模糊逻辑 - 快速指南
模糊逻辑 - 简介
模糊一词指的是不明确或模糊的事物。任何持续变化的事件、过程或功能不能总是被定义为真或假,这意味着我们需要以模糊的方式定义此类活动。
什么是模糊逻辑?
模糊逻辑类似于人类决策方法。它处理模糊和不精确的信息。这是对现实世界问题的严重过度简化,并且基于真实程度,而不是像布尔逻辑那样通常的真/假或 1/0。
看一下下图。它表明,在模糊系统中,值由0到1范围内的数字表示。这里1.0代表绝对真值,0.0代表绝对假值。模糊系统中表示数值的数字称为真值。

换句话说,我们可以说模糊逻辑不是模糊的逻辑,而是用来描述模糊性的逻辑。类似的例子还有很多,我们可以借助它们来理解模糊逻辑的概念。
模糊逻辑由 Lofti A. Zadeh 于 1965 年在他的研究论文“模糊集”中提出。他被认为是模糊逻辑之父。
模糊逻辑 - 经典集合论
集合是不同元素的无序集合。可以通过使用设置括号列出其元素来显式地编写它。如果元素的顺序发生更改或集合中的任何元素重复,则不会对集合进行任何更改。
例子
- 所有正整数的集合。
- 太阳系中所有行星的集合。
- 印度所有州的集合。
- 字母表中所有小写字母的集合。
集合的数学表示
集合可以用两种方式表示 -
名册或表格形式
在这种形式中,集合通过列出组成它的所有元素来表示。元素括在大括号内并用逗号分隔。
以下是以名册或表格形式设置的示例 -
- 英语字母表中的一组元音,A = {a,e,i,o,u}
- 小于 10 的奇数集合,B = {1,3,5,7,9}
集合生成器符号
在这种形式中,集合是通过指定集合元素所共有的属性来定义的。该集合被描述为 A = {x:p(x)}
示例 1 - 集合 {a,e,i,o,u} 写为
A = {x:x 是英文字母中的元音}
示例 2 - 集合 {1,3,5,7,9} 写为
B = {x:1 ≤ x < 10 且 (x%2) ≠ 0}
如果元素 x 是任意集合 S 的成员,则用 x∈S 表示,如果元素 y 不是集合 S 的成员,则用 y∉S 表示。
示例- 如果 S = {1,1.2,1.7,2},1 ∈ S 但 1.5 ∉ S
集合的基数
集合 S 的基数,用 |S||S| 表示,是集合中元素的数量。该数字也称为基数。如果一个集合有无限多个元素,则它的基数为 ∞ 。
示例- |{1,4,3,5}| = 4,|{1,2,3,4,5,…}| = 无穷大
如果有两个集合X和Y,|X| =|Y| 表示具有相同基数的两个集合 X 和 Y。当 X 中的元素数量恰好等于 Y 中的元素数量时,就会发生这种情况。在这种情况下,存在从 X 到 Y 的双射函数“f”。
|X| ≤|Y| 表示集合 X 的基数小于或等于集合 Y 的基数。当 X 中的元素数量小于或等于 Y 中的元素数量时,就会发生这种情况。这里,存在从 X 到 Y 的单射函数“f”。
|X| <|Y| 表示集合 X 的基数小于集合 Y 的基数。当 X 中的元素数量小于 Y 中的元素数量时,就会发生这种情况。这里,从 X 到 Y 的函数“f”是单射函数,但不是双射函数。
如果|X| ≤|Y| 和|X| ≤|Y| 然后|X| =|Y| 。集合 X 和 Y 通常称为等价集合。
套装类型
集合可以分为很多种;其中一些是有限集、无限集、子集、全集、真集、单例集等。
有限集
包含一定数量元素的集合称为有限集合。
示例- S = {x|x ∈ N 且 70 > x > 50}
无限集
包含无限个元素的集合称为无限集。
示例- S = {x|x ∈ N 且 x > 10}
子集
如果 X 的每个元素都是集合 Y 的元素,则集合 X 是集合 Y 的子集(写为 X ⊆ Y)。
示例 1 - 令 X = {1,2,3,4,5,6} 且 Y = {1,2}。这里集合Y是集合X的子集,因为集合Y的所有元素都在集合X中。因此,我们可以写成Y⊆X。
示例 2 - 令 X = {1,2,3} 且 Y = {1,2,3}。这里集合Y是集合X的子集(不是真子集),因为集合Y的所有元素都在集合X中。因此,我们可以写成Y⊆X。
真子集
术语“真子集”可以定义为“但不等于”的子集。如果 X 的每个元素都是集合 Y 的元素且 |X| ,则集合 X 是集合 Y 的真子集(写为 X ⊂ Y)<|Y|。
示例- 设 X = {1,2,3,4,5,6} 且 Y = {1,2}。这里集合 Y ⊂ X,因为 Y 中的所有元素也包含在 X 中,并且 X 至少有一个元素比集合 Y 多。
通用套装
它是特定上下文或应用程序中所有元素的集合。该上下文或应用程序中的所有集合本质上都是该通用集合的子集。通用集表示为 U。
示例- 我们可以将 U 定义为地球上所有动物的集合。在这种情况下,所有哺乳动物的集合是 U 的子集,所有鱼类的集合是 U 的子集,所有昆虫的集合是 U 的子集,依此类推。
空集或零集
空集不包含任何元素。用Φ表示。由于空集的元素个数是有限的,所以空集是有限集。空集或空集的基数为零。
示例– S = {x|x ∈ N 且 7 < x < 8} = Φ
单例集或单元集
单例集或单元集仅包含一个元素。单例集用 {s} 表示。
示例- S = {x|x ∈ N, 7 < x < 9} = {8}
等集
如果两个集合包含相同的元素,则称它们相等。
示例- 如果 A = {1,2,6} 且 B = {6,1,2},则它们相等,因为集合 A 的每个元素都是集合 B 的元素,集合 B 的每个元素都是集合 A 的元素。
等效组
如果两个集合的基数相同,则称它们为等价集合。
示例- 如果 A = {1,2,6} 且 B = {16,17,22},则它们等价,因为 A 的基数等于 B 的基数。即 |A| =|B| = 3
重叠集
至少有一个公共元素的两个集合称为重叠集合。如果集合重叠 -
$$n\left ( A\cup B \right ) = n\left ( A \right ) + n\left ( B \right ) - n\left ( A\cap B \right )$$
$$n\left ( A\cup B \right ) = n\left ( AB \right )+n\left ( BA \right )+n\left ( A\cap B \right )$$
$$n\left ( A \right ) = n\left ( AB \right )+n\left ( A\cap B \right )$$
$$n\left ( B \right ) = n\left ( BA \right )+n\left ( A\cap B \right )$$
