- 木偶师教程
- 傀儡师 - 主页
- 傀儡师 - 简介
- Puppeteer - 元素处理
- Puppeteer - Google 的使用
- Puppeteer - NodeJS 安装
- Puppeteer VS 代码配置
- 傀儡师 - 安装
- Puppeteer - 基本测试
- Puppeteer - 非无头执行
- Puppeteer 和 Selenium 之间的比较
- Puppeteer 与Protractor之间的比较
- Puppeteer 与 Cypress 的比较
- Puppeteer - 浏览器操作
- Puppeteer - 处理选项卡
- Puppeteer - 基本命令
- 傀儡师 - 火狐
- 木偶师 - Chrome
- Puppeteer - 处理确认警报
- Puppeteer - 处理下拉菜单
- 傀儡师 - 定位器
- Puppeteer - Xpath 函数
- Puppeteer - Xpath 属性
- Puppeteer - Xpath 分组
- Puppeteer - 绝对 Xpath
- Puppeteer - 相对 Xpath
- Puppeteer - Xpath 轴
- Puppeteer - 类型选择器
- 名称选择器和类名称选择器
- Puppeteer - ID 选择器
- Puppeteer - 属性选择器
- Puppeteer - 处理链接/按钮
- 处理编辑框和复选框
- Puppeteer - 处理框架
- Puppeteer - 键盘模拟
- Puppeteer - 获取元素文本
- Puppeteer - 获取元素属性
- Puppeteer - 设备模拟
- Puppeteer - 禁用 JavaScript
- 傀儡师 - 同步
- Puppeteer - 捕获屏幕截图
- 木偶师有用资源
- 木偶师 - 快速指南
- Puppeteer - 有用的资源
- 木偶师 - 讨论
木偶师 - 快速指南
傀儡师 - 简介
Puppeteer 分别用于前端开发和测试的自动化和简化。它是由谷歌推出的。Puppeteer 基于 Node.js 库并且是开源的。
Puppeteer 包含用于在无头模式或 Chromium(遵循 DevTools 中的协议)下交互和管理 Chrome 浏览器的 API。但是,它也可以用于 Chrome/Chromium/Edge/Firefox 等浏览器上的非无头执行。
Puppeteer 可用于自动化大多数 UI 测试、键盘、鼠标移动等。它可用于测试用 Angular 和 Angularjs 开发的应用程序。网页抓取和抓取等操作可以通过 Puppeteer 来执行。
Puppeteer 并不像 Selenium、Cypress、Protractor 等那样被视为自动化工具。它主要用于管理 Chromium 浏览器的内部功能。我们可以通过按 F12 或 Command+Option+C(在 MacOS 中)在 Chrome 浏览器中打开 DevTools。
Puppeteer 就像一个开发工具,因为它能够执行开发人员执行的大部分任务,例如处理请求和响应、定位元素、网络流量和性能等。
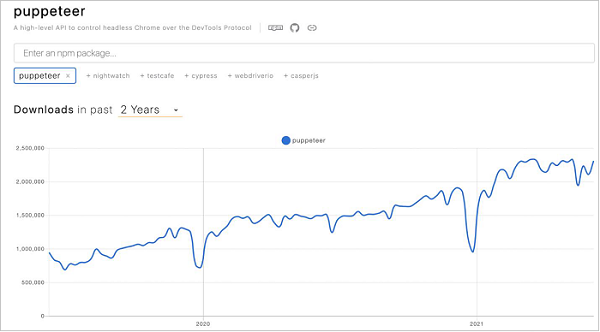
如果我们跟踪过去几年 Puppeteer 下载的 npm 趋势,我们将观察到 Puppeteer 的使用呈上升趋势(可从以下链接获取) -
傀儡师架构
Puppeteer 利用 Node 库提供顶级 API 来管理 Chromium 或 Chrome 浏览器。这是通过遵循 DevTools 的协议来完成的。
Puppeteer 具有以下层次结构 -
浏览器(带/不带无头模式) - 浏览器执行要在浏览器引擎上执行的操作。
Chromium 开发项目或 CDP - Chromium 是执行所有操作的真实位置。浏览器 - Microsoft Edge 和 Chrome 使用 Chromium 作为浏览器引擎。
Puppeteer - 这实际上是一个基于节点模块的包。
自动化测试代码- 这也称为 Nodejs 级别。在这里,实际的自动化代码是由最终用户使用 JavaScript 开发的。
Puppeteer - 元素处理
我们可以使用 Puppeteer 处理页面上的元素。导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。为了唯一地获取元素的属性,我们需要检查它(右键单击该元素,然后选择“检查”选项)。ElementHandle 对象是通过方法创建的 - page.$、page.$$ 和 page.$x。这些对象引用页面中的元素或标签。
定位元素的 Puppeteer 方法
下面列出了这些方法 -
页.$(定位器值)
此方法使用 ElementHandle 生成一个 Promise。ElementHandle 是所识别元素的对象。如果有多个元素具有相同的定位器值,则仅返回页面左上角的第一个匹配元素。
页。$$(定位器值)
此方法生成一个带有 ElementHandle 数组的 Promise。如果有多个元素具有相同的定位器值,则所有匹配的元素将以数组的形式返回。
页.$x(xpath 值)
此方法生成一个带有 ElementHandle 数组的 Promise。如果有多个元素具有相同的 xpath 值,则所有匹配的元素将以数组的形式返回。如果有一个匹配元素,则返回的数组应只有一个元素。
ElementHandle 方法(如 elementHandle.$、elementHandle.$$ 和 elementHandle.$x)可以应用于元素。在这种情况下,应在当前 ElementHandle 的 DOM 中搜索元素,而不是在整个 DOM 中。
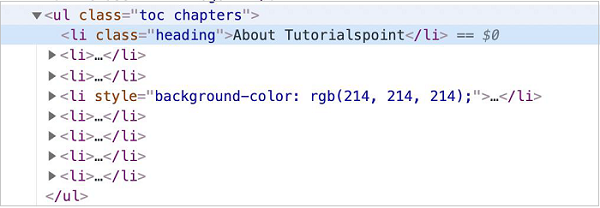
在下图中,我们以具有 li 标签(具有父元素 ul)和 class 属性值作为标题的元素为例。要使用页面上的 ElementHandle 方法来识别它,表达式应如下所示 -
const n = await page.$(".heading")
要在元素上使用 ElementHandle 方法来识别它,表达式应如下所示 -
const m = await page.$("ul")
const p = await m.$(".heading")
现在,请参考下面给出的具有 li 标签的元素的图像
定位器的类型
Puppeteer 中的定位器类型如下所示 -
ID
班级
类型
X路径
属性
类型
要使用上述定位器,我们应该对 HTML 代码有基本的了解。让我们以具有以下属性的编辑框为例 -
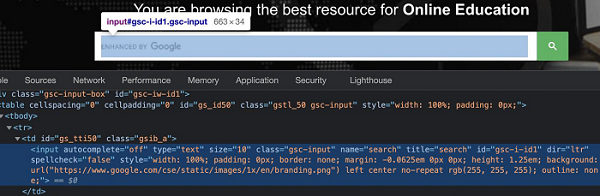
这里,输入是标记名。HTML 中的标签可能有属性,也可能没有。type、class、name、id等都是元素的属性。
例如,在表达式 class = "gsc-input" 中,= 左侧的文本是属性名称(类),= 右侧的文本是属性值 (gsc-input)。
