip3 install ffpyplayer
该模块中 MediaPlayer 对象的get_frame ()方法返回音频帧,该音频帧将与从视频文件读取的每个帧一起播放。
以下是播放视频文件及其音频的完整代码 -
import cv2
from ffpyplayer.player import MediaPlayer
file="video.mp4"
video=cv2.VideoCapture(file)
player = MediaPlayer(file)
while True:
ret, frame=video.read()
audio_frame, val = player.get_frame()
if not ret:
print("End of video")
break
if cv2.waitKey(1) == ord("q"):
break
cv2.imshow("Video", frame)
if val != 'eof' and audio_frame is not None:
#audio
img, t = audio_frame
video.release()
cv2.destroyAllWindows()
OpenCV Python - 从视频中提取图像
视频只不过是一系列帧,每个帧都是一个图像。通过使用 OpenCV,可以通过执行imwrite()函数提取组成视频文件的所有帧,直到视频结束。
cv2.read ()函数返回下一个可用帧。该函数还给出了一个