示例- 设 A = {1,2,6} 且 B = {6,12,42}。有一个公共元素“6”,因此这些集合是重叠集合。
不相交集
如果两个集合 A 和 B 甚至没有一个共同元素,则这两个集合称为不相交集合。因此,不相交集具有以下属性 -
$$n\left ( A\cap B \right ) = \phi$$
$$n\left ( A\cup B \right ) = n\left ( A \right )+n\left ( B \right )$$
示例- 设 A = {1,2,6} 且 B = {7,9,14},没有单个公共元素,因此这些集合是重叠集合。
经典集合的运算
集合运算包括集合并、集合交、集合差、集合补和笛卡尔积。
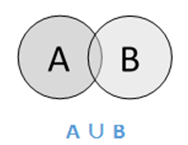
联盟
集合 A 和 B 的并集(表示为 A ∪ BA ∪ B)是 A 中、B 中或 A 和 B 中的元素的集合。因此,A ∪ B = {x|x ∈ A OR x ε B}。
示例- 如果 A = {10,11,12,13} 且 B = {13,14,15},则 A ∪ B = {10,11,12,13,14,15} – 公共元素仅出现一次。
路口
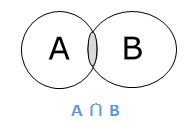
集合 A 和 B 的交集(记为 A ∩ B)是同时包含在 A 和 B 中的元素的集合。因此,A ∩ B = {x|x ∈ A AND x ∈ B}。
差异/相对互补
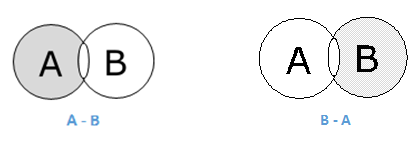
集合 A 和 B 的集合差(记为 A–B)是只在 A 中而不在 B 中的元素的集合。因此,A − B = {x|x ∈ A AND x ∉ B}。
示例- 如果 A = {10,11,12,13} 且 B = {13,14,15},则 (A − B) = {10,11,12} 且 (B − A) = {14,15 }。在这里,我们可以看到 (A − B) ≠ (B − A)
集合的补集
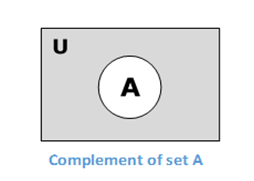
集合 A 的补集(记为 A')是不在集合 A 中的元素的集合。因此,A' = {x|x ∉ A}。
更具体地说,A' = (U−A),其中 U 是包含所有对象的通用集合。
示例- 如果 A = {x|x 属于加法整数集合},则 A′ = {y|y 不属于奇数整数集合}
笛卡尔积/叉积
n 个集合 A1,A2,…An 的笛卡尔积表示为 A1 × A2...× An 可以定义为所有可能的有序对 (x1,x2,…xn),其中 x1 ∈ A1,x2 ∈ A2,… xn ∈ An
示例- 如果我们采用两个集合 A = {a,b} 和 B = {1,2},
A 和 B 的笛卡尔积写为 − A × B = {(a,1),(a,2),(b,1),(b,2)}
并且,B 和 A 的笛卡尔积写为 − B × A = {(1,a),(1,b),(2,a),(2,b)}
经典集合的性质
集合的性质对于获得解决方案起着重要作用。以下是经典集合的不同属性 -
交换律
有两个集合A和B,该属性指出 -
$$A \cup B = B \cup A$$
$$A \cap B = B \cap A$$
关联属性
具有三个集合A、B和C,该属性指出 -
$$A\cup \left ( B\cup C \right ) = \left ( A\cup B \right )\cup C$$
$$A\cap \left ( B\cap C \right ) = \left ( A\cap B \right )\cap C$$
分配财产
具有三个集合A、B和C,该属性指出 -
$$A\cup \left ( B\cap C \right ) = \left ( A\cup B \right )\cap \left ( A\cup C \right )$$
$$A\cap \left ( B\cup C \right ) = \left ( A\cap B \right )\cup \left ( A\cap C \right )$$
幂等性
对于任何集合A,该属性表示 -
$$A\杯子A = A$$
$$A\上限 A = A$$
身份属性
对于集合A和通用集合X,该属性指出 -
$$A\cup \varphi = A$$
$$A\上限 X = A$$
$$A\cap \varphi = \varphi$$
$$A\cup X = X$$
传递性
具有三个集合A、B和C,该属性表示 -
如果 $A\subseteq B\subseteq C$,则 $A\subseteq C$
合合性
对于任何集合A,该属性表示 -
$$\overline{{\overline{A}}} = A$$
德摩根定律
它是证明同义反复和矛盾的一个非常重要的定律和支持。该法规定 -
$$\overline{A\cap B} = \overline{A} \cup \overline{B}$$
$$\overline{A\cup B} = \overline{A} \cap \overline{B}$$
模糊逻辑 - 集合论
模糊集可以被认为是经典集的扩展和总体过度简化。在集合成员资格的背景下可以最好地理解它。基本上它允许部分成员资格,这意味着它包含在集合中具有不同程度的成员资格的元素。由此,我们可以理解经典集合和模糊集合的区别。经典集合包含满足精确隶属属性的元素,而模糊集合包含满足不精确隶属属性的元素。
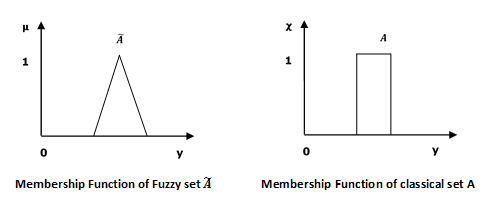
数学概念
信息域 $U$ 中的模糊集 $\widetilde{A}$ 可以定义为一组有序对,并且可以在数学上表示为 -
$$\widetilde{A} = \left \{ \left ( y,\mu _{\widetilde{A}} \left ( y \right ) \right ) | y\in U\right \}$$
这里 $\mu _{\widetilde{A}}\left ( y \right )$ = $y$ 在 \widetilde{A} 中的隶属度,假设值在 0 到 1 的范围内,即 $\mu _{\widetilde{A}}(y)\in \left [ 0,1 \right ]$。
模糊集的表示
现在让我们考虑信息域的两种情况,并了解如何表示模糊集。
情况1
当信息域 $U$ 是离散且有限的时 -