属性可以分配也可以不分配值。另外,如果分配了值,则应将其括在双引号或单引号中。属性的值由开发人员根据他的选择设置。
Puppeteer - Google 的使用
下面列出了 Puppeteer 的用法 -
Puppeteer 可用于从网页中抓取内容。废弃意味着从特定网站中提取数据。
Puppeteer 可用于捕获屏幕截图。它可用于将网页导出为 PDF 格式。
Puppeteer 不需要外部驱动程序或库。它可以以无头模式在实际浏览器上运行。
它可以用作其他浏览器自动化工具(如 Selenium 或 Cypress)的良好替代品。有时,傀儡师的功能甚至比他们两者都好。
它的执行速度非常快,可用于在无头和有头模式下执行测试。
Puppeteer 拥有非常敏捷的社区支持,在 GitHub 上拥有超过 60,000 个启动项。请参阅此处给出的链接: https: //github.com/puppeteer/puppeteer
Puppeteer 支持无头执行,因此可以在 Unix、Linux、云、AWS 等平台上使用。
它可用于抓取 SPA(单页应用程序)并生成预渲染内容。爬取是指在没有从互联网获取真实网页的情况下,将网页的静态对象保存在本地并离线利用。
它可用于自动化大多数 UI 测试、键盘、鼠标移动、表单提交等。
Puppeteer 可用于构建最新的自动化测试环境。它可以利用 JavaScript 和浏览器的最新功能在最新版本的 Chrome 上运行测试。
Puppeteer 可用于获取 Web 应用程序的时间线跟踪以确定其性能。此外,它还可用于检查 Chrome 扩展并获取网页使用的 HTML 和 CSS 的覆盖率。
Puppeteer - NodeJS 安装
Puppeteer 代码实现是使用 JavaScript 完成的。为此,必须安装 NodeJS,因为它是一个 JavaScript 引擎。只有安装完成后,我们才能执行Puppeteer测试。
配置 NodeJS 的步骤如下:
步骤 1 - 启动具有以下链接的应用程序 -
https://nodejs.org/en/download/
步骤 2 - 根据我们使用的本地操作系统(Windows、Mac 或 Linux),单击链接下载安装程序。
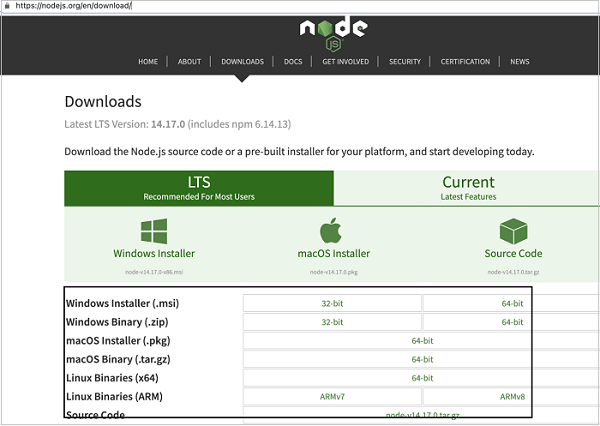
步骤 3 - 下载安装程序后,单击它。我们将导航到 Node.js 安装程序欢迎屏幕。单击继续。
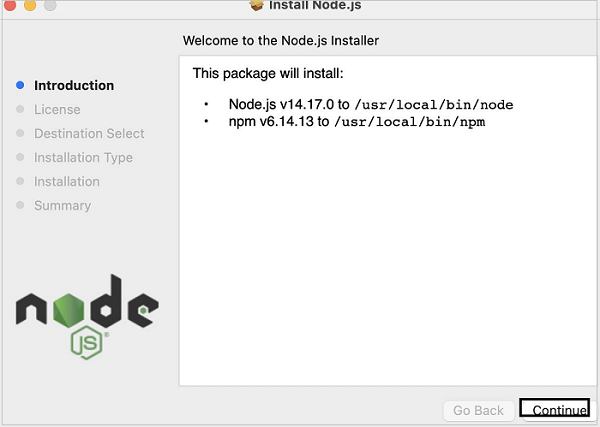
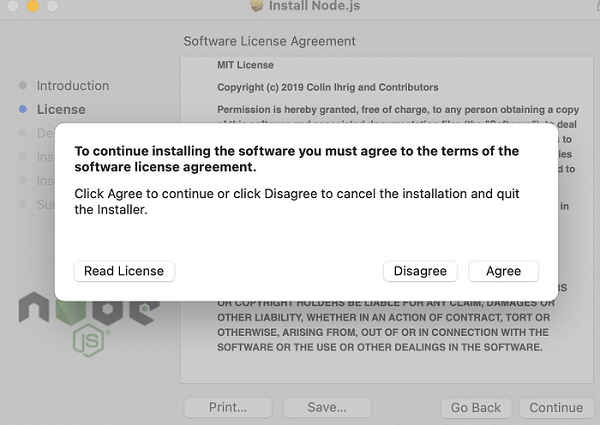
步骤 4 - 同意 Nodejs 的协议条款。
步骤 5 - 单击“安装”。
步骤 6 - 显示 Nodejs 安装成功消息后,单击“关闭”。
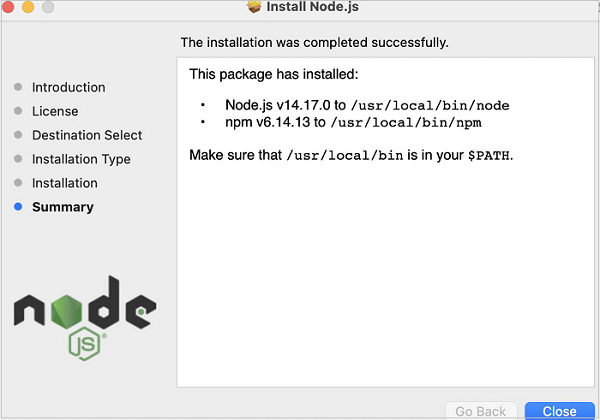
步骤 7 - 要检查 Nodejs 是否安装成功,请打开终端并运行命令:node.js。

应显示计算机中安装的 Nodejs 版本。
Puppeteer - VS 代码配置
下面列出了安装 Visual Studio (VS) 代码的步骤 -
第 1 步- 导航到以下链接 -
https://code.visualstudio.com/
步骤 2 - 根据我们拥有的本地操作系统(例如 macOS、Linux 或 Windows),我们需要选择下载链接。
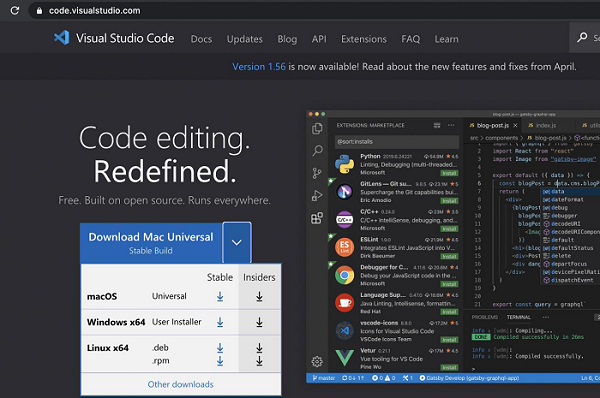
步骤 3 - 单击“下载”按钮后将下载 zip 文件。下载此文件完成后,单击它,Visual Studio Code 应用程序应该可供使用。

步骤 4 - 双击它,Visual Studio Code 应用程序应与欢迎页面一起启动。
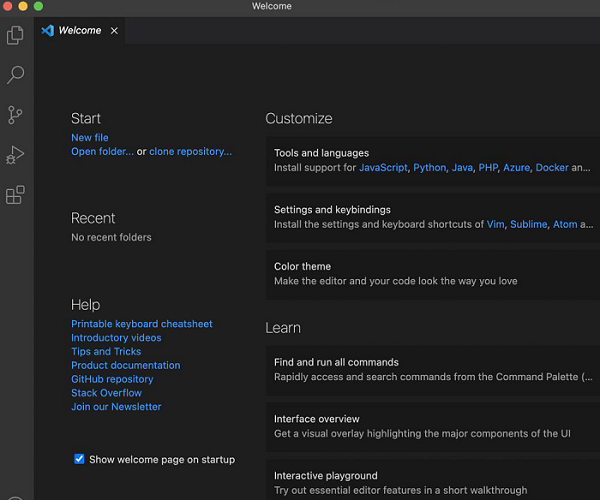
傀儡师 - 安装
下面列出了 Puppeteer 的安装步骤 -
步骤 1 - 安装 NodeJS。
关于如何安装NodeJs的细节在NodeJS安装章节中有详细讨论。
步骤 2 - 创建一个空文件夹,例如在某个位置创建 puppeteer。
步骤 3 - 启动 Visual Studio Code 应用程序,然后单击“打开文件夹”链接并导入我们在步骤 2 中创建的文件夹。
有关如何安装 VS Code 的详细信息,请参阅 VS Code 配置一章。
步骤 4 - 打开终端并从当前目录移动到我们在步骤 2 中创建的空文件夹的目录。然后运行以下命令 -
npm
步骤 5 - 对于 Puppeteer 安装,运行下面提到的命令 -
npm install puppeteer
或者,
npm i puppeteer
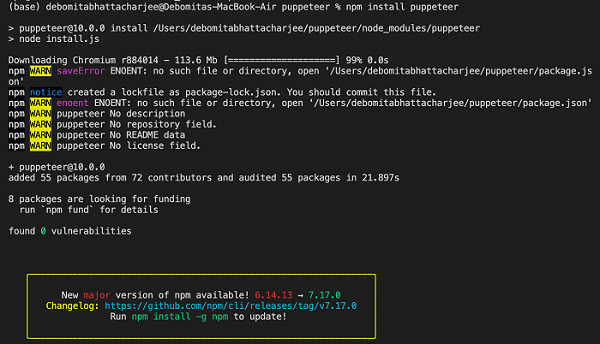
步骤 6 - 要安装 Puppeteer 核心,请运行下面提到的命令 -
npm i puppeteer-core
步骤 7 - 安装 Puppeteer 和 Puppeteer core 后,我们将在步骤 2 中创建的空文件夹中找到生成的 node_modules 文件夹和 package.json 文件。
步骤 8 - 在进行测试时,我们必须在代码中添加以下 Puppeteer 库。
const pt = require('puppeteer')
Puppeteer - 基本测试
要开始对 Puppeteer 进行基本测试,我们必须遵循以下步骤 -
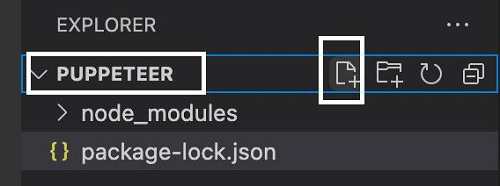
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
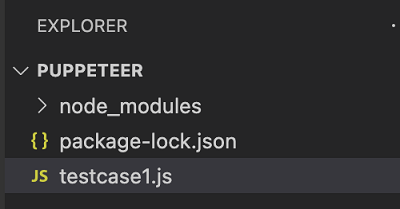
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在该文件中添加以下代码 -
//adding Puppeteer library
const pt = require('puppeteer');
pt.launch().then(async browser => {
//browser new page
const p = await browser.newPage();
//set viewpoint of browser page
await p.setViewport({ width: 1000, height: 500 })
//launch URL
await p.goto('https://www.tutorialspoint.com/index.htm')
//capture screenshot
await p.screenshot({
path: 'tutorialspoint.png'
});
//browser close
await browser.close()
})
步骤 4 - 使用以下命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js
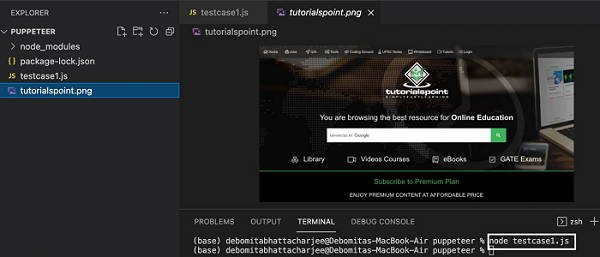