$$\widetilde{A} = \left \{ \frac{\mu _{\widetilde{A}}\left ( y_1 \right )}{y_1} +\frac{\mu _{\widetilde{A}} \left ( y_2 \right )}{y_2} +\frac{\mu _{\widetilde{A}}\left ( y_3 \right )}{y_3} +...\right \}$$
$= \left \{ \sum_{i=1}^{n}\frac{\mu _{\widetilde{A}}\left ( y_i \right )}{y_i} \right \}$
案例2
当信息宇宙 $U$ 是连续且无限时 -
$$\widetilde{A} = \left \{ \int \frac{\mu _{\widetilde{A}}\left ( y \right )}{y} \right \}$$
在上面的表示中,求和符号表示每个元素的集合。
模糊集的运算
具有两个模糊集 $\widetilde{A}$ 和 $\widetilde{B}$、信息域 $U$ 和域的元素 ð ',以下关系表示模糊上的并、交和补运算套。
联合/模糊“或”
让我们考虑以下表示来理解并集/模糊“OR”关系如何工作 -
$$\mu _{{\widetilde{A}\cup \widetilde{B} }}\left ( y \right ) = \mu _{\widetilde{A}}\vee \mu _\widetilde{B} \四元 \forall y \in U$$
这里∨代表“max”操作。

交叉点/模糊“AND”
让我们考虑以下表示来理解交集/模糊“AND”关系如何工作 -
$$\mu _{{\widetilde{A}\cap \widetilde{B} }}\left ( y \right ) = \mu _{\widetilde{A}}\wedge \mu _\widetilde{B} \四元 \forall y \in U$$
这里∧代表“min”操作。

补足/模糊“NOT”
让我们考虑以下表示来理解补集/模糊“非”关系如何工作 -
$$\mu _{\widetilde{A}} = 1-\mu _{\widetilde{A}}\left ( y \right )\quad y \in U$$

模糊集的性质
让我们讨论模糊集的不同属性。
交换律
有两个模糊集 $\widetilde{A}$ 和 $\widetilde{B}$,该属性指出 -
$$\widetilde{A}\cup \widetilde{B} = \widetilde{B}\cup \widetilde{A}$$
$$\widetilde{A}\cap \widetilde{B} = \widetilde{B}\cap \widetilde{A}$$
关联属性
具有三个模糊集 $\widetilde{A}$、$\widetilde{B}$ 和 $\widetilde{C}$,该属性指出 -
$$(\widetilde{A}\cup \left \widetilde{B}) \cup \widetilde{C} \right = \left \widetilde{A} \cup (\widetilde{B}\right )\cup \widetilde {C})$$
$$(\widetilde{A}\cap \left \widetilde{B}) \cap \widetilde{C} \right = \left \widetilde{A} \cup (\widetilde{B}\right \cap \widetilde{ C})$$
分配财产
具有三个模糊集 $\widetilde{A}$、$\widetilde{B}$ 和 $\widetilde{C}$,该属性指出 -
$$\widetilde{A}\cup \left ( \widetilde{B} \cap \widetilde{C}\right ) = \left ( \widetilde{A} \cup \widetilde{B}\right )\cap \left ( \widetilde{A}\cup \widetilde{C} \right )$$
$$\widetilde{A}\cap \left ( \widetilde{B}\cup \widetilde{C} \right ) = \left ( \widetilde{A} \cap \widetilde{B} \right )\cup \left ( \widetilde{A}\cap \widetilde{C} \right )$$
幂等性
对于任何模糊集 $\widetilde{A}$,该属性指出 -
$$\widetilde{A}\cup \widetilde{A} = \widetilde{A}$$
$$\widetilde{A}\cap \widetilde{A} = \widetilde{A}$$
身份属性
对于模糊集 $\widetilde{A}$ 和通用集 $U$,该属性指出 -
$$\widetilde{A}\cup \varphi = \widetilde{A}$$
$$\widetilde{A}\cap U = \widetilde{A}$$
$$\widetilde{A}\cap \varphi = \varphi$$
$$\widetilde{A}\cup U = U$$
传递性
具有三个模糊集 $\widetilde{A}$、$\widetilde{B}$ 和 $\widetilde{C}$,该属性指出 -
$$如果 \: \widetilde{A}\subseteq \widetilde{B}\subseteq \widetilde{C},\:则\:\widetilde{A}\subseteq \widetilde{C}$$
合合性
对于任何模糊集 $\widetilde{A}$,该属性指出 -
$$\overline{\overline{\widetilde{A}}} = \widetilde{A}$$
德摩根定律
该定律在证明同义反复和矛盾方面发挥着至关重要的作用。该法规定 -
$$\overline{{\widetilde{A}\cap \widetilde{B}}} = \overline{\widetilde{A}}\cup \overline{\widetilde{B}}$$
$$\overline{{\widetilde{A}\cup \widetilde{B}}} = \overline{\widetilde{A}}\cap \overline{\widetilde{B}}$$