成功执行该命令后,会在页面目录中创建一个名为tutorialspoint.png 的新文件。它包含在浏览器中以无头模式启动的页面的捕获屏幕截图。
Puppeteer - 非无头执行
默认情况下,Puppeteer 在无头 Chromium 中执行测试。这意味着如果我们使用 Puppeteer 运行测试,那么我们将无法在浏览器中查看执行情况。
要启用 headless 模式执行,我们必须在代码中添加参数:headless:false。
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//adding Puppeteer library
const pt = require('puppeteer');
//adding headless flag to false
pt.launch({headless:false}).then(async browser => {
//browser new page
const p = await browser.newPage();
//set viewpoint of browser page
await p.setViewport({ width: 1000, height: 500 })
//launch URL
await p.goto('https://www.tutorialspoint.com/about/about_careers.htm');
})
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行下面提到的命令 -
node testcase1.js
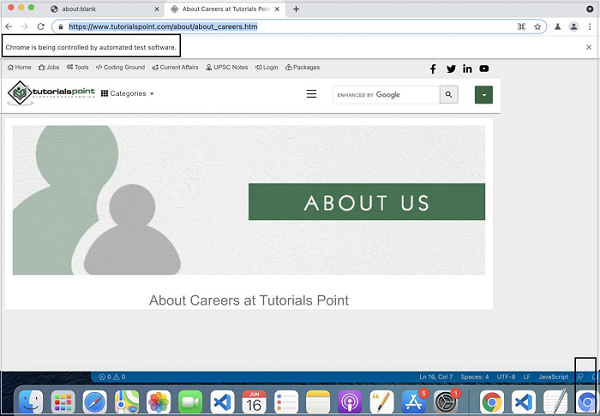
命令成功执行后,我们将看到执行以 head 模式被触发。
Puppeteer 和 Selenium 之间的比较
Puppeteer 和 Selenium 之间的主要区别如下 -
| 先生编号 | 傀儡师 | Selenium |
|---|---|---|
| 1 | Puppeteer 主要是为 Chromium 开发的,因此开发的测试主要在 Chrome 中执行。 | Selenium 可用于在 Chrome、Firefox、IE、Safari 等多种浏览器上执行测试。 |
| 2 | Puppeteer 代码只能用 JavaScript 实现。 | Selenium 代码可以用多种语言实现,例如 Java、Python、JavaScript、C# 等。 |
| 3 | Puppeteer 提供 API,通过使用 DevTools 协议来管理 Chrome 中的无头执行。 | Selenium 需要额外的外部浏览器驱动程序来根据用户命令触发测试。 |
| 4 | Puppeteer 管理 Chrome 浏览器。 | Selenium 主要用于执行测试以自动执行在浏览器上执行的操作。 |
| 5 | Puppeteer 执行测试的速度比 Selenium 更快。 | Selenium 执行测试的速度比 Puppeteer 慢。 |
| 6 | Puppeteer 是为 Chromium 引擎开发的 Node 中的模块。 | Selenium 是一个专用的测试自动化工具。 |
| 7 | Puppeteer 可通过利用请求和响应来进行 API 测试。 | 使用 Selenium 进行 API 测试很困难。 |
| 8 | Puppeteer 可用于验证用于加载网页的 CSS 和 JavaScript 文件的数量。 | Selenium 不能用于验证用于加载网页的 CSS 和 JavaScript 文件的数量。 |
| 9 | Puppeteer 可用于处理 Chrome 浏览器中 DevTools 中的大多数功能。 | Selenium 无法用于处理 Chrome 浏览器中 DevTools 中的大多数功能。 |
| 10 | Puppeteer 可用于在模拟器的帮助下在各种设备上执行测试。 | 使用带有 Selenium 的模拟器并不容易。 |
| 11 | Puppeteer 可用于获取页面加载所需的时间。 | Selenium 无法用于获取页面加载所需的时间。 |
| 12 | Puppeteer 可用于保存图像和 PDF 格式的屏幕截图。 | Selenium 仅在 Selenium 4 版本中可用于保存图像和 PDF 格式的屏幕截图。 |
| 13 | Puppeteer 于 2017 年首次推出。 | Selenium 于 2004 年首次推出。 |
| 14 | 在 Puppeteer 中,我们可以在不加载图像的情况下验证应用程序。 | 在 Selenium 中,我们可以在不加载图像的情况下验证应用程序。 |
Puppeteer 与Protractor之间的比较
Puppeteer 和 Protractor 之间的主要区别如下 -
| 先生。 | 傀儡师 | Protractor |
|---|---|---|
| 1 | Puppeteer 是为 Chromium 引擎开发的 Node 中的模块。 | Protractor 是一款专用的测试自动化工具。 |
| 2 | Puppeteer 执行测试的速度比 Protractor 更快。 | Protractor 执行测试的速度比 Puppeteer 慢。 |
| 3 | Puppeteer 主要是为 Chromium 开发的,因此开发的测试主要在 Chrome 中执行。 | Protractor 可用于在 Chrome、Firefox、IE、Safari 等多种浏览器上执行测试。 |
| 4 | Puppeteer 可通过利用请求和响应来进行 API 测试。 | 使用 Protractor 进行 API 测试很困难。 |
| 5 | Puppeteer 可用于验证用于加载网页的 CSS 和 JavaScript 文件的数量。 | Protractor 不能用于验证用于加载网页的 CSS 和 JavaScript 文件的数量。 |
| 6 | Puppeteer 可用于处理 Chrome 浏览器中 DevTools 中的大多数功能。 | Protractor 无法用于处理 Chrome 浏览器中 DevTools 中的大多数功能。 |
| 7 | Puppeteer 可用于在模拟器的帮助下在各种设备上执行测试。 | 将模拟器与Protractor一起使用并不容易。 |
| 8 | Puppeteer 可用于保存图像和 PDF 格式的屏幕截图。 | Protractor可用于仅以图像格式保存屏幕截图。 |
| 9 | Puppeteer 可用于获取页面加载所需的时间。 | Protractor无法用于获取页面加载所需的时间。 |
| 10 | 在 Puppeteer 中,我们可以在不加载图像的情况下验证应用程序。 | 在 Protractor 中,我们可以在不加载图像的情况下验证应用程序。 |
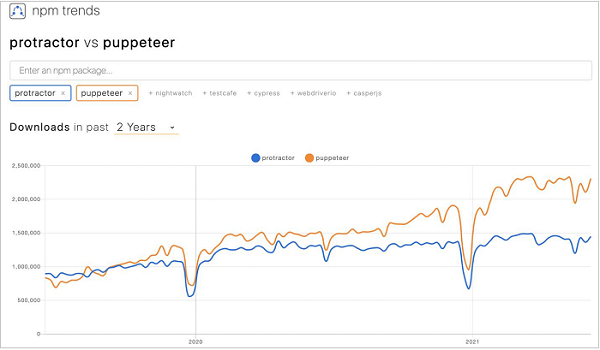
让我们观察一下 Puppeteer 和 Protractor 这两年的 npm 趋势。我们将观察到 Puppeteer 的使用量比 Protractor 的使用量呈上升趋势(可从以下链接获取) -
https://www.npmtrends.com/protractor-vs-puppeteer
Puppeteer 与 Cypress 的比较
Puppeteer 和 Cypress 之间的主要区别如下 -
| 先生编号 | 傀儡师 | 柏 |
|---|---|---|
| 1 | Puppeteer 是为 Chromium 引擎开发的 Node 中的模块。 | Cypress 是一个用 JavaScript 开发的专用测试自动化框架。 |
| 2 | Puppeteer主要用于网页抓取和SPA(单页应用程序)爬取。 | Cypress 主要用于自动化完整应用程序的测试用例。 |
| 3 | Puppeteer 中的断言基于 Mocha、Jasmine 或 Jest 框架。 | Cypress有其独特的主张。 |
| 4 | VS Code 和 Webstorm 主要用作 Puppeteer 的 IDE。 | Cypress 有自己的 IDE。 |
| 5 | Puppeteer 主要是为 Chromium 开发的,因此开发的测试主要在 Chrome 中执行。 | Cypress 可用于在 Chrome、Firefox、Electron 等多种浏览器上执行测试。 |
| 6 | Puppeteer 没有仪表板。 | Cypress有其仪表板来查看记录的测试,并向我们提供执行期间发生的事件的详细信息。 |
| 7 | Puppeteer 执行测试的速度比 Cypress 更快。 | Cypress 执行测试的速度比 Puppeteer 慢。 |
| 8 | Puppeteer API 并不比 Cypress 更容易使用。 | Cypress API 比 Puppeteer 更容易使用。 |
| 9 | Puppeteer 是免费的。 | Cypress 有免费和付费版本。 |
| 10 | Puppeteer 在测试中没有夹具和组夹具的功能。 | Cypress具有应用于测试的夹具和组夹具的特点。 |
| 11 | 在 Puppeteer 中无法对执行测试进行分组。 | 可以在 Cypress 中对执行测试进行分组。 |
| 12 | Puppeteer 没有嘲笑功能。 | Cypress 具有模拟功能。 |
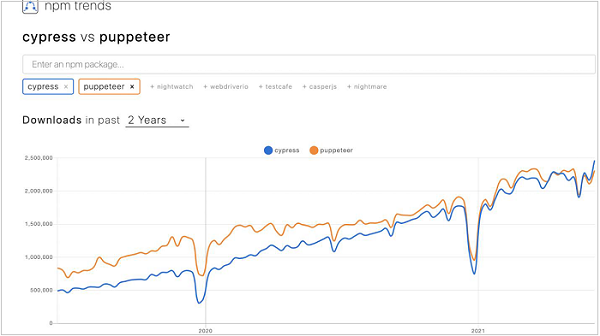
让我们观察一下 Puppeteer 和 Cypress 这两年的 npm 趋势。我们将观察到 Puppeteer 和 Cypress 的使用呈上升趋势(可从以下链接获取) -
https://www.npmtrends.com/cypress-vs-puppeteer
Puppeteer - 浏览器操作
浏览器操作可以由 Puppeteer 在以下给定方法的帮助下完成 -
发射()
它用于打开新浏览器并连接 Chromium 实例。它有一些可选参数,如下所示 -
Product - 这是字符串类型,用于指向要启动的浏览器。
句法
语法如下 -
let l = await puppeteer.launch({product : "chrome" })
headless - 这是布尔类型(默认值为 true),必须设置为 false 值才能以 headless 模式执行测试。
句法
语法如下 -
let l = await puppeteer.launch({headless : false})
devtools - 这是布尔类型。如果设置为 true,则 DevTools 将在每个浏览器选项卡中自动打开。另外,如果 devtools 设置为 true,则 headless 参数应设置为 false。
句法
语法如下 -
let l = await puppeteer.launch({devtools: true})
defaultViewport - 这是对象类型。它为页面提供一个持久的视口(视口的默认值为800*600)。我们可以通过提及像素的宽度和高度的整数值来修改视口的大小。
句法
语法如下 -
let l = await puppeteer.launch({defaultViewport: { width: 500, height: 459}})
SlowMo - 这是数字类型。该参数用于将 Puppeteer 的执行速度减慢一段时间,以毫秒为单位。
句法
语法如下 -
let l = await puppeteer.launch({slowMo: 500})
去()
它用于导航到网页。要导航的页面的 URL 作为参数传递。
句法
语法如下 -
await page.goto('https://www.tutorialspoint.com/index.htm')
关闭()
它用于关闭打开的浏览器。
句法
语法如下 -
await browser.close()
browserContexts()
这会生成所有打开的浏览器上下文的数组。
创建IncognitoBrowserContext()
它会在隐身环境中打开一个新的浏览器。
默认浏览器上下文()
它产生一个默认的浏览器上下文。
断开()
它用于断开 Puppeteer 与浏览器实例的连接。
已连接()
它用于验证浏览器是否已连接。
新一页()
它产生一个带有新页面对象的 Promise。
页数()
它产生一个带有所有打开页面对象数组的 Promise。
过程()
如果使用 launch 方法创建实例,它会生成一个浏览器进程。此外,如果使用 connect 方法创建实例,它会产生空值。
目标()
它产生浏览器的目标。
目标()
它产生一个 Promise,其中包含所有活动目标的数组。
Puppeteer - 处理选项卡
我们可以使用以下方法处理 Puppeteer 中的选项卡 -
新一页()
我们可以使用浏览器对象中提供的此方法打开一个新选项卡。
句法
语法如下 -
const p = await browser.newPage()
关闭()
我们可以关闭使用此方法打开的选项卡。
句法
语法如下 -
await p.close()
关闭()
我们可以使用浏览器对象中可用的此方法关闭所有打开的选项卡。
句法
语法如下 -
await browser.close()
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//adding Puppeteer library
const pt = require('puppeteer')
pt.launch().then(async browser => {
//browser new page
const p = await browser.newPage();
//set viewpoint of browser page
await p.setViewport({ width: 1000, height: 500 })
//launch URL