模糊逻辑 - 隶属函数
我们已经知道,模糊逻辑不是模糊的逻辑,而是用来描述模糊性的逻辑。这种模糊性的最佳特征是其隶属函数。换句话说,我们可以说隶属函数代表了模糊逻辑中的真实程度。

以下是与隶属函数相关的一些要点 -
隶属函数于 1965 年由 Lofti A. Zadeh 在他的第一篇研究论文“模糊集”中首次引入。
隶属函数表征模糊性(即模糊集中的所有信息),无论模糊集中的元素是离散的还是连续的。
隶属函数可以定义为一种通过经验而不是知识来解决实际问题的技术。
隶属函数以图形形式表示。
定义模糊性的规则也是模糊的。
数学符号
我们已经研究过,信息域U中的模糊集à可以定义为一组有序对,并且可以在数学上表示为 -
$$\widetilde{A} = \left \{ \left ( y,\mu _{\widetilde{A}} \left ( y \right ) \right ) | y\in U\right \}$$
这里 $\mu \widetilde{A}\left (\bullet \right )$ = $\widetilde{A}$ 的隶属函数;假设值在 0 到 1 的范围内,即 $\mu \widetilde{A}\left (\bullet \right )\in \left [ 0,1 \right ]$。隶属函数 $\mu \widetilde{A}\left (\bullet \right )$ 将 $U$ 映射到隶属空间 $M$。
上述隶属函数中的点$\left (\bullet \right )$,表示模糊集中的元素;无论是离散的还是连续的。
会员功能特点
我们现在将讨论隶属函数的不同特征。
核
对于任何模糊集合 $\widetilde{A}$,隶属函数的核心是由集合中的完整隶属关系表征的宇宙区域。因此,核心由信息宇宙的所有元素 $y$ 组成,使得,
$$\mu _{\widetilde{A}}\left ( y \right ) = 1$$
支持
对于任何模糊集$\widetilde{A}$,隶属函数的支持是集合中非零隶属度特征的全域区域。因此,核心由信息宇宙的所有元素 $y$ 组成,这样,
$$\mu _{\widetilde{A}}\left ( y \right ) > 0$$
边界
对于任何模糊集合$\widetilde{A}$,隶属函数的边界是宇宙区域,其特征是集合中非零但不完整的隶属关系。因此,核心由信息宇宙的所有元素 $y$ 组成,使得,
$$1 > \mu _{\widetilde{A}}\left ( y \right ) > 0$$

模糊化
它可以被定义为将清晰集转换为模糊集或将模糊集转换为更模糊集的过程。基本上,此操作将准确清晰的输入值转换为语言变量。
以下是模糊化的两种重要方法 -
支持模糊化(s-fuzzification)方法
在这种方法中,模糊集可以借助以下关系来表示 -
$$\widetilde{A} = \mu _1Q\left ( x_1 \right )+\mu _2Q\left ( x_2 \right )+...+\mu _nQ\left ( x_n \right )$$
这里模糊集$Q\left ( x_i \right )$ 被称为模糊化核。该方法是通过保持 $\mu _i$ 恒定并将 $x_i$ 转换为模糊集 $Q\left ( x_i \right )$ 来实现的。
等级模糊化(g-fuzzification)方法
它与上面的方法非常相似,但主要区别在于它保持 $x_i$ 恒定,并且 $\mu _i$ 表示为模糊集。
去模糊化
它可以被定义为将模糊集减少为清晰集或将模糊成员转换为清晰成员的过程。
我们已经研究过模糊化过程涉及从清晰量到模糊量的转换。在许多工程应用中,需要对结果进行去模糊化,或者更准确地说是“模糊结果”,以便将其转换为清晰的结果。从数学上讲,去模糊化的过程也称为“四舍五入”。
下面描述了去模糊化的不同方法 -
最大会员法
该方法仅限于峰值输出函数,也称为高度法。从数学上讲,它可以表示如下 -
$$\mu _{\widetilde{A}}\left ( x^* \right )>\mu _{\widetilde{A}}\left ( x \right ) \: 对于所有\:x \in X$$
这里,$x^*$ 是去模糊化的输出。
质心法
该方法也称为面积中心法或重心法。从数学上讲,去模糊化的输出 $x^*$ 将表示为 -
$$x^* = \frac{\int \mu _{\widetilde{A}}\left ( x \right ).xdx}{\int \mu _{\widetilde{A}}\left ( x \right ).dx}$$
加权平均法
在此方法中,每个隶属函数均以其最大隶属值进行加权。从数学上讲,去模糊化的输出 $x^*$ 将表示为 -
$$x^* = \frac{\sum \mu _{\widetilde{A}}\left ( \overline{x_i} \right ).\overline{x_i}}{\sum \mu _{\widetilde{A }}\left (\overline{x_i}\right)}$$
平均-最大隶属度
该方法也称为最大值中间法。从数学上讲,去模糊化的输出 $x^*$ 将表示为 -
$$x^* = \frac{\displaystyle \sum_{i=1}^{n}\overline{x_i}}{n}$$
模糊逻辑 - 传统模糊复习
逻辑最初只是研究区分合理论证和不合理论证的因素,现在已经发展成为一个强大而严格的系统,根据已知的其他陈述,可以发现真实的陈述。
谓词逻辑
该逻辑涉及谓词,谓词是包含变量的命题。
谓词是在某个特定域上定义的一个或多个变量的表达式。带有变量的谓词可以通过给变量赋值或量化变量来构成命题。
以下是谓词的一些示例 -
- 设 E(x, y) 表示“x = y”
- 设 X(a, b, c) 表示“a + b + c = 0”
- 设 M(x, y) 表示“x 与 y 结婚”
命题逻辑
命题是真值“真”或真值“假”的陈述性陈述的集合。命题由命题变量和连接词组成。命题变量用大写字母(A、B 等)表示。连接词连接命题变量。
下面给出了一些命题的例子 -
- “Man is Mortal”,它返回真值“TRUE”
- “12 + 9 = 3 – 2”,返回真值“FALSE”
以下不是提案 -
“A 小于 2” - 这是因为除非我们给出 A 的具体值,否则我们无法判断该陈述是真还是假。
连接词
在命题逻辑中,我们使用以下五个连接词 -
- 或 (∨∨)
- 与 (∧∧)
- 否定/非 (ØØ)
- 蕴涵/如果-那么 (→→)
- 当且仅当 (⇔⇔)
或 (∨∨)
如果命题变量 A 或 B 中至少有一个为真,则两个命题 A 和 B 的 OR 运算(写为 A∨BA∨B)为真。
真值表如下 -
| A | 乙 | A ∨ B |
|---|---|---|
| 真的 | 真的 | 真的 |
| 真的 | 错误的 | 真的 |
| 错误的 | 真的 | 真的 |
| 错误的 | 错误的 | 错误的 |
与 (∧∧)
如果命题变量 A 和 B 都为真,则两个命题 A 和 B 的 AND 运算(写为 A∧BA∧B)为真。
真值表如下 -
| A | 乙 | A∧B |
|---|---|---|
| 真的 | 真的 | 真的 |
| 真的 | 错误的 | 错误的 |
| 错误的 | 真的 | 错误的 |
| 错误的 | 错误的 | 错误的 |
否定 (--)
当 A 为真时,命题 A 的否定(写作 ØAØA)为假,当 A 为假时,命题 A 的否定为真。
真值表如下 -
| A | ØA |
|---|---|
| 真的 | 错误的 |
| 错误的 | 真的 |
蕴涵/如果-那么 (→→)
蕴涵 A→BA→B 是命题“如果 A,则 B”。如果 A 为真且 B 为假,则为假。其余情况均为真。
真值表如下 -
| A | 乙 | A→B |
|---|---|---|
| 真的 | 真的 | 真的 |
| 真的 | 错误的 | 错误的 |
| 错误的 | 真的 | 真的 |
| 错误的 | 错误的 | 真的 |
当且仅当 (⇔⇔)
A⇔BA⇔B 是双条件逻辑连接词,当 p 和 q 相同时,即均为假或均为真时,该连接词为真。
真值表如下 -
| A | 乙 | A⇔B |
|---|---|---|
| 真的 | 真的 | 真的 |
| 真的 | 错误的 | 错误的 |
| 错误的 | 真的 | 错误的 |
| 错误的 | 错误的 | 真的 |
结构良好的公式
格式良好的公式 (wff) 是包含以下其中一项的谓词 -
- 所有命题常量和命题变量都是wff。
- 如果 x 是变量且 Y 是 wff,则 ∀xY 和 ∃xY 也是 wff。
- 真值和假值是wffs。
- 每个Atomics式都是一个wff。
- 所有连接wff的连接词都是wff。
量词
谓词的变量由量词来量化。谓词逻辑中有两种类型的量词 -
- 通用量词
- 存在量词
通用量词
通用量词指出,其范围内的陈述对于特定变量的每个值都成立。用符号∀表示。
∀xP(x)被解读为对于 x 的每个值,P(x) 都为真。
示例- “人终有一死”可以转化为命题形式 ∀xP(x)。这里,P(x)是谓词,它表示x是凡人,并且话语宇宙是所有人。
存在量词
存在量词指出其范围内的陈述对于特定变量的某些值是正确的。用符号∃表示。
对于 x 的某些值, ∃xP(x)读作 P(x) 为真。
示例- “有些人不诚实”可以转化为命题形式 ∃x P(x),其中 P(x) 是谓词,表示 x 不诚实,并且话语宇宙是一些人。
嵌套量词
如果我们使用的量词出现在另一个量词的范围内,则称为嵌套量词。
例子
- ∀ a∃bP(x,y) 其中 P(a,b) 表示 a+b = 0
- ∀ a∀b∀cP(a,b,c) 其中 P(a,b) 表示 a+(b+c) = (a+b)+c
注- ∀a∃bP(x,y) ≠ ∃a∀bP(x,y)
模糊逻辑 - 近似推理
以下是近似推理的不同模式 -
分类推理
在这种近似推理模式中,不包含模糊量词和模糊概率的先行词被假定为规范形式。
定性推理
在这种近似推理模式中,前因和后果具有模糊的语言变量;系统的输入输出关系表示为模糊 IF-THEN 规则的集合。该推理主要用于控制系统分析。
三段论推理
在这种近似推理模式中,带有模糊量词的先行词与推理规则相关。这表示为 -
x = S 1 A' 是 B'
y = S 2 C′ 是 D′
------------------------
z = S 3 E's 是 F's
这里A、B、C、D、E、F是模糊谓词。
S 1和S 2被赋予模糊量词。
S 3是需要确定的模糊量词。
性格推理
在这种近似推理模式中,先行词是可能包含模糊量词“通常”的处置。量词通常将倾向性推理和三段论推理联系在一起;因此它发挥着重要作用。
例如,处置推理中的推理投影规则可以给出如下 -
通常( (L,M) 是 R ) ⇒ 通常 (L 是 [R ↓ L])
这里[R↓L]是模糊关系R在L上的投影
模糊逻辑规则库
众所周知,人类总是乐于用自然语言进行对话。人类知识的表示可以借助以下自然语言表达来完成 -
IF前件THEN后件
上述表达式称为模糊 IF-THEN 规则库。
规范形式
以下是模糊逻辑规则库的规范形式 -
规则 1 - 如果条件 C1,则限制 R1
规则 2 - 如果条件 C1,则限制 R2
。
。
。
规则 n - 如果条件 C1,则限制 Rn
模糊 IF-THEN 规则的解释
模糊 IF-THEN 规则可以解释为以下四种形式 -
赋值语句
此类语句使用“=”(等于号)来进行赋值。它们的形式如下 -
一个=你好
气候=夏天
条件语句
此类语句使用“IF-THEN”规则库形式来达到条件目的。它们的形式如下 -
IF 温度高 THEN 气候热
如果食物新鲜那就吃。
无条件陈述
它们的形式如下 -
转到10
关掉风扇
语言变量
我们研究了模糊逻辑使用语言变量,这些变量是自然语言中的单词或句子。例如,如果我们说温度,它是一个语言变量;其值是非常热或冷、稍热或冷、非常温暖、稍微温暖等。“非常”、“稍微”这些词是语言上的模糊限制语。
语言变量的表征
以下四个术语描述了语言变量 -
- 变量的名称,一般用x表示。
- 变量的术语集,一般用t(x)表示。
- 用于生成变量 x 的值的语法规则。
- 连接 x 的每个值及其意义的语义规则。
模糊逻辑命题
众所周知,命题是用任何语言表达的句子,通常以以下规范形式表达 -
s 作为 P
这里,s是主语,P是谓语。
例如,“德里是印度的首都”,这是一个命题,其中“德里”是主语,“是印度的首都”是谓语,表明主语的属性。
我们知道,逻辑是推理的基础,模糊逻辑通过在模糊命题中使用模糊谓词、模糊谓词修饰语、模糊量词和模糊限定词来扩展推理能力,这是与经典逻辑的区别。
模糊逻辑中的命题包括以下内容 -
模糊谓词
自然语言中几乎每个谓词本质上都是模糊的,因此模糊逻辑有高、短、温暖、热、快等谓词。
模糊谓词修饰语