await p.goto('https://www.tutorialspoint.com/index.htm')
//capture screenshot
await p.screenshot({
path: 'tutorialspoint.png'
});
//browser close
await browser.close()
})
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js
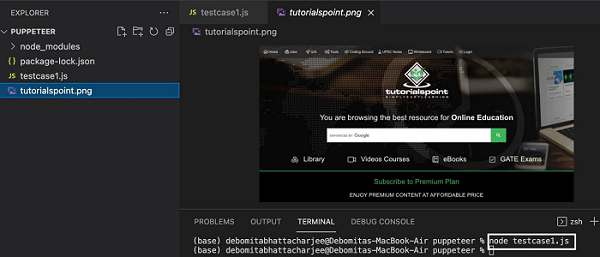
成功执行该命令后,会在页面目录中创建一个名为tutorialspoint.png 的新文件。它包含在浏览器中启动的页面的捕获屏幕截图。
Puppeteer - 基本命令
下面列出了 Puppeteer 的一些基本命令 -
标题()
该命令用于获取当前页面的标题。
句法
语法如下 -
await page.title()
网址()
该命令用于获取当前在浏览器中启动的应用程序的URL。
句法
语法如下 -
await page.url()
内容()
该命令用于获取页面源代码。
句法
语法如下 -
await page.content()
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//adding Puppeteer library
const pt = require('puppeteer');
pt.launch().then(async browser => {
//browser new page
const p = await browser.newPage();
//set viewpoint of browser page
await p.setViewport({ width: 1000, height: 500 })
//launch URL
await p.goto('https://www.tutorialspoint.com/questions/index.php')
//obtain page title
console.log("Page title: " + await p.title())
//obtain URL
console.log("Url: " + await p.url())
//browser close
await browser.close()
})
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js

命令成功执行后,页面标题 - 最佳技术问题和解答将打印在控制台中。此外,URL - www.tutorialspoint.com/questions/index.php也会打印在控制台中。执行是在无头模式下进行的。
傀儡师 - 火狐
我们可以在 Firefox 中运行 Puppeteer 开发的测试。必须记住,在 Firefox 中执行测试时,Puppeteer 使用其内部 Firefox 浏览器,而不是本地系统中安装的 Firefox 浏览器。
步骤 1 - 我们必须首先通过执行以下命令为 Firefox 浏览器安装 Puppeteer -
npm install puppeteer-firefox
另外,我们还必须在代码中添加 Firefox-Puppeteer 库。
const f = require('puppeteer-firefox')
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//adding Puppeteer- Firefox library
const pt = require('puppeteer-firefox');
//adding headless flag to false
pt.launch().then(async browser => {
//browser new page
const p = await browser.newPage();
//set viewpoint of browser page
await p.setViewport({ width: 1000, height: 500 })
//launch URL
await p.goto('https://www.tutorialspoint.com/about/about_careers.htm')
//get browser
const v = await p.browser().version();
console.log("Browser: " + v)
//browser close
await browser.close()
})
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js

成功执行命令后,执行测试的浏览器 - Firefox/65.0 将打印在控制台中。
木偶师 - Chrome
默认情况下,用 Puppeteer 编写的测试在 Chrome 或 Chromium 浏览器中以无头模式执行。另外,我们必须在代码中添加以下 Puppeteer 库。
const pt = require('puppeteer')
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//adding Puppeteer library
const pt = require('puppeteer');
pt.launch().then(async browser => {
//browser new page
const p = await browser.newPage();
//set viewpoint of browser page
await p.setViewport({ width: 1000, height: 500 })
//launch URL
await p.goto('https://www.tutorialspoint.com/index.htm')
//get browser
const v = await p.browser().version();
console.log("Browser: " + v)
//browser close
await browser.close()
})
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js

成功执行命令后,执行测试的浏览器 - HeadlessChrome/92.0.4512.0 将打印在控制台中。
Puppeteer - 处理确认警报
Puppeteer 能够处理警报。Selenium、WebdriverIO 等自动化工具会在警报出现在页面上后接受或消除警报。
然而,在 Puppeteer 中,用户必须在警报出现在页面上之前给出是否接受或忽略警报的指示。为此,必须使用 Puppeteer 触发 on 事件侦听器。
处理确认警报的方法
下面列出了一些使用警报的方法 -
Accept(): Promise<void> - 此方法用于接受警报。