我们在上面讨论了语言模糊限制语;我们还有许多模糊谓词修饰语充当模糊限制语。它们对于产生语言变量的值非常重要。例如,“非常”、“稍微”等词是修饰语,命题可以是“水有点热”。
模糊量词
它可以被定义为一个模糊数,它给出一个或多个模糊或非模糊集的基数的模糊分类。它可用于影响模糊逻辑中的概率。例如,“许多”、“大多数”、“频繁”等词被用作模糊量词,命题可以是“大多数人对此过敏”。
模糊限定符
现在让我们了解模糊限定符。模糊限定符也是模糊逻辑的命题。模糊限定有以下形式 -
基于真实性的模糊资格
它要求模糊命题的真实程度。
表达式- 表示为x is t。这里,t是模糊真值。
示例- (汽车是黑色的)不是很正确。
基于概率的模糊资格
它要求模糊命题的概率,无论是数值概率还是区间概率。
表达式- 表示为x 是 λ。这里,λ是模糊概率。
示例- (汽车是黑色的)很可能。
基于可能性的模糊资格
它声称模糊命题的可能性。
表达式- 表示为x 是 π。这里,π是一个模糊可能性。
示例- (汽车是黑色的)几乎是不可能的。
模糊逻辑 - 推理系统
模糊推理系统是以决策为主要工作的模糊逻辑系统的关键单元。它使用“IF…THEN”规则以及连接器“OR”或“AND”来绘制基本的决策规则。
模糊推理系统的特点
以下是 FIS 的一些特征 -
FIS 的输出始终是一个模糊集,无论其输入可以是模糊的或清晰的。
作为控制器时需要有模糊输出。
FIS 中将有一个去模糊化单元,将模糊变量转换为清晰变量。
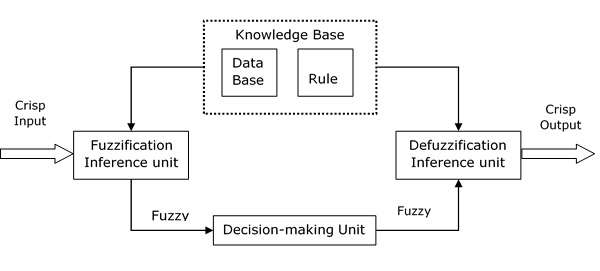
FIS 的功能块
以下五个功能块将帮助您了解 FIS 的构造 -
规则库- 它包含模糊 IF-THEN 规则。
数据库- 它定义模糊规则中使用的模糊集的隶属函数。
决策单元- 它根据规则执行操作。
模糊化接口单元- 它将清晰的数量转换为模糊的数量。
去模糊化接口单元- 它将模糊量转换为清晰的量。下图是模糊干扰系统的框图。
FIS 的工作
FIS 的工作包括以下步骤 -
模糊化单元支持多种模糊化方法的应用,并将清晰输入转换为模糊输入。
知识库——规则库和数据库的集合是在清晰输入转换为模糊输入时形成的。
去模糊单元的模糊输入最终被转换为清晰的输出。
FIS方法
现在让我们讨论 FIS 的不同方法。以下是 FIS 的两种重要方法,它们具有不同的模糊规则结果 -
- Mamdani 模糊推理系统
- Takagi-Sugeno 模糊模型(TS 方法)
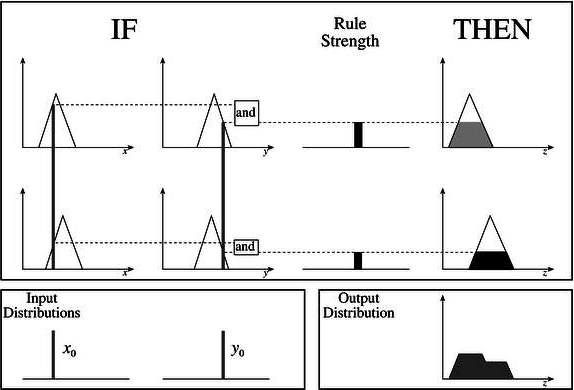
Mamdani 模糊推理系统
该系统由 Ebhasim Mamdani 于 1975 年提出。基本上,人们期望通过综合从系统工作人员那里获得的一组模糊规则来控制蒸汽机和锅炉组合。
计算输出的步骤
需要遵循以下步骤来计算该 FIS 的输出 -
步骤 1 - 此步骤需要确定一组模糊规则。
步骤 2 - 在此步骤中,通过使用输入隶属函数,输入将变得模糊。
步骤 3 - 现在通过根据模糊规则组合模糊化输入来建立规则强度。
步骤 4 - 在此步骤中,通过结合规则强度和输出隶属函数来确定规则的结果。
步骤 5 - 为了获得输出分布,请结合所有结果。
步骤 6 - 最后,获得去模糊化的输出分布。
以下是 Mamdani 模糊接口系统的框图。
Takagi-Sugeno 模糊模型(TS 方法)
该模型由 Takagi、Sugeno 和 Kang 于 1985 年提出。该规则的格式如下:
如果 x 是 A 并且 y 是 B 那么 Z = f(x,y)
这里,AB是前件中的模糊集,z = f(x,y)是后件中的清晰函数。
模糊推理过程
Takagi-Sugeno 模糊模型(TS 方法)下的模糊推理过程按以下方式工作 -
步骤 1:模糊化输入- 在这里,系统的输入被模糊化。
步骤 2:应用模糊运算符- 在此步骤中,必须应用模糊运算符以获得输出。
Sugeno表格的规则格式
Sugeno 形式的规则格式由下式给出 -
如果 7 = x 且 9 = y,则输出为 z = ax+by+c
两种方法的比较
现在让我们了解一下 Mamdani 系统和 Sugeno 模型之间的比较。
输出隶属函数- 它们之间的主要区别在于输出隶属函数的基础。Sugeno 输出隶属函数是线性的或恒定的。
聚合和去模糊化过程- 它们之间的差异还在于模糊规则的结果,因此它们的聚合和去模糊化过程也不同。
数学规则- Sugeno 规则比 Mamdani 规则存在更多的数学规则。
可调节参数- Sugeno 控制器比 Mamdani 控制器具有更多可调节参数。
模糊逻辑 - 数据库和查询
我们在前面的章节中已经研究过,模糊逻辑是一种基于“真实程度”而不是通常的“真或假”逻辑的计算方法。它处理近似推理而不是精确推理,以更类似于人类逻辑的方式解决问题,因此布尔代数的二值实现的数据库查询过程是不够的。
数据库关系的模糊场景
数据库关系的模糊场景可以借助以下示例来理解 -
例子
假设我们有一个数据库,其中包含访问过印度的人员的记录。在简单的数据库中,我们将按以下方式输入条目 -
| 姓名 | 年龄 | 公民 | 访问过的国家 | 度过的天数 | 访问年份 |
|---|---|---|---|---|---|
| 约翰·史密斯 | 35 | 我们 | 印度 | 41 | 1999年 |
| 约翰·史密斯 | 35 | 我们 | 意大利 | 72 | 1999年 |
| 约翰·史密斯 | 35 | 我们 | 日本 | 31 | 1999年 |
现在,如果有人查询 99 年访问过印度和日本并且是美国公民的人,那么输出将显示两个名为 John Smith 的条目。这是生成简单输出的简单查询。
但是如果我们想知道上面查询中的人是否年轻怎么办?根据以上结果,该人的年龄为35岁。但我们能假设这个人年轻吗?同样,同样的事情也可以应用于其他字段,例如花费的天数、访问的年份等。
上述问题的解决方案可以借助模糊值集找到,如下所示 -
FV(年龄){ 非常年轻、年轻、有点老、老 }
FV(花费的天数){ 几乎几天、几天、相当几天、很多天 }
FV(访问年份){遥远的过去、最近的过去、最近的}
现在,如果任何查询具有模糊值,那么结果本质上也将是模糊的。
模糊查询系统
模糊查询系统是用户使用(准)自然语言句子从数据库获取信息的接口。已经提出了许多模糊查询实现,导致语言略有不同。尽管根据不同实现的特殊性存在一些变化,但模糊查询语句的答案通常是一个记录列表,按匹配程度排序。
模糊逻辑 - 量化