message(): string - 此方法用于生成警报中获得的消息。
type(): DialogType - 此方法用于获取对话框类型。对话框类型可以是提示、确认或提示。
miss(): Promise<void> - 此方法用于消除警报。
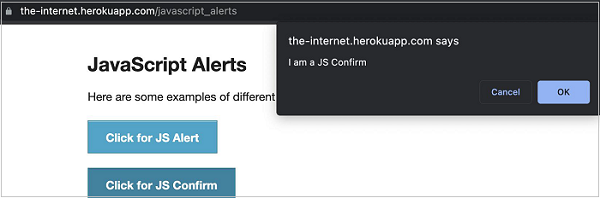
在下图中,单击“Click for JS Confirm”后,将显示确认警报。让我们获取警报上的文本。
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//Puppeteer library
const pt= require('puppeteer')
async function confirmAlert(){
//launch browser in headless mode
const browser = await pt.launch()
//browser new page
const page = await browser.newPage();
//on event listener trigger
page.on('dialog', async dialog => {
//get alert message
console.log(dialog.message());
//accept alert
await dialog.accept();
})
//launch URL
await page.goto('https://the-internet.herokuapp.com/javascript_alerts')
//identify element with xpath then click
const b = (await page.$x("//button[text()='Click for JS Confirm']"))[0]
b.click()
}
confirmAlert()
步骤 4 - 使用以下命令执行代码。
node <filename>
因此,在我们的示例中,我们将运行下面给出的命令 -
node testcase1.js

命令成功执行后,控制台中会打印确认警报文本 - I am a JS Confirm。
Puppeteer - 处理下拉菜单
我们可以处理 UI 中的下拉菜单,同时使用 Puppeteer 进行自动化测试。静态下拉列表在 html 代码中以标记名作为 select 进行标识,其选项以标记名作为选项。
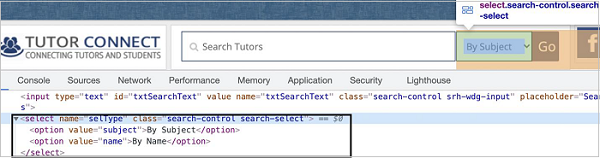
处理下拉菜单的方法
使用静态下拉菜单的一些方法 -
选择()
此方法用于从下拉列表中选择一个选项。要选择的选项的值作为参数传递给此方法。
句法
语法如下 -
const page = await browser.newPage()
const f = await page.$('[name="selType"]')
await f.select("subject")
我们还可以从多选下拉列表中选择多个选项。
句法
语法如下 -
await f.select("subject", "name")
要从下拉列表中获取选择值,我们必须使用 getProperty 方法并将值作为参数传递给该字段。
const v = await (await n.getProperty("value")).jsonValue()
console.log(v)
类型()
此方法用于从下拉列表中选择一个选项。要选择的选项的值作为参数传递给此方法。
句法
语法如下 -
const page = await browser.newPage()
const f = await page.$('[name="selType"]')
await f.type("subject")
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//Puppeteer library
const pt= require('puppeteer')
async function dropDownHandle(){
//launch browser in headless mode
const browser = await pt.launch()
//browser new page
const page = await browser.newPage()
//launch URL
await page.goto('https://www.tutorialspoint.com/tutor_connect/index.php')
//identify dropdown then select an option by value
const f = await page.$('[name="selType"]')
await f.select("subject")
//wait for sometime
await page.waitForTimeout(4000)
//get value selected
const v = await (await f.getProperty("value")).jsonValue()
console.log(v)
}
dropDownHandle()
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.j

命令成功执行后,在下拉列表中选择的选项值 - 主题将打印在控制台中。
傀儡师 - 定位器
我们可以使用 Puppeteer 处理页面上的元素。导航到网页后,我们必须与页面上可用的网络元素进行交互,例如单击链接/按钮、在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要工作是识别元素。为了唯一地获取元素的属性,我们需要检查它(右键单击该元素,然后选择“检查”选项)。ElementHandle 对象是通过方法创建的 - page.$、page.$$ 和 page.$x。这些对象引用页面中的元素或标签。
为了唯一地确定一个元素,我们可以借助 html 标签中的任何属性,也可以使用 html 标签上的属性组合。大多数情况下使用 id 属性,因为它对于页面来说是唯一的。
但是,如果 id 属性不存在,我们可以使用其他属性,例如类、名称等。如果 id、name 和 class 等属性不存在,我们可以利用仅对该标签可用的独特属性或属性及其值的组合来标识元素。为此,我们必须使用 xpath 表达式。
定位元素的方法
下面列出了这些方法 -
页.$(定位器值)
此方法使用 ElementHandle 生成一个 Promise。ElementHandle 是所识别元素的对象。如果有多个元素具有相同的定位器值,则仅返回页面左上角的第一个匹配元素。
页。$$(定位器值)
此方法生成一个带有 ElementHandle 数组的 Promise。如果有多个元素具有相同的定位器值,则所有匹配的元素将以数组的形式返回。
页.$x(xpath 值)
此方法生成一个带有 ElementHandle 数组的 Promise。如果有多个元素具有相同的 xpath 值,则所有匹配的元素将以数组的形式返回。如果有一个匹配元素,则返回的数组应只有一个元素。
ElementHandle 方法(如 elementHandle.$、elementHandle.$$ 和 elementHandle.$x)可以应用于元素。在这种情况下,应在当前 ElementHandle 的 DOM 中搜索元素,而不是在整个 DOM 中。
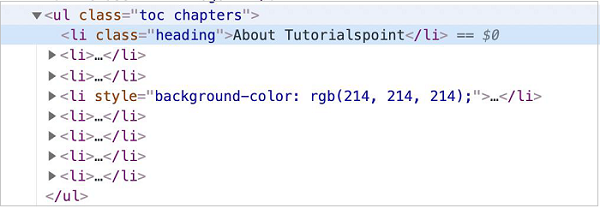
在下面给出的图像中,让我们以具有 li 标签(具有父元素 ul)和 class 属性值作为标题的元素为例。
要使用页面上的 ElementHandle 方法来识别它,表达式应如下所示 -
const n = await page.$(".heading")
要在元素上使用 ElementHandle 方法来识别它,表达式应该是 -
const m = await page.$("ul")
const p = await m.$(".heading")
现在,请参考下面给出的具有 li 标签的元素的图像
定位器的类型
Puppeteer 中的定位器类型如下所示 -
ID
班级
类型
X路径
属性
类型
要使用上述定位器,我们应该对 HTML 代码有基本的了解。让我们以具有以下属性的编辑框为例 -
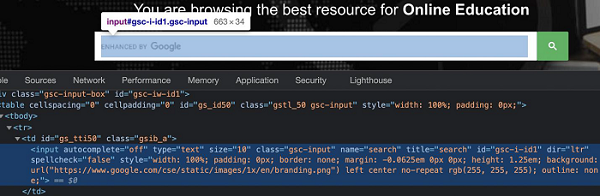
这里,输入是标记名。HTML 中的标签可能有属性,也可能没有。type、class、name、id等都是元素的属性。
例如,在表达式 id = "gsc-i-id1" 中,= 左侧的文本是属性名称 (id),= 右侧的文本是属性值 (gsc-i-id1)。
属性可以分配也可以不分配值。另外,如果分配了值,则应将其括在双引号或单引号中。属性的值由开发人员根据他的选择设置。
让我们以具有以下 html 代码的元素为例 -
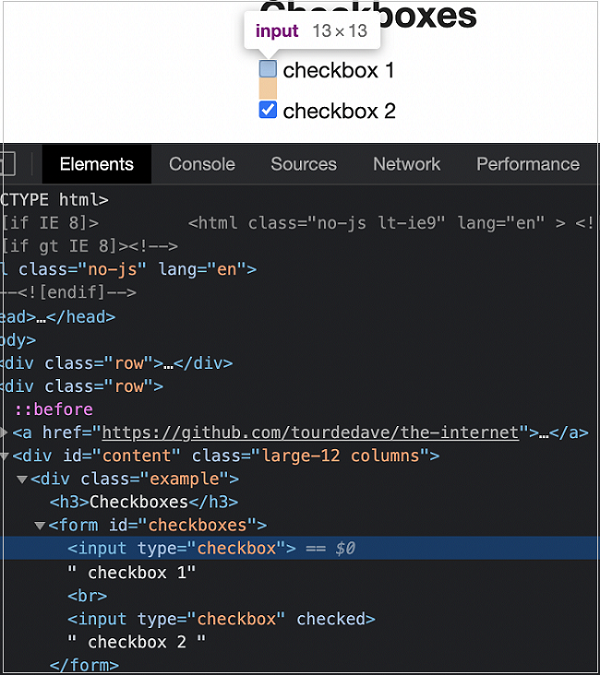
我们可以使用表达式识别上图中的第一个复选框 -
const n = await page.$("input[type='checkbox']")
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//Puppeteer library
const pt= require('puppeteer')
async function checkBoxHandle(){
//launch browser in headed mode
const browser = await pt.launch()
//browser new page
const page = await browser.newPage()
//launch URL
await page.goto('https://the-internet.herokuapp.com/checkboxes')
//identify element with xpath then click
const n = await page.$("input[type='checkbox']")
n.click()
//wait for sometime
await page.waitForTimeout(4000)
//verify if checkbox is checked
const v = await (await n.getProperty("checked")).jsonValue()
console.log(v)
}
checkBoxHandle()
步骤 4 - 使用下面提到的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js

命令执行成功后,控制台会打印布尔值true。这是由 getProperty("checked") 返回的,当选中复选框时返回 true。
Puppeteer - Xpath 函数
为了唯一地确定一个元素,我们可以借助 html 标签中的任何属性,也可以使用 html 标签上的属性组合。大多数情况下使用 id 属性,因为它对于页面来说是唯一的。
但是,如果 id 属性不存在,我们可以使用其他属性,例如类、名称等。如果 id、name 和 class 等属性不存在,我们可以利用仅对该标签可用的独特属性或属性及其值的组合来标识元素。为此,我们必须使用 xpath 表达式。
如果元素有重复属性或没有属性,则使用函数 text() 来标识元素。为了使用 text() 函数,元素必须具有页面上可见的文本。
句法
使用 text() 函数的语法如下 -
//tagname[text()='visible text on element']
如果元素或文本的值本质上是部分动态的或非常长,我们可以使用 contains() 函数。为了使用 contains() 函数,元素必须具有属性值或文本。
句法
使用 contains() 函数的语法如下 -
//tagname[contains(@attribute,'value')] //tagname[contains(text(),'visible text on element')]
如果元素的文本以特定文本开头,我们可以对其使用starts-with() 函数。
句法
使用starts-with()函数的语法如下 -
//tagname[starts-with(text(),'visible text on element')
在上述所有函数中,标记名是可选的。我们可以使用符号 * 来代替标记名。
在下图中,让我们借助显示的文本来识别元素 - 库,然后单击它。
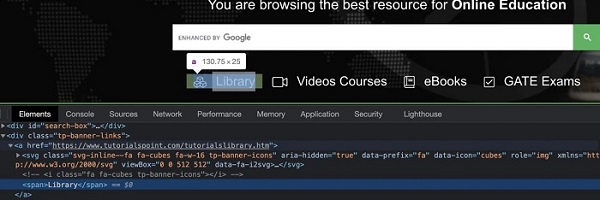
元素的 xpath 应为 //*[text()='Library']。
在这里,我们正在使用 xpath 选择器,因此我们必须使用方法:page.$x(xpath value)。有关此方法的详细信息将在“Puppeteer 定位器”一章中讨论。
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//Puppeteer library
const pt= require('puppeteer')
async function selectorFunTextXpath(){
//launch browser in headless mode
const browser = await pt.launch()
//browser new page
const page = await browser.newPage()
//launch URL
await page.goto('https://www.tutorialspoint.com/index.htm')
//identify element with xpath function - text() then click