在自然语言语句建模中,量化语句发挥着重要作用。这意味着 NL 在很大程度上依赖于量化构造,其中通常包括“几乎所有”、“许多”等模糊概念。以下是量化命题的一些示例 -
- 每个学生都通过了考试。
- 每辆跑车都很昂贵。
- 许多学生通过了考试。
- 许多跑车都很昂贵。
在上面的示例中,量词“Every”和“Many”应用于明确限制“学生”以及明确范围“通过考试的(人)”和“汽车”以及明确范围“体育”。
模糊事件、模糊均值和模糊方差
借助一个例子,我们可以理解上述概念。假设我们是一家名为 ABC 公司的股东。目前该公司正以 40 卢比的价格出售其每股股票。有 3 家不同的公司,其业务与 ABC 类似,但它们以不同的价格发行股票——分别为每股 100 卢比、每股 85 卢比和每股 60 卢比。
现在价格接管的概率分布如下 -
| 价格 | 100 卢比 | 85 卢比 | 60 卢比 |
|---|---|---|---|
| 可能性 | 0.3 | 0.5 | 0.2 |
现在,根据标准概率论,上述分布给出的预期价格平均值如下 -
100 美元 × 0.3 + 85 × 0.5 + 60 × 0.2 = 84.5 美元
并且,根据标准概率论,上述分布给出了预期价格的方差如下 -
$(100 − 84.5)2 × 0.3 + (85 − 84.5)2 × 0.5 + (60 − 84.5)2 × 0.2 = 124.825$
假设该集合中 100 的隶属度为 0.7,85 的隶属度为 1,值 60 的隶属度为 0.5。这些可以反映在以下模糊集中 -
$$\left \{ \frac{0.7}{100}, \: \frac{1}{85}, \: \frac{0.5}{60}, \right \}$$
这样得到的模糊集称为模糊事件。
我们想要我们的计算给出的模糊事件的概率 -
0.7 美元 × 0.3 + 1 × 0.5 + 0.5 × 0.2 = 0.21 + 0.5 + 0.1 = 0.81 美元
现在,我们需要计算模糊均值和模糊方差,计算如下 -
模糊均值$= \left ( \frac{1}{0.81} \right ) × (100 × 0.7 × 0.3 + 85 × 1 × 0.5 + 60 × 0.5 × 0.2)$
$= 85.8$
模糊_方差$= 7496.91 − 7361.91 = 135.27$
模糊逻辑 - 决策
它是一项活动,包括从实现特定目标所需的步骤中选择合适的替代方案所要采取的步骤。
决策步骤
现在让我们讨论决策过程中涉及的步骤 -
确定替代方案集- 在此步骤中,必须确定必须从中做出决策的替代方案。
评估替代方案- 在这里,必须评估替代方案,以便可以对其中一种替代方案做出决定。
替代方案之间的比较- 在此步骤中,将完成评估的替代方案之间的比较。
决策类型
我们现在将了解不同类型的决策。
个人决策
在这种类型的决策中,只有一个人负责做出决策。这种决策模型可以描述为 -
一组可能的操作
目标集 $G_i\left ( i \: \in \: X_n \right );$
约束集 $C_j\left ( j \: \in \: X_m \right )$
上述目标和约束以模糊集的形式表达。
现在考虑一个集合 A。然后,该集合的目标和约束由下式给出 -
$G_i\left ( a \right )$ = 组合$\left [ G_i\left ( a \right ) \right ]$ = $G_i^1\left ( G_i\left ( a \right ) \right )$ 与 $ G_i^1$
$C_j\left ( a \right )$ = 组合$\left [ C_j\left ( a \right ) \right ]$ = $C_j^1\left ( C_j\left ( a \right ) \right )$ 与 $ C_j^1$对于 $a\:\in \:A$
上述情况下的模糊决策由下式给出 -
$$F_D = min[i\in X_{n}^{in}fG_i\left ( a \right ),j\in X_{m}^{in}fC_j\left ( a \right )]$$
多人决策
在这种情况下,决策涉及多个人,因此利用多个人的专业知识来做出决策。
计算公式如下:
偏好 $x_i$ 而非 $x_j$ 的人数= $N\left ( x_i, \: x_j \right )$
决策者总数= $n$
那么 $SC\left ( x_i, \: x_j \right ) = \frac{N\left ( x_i, \: x_j \right )}{n}$
多目标决策
当有多个目标需要实现时,就会出现多目标决策。此类决策存在以下两个问题 -
获取与通过各种替代方案实现目标有关的适当信息。
权衡每个目标的相对重要性。
从数学上来说,我们可以将 n 个备选方案定义为 -
$A = \left [ a_1, \:a_2,\:..., \: a_i, \: ..., \:a_n \right ]$
“m”个目标的集合为 $O = \left [ o_1, \:o_2,\:..., \: o_i, \: ..., \:o_n \right ]$
多属性决策
当可以根据对象的多个属性对替代方案进行评估时,就会发生多属性决策。属性可以是数值数据、语言数据和定性数据。
在数学上,多属性评估是在线性方程的基础上进行的,如下所示 -
$$Y = A_1X_1+A_2X_2+...+A_iX_i+...+A_rX_r$$
模糊逻辑 - 控制系统
模糊逻辑在各种控制应用中得到了巨大成功的应用。几乎所有的消费品都有模糊控制。其中一些例子包括借助空调控制室温、车辆使用的防制动系统、交通灯控制、洗衣机、大型经济系统等。
为什么在控制系统中使用模糊逻辑
控制系统是物理组件的排列,旨在改变另一个物理系统,以便该系统表现出某些所需的特性。以下是在控制系统中使用模糊逻辑的一些原因 -
在应用传统控制时,需要了解模型和精确表述的目标函数。这使得在很多情况下应用起来非常困难。
通过应用模糊逻辑进行控制,我们可以利用人类的专业知识和经验来设计控制器。
模糊控制规则,基本上是 IF-THEN 规则,可以在设计控制器时得到最好的利用。
模糊逻辑控制 (FLC) 设计中的假设
在设计模糊控制系统时,应做出以下六个基本假设 -
该设备是可观察和可控的- 必须假设输入、输出以及状态变量可用于观察和控制目的。
知识体的存在- 必须假设存在一个具有语言规则的知识体和一组可以从中提取规则的输入输出数据集。
解的存在性- 必须假设存在解。
“足够好”的解决方案就足够了- 控制工程必须寻找“足够好”的解决方案,而不是最佳的解决方案。