const b = (await page.$x("//*[text()='Library']"))[0]
b.click()
//wait for sometime
await page.waitForTimeout(4000)
//obtain URL after click
console.log(await page.url())
}
selectorFunTextXpath()
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js

成功执行命令后,单击元素库时导航的页面的 URL - https://www.tutorialspoint.com/tutorialslibrary.htm将打印在控制台中。
Puppeteer - Xpath 属性
为了唯一地确定一个元素,我们可以借助 html 标签中的任何属性,也可以使用 html 标签上的属性组合。大多数情况下使用 id 属性,因为它对于页面来说是唯一的。
但是,如果 id 属性不存在,我们可以使用其他属性,例如类、名称等。如果 id、name 和 class 等属性不存在,我们可以利用仅对该标签可用的独特属性或属性及其值的组合来标识元素。为此,我们必须使用 xpath 表达式。
如果具有单个属性的 xpath 表达式标识多个元素,我们可以在 xpath 表达式中使用多个属性来定位单个元素。
仅具有一个属性的 xpath 的编写格式如下 -
//tagname[@attribute='value']
对于多个属性,我们可以应用 AND 和 OR 条件。使用 AND 条件编写 xpath 的格式 -
//tagName[@attribute1='value1'] [@attribute2='value2']
或者,
//tagName[@attribute1='value1' and @attribute2='value2']
使用 OR 条件编写 xpath 的格式如下 -
//tagName[@attribute1='value1' or @attribute2='value2']
我们还可以通过对属性应用 NOT 条件来识别元素。编写带有 NOT 条件的 xpath 的格式 -
//tagname[not(@attribute='value')]
让我们借助 alt 属性识别页面上下面突出显示的徽标,然后单击它。
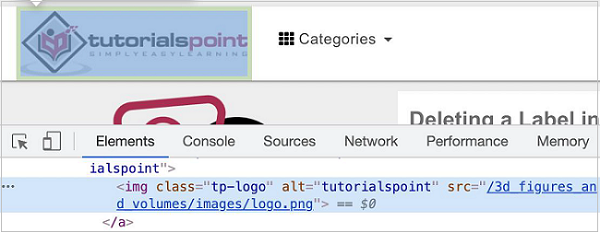
元素的 xpath 应如下 -
//img[@alt='tutorialspoint'].
在这里,我们正在使用 xpath 选择器,因此我们必须使用方法:page.$x(xpath value)。有关此方法的详细信息将在 Puppeteer 定位器一章中讨论。
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在创建的 testcase1.js 文件中添加以下代码。
//Puppeteer library
const pt= require('puppeteer')
async function selectorAttributeXpath(){
//launch browser in headed mode
const browser = await pt.launch()
//browser new page
const page = await browser.newPage()
//launch URL
await page.goto('https://www.tutorialspoint.com/questions/index.php')
//identify element with relative xpath then click
const b = (await page.$x("//img[@alt='tutorialspoint']"))[0]
b.click()
//wait for sometime
await page.waitForTimeout(4000)
//obtain URL after click
console.log(await page.url())
}
selectorAttributeXpath()
步骤 4 - 使用下面给出的命令执行代码 -
node <filename>
因此,在我们的示例中,我们将运行以下命令 -
node testcase1.js

成功执行命令后,单击徽标图像时导航的页面 URL - https://www.tutorialspoint.com/index.htm将打印在控制台中。
Puppeteer - Xpath 分组
为了唯一地确定一个元素,我们可以借助 html 标签中的任何属性,也可以使用 html 标签上的属性组合。大多数情况下使用 id 属性,因为它对于页面来说是唯一的。
但是,如果 id 属性不存在,我们可以使用其他属性,例如类、名称等。如果 id、name、class 等属性不存在,我们可以利用仅对该标签可用的不同属性或属性及其值的组合来标识元素。为此,我们必须使用 xpath 表达式。
利用索引从一组匹配元素中获取一个元素称为组索引。如果 xpath 表达式标识多个元素,那么我们可以使用组索引。
编写组索引的格式首先是 xpath 表达式,后跟 [] 中括起来的索引号。它表示一个xpath数组,索引从1开始。函数last()用于指向xpath数组中的最后一个元素。
句法
使用函数last()的语法如下 -
(/table/tbody/tr/td[1]/input)[last()]
句法
函数position()用于获取xpath数组中特定位置的元素。语法如下 -
(/table/tbody/tr/td[1]/input)[position()=1]
上述 xpath 表达式应从所有匹配元素的组中获取第一个元素。
在下图中,让我们识别突出显示的编辑框并在其中输入一些文本。
因此 xpath 表达式应如下所示 -
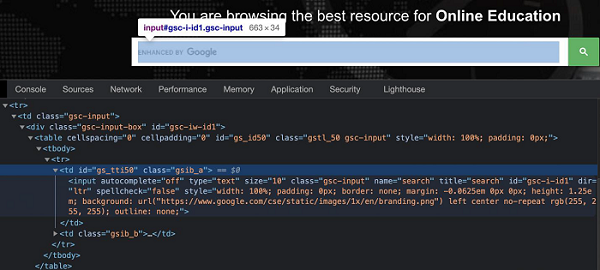
在上面的示例中,表中有两列(由 td 标签表示),其父级为 tr 标签。输入框位于第一列中。
因此 xpath 表达式应如下所示 -
//table/tbody/tr/td[1]/input
在这里,我们正在使用 xpath 选择器,因此我们必须使用方法:page.$x(xpath value)。有关此方法的详细信息将在 Puppeteer 定位器一章中讨论。
首先,请按照《Puppeteer 基本测试》一章中的步骤 1 至 2 进行操作,如下所示 -
步骤 1 - 在创建 node_modules 文件夹的目录中创建一个新文件(Puppeteer 和 Puppeteer 核心的安装位置)。
Puppeteer 安装的详细信息将在 Puppeteer 安装章节中讨论。
右键单击创建 node_modules 文件夹的文件夹,然后单击“新建文件”按钮。
步骤 2 - 输入文件名,例如 testcase1.js。
步骤 3 - 在 testcase1 中添加以下代码