精度范围- 模糊逻辑控制器必须设计在可接受的精度范围内。
关于稳定性和最优性的问题 - 在设计模糊逻辑控制器时必须公开稳定性和最优性问题,而不是明确解决。
模糊逻辑控制的体系结构
下图显示了模糊逻辑控制(FLC)的架构。

FLC的主要组成部分
以下是 FLC 的主要组件,如上图所示 -
模糊器- 模糊器的作用是将清晰的输入值转换为模糊值。
模糊知识库- 它存储有关所有输入输出模糊关系的知识。它还具有定义模糊规则库的输入变量和受控对象的输出变量的隶属函数。
模糊规则库- 它存储有关域过程操作的知识。
推理引擎- 它充当任何 FLC 的内核。基本上,它通过执行近似推理来模拟人类决策。
去模糊器- 去模糊器的作用是将模糊值转换为从模糊推理引擎获得的清晰值。
FLC 设计步骤
以下是设计 FLC 所涉及的步骤 -
变量识别- 此处,必须识别所考虑的工厂的输入、输出和状态变量。
模糊子集配置- 信息域被划分为多个模糊子集,每个子集都分配有一个语言标签。始终确保这些模糊子集包含宇宙的所有元素。
获取隶属函数- 现在获取我们在上述步骤中获得的每个模糊子集的隶属函数。
模糊规则库配置- 现在通过分配模糊输入和输出之间的关系来制定模糊规则库。
模糊化- 模糊化过程在此步骤中启动。
组合模糊输出- 通过应用模糊近似推理,找到模糊输出并将它们合并。
去模糊化- 最后,启动去模糊化过程以形成清晰的输出。
模糊逻辑控制的优点
现在让我们讨论模糊逻辑控制的优点。
更便宜- 就性能而言,开发 FLC 比开发基于模型的控制器或其他控制器相对便宜。
稳健- FLC 比 PID 控制器更稳健,因为它们能够覆盖大范围的操作条件。
可定制- FLC 是可定制的。
模拟人类演绎思维- 基本上,FLC 旨在模拟人类演绎思维,即人们根据已知信息推断结论的过程。
可靠性- FLC 比传统控制系统更可靠。
效率- 模糊逻辑在控制系统中应用时可提供更高的效率。
模糊逻辑控制的缺点
现在我们将讨论模糊逻辑控制的缺点。
需要大量数据- FLC 需要应用大量数据。
在历史数据中等的情况下有用- FLC 对于比历史数据小或大得多的程序没有用。
需要较高的人类专业知识-这是一个缺点,因为系统的准确性取决于人类的知识和专业知识。
需要定期更新规则- 规则必须随时间更新。
自适应模糊控制器
在本章中,我们将讨论什么是自适应模糊控制器及其工作原理。自适应模糊控制器设计有一些可调参数以及用于调整它们的嵌入式机制。自适应控制器被用来提高控制器的性能。
实现自适应算法的基本步骤
现在让我们讨论实现自适应算法的基本步骤。
可观察数据的收集- 收集可观察数据以计算控制器的性能。
控制器参数的调整- 现在,借助控制器性能,可以完成控制器参数调整的计算。
控制器性能的改进- 在此步骤中,调整控制器参数以提高控制器的性能。
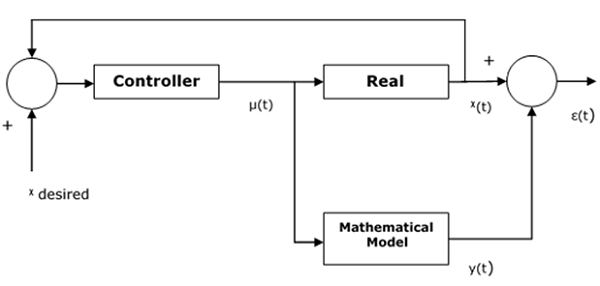
经营理念
控制器的设计基于类似于真实系统的假设数学模型。计算实际系统与其数学表示之间的误差,如果误差相对较小,则假设模型有效工作。
还存在为控制器的有效性设置边界的阈值常数。控制输入被馈送到实际系统和数学模型中。这里,假设$x\left ( t \right )$ 是真实系统的输出,$y\left ( t \right )$ 是数学模型的输出。那么误差 $\epsilon \left ( t \right )$ 可以计算如下 -
$$\epsilon \left ( t \right ) = x\left ( t \right ) - y\left ( t \right )$$
这里,$x$desired是我们想要从系统中得到的输出,而$\mu\left(t\right)$是来自控制器并进入真实模型和数学模型的输出。
下图显示了如何在实际系统的输出和数学模型之间跟踪误差函数 -
系统参数化
基于模糊数学模型设计的模糊控制器将具有以下形式的模糊规则 -
规则 1 − IF $x_1\left ( t_n \right )\in X_{11} \: AND...AND\: x_i\left ( t_n \right )\in X_{1i}$
那么 $\mu _1\left ( t_n \right ) = K_{11}x_1\left ( t_n \right ) + K_{12}x_2\left ( t_n \right ) \: +...+ \: K_{1i }x_i\左 ( t_n \右 )$
规则 2 − IF $x_1\left ( t_n \right )\in X_{21} \: AND...AND \: x_i\left ( t_n \right )\in X_{2i}$
那么 $\mu _2\left ( t_n \right ) = K_{21}x_1\left ( t_n \right ) + K_{22}x_2\left ( t_n \right ) \: +...+ \: K_{2i }x_i\左 ( t_n \右 ) $
。
。
。
规则 j − IF $x_1\left ( t_n \right )\in X_{k1} \: AND...AND \: x_i\left ( t_n \right )\in X_{ki}$
那么 $\mu _j\left ( t_n \right ) = K_{j1}x_1\left ( t_n \right ) + K_{j2}x_2\left ( t_n \right ) \: +...+ \: K_{ji }x_i\左 ( t_n \右 ) $
上述参数组表征了控制器。
机制调整
调整控制器参数以提高控制器的性能。计算调整参数的过程就是调整机制。
从数学上讲,令 $\theta ^\left ( n \right )$ 为在 $t = t_n$ 时刻调整的一组参数。调整可以是参数的重新计算,
$$\theta ^\left ( n \right ) = \Theta \left ( D_0,\: D_1, \: ..., \:D_n \right )$$
这里 $D_n$ 是在时间 $t = t_n$ 时收集的数据。
现在,通过根据其先前值更新参数集来重新制定该公式,如下所示:
$$\theta ^\left ( n \right ) = \phi ( \theta ^{n-1}, \: D_n)$$
选择自适应模糊控制器的参数
选择自适应模糊控制器需要考虑以下参数 -
系统可以完全用模糊模型来近似吗?
如果一个系统可以完全用模糊模型来近似,那么这个模糊模型的参数是容易获得的还是必须在线确定?
如果一个系统